以前からGlacierを理解したいと思っていて軽く触ってみたのでまとめてみた。
しかしながら、現在はS3のGlacierアーカイブ機能があるためS3経由でならこの記事のように複雑なことをしなくても料金の圧縮が行える。
Glacierというサービスがどのようなものなのかという理解を深める上で手を動かして理解するにはこの記事はちょうどよいのかもしれない。
想定読者
以下のような方を想定している。
- AWSを使っている
- S3を使ったことがある or ある程度の知識を持っている
- AWS Glacierを聞いたことはあるけどよくわからない
- 使ってみたいけど使い方が分からない
Glacierとは?
おそらく知っていると思うが念のため。
一言で言うと 利便性を落とした代わりに値段が安く使えるS3。
主に似ているAWSサービスのS3と比較すると特徴は以下。
- ストレージ単価が安い
- 取り出すまでに若干のタイムラグがある
用途
アクセス頻度が低いが消したくないデータを低価格 & 高可用性な環境で保持したい場合に使用する。
用語
Glacierを理解するために以下の用語を抑えておく。
- Vault(ボールト)
- S3でいうバケット
- Archive(アーカイブ)
- S3でいうオブジェクト
- ただしS3と異なりIDが振られていてそれを使ってアクセスする
- S3のようにファイル間隔で気軽にはアクセスできない
- Jobを経由して一定期間後に取得可能になる
- Inventory(インベントリー)
- Archive一覧を保持している
- 公式いわく一日間隔でArchive一覧が更新されるらしい
- Job (ジョブ)
- Vaultを対象にして行う処理
- 主にArchive/Inventoryの取得作業に用いる(他にあるかは分からない)
動作環境
| 項目 | バージョンなど |
|---|---|
| OS | Mac Sierra |
| AWS CLI | aws-cli/1.11.180 Python/3.6.3 Darwin/16.7.0 botocore/1.7.38 |
使い方
以下の工程を使って使い方を学ぶ。
- Vaultの作成
- Archiveのアップロード
- Archiveの取得
- Archiveの削除
- Vaultの削除
Glacierは2017-12-02現在でマネジメントコンソールから利用することが出来ない。
故に今回はAWS CLIを用いて解説していく。
ただしここではAWS CLIの使い方や導入については解説しない。
Vaultの作成
これはマネジメントコンソールからでも作成可能。
だがそれ以降はCLIを使っていくことになるのでここでもCLIを使用する。
vault-name には付けたい名前をつければ良いが今回は qiita-test という名前を使っていく。
account-id は - を指定すればIAMユーザに紐付いたアカウントIDが使用される。
# {{account-id}}は伏せている
$ aws glacier create-vault --account-id - --vault-name qiita-test
{
"location": "/{{account-id}}/vaults/qiita-test"
}
これで作成が完了した。
以下で確認して該当のVaultが作成できていれば完了していることを確認できる。
$ aws glacier list-vaults --account-id -
{
"VaultList": [
{
"VaultARN": "arn:aws:glacier:ap-northeast-1:{{account-id}}:vaults/qiita-test",
"VaultName": "qiita-test",
"CreationDate": "2017-11-02T13:46:26.012Z",
"NumberOfArchives": 0,
"SizeInBytes": 0
},
]
}
Archiveをアップロード
次に保存させたいデータをVaultにアップロードしていく。
コマンドは upload-archive を使用する。
ここで最も重要なのが出力された archiveId である。
以降のArchive取得時には必須パラメータなので忘れずに保存しておくこと。
ArchiveIdを忘れた場合は後述するInventoryを使うことになる。
# テスト用のファイル
$ echo 'Hello Glacier' > ~/simple.txt
$ aws glacier upload-archive --account-id - --vault-name qiita-test --body ~/simple.txt
{
"location": "/{{account-id}}/vaults/qiita-test/archives/OQBATOmxpMSNOxXPrKLkGiISpNvtZySRe-Dg_PvVbg3zxfIRGa3o1et33LvKvZSJA2_nAHW9eMhclfJAbGLzSV3owDcUvNglvAEafu67wKsECismh1uRL_-Rz0rCsGD_4AoGB7UP8w",
"checksum": "6b72933f6d83bb1294fef21c290d86ad4d5bacee89a0e34eca284c08b00e88c1",
"archiveId": "OQBATOmxpMSNOxXPrKLkGiISpNvtZySRe-Dg_PvVbg3zxfIRGa3o1et33LvKvZSJA2_nAHW9eMhclfJAbGLzSV3owDcUvNglvAEafu67wKsECismh1uRL_-Rz0rCsGD_4AoGB7UP8w"
}
Archiveの取得
取得Jobの発行
GlacierではS3のように即時にデータにはアクセスできず、Jobを経由してデータを取得する。
データの取得Jobには速度・価格で3種類選べるので場合によって使い分けると良い。
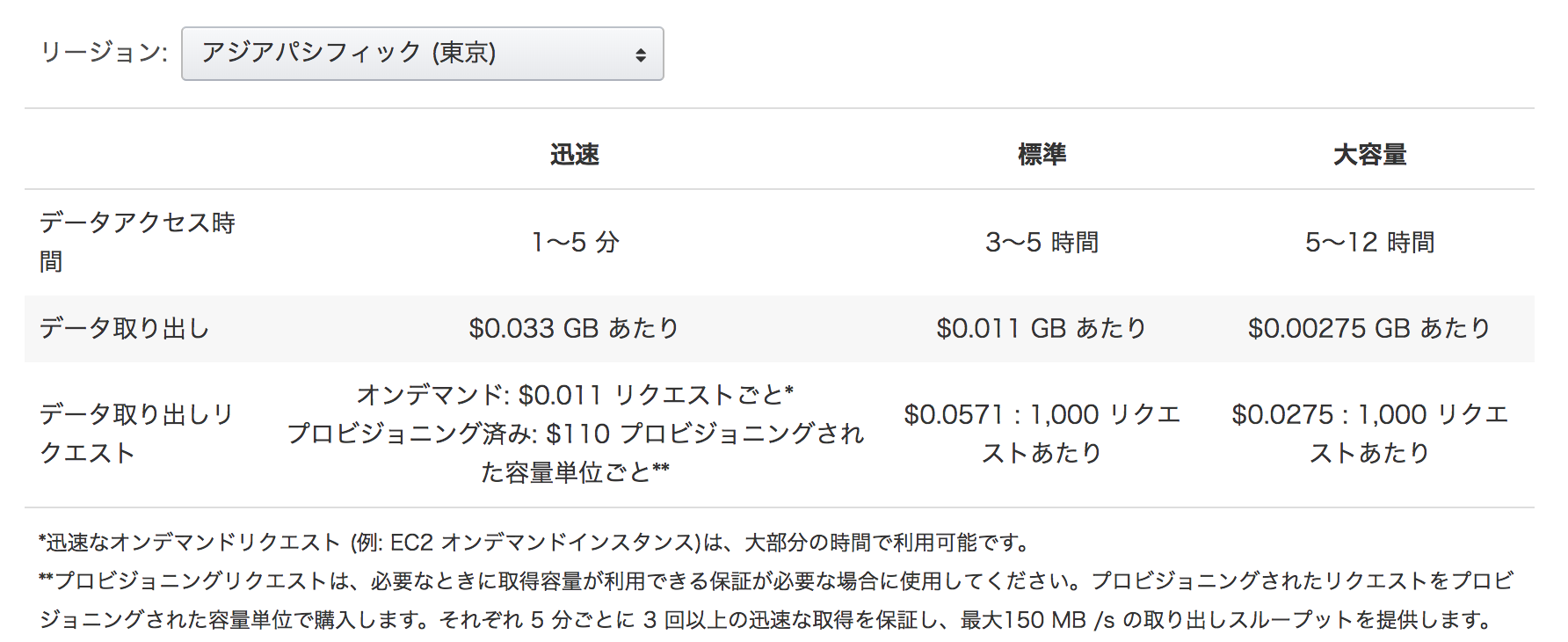
まずはArchive取得Jobを投げる。
先程のArchiveIdを指定してあげる必要があるのだけど、パラメータがJSONなので一度ファイルに展開しておく。
jobのパラメータの説明は以下に記載。
- SNSTopic
- Jobが完了したときに通知するSNSのARNを指定する
- これがないとJobが完了したときに通知をしてくれなくなる
- SNSについての説明はここではしない
- Tier
- 上記の料金表に記載されている取得方法の種類を指定する
- 左から順に Expedited|Standard|Bulk にそれぞれ対応している
$ cat ~/job.json
{
"Type": "archive-retrieval",
"ArchiveId": "OQBATOmxpMSNOxXPrKLkGiISpNvtZySRe-Dg_PvVbg3zxfIRGa3o1et33LvKvZSJA2_nAHW9eMhclfJAbGLzSV3owDcUvNglvAEafu67wKsECismh1uRL_-Rz0rCsGD_4AoGB7UP8w",
"Description": "Hello Glacier Simple Message",
"SNSTopic": "{{sns-arn}}",
"Tier" : "Standard"
}
あとは上記のファイルを --job-parameters オプションで指定してあげれば良い。
出力される jobId は今後必要になるので覚えておこう。
# --job-parameter 'JSON' で直接記述することも可能
$ aws glacier initiate-job --account-id - --vault-name qiita-test --job-parameters file://~/job.json
{
"location": "/{{account-id}}/vaults/qiita-test/jobs/3o5VRlLDKI7rc3kykAzvGqfHop1AbJbX5CjDAd9_GPaFtCVAcRDp6Rjp2Wigz5iVhQSZq8VAvy4xCNhjWVV_4Ie2Syci",
"jobId": "3o5VRlLDKI7rc3kykAzvGqfHop1AbJbX5CjDAd9_GPaFtCVAcRDp6Rjp2Wigz5iVhQSZq8VAvy4xCNhjWVV_4Ie2Syci"
}
Jobの状態は以下のコマンドで確認できる。
もしJobIdを忘れた場合はこれで調べることも出来る。
$ aws glacier list-jobs --account-id - --vault-name qiita-test
{
"JobList": [
{
"JobId": "3o5VRlLDKI7rc3kykAzvGqfHop1AbJbX5CjDAd9_GPaFtCVAcRDp6Rjp2Wigz5iVhQSZq8VAvy4xCNhjWVV_4Ie2Syci",
"JobDescription": "Hello Glacier Simple Message",
"Action": "ArchiveRetrieval",
"ArchiveId": "OQBATOmxpMSNOxXPrKLkGiISpNvtZySRe-Dg_PvVbg3zxfIRGa3o1et33LvKvZSJA2_nAHW9eMhclfJAbGLzSV3owDcUvNglvAEafu67wKsECismh1uRL_-Rz0rCsGD_4AoGB7UP8w",
"VaultARN": "arn:aws:glacier:ap-northeast-1:{{account-id}}:vaults/qiita-test",
"CreationDate": "2017-12-02T14:30:24.038Z",
"Completed": false,
"StatusCode": "InProgress",
"ArchiveSizeInBytes": 14,
"SNSTopic": "{{snsのarn}}",
"SHA256TreeHash": "6b72933f6d83bb1294fef21c290d86ad4d5bacee89a0e34eca284c08b00e88c1",
"ArchiveSHA256TreeHash": "6b72933f6d83bb1294fef21c290d86ad4d5bacee89a0e34eca284c08b00e88c1",
"RetrievalByteRange": "0-13",
"Tier": "Standard"
}
]
}
完了JobからArchiveをダウンロード
JOBが完了すると以下のようなメッセージがSNS経由で来る。
{
"Action": "ArchiveRetrieval",
"ArchiveId": "OQBATOmxpMSNOxXPrKLkGiISpNvtZySRe-Dg_PvVbg3zxfIRGa3o1et33LvKvZSJA2_nAHW9eMhclfJAbGLzSV3owDcUvNglvAEafu67wKsECismh1uRL_-Rz0rCsGD_4AoGB7UP8w",
"ArchiveSHA256TreeHash": "6b72933f6d83bb1294fef21c290d86ad4d5bacee89a0e34eca284c08b00e88c1",
"ArchiveSizeInBytes": 14,
"Completed": true,
"CompletionDate": "2017-12-02T18:24:32.585Z",
"CreationDate": "2017-12-02T14:30:24.038Z",
"InventoryRetrievalParameters": null,
"InventorySizeInBytes": null,
"JobDescription": "Hello Glacier Simple Message",
"JobId": "3o5VRlLDKI7rc3kykAzvGqfHop1AbJbX5CjDAd9_GPaFtCVAcRDp6Rjp2Wigz5iVhQSZq8VAvy4xCNhjWVV_4Ie2Syci",
"RetrievalByteRange": "0-13",
"SHA256TreeHash": "6b72933f6d83bb1294fef21c290d86ad4d5bacee89a0e34eca284c08b00e88c1",
"SNSTopic": "{{sns-arn}}",
"StatusCode": "Succeeded",
"StatusMessage": "Succeeded",
"Tier": "Standard",
"VaultARN": "arn:aws:glacier:ap-northeast-1:{{account-id}}:vaults/qiita-test"
}
これでArchiveからダウンロード出来る環境は整ったのでJobIdを指定してArchiveのダウンロードを行っていく。
$ aws glacier get-job-output --account-id - --vault-name qiita-test --job-id 3o5VRlLDKI7rc3kykAzvGqfHop1AbJbX5CjDAd9_GPaFtCVAcRDp6Rjp2Wigz5iVhQSZq8VAvy4xCNhjWVV_4Ie2Syci ~/job-output.txt
{
"checksum": "6b72933f6d83bb1294fef21c290d86ad4d5bacee89a0e34eca284c08b00e88c1",
"status": 200,
"acceptRanges": "bytes",
"contentType": "application/octet-stream"
}
$ cat ~/job-output.txt
Hello Glacier
無事Archiveをダウンロードすることが出来た。
Archiveの削除
Archiveおいておくだけでお金は掛かるのでそれが気になるという場合はArchiveを削除できる。
削除にはArchiveIdを指定すれば良い。
ちなみに削除してもすぐにはインベントリには反映はされず最大1日掛かる。
$ aws glacier delete-archive --account-id - --vault-name qiita-test --archive-id OQBATOmxpMSNOxXPrKLkGiISpNvtZySRe-Dg_PvVbg3zxfIRGa3o1et33LvKvZSJA2_nAHW9eMhclfJAbGLzSV3owDcUvNglvAEafu67wKsECismh1uRL_-Rz0rCsGD_4AoGB7UP8w
# 何も出力されない
Vaultの削除
Archiveが完全になくなったらVaultを削除することが出来る。
もしArchiveが存在する場合は下記のような例外が投げられる。
消した直後でおかしいと思うが、どうやらInventoryが更新されたタイミングでArchiveが存在しなくなるまではVaultの削除は出来ないようだ。
Inventoryの更新までおとなしく待つ(ちなみにInventoryの更新を手動で行う方法は調べた感じないようだった)
$ aws glacier delete-vault --account-id - --vault-name qiita-test
An error occurred (InvalidParameterValueException) when calling the DeleteVault operation: Vault not empty or recently written to: arn:aws:glacier:ap-northeast-1:{{account-id}}:vaults/qiita-test
Inentoryが更新されて空になったらVaultが削除できるようになっているので試してみよう。
$ aws glacier delete-vault --account-id - --vault-name qiita-test
# 上記の例外を除いて成功・失敗に関わらず何も表示されない
Vaultの一覧を取得してVaultがなくなっていることを確認してなくなっていれば削除完了。
$ aws glacier list-vaults --account-id -
{
"VaultList": [
]
}
もしArchiveIdが分からなくなった場合
ArchiveIdがないとArchiveを取得することすら出来ない。
もしArchiveIdを保存し忘れていた場合はInventory経由でArchiveIdを知る必要がある。
以下のようにInventoryの取得Jobを流して一覧を取得することが出来る。
ただしこちらもArchive取得と同様に待たされる上にTierで速度も選べないので数時間の待ちが発生する。
そのため、基本ArchiveIdはupload時点で保存するようにしておくことをオススメする。
Inventoryを取得するJsonパラメータを以下に記載。
- Format
- 取得結果のファイル形式
- JSON|CSV のどちらかが選べる
- SNSTopic
- Archive取得Jobと同義
- InventoryRetrievalParameters
- オプションで指定可能。Archiveの絞込が行える
- .StartDate
- 取得したいArchiveの開始期間
- .EndDate
- 取得したいArchiveの終了期間
- .Limit
- Archiveを最大何件表示するか
- なければ限界の数を返す
以下のパラメータの場合は2017/11/23 ~ 2017/12/03 の間で1000件という条件を付けてInventoryからArchiveの検索を行っている(1件しかないから意味ないけど)。
$ cat ~/inventory_job.txt
{
"Type": "inventory-retrieval",
"Description": "Get Inventory",
"Format": "JSON",
"SNSTopic": "{{sns-arn}}",
"InventoryRetrievalParameters": {
"StartDate": "2017-11-23T00:00:00Z",
"EndDate": "2017-12-03T00:00:00Z",
"Limit": "1000"
}
}
$ aws glacier initiate-job --account-id - --vault-name qiita-test --job-parameters file://~/inventory_job.json
{
"location": "/{{account-id}}/vaults/qiita-test/jobs/CgRscKViRNU3XUgqxa8nu8GWVhmkw3yEWEZ089NZ0Hj-a9aL86QHHc5zav3VW2e5KUHm5AQwoMEd5QjNysg9EWYvhSin",
"jobId": "CgRscKViRNU3XUgqxa8nu8GWVhmkw3yEWEZ089NZ0Hj-a9aL86QHHc5zav3VW2e5KUHm5AQwoMEd5QjNysg9EWYvhSin"
}
Jobが発行されていることをArchiveの時と同様に list-jobs で確認できる。
今回はオプションに --completed false を付けることで完了していないJobのみを表示するようにした。
$ aws glacier list-jobs --account-id - --vault-name qiita-test --completed false
{
"JobList": [
{
"JobId": "CgRscKViRNU3XUgqxa8nu8GWVhmkw3yEWEZ089NZ0Hj-a9aL86QHHc5zav3VW2e5KUHm5AQwoMEd5QjNysg9EWYvhSin",
"JobDescription": "Get Inventory",
"Action": "InventoryRetrieval",
"VaultARN": "arn:aws:glacier:ap-northeast-1:{{account-id}}:vaults/qiita-test",
"CreationDate": "2017-12-03T01:28:54.814Z",
"Completed": false,
"StatusCode": "InProgress",
"SNSTopic": "{{sns-arn}}",
"InventoryRetrievalParameters": {
"Format": "JSON",
"StartDate": "2017-11-23T00:00:00Z",
"EndDate": "2017-12-03T00:00:00Z",
"Limit": "1000"
}
}
]
}
Archiveと同様にJobが完了するとSNS経由で通知が来る。
通知を確認したらArchiveの取得と同様に JobId をパラメータに渡してあげることでInventoryからArchiveの一覧を取得することが可能。
$ aws glacier get-job-output --account-id - --vault-name qiita-test --job-id CgRscKViRNU3XUgqxa8nu8GWVhmkw3yEWEZ089NZ0Hj-a9aL86QHHc5zav3VW2e5KUHm5AQwoMEd5QjNysg9EWYvhSin ~/output-get-inventory.json
$ cat ~/output-get-inventory.json | jq .
{
"VaultARN": "arn:aws:glacier:ap-northeast-1:{{account-id}}:vaults/qiita-test",
"InventoryDate": "2017-12-02T17:21:20Z",
"ArchiveList": [
{
"ArchiveId": "OQBATOmxpMSNOxXPrKLkGiISpNvtZySRe-Dg_PvVbg3zxfIRGa3o1et33LvKvZSJA2_nAHW9eMhclfJAbGLzSV3owDcUvNglvAEafu67wKsECismh1uRL_-Rz0rCsGD_
4AoGB7UP8w",
"ArchiveDescription": "",
"CreationDate": "2017-12-02T13:57:27Z",
"Size": 14,
"SHA256TreeHash": "6b72933f6d83bb1294fef21c290d86ad4d5bacee89a0e34eca284c08b00e88c1"
}
]
}
おわりに
S3は使い方を分かっているけどGlacierをどう使っていいか分からない、という読者の疑問はこの記事を読んで多少は解消されることを期待している。
他にも分割アップロードや分割ダウンロードなどの機能があるようですが、あくまでも触りということで記載しなかった(し、自分も試してないので分からない)。
気になる方は公式の資料などを読むことでより理解が深まると思う。