やること
二次元の散布図をクラスタリングしたい場面が個人的によくあります。Rでは、kmean関数にデータフレームとクラスター数を入れてしまえば良いのですが、クラスター数の設定や初期値のあれやこれやが。そういった場合にk-means的なノリでlouvain法を用いる際の覚書。
散布図から隣接行列を作り、グラフにしてから、louvain法でクラスター抽出をします。
データはkaggle(https://www.kaggle.com/c/digit-recognizer/data )からMNISTをダウンロードして使ってみます。
下処理
データを読み込みます。
tidyverseはマストではないです。
library(tidyverse)
mnist <- read_csv("~/train.csv")
lab <- mnist %>% pull(label)
mnist <- mnist %>% select(-label)
データ数が42000個と結構多くて大変なので、適当に1割くらい抽出して使います。
idx <- sample(1:nrow(mnist),0.1*nrow(mnist))
lab <- lab[idx]
mnist <- mnist[idx,]
二次元の散布図のクラスタリングを想定しているので、mnistを二次元に次元圧縮します。
ここではUMAPを使います。
um <- uwot::umap(mnist)
プロットしてみます。色はラベルで。
tab <- um %>%
as_tibble() %>%
rename(UMAP1=1,UMAP2=2) %>%
mutate(label=as_factor(lab))
tab %>%
ggplot(aes(UMAP1,UMAP2,color=label)) +
geom_point(size=.6,alpha=.6) +
theme_minimal() + coord_fixed()
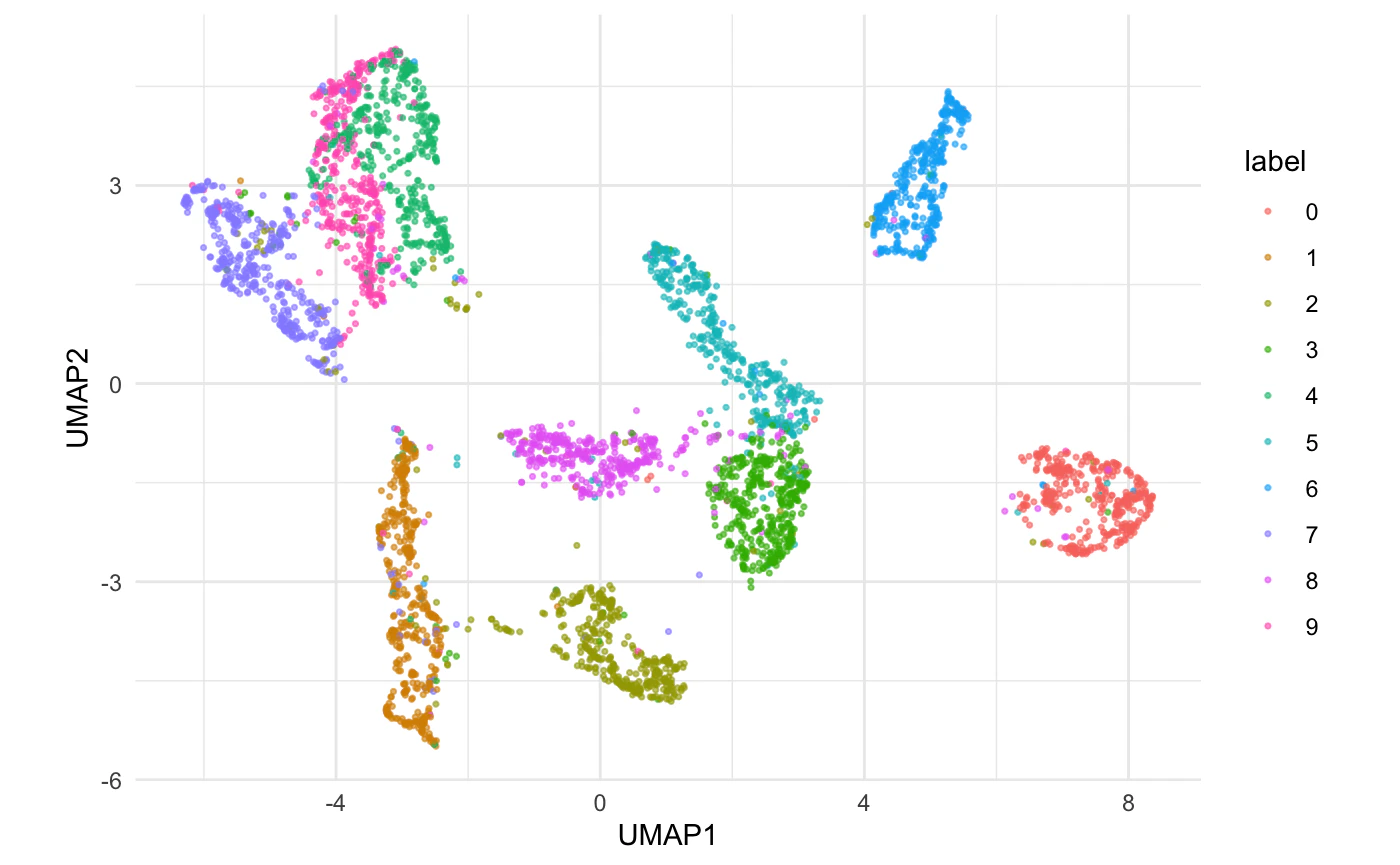
クラスタリング
louvain法はigraph::cluster_louvainで実装されていますが、入力がグラフなので、先ほどの散布図をグラフにしてから、この関数に入れます。
まず、座標(→距離行列)→隣接行列
d <- dist(um)
adj <- as.matrix(d)<1.5
距離が1.5より近いデータ点同士を結んだ隣接行列を作っています。
ここの閾値の設定はもっと適切な方法がありそうです。
次に、隣接行列→グラフにしてから、クラスター抽出。
グラフにする際は、mode='undirected'で無向グラフに設定する必要があります。
g <- igraph::graph_from_adjacency_matrix(adj,mode='undirected')
lou <- igraph::cluster_louvain(g)
抽出したクラスターで色分けしてプロットしてみます。
クラスタリングの結果は、membershipに格納されています。
tab %>%
mutate(cluster=paste0('C',lou$membership)) %>%
ggplot(aes(UMAP1,UMAP2,color=cluster)) +
geom_point(size=.6,alpha=.6) +
theme_minimal() + coord_fixed()
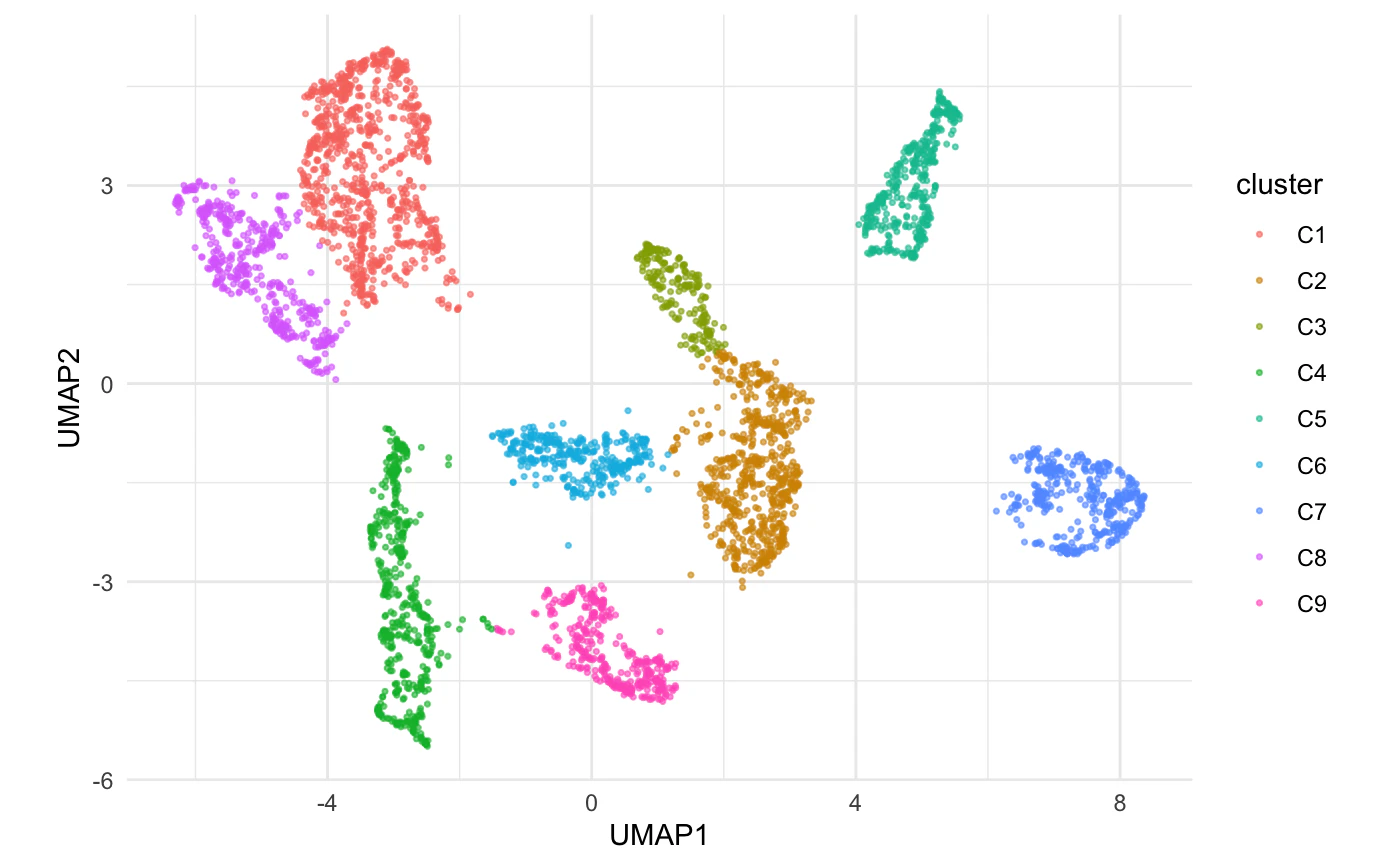
いい感じです。
まとめ
louvain法はk-meansとかと比べてロバストで直感にあったクラスタリングしてくれるので好きです(こなみ)。
以下データと閾値を引数に入れるとfactorの行列でクラスター番号を返す形でまとめたものです。
louvain <- function(mat,cut,membership=T){
D <- as.matrix(dist(mat))
g <- igraph::graph_from_adjacency_matrix(D<cut,mode='undirected')
Lou <- igraph::cluster_louvain(g)
res <- as.factor(Lou$membership)
Nc <- length(levels(res))
cat(paste0(Nc," clusters\n"))
if(membership){
return(res)
}else{
return(Lou)
}
}