以下のGitHubのサンプルで手軽にAmazon Bedrockを試すことができます。
Cloud9を使えば手軽に環境も準備できるので、その方法を紹介します。
準備
まずは、Cloud9を作成します。
リージョンはap-northeast-1、インスタンスは、Amazon Linux 2023/t3.smallを使いました。
Amazon Linux 2023にはpythonが入っていないため、以下のコマンドでインストールしました。
sudo dnf install python
次に、GitHubからサンプルをクローニングします。
git clone https://github.com/build-on-aws/amazon-bedrock-quick-start.git
cd amazon-bedrock-quick-start
pip install -r requirements.txt
Chatbot

Chatbotのサンプルがありますが、Ahthropic社のClaudeがAccess grantedになっている必要があります。
サンプルのChatbotはStreamlitを使っており、以下のコマンドで実行することができます。
--server.portオプションで起動ポートを変更できます。
Cloud9では、プレビュー機能を使うために8080で起動する必要があります。
streamlit run chat_bedrock_st.py --server.port 8080
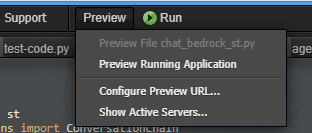
以下のメニューから、「Preview Running Application」を選択します。
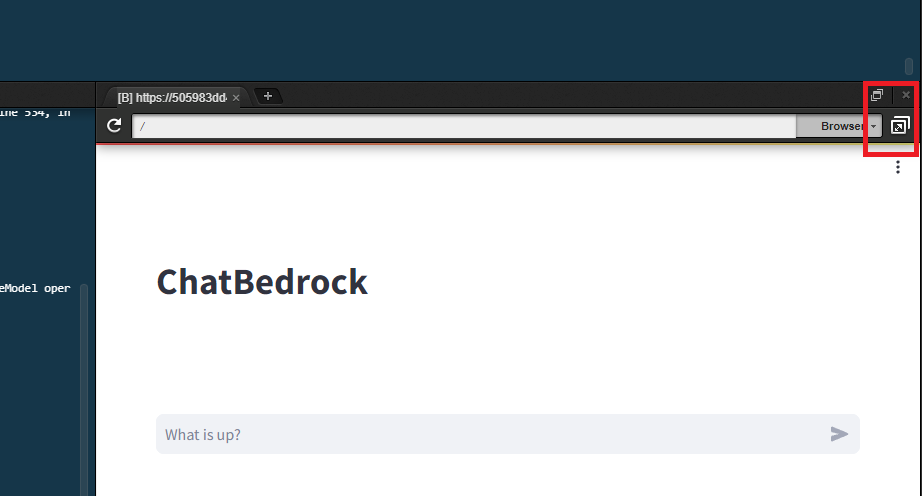
そうするとプレビュー用のブラウザが起動します。
右上の拡大ボタンを押すことでブラウザ全体で表示できます。
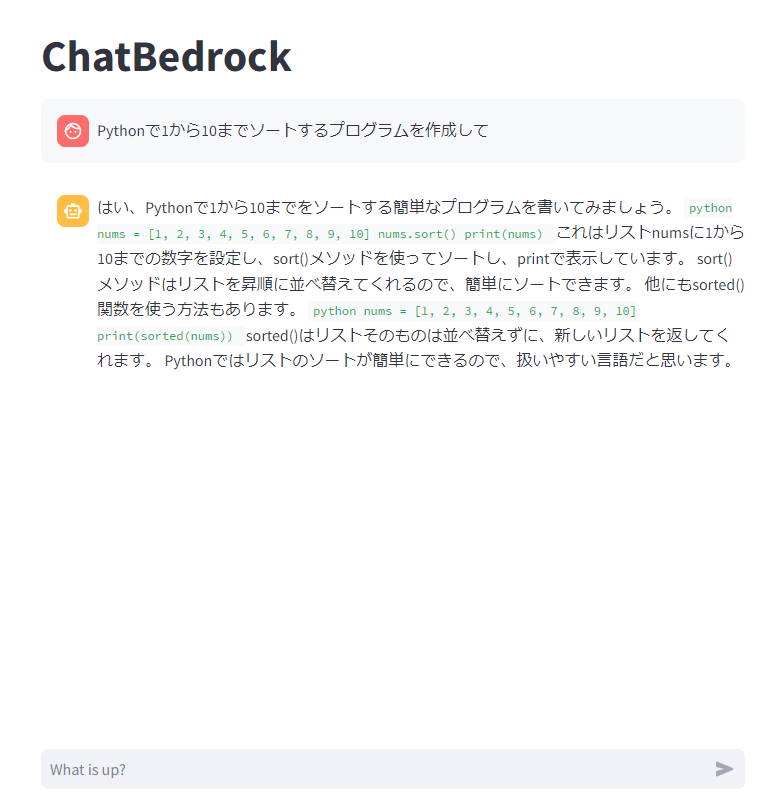
以上で、以下のようにChatbotのサンプルアプリケーションが実行できます。
しかし、一つ大きな問題があります。
それは、Bedrockが回答をMarkdownで回答してくれているのですが、コードがうまく表示されていない点です。
具体的には、コードが改行されずに表示されています。
この問題は、Bedrockの回答をsplitして表示していますが、
splitにより、スペースだけでなく、改行やタブも含めてスペースに変換されてしまっています。
簡易的に解決するために、splitの対象を改行(\n)のみにして、(\n)をくっつけることで解決します。
厳密には、Markdownの改行はスペース2個に続き\nがあれば改行になります。
\nで区切って、\nをつけているので元通りになります。
差分は以下のようになります。
ついでに、Claude2.1に変更しています。
$ diff -u chat_bedrock_st.py chat_bedrock_st.py.orig
--- chat_bedrock_st.py 2023-12-21 17:59:53.168601175 +0000
+++ chat_bedrock_st.py.orig 2023-12-21 17:59:48.518580682 +0000
@@ -16,7 +16,7 @@
@st.cache_resource
def load_llm():
- llm = Bedrock(client=bedrock_runtime, model_id="anthropic.claude-v2:1")
+ llm = Bedrock(client=bedrock_runtime, model_id="anthropic.claude-v2")
llm.model_kwargs = {"temperature": 0.7, "max_tokens_to_sample": 2048}
model = ConversationChain(llm=llm, verbose=True, memory=ConversationBufferMemory())
@@ -46,8 +46,8 @@
result = model.predict(input=prompt)
# Simulate stream of response with milliseconds delay
- for chunk in result.split("\n"):
- full_response += chunk + "\n"
+ for chunk in result.split():
+ full_response += chunk + " "
time.sleep(0.05)
# Add a blinking cursor to simulate typing
message_placeholder.markdown(full_response + "▌")
元ネタはStreamlitのドキュメントのようですが、同じ問題があります。
これで、うまくコードが表示されるようになりました。
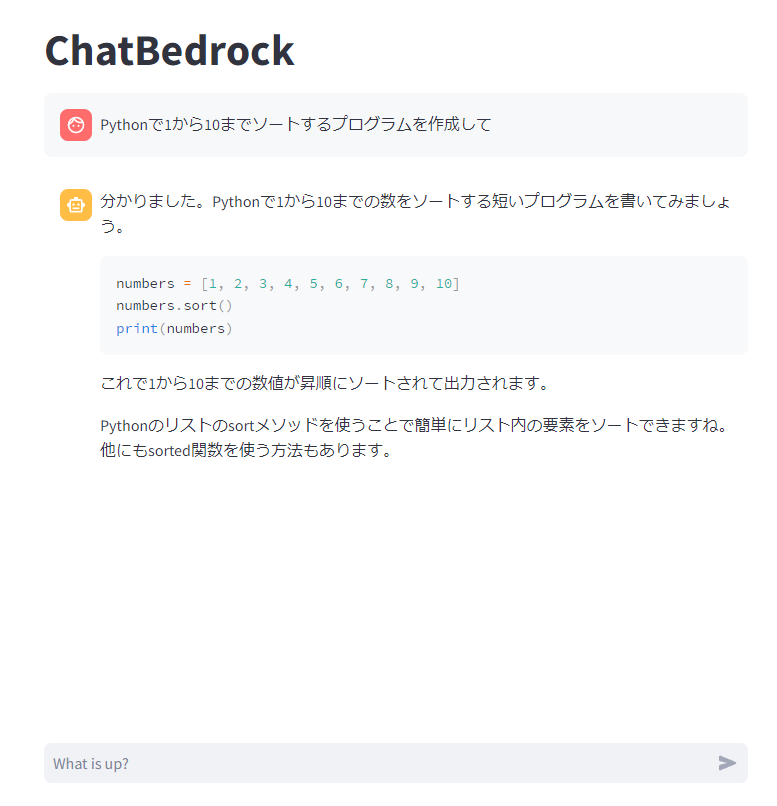
import time
import boto3
import streamlit as st
from langchain.chains import ConversationChain
from langchain.llms.bedrock import Bedrock
from langchain.memory import ConversationBufferMemory
st.title("ChatBedrock")
# Setup bedrock
bedrock_runtime = boto3.client(
service_name="bedrock-runtime",
region_name="us-east-1",
)
@st.cache_resource
def load_llm():
llm = Bedrock(client=bedrock_runtime, model_id="anthropic.claude-v2:1")
llm.model_kwargs = {"temperature": 0.7, "max_tokens_to_sample": 2048}
model = ConversationChain(llm=llm, verbose=True, memory=ConversationBufferMemory())
return model
model = load_llm()
if "messages" not in st.session_state:
st.session_state.messages = []
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
if prompt := st.chat_input("What is up?"):
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
with st.chat_message("assistant"):
message_placeholder = st.empty()
full_response = ""
# prompt = prompt_fixer(prompt)
result = model.predict(input=prompt)
# Simulate stream of response with milliseconds delay
for chunk in result.split("\n"):
full_response += chunk + "\n"
time.sleep(0.05)
# Add a blinking cursor to simulate typing
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
st.session_state.messages.append({"role": "assistant", "content": full_response})
試しに、今回の問題点をClaude2.1とGPT4に問い合わせてみました。
Claude2.1の改行置換はいるの?と思いますが、全体的にClaude2.1の方が正解に近いです。
GPT4の方は、ハルシネーションのような回答ですね。
# 改行コードを置換
result = re.sub(r'\\n', '\n', result)
# ストリーム応答のシミュレーション
for chunk in result.split('\n'):
full_response += chunk + "\n"
time.sleep(0.05)
message_placeholder.markdown(full_response + "▌")
# Simulate stream of response with milliseconds delay
for chunk in result.split():
full_response += chunk + " "
time.sleep(0.05)
# Convert newline characters to Markdown line breaks for proper display
display_response = full_response.replace("\n", " \n")
# Add a blinking cursor to simulate typing
message_placeholder.markdown(display_response + "▌")
# Convert newline characters to Markdown line breaks for the final display
final_display_response = full_response.replace("\n", " \n")
message_placeholder.markdown(final_display_response)
Image Generation
次は画像生成のサンプルです。
Stability AIのSDXLを使っています。
例によって、8080ポートで起動します。
streamlit run sd_sample_st.py --server.port 8080
その際、以下のエラーが出ました。
対象の基盤モデルを有効にしていなかったためです。
2023-12-23 04:20:55.847 Uncaught app exception
Traceback (most recent call last):
File "/home/ec2-user/.local/lib/python3.9/site-packages/streamlit/runtime/scriptrunner/script_runner.py", line 534, in _run_script
exec(code, module.dict)
File "/home/ec2-user/environment/amazon-bedrock-quick-start/sd_sample_st.py", line 102, in
image = base64_to_pil(generate_image(prompt, style))
File "/home/ec2-user/environment/amazon-bedrock-quick-start/sd_sample_st.py", line 68, in generate_image
response = bedrock_runtime.invoke_model(
File "/home/ec2-user/.local/lib/python3.9/site-packages/botocore/client.py", line 553, in _api_call
return self._make_api_call(operation_name, kwargs)
File "/home/ec2-user/.local/lib/python3.9/site-packages/botocore/client.py", line 1009, in _make_api_call
raise error_class(parsed_response, operation_name)
botocore.errorfactory.AccessDeniedException: An error occurred (AccessDeniedException) when calling the InvokeModel operation: You don't have access to the model with the specified model ID.
以下の通り、SDXL 1.0のみ有効にしていました。

モデルIDを確認すると無印のSDXL(stability.stable-diffusion-xl)は、SDXL 0.8のようです。
$ aws bedrock list-foundation-models --region us-east-1 | jq '.modelSummaries[] | select(.providerName == "Stability AI")'
{
"modelArn": "arn:aws:bedrock:us-east-1::foundation-model/stability.stable-diffusion-xl",
"modelId": "stability.stable-diffusion-xl",
"modelName": "SDXL 0.8",
"providerName": "Stability AI",
"inputModalities": [
"TEXT",
"IMAGE"
],
"outputModalities": [
"IMAGE"
],
"customizationsSupported": [],
"inferenceTypesSupported": [
"ON_DEMAND"
],
"modelLifecycle": {
"status": "ACTIVE"
}
}
{
"modelArn": "arn:aws:bedrock:us-east-1::foundation-model/stability.stable-diffusion-xl-v0",
"modelId": "stability.stable-diffusion-xl-v0",
"modelName": "SDXL 0.8",
"providerName": "Stability AI",
"inputModalities": [
"TEXT",
"IMAGE"
],
"outputModalities": [
"IMAGE"
],
"customizationsSupported": [],
"inferenceTypesSupported": [
"ON_DEMAND"
],
"modelLifecycle": {
"status": "ACTIVE"
}
}
{
"modelArn": "arn:aws:bedrock:us-east-1::foundation-model/stability.stable-diffusion-xl-v1:0",
"modelId": "stability.stable-diffusion-xl-v1:0",
"modelName": "SDXL 1.0",
"providerName": "Stability AI",
"inputModalities": [
"TEXT",
"IMAGE"
],
"outputModalities": [
"IMAGE"
],
"customizationsSupported": [],
"inferenceTypesSupported": [
"PROVISIONED"
],
"modelLifecycle": {
"status": "ACTIVE"
}
}
{
"modelArn": "arn:aws:bedrock:us-east-1::foundation-model/stability.stable-diffusion-xl-v1",
"modelId": "stability.stable-diffusion-xl-v1",
"modelName": "SDXL 1.0",
"providerName": "Stability AI",
"inputModalities": [
"TEXT",
"IMAGE"
],
"outputModalities": [
"IMAGE"
],
"customizationsSupported": [],
"inferenceTypesSupported": [
"ON_DEMAND"
],
"modelLifecycle": {
"status": "ACTIVE"
}
}
SDXL 1.0に変更しました。
$ diff -u sd_sample_st.py sd_sample_st.py.orig
--- sd_sample_st.py 2023-12-23 04:25:26.875946880 +0000
+++ sd_sample_st.py.orig 2023-12-23 04:19:22.205589725 +0000
@@ -61,7 +61,7 @@
body = json.dumps(body)
- modelId = "stability.stable-diffusion-xl-v1"
+ modelId = "stability.stable-diffusion-xl"
accept = "application/json"
contentType = "application/json"
無事、実行でき、画像が生成されました。
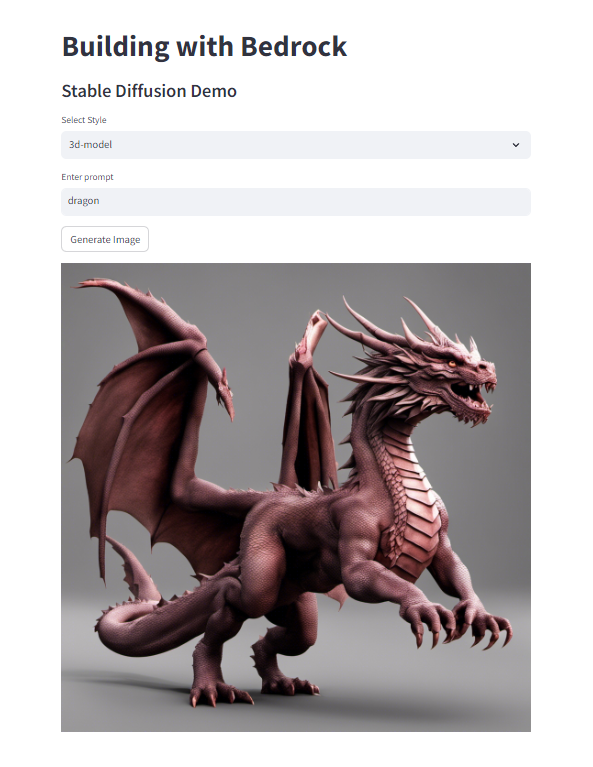
Text Examples
次は、テキストベースの問い合わせの例です。
以下の基盤モデルを使用しています。事前に有効化する必要があります。
$ grep modelId text_examples.py
modelId = "ai21.j2-mid"
body=body, modelId=modelId, accept=accept, contentType=contentType
modelId = "anthropic.claude-v2"
body=body, modelId=modelId, accept=accept, contentType=contentType
modelId = "cohere.command-text-v14"
body=body, modelId=modelId, accept=accept, contentType=contentType
実行は以下の通りです。
python text_examples.py
実行結果です。
$ python text_examples.py
=== Summarization Example ===
Summary:
Amazon Bedrock is a fully managed service that offers high-performing foundation models (FMs) from leading AI companies, along with a broad set of capabilities to build generative AI applications. It is generally available, and Meta's Llama 2 13B and 70B parameter models will soon be available on Amazon Bedrock.
=== Code Generation Example ===
Generated Code:
Here is a Python function to upload a file to Amazon S3:
```python
import boto3
def upload_file_to_s3(file_name, bucket, object_name=None):
"""Upload a file to an S3 bucket
:param file_name: File to upload
:param bucket: Bucket to upload to
:param object_name: S3 object name. If not specified then file_name is used
:return: True if file was uploaded, else False
"""
# If S3 object_name was not specified, use file_name
if object_name is None:
object_name = file_name
# Upload the file
s3_client = boto3.client('s3')
try:
response = s3_client.upload_file(file_name, bucket, object_name)
except ClientError as e:
logging.error(e)
return False
return True
```
To use it:
```python
import upload_to_s3
file_to_upload = '/local/path/to/file.txt'
bucket_name = 'mybucket'
upload_file_to_s3(file_to_upload, bucket_name)
```
This will upload the file /local/path/to/file.txt to the S3 bucket 'mybucket'. The S3 object will be named file.txt.
You would need to set up boto3 with your AWS credentials to authenticate.
=== Q&A Example ===
Answer: Based on the provided information, the announcement was that Amazon Bedrock supports two models from Meta: Llama 2 13B and Llama 2 70B. There was no mention of other models in the text.
各問合せと回答を以下にまとめました。
Summarization Example (ai21.j2-mid)
Prompt:
This April, we announced Amazon Bedrock as part of a set of new tools for building with generative AI on AWS. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies, including AI21 Labs, Anthropic, Cohere, Stability AI, and Amazon, along with a broad set of capabilities to build generative AI applications, simplifying the development while maintaining privacy and security Today, I'm happy to announce that Amazon Bedrock is now generally available! I'm also excited to share that Meta's Llama 2 13B and 70B parameter models will soon be available on Amazon Bedrock.
Completion:
Amazon Bedrock is a fully managed service that offers high-performing foundation models (FMs) from leading AI companies, along with a broad set of capabilities to build generative AI applications. It is generally available, and Meta's Llama 2 13B and 70B parameter models will soon be available on Amazon Bedrock.
Code Generation Example (anthropic.claude-v2)
Prompt:
Write a Python function that uploads a file to Amazon S3
Completion:
Generated Code:
Here is a Python function to upload a file to Amazon S3:
import boto3
def upload_file_to_s3(file_name, bucket, object_name=None):
"""Upload a file to an S3 bucket
:param file_name: File to upload
:param bucket: Bucket to upload to
:param object_name: S3 object name. If not specified then file_name is used
:return: True if file was uploaded, else False
"""
# If S3 object_name was not specified, use file_name
if object_name is None:
object_name = file_name
# Upload the file
s3_client = boto3.client('s3')
try:
response = s3_client.upload_file(file_name, bucket, object_name)
except ClientError as e:
logging.error(e)
return False
return True
To use it:
import upload_to_s3
file_to_upload = '/local/path/to/file.txt'
bucket_name = 'mybucket'
upload_file_to_s3(file_to_upload, bucket_name)
This will upload the file /local/path/to/file.txt to the S3 bucket 'mybucket'. The S3 object will be named file.txt.
You would need to set up boto3 with your AWS credentials to authenticate.
Q&A Example (cohere.command-text-v14)
Prompt:
How many models does Amazon Bedrock support given the following text:
This April, we announced Amazon Bedrock as part of a set of new tools for building with generative AI on AWS. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies, including AI21 Labs, Anthropic, Cohere, Stability AI, and Amazon, along with a broad set of capabilities to build generative AI applications, simplifying the development while maintaining privacy and security Today, I'm happy to announce that Amazon Bedrock is now generally available! I'm also excited to share that Meta's Llama 2 13B and 70B parameter models will soon be available on Amazon Bedrock.
Completion:
Based on the provided information, the announcement was that Amazon Bedrock supports two models from Meta: Llama 2 13B and Llama 2 70B. There was no mention of other models in the text.
RAG Example
最後はRAGのサンプルです。
以下の基盤モデルを使用します。
- anthropic.claude-v2
- amazon.titan-embed-text-v1
実行は以下のコマンドです。
python rag_example.py
$ python rag_example.py
What type of pet do I have?
Based on the context provided, it seems you have a dog as a pet. The context contains multiple sentences mentioning "your dog" and describing it as "cute". There are no references to any other type of pet. Therefore, the most reasonable conclusion is that you have a dog as a pet.
ちょっとわかりづらいので補足します。
What type of pet do I have?
ペットの種類を訪ねています。
Use the following pieces of context to answer the question at the end.
How cute your dog is!You have such a cute dog!Your dog is so cute.I work in New York City.
Question: What type of pet do I have?
Answer:
事前情報をベクトルデータベース化して、プロンプトに情報を挿入しています。
Based on the context provided, it seems you have a dog as a pet. The context contains multiple sentences mentioning "your dog" and describing it as "cute". There are no references to any other type of pet. Therefore, the most reasonable conclusion is that you have a dog as a pet.
事前情報を参考に、dogと回答しています。