前書き
何故この記事を書こうと思ったのか
正直、長いエンジニア人生の中でまともにアセンブリを書いた事は(ほぼ)ない。ほぼ、というのは以前一度だけトライした事があって、何かしら書いた記憶があるのだが、どこかに残る様な何かを書いた訳ではないし今となってはどういうものだったのかもほとんど覚えていない。大学は情報系でマイコンで回路を組んだりした事はあったがアセンブリで書いた事はなかった。
私は Web 開発も多数したし最近はクライアントサイドの開発も多いが、最近の開発はサーバーサイドにしろクライアントサイドにしろとにかく高級で、基礎工事は全部終わってビルも建っていて内装をちょろっといじりましたみたいな実装が多い。これでいいのか。いや、開発手法としてはこれでいいのは分かる。効率的だから。しかし、エンジニアとして本当にこれでいいのだろうかという思いが拭い切れない。**内装工事だけして、「僕ビル建てましたぁ!ドヤァー!」**とは心から言えないものがある。
全ての工事について基礎から全部自分で建てろとは言わないが、せめて「建てようと思えば建てる事ができる」状態になっておく事は必要なのではないだろうか。そんな思いで、ほんの少しだけ土を掘ってみた。立派な杭は立てていない。
なお、全編自分の理解を垂れ流すオナニー記事なので、何か間違いなどあったらコメントして頂けると助かります。
せっかちなアタナに
全部読むのめんどくさい!というアナタ。個人的に心踊ったツールとかを書き出しておくので、もし使った事がなければ使ってみてください。
- nasm
- Mac でも使えるアセンブラ
- lldb
- ステップ実行したりメモリの中身を見たりできるツール
-
memory readやregister readでメモリやレジスタの中身も見える
- vmmap
- 実行ファイルに書かれているロジックやデータがどの様にメモリ上に展開されるかを確認できるツール
- lldb と組み合わせると理論と実際が繋がって超面白い
- otool
- Mach-o フォーマットのファイルの中身がどうなっているかを人間でも分かる感じに書き出してくれるツール
基礎知識
コンピュータとは何なのか
「んなこたぁ知っとるわい!」という方も多数だとは思うが、自分の理解を披露するオナニー記事なので(笑)一応書いておこうと思う。そもそも、アセンブリにたどり着く前にコンピュータというものについて、簡単に書いておく。よく言われる事だが、コンピュータの基本的な構成は下記の様なものだ。
- 外部から情報を入力し → 入力
- それを一時的に記憶したりして → 記憶
- 最終的にはそれを用いて演算し → 演算
- 何かをアウトプットする → 出力
- という流れを制御装置が制御する → 制御
これらをどの様に行うかという事を、エンジニアは逐一指定しなければならない。それには、これらの制御を司る CPU に命令を出せなければならない。その様な一連の命令を昔は配線を変える事などで実現していた様であるが(詳しくは知らない)、今日ではストアド・プログラム方式と言ってハードディスクなどに記録されており、これがプログラムの起動時にメモリに読み込まれ、さらにそこからデータとして命令を読み出して CPU が動作しているという訳だ。これがなかなか画期的で、コンピュータの中で命令を作りそれを実行する事ができる。ハードウェア的に何かをいじる必要がないという事だ。
アセンブリとは何なのか
アセンブリ(アセンブリ言語)とは CPU が実行できる命令1つ1つに人間の理解できるワード(ニーモニックとも呼ばれる)を割り当てた最もレベルの低い言語である。逆に、最近 Unity で有名な C# や Web 系の開発で有名な Ruby などはレベルの高い(高級)言語である。レベルが低い高いとはどういう事かと言うと、下記の様なイメージだ。
- レベルが低い
- 機械は理解できるが、人間は理解しにくい
- CPU が実行できる最小単位の手続き
- レベルが高い
- 機械は理解できないが、人間は理解しやすい
- 抽象化された便利な手続き
要は機械に分かる言葉で全部書いているとチビチビチビチビ小難しく書かなければならないのでとてつもなく大変で、もう少し抽象化して分かりやすい手続きとして記述して、それを機械が分かる言葉に変換してもらおう、という事だ。
なお、最小単位の手続きと書いたが、必ずしもこれが 1 クロックを示すものではないという点はやや注意が必要だ。1つの命令が何クロックを消費するのかという CPI (Cycles Per Instruction) という単位があり、必ずしも 1 ではないからだ(むしろ 0.5 という事もある)。
アセンブリの命令の種類
では実際にアセンブリにはどの様な命令の種類があるだろうか。そういった一連の命令は Instruction Set(命令セット)と呼ばれ、CPU のアーキテクチャ(基本構造)ごとに違っている。MIPS や ARM や Intel で違う、といったイメージだ。今日では Mac は Intel 系の CPU を搭載しているので、ここでは Intel 系の命令セットで書いていこうと思う。なお、自分は Intel 系でしか書いた事はないが、命令セットは「方言」の様なもので、ほぼほぼ同じ様なものであると考えて問題ない様である(参考:コンピュータの構成と設計)。
ここに、Intel アーキテクチャの命令セット(の一部)を書き出してみる。…一応補足だが、Intel と言っても厳密には x86, IA32, IA64, x86-64 などの種類がある様で(すみませんあまり詳しくない)、このリストは IA32(32bit の x86 という認識)から割と本質っぽい動作をするものを抜粋したものである。
| ニーモニック | 説明 |
|---|---|
| ADD | 加算を行う |
| AND | 論理積を算出する |
| CALL | 別のプロシージャにジャンプする |
| CMP | 比較を行う |
| CPUID | CPU の識別情報を取得する |
| DEC | デクリメントする |
| DIV | 除算を行う |
| IN | ポートから入力を行う |
| INC | インクリメントする |
| INT | 割り込み処理を行う |
| JMP | ジャンプする |
| LOOP | ループ処理を行う |
| MOV | データを転送する |
| NOT | 否定を行う |
| OR | 論理和を算出する |
| OUT | ポートに出力する |
| POP | スタックから POP する |
| PUSH | スタックに PUSH する |
| RET | プロシージャから CALL 元に戻る |
| SUB | 減算を行う |
| XOR | 排他的論理和を算出する |
これらを使えば、データを読み込み、条件によって様々な演算をし、その一部を保存したりして、外部に出力する事ができる。また、OS の機能を呼び出す事もできる。
ここで、初めて出てきた言葉がいくつかある。
- プロシージャ
- ポート
- スタック
これらを一応軽く説明すると、下記の様な感じになると思う。
- 高級言語における関数の様なイメージで、インプットを与える事ができ、返り値として結果を返す事ができ、何度も呼ばれる前提で一定区間に区切られた一連の命令。
- CPU が外部の装置とデータをやりとりするために情報を一時的にためておく領域。ポート番号を指定してデータを読み込んだり書き込んだりする。
- プロシージャのローカル変数を保持したり、引数を格納したりするためのメモリ領域。プロシージャの呼び出しに応じて積み上げられていき、返る段階で削除される(Last In, First Out)のでスタックと呼ばれている。
これで、おおよそではあるが命令の種類は理解できたと思う。
演算の流れ
実際にアセンブリで書くとなると、CPU がどの様に動いているのかをイメージしなければならない。ざっくり言うと、下記の様な感じだ。
- メモリやポートからデータをレジスタという CPU 内の一時記憶領域にコピーする
- レジスタの値を使って演算し、結果はまたレジスタに格納される
- そのデータをメモリやポートなどに出力する
レジスタには色々な種類がある。IA32 では下記の様な感じだ。なお、プレフィックスとして E が付いているのは元々 16bit 時代に AX とか BX とかだったものが 32bit に Extend されて E が付いている模様である。64bit だと R になっている。 R が何を示しているのかは知らない(ぉぃ)。
- 汎用レジスタ
- EAX、EBX、ECX、EDX、ESI、EDI、EBP、ESP
- セグメント・レジスタ
- CS、DS、SS、ES、FS、GS
- フラグレジスタ
- EFLAGS
- 命令ポインタ
- EIP
実際には汎用レジスタの使い方が分かっていればほぼ問題ない様に思う。レジスタの種類と使い方を解説していると日が暮れてしまうので、気になる人は本やサイトなどで調べてみて欲しい。参考書籍・文献の章が参考になると思う。大事なのはメモリからレジスタにデータを移して、そこで演算を行うという事だ。
一応、よく使う大事な esp について軽く触れておくと、これはスタックの先端のメモリアドレスを示している。push するとマイナスされ、pop するとプラスされる。詳しくは後で説明する。
アセンブリを書いてみる
目的地を定める
一通り命令が分かったところで、これらの命令を使って以下の様な事ができれば、とりあえず何となく処理の流れとして本質的なものができているのではないだろうか。
- 何らか条件分岐を伴う
- プロシージャに引数を与えて返り値を取得する
- メモリを確保してその領域のデータを読んだり、書き込んだりする
- システムコールを行う
という訳で、これをアセンブリで書いてみたいと思う(IO は行っていないが、メモリの読み書きとそこまで違わないと思う)。
Mac のアセンブラをインストール
Mac で使えるアセンブラには GAS や NASM といったものがある様だ。
アセンブラと言っても、ニーモニックだけが全てではなく、細かい文法が違っている様である。様である、と書いたのは、ASM386 と NASM ではニーモニックは全て一緒なのか?とか、微妙な質問に答えられるだけの情報収集ができなかったためである。詳しい人に教えてもらいたい…。ニーモニックは CPU アーキテクチャを策定した段階でこれを使え!と言われている様なものなのか、あるいはアセンブラ実装者がアーキテクチャごとに決めていっているものなのか、調べたがよく分からなかった。
とは言え、GAS が AT&T 構文で NASM が Intel 構文という事くらいは分かった。Intel の CPU を使っているんだからおとなしく NASM にしておこう(笑)今回の主眼は別に個別のアセンブラに詳しくなる事ではないので、そこはどうでもよいのです。という訳で、NASM をインストールしてみる。
$ brew install nasm
$ nasm -v
NASM version 2.13.01 compiled on May 2 2017
とりあえずインストールできた。
基本的な構文について学ぶ
さて、インストールはできたので実際に書きたいところだが、基本的な構造について理解しておく必要がある。マクロな視点では、理解しておくべき要所は下記の様な事だと考えている。
- プログラムを構成する要素にはおおよそ2つあり、データ(DATA / BSS)とロジック(TEXT)である
- 数値や文字列など初期値のあるデータは DATA に、初期値のないデータ(変数)は BSS に、ロジックは TEXT の領域にそれぞれ記述する
- 領域を定義するのは section というキーワードである
- 各行にはラベルを付ける事ができ、ラベルは裏ではその行の命令のアドレスを指す(シンボルとも呼ばれる)
- 外部に公開したいラベル(シンボル)は global キーワードで指定する
- プログラムのエントリポイント(起動して最初に実行されるところ)は _start ラベルで指定する
- ただし OS によってエントリポイントのシンボルは違って、Mach-o では MacOS 10.7 以前だと start、10.8 以降だと _main になる
- データサイズは、byte, word, double word, quad word で表現され、主に「そのポインタからどれだけのデータを対象とするか」を指定するために使われる
- word = 2 bytes
- dword = double word = 2 * 2 = 4 bytes
- qword = quad word = 2 * 4 = 8 bytes
- その他にも tword, oword, yword or zword がある
- プロシージャにジャンプする時に引数を渡したい場合には、スタックに push する
- プロシージャからの返り値は eax レジスタに格納する
- プロシージャ内で ebp レジスタの内容を変更したい場合は先頭で push しておき、最後に pop して戻しておく
- コール元に戻った時に ebp レジスタの内容が変わらない様にしてあげるお作法である
- 値を取り出さなくてもよい pop を連続で行いたい場合は、esp レジスタに add しても同じ事である
- call は、戻ってくるべき命令のアドレスを push した上で jump するので esp が 4 バイトずれるという事は注意しなければいけない
書いていて、「スタック」ってみんな理解しているんだろうか、と思ったが、これを説明するのは結構大変なのでこれも本を読んで理解してもらいたい(ぉぃ)。要所だけ簡単に言うと、後方から先頭に向かって 確保されているメモリ領域で、データを LIFO 形式で保存してローカル変数や引数として利用するものである。後方から先頭に向かって確保するので、push すれば esp はマイナスされるし、pop したらプラスされるという所がミソである。
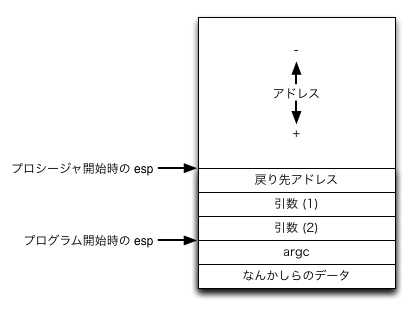
この様に、プログラム開始時の esp は argc を指しており、プログラム中で引数ありの別プロシージャを呼ぶ場合には引数のデータを push する訳だが、そうすると esp がマイナス(スタックが上がるイメージ)されていく。call を呼ぶとプロシージャが終わった際に戻る命令のアドレスが自動的に push されるので、その時にも 4 バイト分上がるイメージだ。そして、ret を呼ぶとそのアドレスを消費して call 元に返ってくるので、その上で引数分 esp を下げる必要がある。おおよそこの様な事が分かっていればアセンブリでもスタックが使える様になると思う。
ミクロな視点で見ると、一行の構成は下記の様な文法になっている。
label: instruction operands ; comment
ラベルとコメントは省略可能、モノによってはオペランドがない場合もある。
という事で、マクロとミクロで理解しておくべき要所は確認したので、最小の構成としては下記の様になると思う(実際には動かないが)。
; 公開したいシンボルを定義する
global start
; TEXT セクションの始まりを定義する
section .text
; start というシンボルを定義する
start:
; DATA セクションの始まりを定義する
section .data
; BSS セクションの始まりを定義する
section .bss
書いてみた
だんだん丁寧に説明するのが困難になってきた(笑)もう、細かいこたぁいいんだよ!という事でとりあえず書いたプログラムを貼ってみる。
global start ; start ラベル(シンボル)は外部から参照可能にする
section .text ; text セクションの開始を定義
start:
cmp dword [esp], 2 ; esp のアドレスから double word (4バイト) 分にあるデータと 2 を比較する
jl .if ; もし 2 未満であれば .if ラベルにジャンプする
jge .else ; もし 2 以上であれば .else ラベルにジャンプする
.if:
call func_1 ; func_1 プロシージャを呼ぶ(戻り先アドレスが自動でスタックにプッシュされる)
jmp .end_if ; .end_if ラベルにジャンプする
.else:
call func_2 ; func_2 プロシージャを呼ぶ(戻り先アドレスが自動でスタックにプッシュされる)
.end_if:
push dword eax ; eax レジスタの内容をスタックにプッシュする
mov eax, 0x1 ; eax レジスタに 1 を入れる
sub esp, 4 ; esp レジスタから 4 を引く(Mac のシステムコール時のおまじない)
int 0x80 ; システムコールを行う
console:
push dword ebp ; ebp レジスタの内容をスタックにプッシュする。esp レジスタが -4 されるので注意
mov ebp, esp ; esp レジスタの内容を ebp レジスタに入れる
push dword [ebp + 12] ; システムコール引数のメッセージの長さをスタックにプッシュする
push dword [ebp + 8] ; システムコール引数のメッセージのアドレスをスタックにプッシュする
push dword 1 ; システムコール引数の 1(標準出力)をスタックにプッシュする
mov eax, 4 ; システムコール番号の 4 を eax レジスタに入れる
sub esp, 4 ; esp レジスタから 4 を引く(Mac のシステムコール時のおまじない)
int 0x80 ; システムコールを行う
add esp, 16 ; push した引数とおまじないをスタックから消す
pop ebp ; ebp レジスタの内容をプロシージャ開始時と同じ状態に戻す(作法)
ret
func_1:
push dword hello_world_len ; "Hello World!" の長さをスタックにプッシュする
push dword hello_world ; "Hello World!" のアドレスをスタックにプッシュする
call console ; console プロシージャを呼ぶ(戻り先アドレスが自動でスタックにプッシュされる)
add esp, 8 ; push した引数をスタックから消す
mov eax, 1 ; プロシージャの返り値として 1 を eax レジスタに入れる
ret ; call 元に戻る
func_2:
push dword good_night_world_len ; "Goodnight baby." の長さをスタックにプッシュする
push dword good_night_world ; "Goodnight baby." のアドレスをスタックにプッシュする
call console ; console プロシージャを呼ぶ(戻り先アドレスが自動でスタックにプッシュされる)
add esp, 8 ; push した引数をスタックから消す
mov eax, 2 ; プロシージャの返り値として 2 を eax レジスタに入れる
ret ; call 元に戻る
section .data ; data セクションの開始を定義
hello_world: db "Hello World!", 10 ; hello_world というラベルに、文字列のアドレスを入れる
hello_world_len: equ $ - hello_world ; hello_world_len というラベルに、文字列の長さを入れる
good_night_world: db "Goodnight baby.", 10 ; good_night_world というラベルに、文字列のアドレスを入れる
good_night_world_len: equ $ - good_night_world ; good_night_world_len というラベルに、文字列の長さを入れる
section .bss ; bss セクションの開始を定義
; 今回は初期値未定義のメモリは確保しない事にした
どういうプログラムかと言うと、コマンドライン引数の数が 2 つ以上なら Goodnight baby. を出力し、そうでなければ Hello World! を出力するというものだ。内容的には別にどうという事はないが、目的地として定めた動作は含めてある。ただ、これはアセンブリ素人が書いているので、おかしな事をしている可能性は大いにあるという点は注意してもらいたい。
何故コマンドライン引数で何か数値を渡さないのか?という疑問があると思うが、実はコマンドライン引数の値を取得するのは結構大変なのだ。というか、厳密な仕様が分からなかったので諦めたという経緯がある。分かっているのは、起動時点の esp から 4 バイトに、argc(引数の数)が入っているという事だ。どうやってこれを確認したのかは、次に記す。
メモリとレジスタの内容を見る
ここではメモリとレジスタの内容を見る方法を書いてみる。やり方としては、ざっくり言うとこんな感じだ。
- int 3 命令でブレークポイントを定義する
- ブレークポイントを定義したプログラムを lldb から実行する
- lldb で実行したら、vmmap でそのプロセス番号を見る
ということで、先ほどのプログラムの start: ラベルの直後に int 3 を入れてコンパイル、lldb で実行する。
# nasm でコンパイル。macho32 で 32bit 想定でコンパイルする。
$ nasm -f macho32 -o sample.o sample.asm
# ld で実行ファイルを作る
$ ld -o sample.out sample.o
# lldb で上記で作った実行ファイルを指定
$ lldb sample.out
(lldb) target create "sample.out"
Current executable set to 'sample.out' (i386).
(lldb) r
Process 12832 launched: '/Users/dora_gt/sample.out' (i386)
Process 12832 stopped
* thread #1, stop reason = EXC_BREAKPOINT (code=EXC_I386_BPT, subcode=0x0)
frame #0: 0x00001f9d sample.out`start + 2
sample.out`start:
-> 0x1f9d <+2>: cmpl $0x2, (%esp)
0x1fa1 <+6>: jl 0x1fa5 ; start.if
0x1fa3 <+8>: jge 0x1fac ; start.else
sample.out`start.if:
0x1fa5 <+0>: calll 0x1fd6 ; func_1
Target 0: (sample.out) stopped.
(lldb)
# 以下は別ターミナルで実行する
# プロセスが 12832 だと分かったので、vmmap で見てみる
$ vmmap 12832
2017-09-24 02:52:18.426 vmmap32[12981:1885438] *** task_malloc_get_all_zones: couldn't find libsystem_malloc dylib in target task
2017-09-24 02:52:18.427 vmmap32[12981:1885438] *** task_malloc_get_all_zones: couldn't find libsystem_malloc dylib in target task
Process: sample.out [12832]
Path: /Users/dora_gt/sample.out
Load Address: 0x1000
Identifier: sample.out
Version: ???
Code Type: X86
Parent Process: debugserver [12833]
Date/Time: 2017-09-24 02:52:18.420 +0900
Launch Time: 2017-09-24 02:49:17.861 +0900
OS Version: Mac OS X 10.12.6 (16G29)
Report Version: 7
Analysis Tool: /Applications/Xcode.app/Contents/Developer/usr/bin/vmmap32
Analysis Tool Version: Xcode 9.0 (9A235)
----
Virtual Memory Map of process 12832 (sample.out)
Output report format: 2.4 -- 32-bit process
VM page size: 4096 bytes
==== Non-writable regions for process 12832
REGION TYPE START - END [ VSIZE RSDNT DIRTY SWAP] PRT/MAX SHRMOD PURGE REGION DETAIL
__TEXT 00001000-00002000 [ 4K 4K 0K 0K] r-x/r-x SM=COW /Users/dora_gt/sample.out
__LINKEDIT 00003000-00004000 [ 4K 4K 0K 0K] r--/r-- SM=COW /Users/dora_gt/sample.out
__TEXT 00004000-0003f000 [ 236K 232K 4K 0K] r-x/rwx SM=COW /usr/lib/dyld
__LINKEDIT 00068000-0007d000 [ 84K 84K 0K 0K] r--/rwx SM=COW /usr/lib/dyld
STACK GUARD bc000000-bf800000 [ 56.0M 0K 0K 0K] ---/rwx SM=NUL stack guard for thread 0
shared memory ffff0000-ffff1000 [ 4K 4K 4K 0K] r--/r-- SM=SHM
shared memory ffff7000-ffff8000 [ 4K 4K 4K 0K] r-x/r-x SM=SHM
==== Writable regions for process 12832
REGION TYPE START - END [ VSIZE RSDNT DIRTY SWAP] PRT/MAX SHRMOD PURGE REGION DETAIL
__DATA 00002000-00003000 [ 4K 4K 0K 0K] rw-/rw- SM=COW /Users/dora_gt/sample.out
__DATA 0003f000-00042000 [ 12K 12K 12K 0K] rw-/rwx SM=COW /usr/lib/dyld
__DATA 00042000-00068000 [ 152K 8K 8K 0K] rw-/rwx SM=PRV /usr/lib/dyld
Stack bf800000-c0000000 [ 8192K 20K 20K 0K] rw-/rwx SM=PRV thread 0
==== Legend
SM=sharing mode:
COW=copy_on_write PRV=private NUL=empty ALI=aliased
SHM=shared ZER=zero_filled S/A=shared_alias
PURGE=purgeable mode:
V=volatile N=nonvolatile E=empty otherwise is unpurgeable
==== Summary for process 12832
ReadOnly portion of Libraries: Total=328K resident=324K(99%) swapped_out_or_unallocated=4K(1%)
Writable regions: Total=8344K written=28K(0%) resident=28K(0%) swapped_out=0K(0%) unallocated=8316K(100%)
VIRTUAL RESIDENT DIRTY SWAPPED VOLATILE NONVOL EMPTY REGION
REGION TYPE SIZE SIZE SIZE SIZE SIZE SIZE SIZE COUNT (non-coalesced)
=========== ======= ======== ===== ======= ======== ====== ===== =======
STACK GUARD 56.0M 0K 0K 0K 0K 0K 0K 2
Stack 8192K 20K 20K 0K 0K 0K 0K 2
__DATA 168K 24K 20K 0K 0K 0K 0K 4
__LINKEDIT 88K 88K 0K 0K 0K 0K 0K 3
__TEXT 240K 236K 4K 0K 0K 0K 0K 3
shared memory 8K 8K 8K 0K 0K 0K 0K 3
=========== ======= ======== ===== ======= ======== ====== ===== =======
TOTAL 64.5M 376K 52K 0K 0K 0K 0K 11
VIRTUAL RESIDENT DIRTY SWAPPED ALLOCATION BYTES DIRTY+SWAP REGION
MALLOC ZONE SIZE SIZE SIZE SIZE COUNT ALLOCATED FRAG SIZE % FRAG COUNT
=========== ======= ========= ========= ========= ========= ========= ========= ====== ======
見て欲しいのは、_TEXT セクションがこの領域にあり、_DATA セクションはこの領域で Stack はこの領域で、という情報が書き出されているという事だ。試しに、sample.out の _DATA セクションのアドレスである 00002000 を lldb で見てみるとこうなる。先ほどの lldb のコンソールに戻る。
(lldb) memory read 0x00002000
0x00002000: 48 65 6c 6c 6f 20 57 6f 72 6c 64 21 0a 47 6f 6f Hello World!.Goo
0x00002010: 64 6e 69 67 68 74 20 62 61 62 79 2e 0a 00 00 00 dnight baby.....
ほれほれ。さっきアセンブリで .data セクションに定義した文字列が入っていますよ。やばいですよね、これ。超楽しくないですか?(笑)では次に Stack を見たいのですが、結構色々データが入っていて見にくいのです。ピンポイントで、このプログラムが実行されている時のスタックの先頭を見てみるには、esp レジスタに入っている値のあたりを見ればよいはずです。なので、こんな感じにしてみます。
(lldb) register read esp
esp = 0xbffff95c
(lldb) memory read 0xbffff95c
0xbffff95c: 01 00 00 00 24 fa ff bf 00 00 00 00 49 fa ff bf ....$���....I���
0xbffff96c: 95 fa ff bf cc fa ff bf e0 fa ff bf f1 fa ff bf .���������������
(lldb)
ここでよく見て頂きたいのですが、先頭 4 バイトが 01 になっていますよね。これが、引数を 2 つ 3 つと増やしていくと、それに応じて増加します。つまり、起動時の esp〜4 バイト分が argc だと分かります(厳密には仕様を調べたいところだが、時間がなかった)。という訳で、この値を使って分岐するプログラムを書いてみたのが、先ほどのサンプルプログラムだ。
システムコール
サンプルプログラムだと、1)標準出力に書き出す、2)実行結果を返す、というあたりはシステムコールになっている。システムコールをする時の作法はだいたいプロシージャ呼び出しと変わらないのだが、こんな感じだ。
- 引数のデータをスタックに push する
- eax レジスタにシステムコール番号を入れる
- esp を 4 つ進める(マイナスする)
- 0x80 で int する
- push した分 pop するか esp をプラスする
システムコール番号は、syscalls が参考になる。esp を 4 つ進めなければいけない理由は謎だ。MacOS のシステムコール時の作法という事になっている様だ。0x80 の割り込み処理でシステムコールを実行した後で、引数としてスタックに push したデータは pop しておかなければならない。
Xcode で書く
ここでは全て単体のコマンドでコンパイルしたりメモリを見たりしたが、Xcode でもできる様だ。詳しくはこちらの記事を見て欲しい。Xcodeでx86アセンブリを書く
おわり
細かい事を言うと色々説明していない部分があるのだが、参考書籍・文献で書いたものを見ればほぼ分かるはずだ。理解するためのキーみたいなものは書いたつもりである。すいません。頑張って全部説明しようと思ったのだが、思いの外説明しなければいけない事が多くて、このままでは100年経っても終わらないと思ったので割と雑な感じで終わろうとしています😂
眠い。3日ほどこの記事を書いていて、だいぶ疲れた。完璧なクオリティとは言えないのだが、この辺にさせて頂きたいと思います。
分からなかった事
ld -e
$ ld -e main hoge.o
といった形で -e オプションでエントリポイントのシンボルを指定できるが、これが何故できるのか分からなかった。MacOS 10.7 までは LC_UNIXTHREAD が、10.8 からは LC_MAIN が起動の処理を行っているという所までは分かったが、どちらにしても何故リンカからエントリポイントを変更できるのかが分からなかった。外部からはシンボルテーブルを見て、特定のシンボルのアドレスから実行を開始するものだと思っているが、だとするとリンカからエントリポイントのシンボルを指定できる意味が分からない。詳しい方に教えて頂きたい…。
MacOS のシステムコール時の謎のスタック空白領域
MacOS でシステムコールを行う時にスタックポインタを謎に4バイト分下げなければならない。このサイトでは OS X (and BSD) system calls needs "extra space" on stack と説明されているが、おまじないチックであまり納得できるものではなかった。できれば理由が知りたいものである。
参考書籍・文献
- コンピュータの構成と設計 上
- コンピュータの構成と設計 下
- プログラムはなぜ動くのか
- IA-32 インテル® アーキテクチャ ソフトウェア・デベロッパーズ・マニュアル 上巻:基本アーキテクチャ
- IA-32 インテル® アーキテクチャ ソフトウェア・デベロッパーズ・マニュアル 中巻 A:命令セット・リファレンス A-M
- IA-32 インテル® アーキテクチャ ソフトウェア・デベロッパーズ・マニュアル 中巻 B:命令セット・リファレンス N-Z
- IA-32 インテル® アーキテクチャ ソフトウェア・デベロッパーズ・マニュアル システム・プログラミング・ガイド
- GAS と NASM を比較する
- NASM - The Netwide Assembler
上記は一般的によく参考にされている本と、個人的に参考にさせてもらった本、PDF、サイトのリストである。低レイヤーに触れた事がない人は読んでおいて損はないと思う。