先月の7/24に、GoogleからCloud Auto ML Natural Languageというものがリリースされました。
http://www.itmedia.co.jp/news/articles/1807/25/news066.html
ページの後半で、Natural Languageを触った感触などを書いています。
このCloud Auto MLというのは何かと言うと、ほぼGUIだけで機械学習したモデルを作ることができるサービスの総称で、その中にNatural Language(自然言語)、Translation(翻訳)、Vision(画像認識)というものがあります。
それぞれのサービスの役割
Natural Language
NLと銘打っておきながら、できることはテキストデータのカテゴライズです。
テキストとラベルの組み合わせをCSVなどで用意して、アップして数クリックするだけで、学習されたモデルが作成されるサービスです。

Translation
これは翻訳用のML自動化サービスです。機械翻訳をするために、テキストと翻訳データを用意して、自分のデータセットで学習させることができます。
Vision
これは画像が何であるか、というカテゴライズをするための仕組みです。
画像の中の物体検知ではなく、あくまで一つの画像に対するラベリングですね。
さて、NLを実際に使ってみたよ
某HKのニュースのRSSデータを取得して、それぞれもともとのカテゴリをラベル付けして、カテゴライズできるかをテストしました。
APIの有効化
まずプロジェクトに対してAuto ML NLを使うために、APIを有効化します。
ワンクリックで自動でやってくれるボタンもありましたが、なかなか時間がかかっていたので、その横にあるマニュアル設定のボタンから、指示通りにAPIを有効化しました。
学習用CSVの用意
他にもやり方ありますが、CSVを使ってデータを登録する方法を書いていきます。
実は一番困ったのはここで、公式ドキュメントに「どんな形式のデータを用意すればいいか」という具体例がないという。英語だけだったので不安でしたが、想像はできたのでなんとか作ることができました。
なのでここには具体例を書きますが、こんな形でデータトラベルの対のCSVを用意します。
"こんにちは、電気グルーヴです。電気で作る、グルーヴです。", denki
"僕は音楽家、電卓片手に足したり引いたり操作して作曲する", kraftwerk
"君に、胸キュン。浮気な夏が僕の方に手をかけて", ymo
"このボタン押せば、音楽奏でる", kraftwerk
"誰だ!ゴクミに似てるのは", denki
"日本でも放射能、今日もいつまでも", kraftwerk
"俺のビデオを消したやつは誰だ!", denki
...
ポイントは
- 1カラム目にテキストデータ、2カラム目にラベルデータ
- ラベルデータはマルチバイト文字を受け付けない
- データは20以上、100,000以下
- ラベルの種類は2以上、100以下
- ラベルあたりのコンテンツは最低10データ
これを守ればOK。
GCSへのアップロード
他にもやり方あります。が、これが一番早い?
APIの有効化セクションで、GCSのバケットも作ったと思いますが、そのバケットに作ったCSVを入れます。
+ NEW DATASETからデータを作る

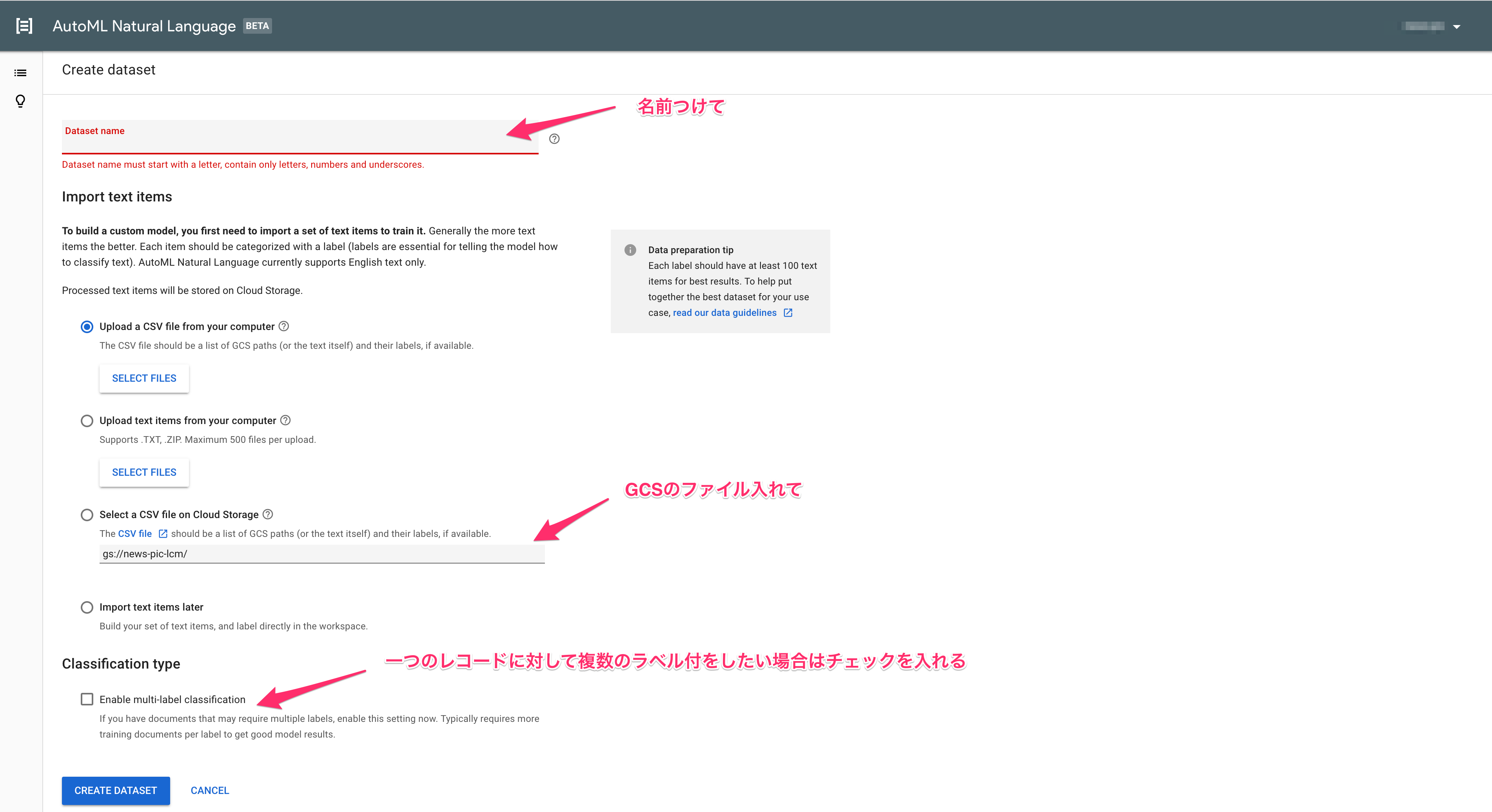
これで「CREATE DATASET」を押せばデータのインポートが始まります。
1000件のデータだけでも2時間位かかりました…
データがインポートできたらトレーニング開始
データのインポート後に、重複したデータを削除したと言うようなメッセージがあり、データのチェックもやってくれているようでした。
そのため1000件のデータが668件に。
作成されたモデルをクリックして、TRAINタブに移動します。
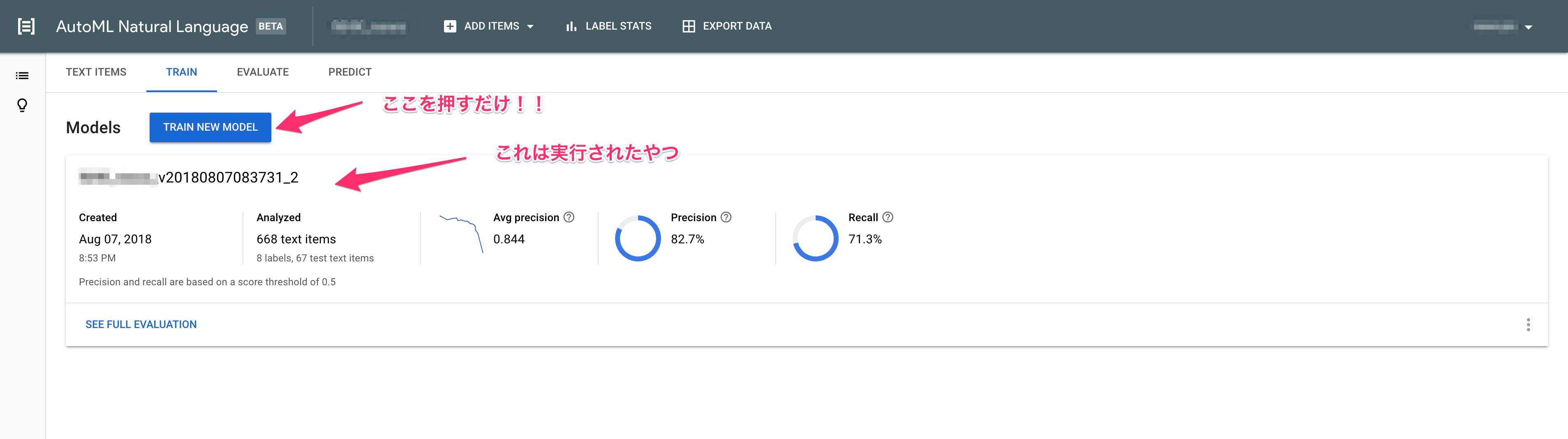
さて、ここで待ちます。
待ちます
。
5時間くらい待ちます。
パチンコにでも行くか、Netflixでドラマを1シーズンまるっと見て気長に待ちましょう。
モデルのテスト
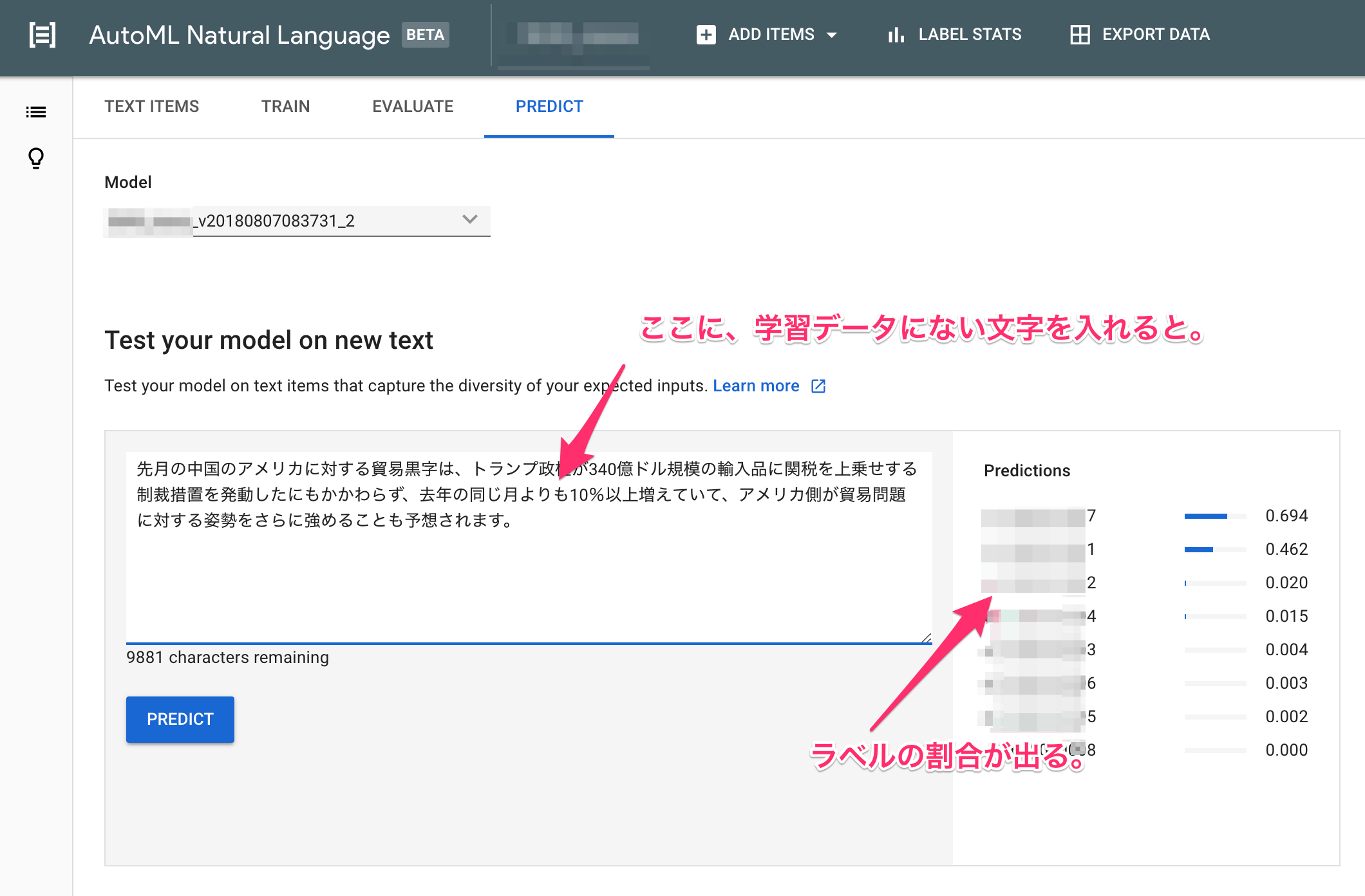
使ってみた感想
700件弱のニュースデータのカテゴライズ(8ラベル)の学習を試してみましたが、2時間無料とは言え、1回の学習で1000円を越えました。
word2vecとKerasで自分で学習させたモデルも、同じデータのカテゴライズでは8割くらいの精度が出ていましたが、自分であれやこれやニューラルネットを試行錯誤して作っていくよりも安定しているのかなぁとは思いました。
AutoML Natural Languageでは、1つのInput、1つのOutputという感じのモデルになるので、InputやOutputの多いネットワークなどを作りたい場合などは、やはりまだ自前で組まないといけないようです。
まだまだこれから注視していきたいですね!