本記事は国土交通データプラットフォームアドベントカレンダー16日目の記事です。
はじめに
みなさん こんにちは
昨日の記事では国土交通DPFからAPIを利用して全国道路施設点検データベースのデータセットから「措置状況」が「措置未着手」かつ「健全性」が「Ⅳ(緊急措置)」または「Ⅲ(早期措置)」の施設を取得しました。
本日は道路交通センサスのデータも組み合わせてみていきます。
リクエストボディの定義
検索APIのクエリ内容を定義します。
データセットに「令和3年度道路交通センサス」のIDを指定し、東京都のデータを取得するようにDPF:prefecture_codeが13のデータのみとしています。
graphql_query: str = """
{
search(
term: "",
phraseMatch: true,
first: 0,
size: 10000,
attributeFilter: {
AND: [
{
attributeName: "DPF:dataset_id",
is: "rtc_2021"
},
{
attributeName: "DPF:prefecture_code",
is: "13"
}
]
}
) {
totalNumber
searchResults {
title
lat
lon
metadata
shape
}
}
}
"""
令和3年度道路交通センサスデータの取得
準備ができたのでリクエストを送信します。
このあたりのくだりは昨日と同じですね。
data: dict = send_request(query=graphql_query)
df: pd.DataFrame = pd.json_normalize(data["search"]["searchResults"])
前回同様、不要な項目が多く、列名も長いので必要な項目に列名も変えます。交通量に関するデータは様々な項目がメタデータにはあるのですが今回は24時間自動車類交通量(観測値上下合計)合計(台)のみを取得します。
selected_columns: list = [
"title",
"lat",
"lon",
"shape",
"metadata.RTC:24jikan_jidousharui_koutsuuryou_jouge_goukei_goukei",
]
sections_df = (
df[selected_columns]
.rename(
columns={
"metadata.RTC:24jikan_jidousharui_koutsuuryou_jouge_goukei_goukei": "n",
}
)
)
| title | lat | lon | shape | n | |
|---|---|---|---|---|---|
| 0 | 交通調査基本区間番号:13111010005 (中央自動車道富士吉田線) | 35.6791 | 139.61 | 71587 | |
| 1 | 交通調査基本区間番号:13111010010 (中央自動車道富士吉田線) | 35.6805 | 139.604 | 82264 | |
| 2 | 交通調査基本区間番号:13110100030 (東名高速道路) | 35.6267 | 139.608 | 93294 | |
| 3 | 交通調査基本区間番号:13110100010 (東名高速道路) | 35.5053 | 139.482 | 140425 | |
| 4 | 交通調査基本区間番号:13111010030 (中央自動車道富士吉田線) | 35.6745 | 139.588 | 82264 |
あれ!?shapeが全てNoneとなっています。。。
国土交通DPFのWeb上では道路区間の形状が表示されていますが、ポリゴンのLINESTRING情報はAPIでは取得できないようです。
道路施設点検データベースのPOINTの円バッファと道路交通センサスのLINESTRINGを空間結合して交通量を紐づけしようと考えていたため困りました。。。
各区間の緯度・経度は取得できているので次善策として次の2つが考えられそうです。
- 道路施設点検データベースの各施設から道路交通センサスの最寄の区間を探索する
- 道路交通センサスの各区間の緯度・経度からボロノイ分割を行い、道路施設点検データベースの各施設と空間結合する
どちらの方法にしても道路交通センサスの調査区間上にない施設については異なる道路の交通量が紐づいてしまいますが、近くの道路の交通量ということで今回は諦めます。。。
また前者はshapely.ops.nearest_points()、後者はshapely.ops.voronoi_diagram()でそれおぞれ実現できそうですが、実装が容易な後者でやってみます。
ボロノイ分割って何?という方は以下を参考にしてください。
ボロノイ分割
取得したデータのうちshape項目は意味がないため取り除きます。また緯度・経度がNAのデータが含まれており、ボロノイ分割でエラーになるためdropna()で取り除きます。
selected_columns: list = [
"title",
"lat",
"lon",
# "shape",
"metadata.RTC:24jikan_jidousharui_koutsuuryou_jouge_goukei_goukei",
]
sections_df = (
df[selected_columns]
.rename(
columns={
"metadata.RTC:24jikan_jidousharui_koutsuuryou_jouge_goukei_goukei": "n",
}
)
.dropna()
)
ボロノイ分割に必要なライブラリを読み込み、ボロノイ分割を行います。
import geopandas as gpd
from pyproj import CRS
from shapely.geometry import MultiPoint, Point
from shapely.ops import voronoi_diagram
geoms = list(zip(sections_df["lon"], sections_df["lat"]))
regions = voronoi_diagram(MultiPoint(geoms))
voronoi_gdf = gpd.GeoDataFrame(regions.geoms, columns=["geometry"], crs="EPSG:4612")
voronoi_gdf.head()
| geometry | |
|---|---|
| 0 | POLYGON ((129.81219490797355 45.02528740665462, 132.77884694011124 45.02528740665462, 138.99596888287792 35.864862882520626, 139.0218767933142 35.78820255696122, 138.99485872419288 35.774220682931855, 129.81219490797355 36.929367427583244, 129.81219490797355 45.02528740665462)) |
| 1 | POLYGON ((129.81219490797355 36.929367427583244, 138.99485872419288 35.774220682931855, 138.99659031509447 35.773478557575125, 139.0145246029404 35.75425846740958, 139.01315062225194 35.748503944885805, 138.79391592714157 35.504827752293735, 138.28614368554994 34.95848384902915, 138.04432974610813 34.903870104084405, 136.3900822932036 34.75601311428446, 129.81219490797355 34.18446558700949, 129.81219490797355 36.929367427583244)) |
| 2 | POLYGON ((138.28614368554994 34.95848384902915, 138.79391592714157 35.504827752293735, 139.04885578130128 35.73988195131397, 139.0517164648518 35.740295429732534, 138.9746189775799 35.45292930901753, 138.8499372597349 35.13456247116261, 138.43407594227259 34.99462585803959, 138.37653377668906 34.97617336694454, 138.28614368554994 34.95848384902915)) |
| 3 | POLYGON ((139.02418227157455 35.78247748108477, 139.021195787944 35.77507079826434, 138.99659031509447 35.773478557575125, 138.99485872419288 35.774220682931855, 139.0218767933142 35.78820255696122, 139.02418227157455 35.78247748108477)) |
| 4 | POLYGON ((139.021195787944 35.77507079826434, 139.02418227157455 35.78247748108477, 139.04756150791934 35.77548011605376, 139.03926602950816 35.7568837687862, 139.03270173936824 35.75354336877937, 139.0171702024313 35.74840167918533, 139.01315062225194 35.748503944885805, 139.0145246029404 35.75425846740958, 139.021195787944 35.77507079826434)) |
ボロノイ分割の結果は元の道路区間のDataFrameと順番が異なるため道路区間のDataFrameもGeoDataFrameに変換し、空間結合します。
sections_df["geometry"] = [Point(xy) for xy in geoms]
sections_gdf = gpd.GeoDataFrame(sections_df, geometry="geometry", crs="EPSG:4612")
voronoi_gdf = gpd.sjoin(sections_gdf, voronoi_gdf, how="right", predicate="intersects")
では地図に表示してみましょう。
import folium
from branca.colormap import linear
# カラーパレットの作成
values = voronoi_gdf["n"]
min_val = min(values)
max_val = max(values)
pal = linear.Spectral_11.scale(min_val, max_val)
pal.caption = "n"
m = folium.Map(tiles="http://cyberjapandata.gsi.go.jp/xyz/pale/{z}/{x}/{y}.png", attr="地理院タイル")
# ボロノイ分割の結果を追加
folium.GeoJson(
voronoi_gdf,
name="Voronoi",
style_function=lambda feature: {"fillColor": pal(feature["properties"]["n"]), "fillOpacity": 0.5, "weight": 1},
).add_to(m)
# 道路交通センサスの各区間の座標を追加
for _, row in sections_df.iterrows():
folium.CircleMarker(
location=[row["lat"], row["lon"]], radius=5, color="black", fill=True, fill_color="white", fill_opacity=1
).add_to(m)
m
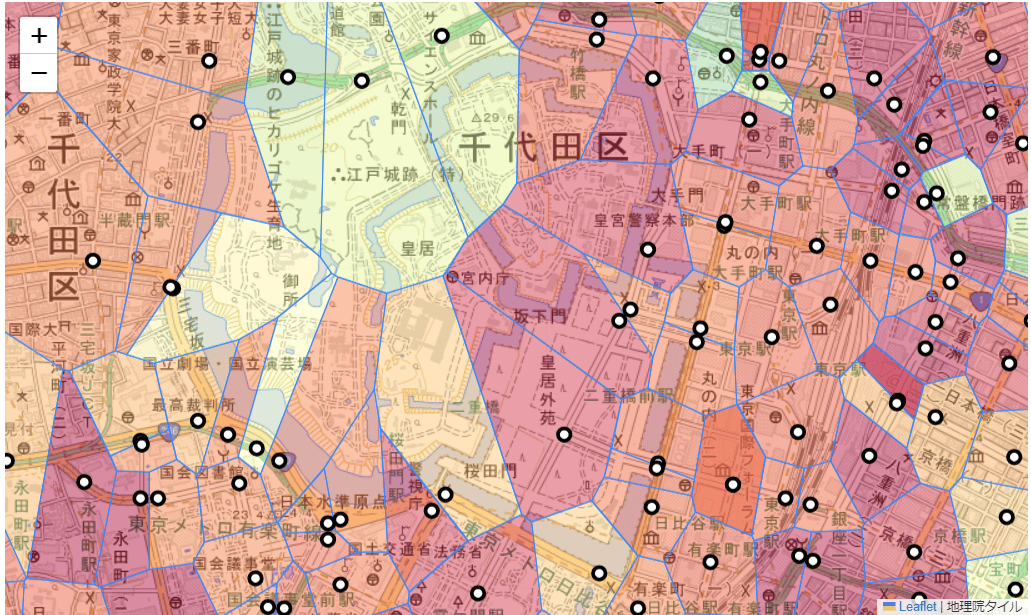
道路交通センサスの各区間の座標からボロノイ分割を行うことができました!
あとは道路施設点検データベースの各施設と空間結合することで施設付近の交通量が紐づけられそうです。
全国道路施設点検データベースと道路交通センサスの結合
昨日作成した全国道路施設点検データベースのデータのDataFrameはfacilities_dfにリネームし、空間結合を行うためGeoDataFrameに変換します。
facilities_df = df
geoms = list(zip(facilities_df["lon"], facilities_df["lat"]))
facilities_df["geometry"] = [Point(xy) for xy in geoms]
facilities_gdf = gpd.GeoDataFrame(facilities_df, geometry="geometry", crs="EPSG:4612")
ボロノイ分割した道路交通センサスと空間結合します。
facilities_gdf = gpd.sjoin(facilities_gdf, voronoi_gdf[["title", "n", "geometry"]])
facilities_gdf[["title_left", "title_right", "hantei_kubun", "n"]]
| title_left | title_right | hantei_kubun | n | |
|---|---|---|---|---|
| 0 | 亀戸駅前歩道橋 | 交通調査基本区間番号:13403060210 (王子千住夢の島線) | 4 | 19815 |
| 695 | 亀戸一丁目歩道橋 | 交通調査基本区間番号:13403060210 (王子千住夢の島線) | 3 | 19815 |
| 1 | 栄町横断歩道橋 | 交通調査基本区間番号:13400050110 (新宿青梅線) | 4 | 37287 |
| 457 | 第二恩多橋 | 交通調査基本区間番号:13400050110 (新宿青梅線) | 3 | 37287 |
| 458 | 第一恩多橋 | 交通調査基本区間番号:13400050110 (新宿青梅線) | 3 | 37287 |
可視化してみましょう!
m = folium.Map(tiles="http://cyberjapandata.gsi.go.jp/xyz/pale/{z}/{x}/{y}.png", attr="地理院タイル")
folium.GeoJson(
voronoi_gdf, name="Voronoi", style_function=lambda feature: {"fillColor": "transparent", "weight": 1}
).add_to(m)
for _, row in facilities_gdf.iterrows():
folium.CircleMarker(
location=[row["lat"], row["lon"]], radius=5, color="black", fill=True, fill_color=pal(row["n"]), fill_opacity=1
).add_to(m)
m
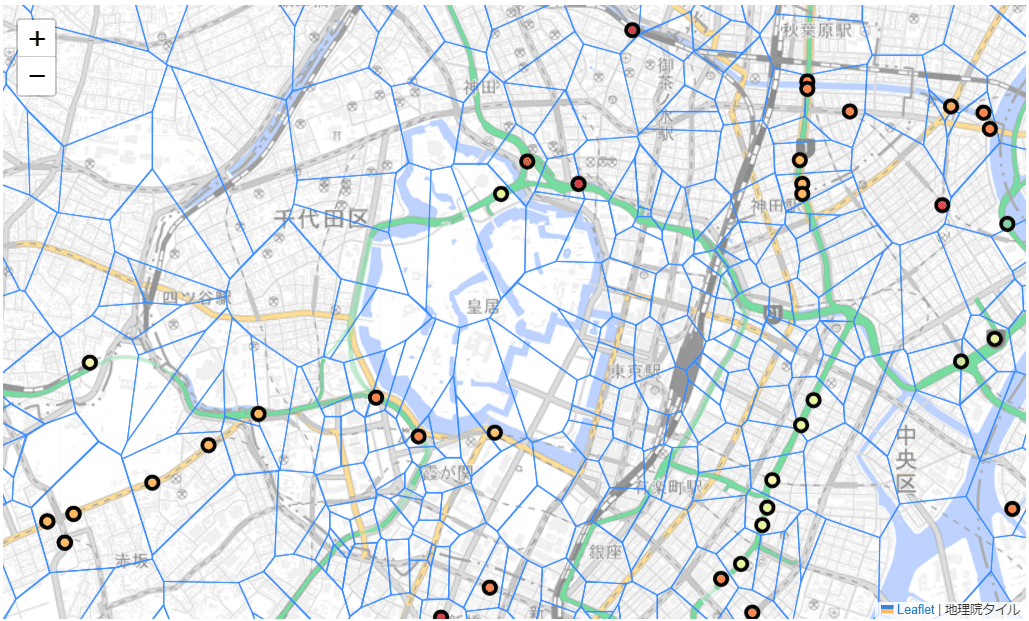
道路施設点検データベースの各施設に付近の道路の交通量を紐づけ、交通量に応じて色分けすることができました!
首都高都心環状線(C1)の京橋~江戸橋JCTの施設よりも神田橋・一ツ橋IC付近の施設の措置を優先した方が良いかもしれません。
まとめ
道路交通センサスの形状データが取得できず、当初思っていた分析はできませんでしたが何とか道路施設点検データベースの各施設に付近の道路の交通量を紐づけることができました。
措置の優先度を決定するにあたり必要な情報は他にもあるかと思いますが、今回の分析が参考になれば幸いです。
また国土交通DPFのデータもAPIを活用することで容易に取得できるのでみなさまも是非ご活用ください!
それではまた~