前書き
こんにちは。LAPRAS Advent Calendar 2020 13日目担当のdonaldchiです。
今回は観点感情分析(Aspect Based Sentiment Analysis, ABSA)分野で珍しく感情表現抽出とその極性判定を同時に学習したモデルがあったので紹介したいと思います。さらに、ネット上に感情分析のモデルは多く存在するものの、日本語で学習して見たよう的なポスティングがなかったので、モデル紹介の続きで日本語の評判データを用いてやった実験結果を述べたいと思います(ましたが、文章が長くなり、日本語実験の話は別途記事を書くことにしました)。
日本語の口コミ分析、商品評判分析モデル構築の時に何らかのヒントを与えることができると嬉しいです。
論文情報
@article{yang2019multi,
title={A multi-task learning model for chinese-oriented aspect polarity classification and aspect term extraction},
author={Yang, Heng and Zeng, Biqing and Yang, JianHao and Song, Youwei and Xu, Ruyang},
journal={arXiv preprint arXiv:1912.07976},
year={2019}
}
背景
感情分析は文章から意見、感情、態度を理解するために該当文章の極性(ポジティブ、ネガティブ、ニュートラルのいずれであるか)を判別するタスクです。
**観点感情分析(Aspect Based Sentiment Analysis, ABSA)**は感情分析の一分野であり、文章中の特定単語やフレーズを観点として抽出し、それに対する感情の極性を予測するタスクです。ABSAは感情分析を文単位(sentence-level)、文書単位(document-level)ではなく、観点単位で行うことで、複数の感情を含む文章にも対応します。
例えば、
The dessert at this restaurant is delicious but the service is poor.
というレストランに対するレビューがある場合、ABSAだとdessert#positive, service#negativeのような粒度の高い分析を可能にします。
観点感情分析を行うためにはdessert, serviceのような**感情表現の抽出(Aspect Term Extraction, ATE)とpositive, negative, neutralのような感情表現の極性分類(Aspect Polarity Classification, APC)**というタスクを解く必要があります。
ABSAにおける従来の手法では、ATEとAPC、どれか片方に注目し、解決していくアプローチになっているのに対し、本論文では**local context focus (LCF)**というメカニズムを導入することで、両タスクを同時に行うことを可能にしています。さらに、実験では中国語と英語が混ざったデータセットの同時分析も可能であることを証明し、多言語混合データセットでの観点感情分析の可能性も示しています。実験の結果、意味解析ワークショップSemEval 2014のtask4 Restaurant、Laptopデータセットと中国語の商品レビューデータでATE, APCタスク両方ともSOTA(state-of-the-art)を達成しました。
感情分析、特にABSAに対してもっと詳しく調べたい場合は、感情の出どころを探る、一歩進んだ感情解析
、Sentiment Analysis and Opinion Miningなどがおすすめです。
アプローチ
モデル全体像
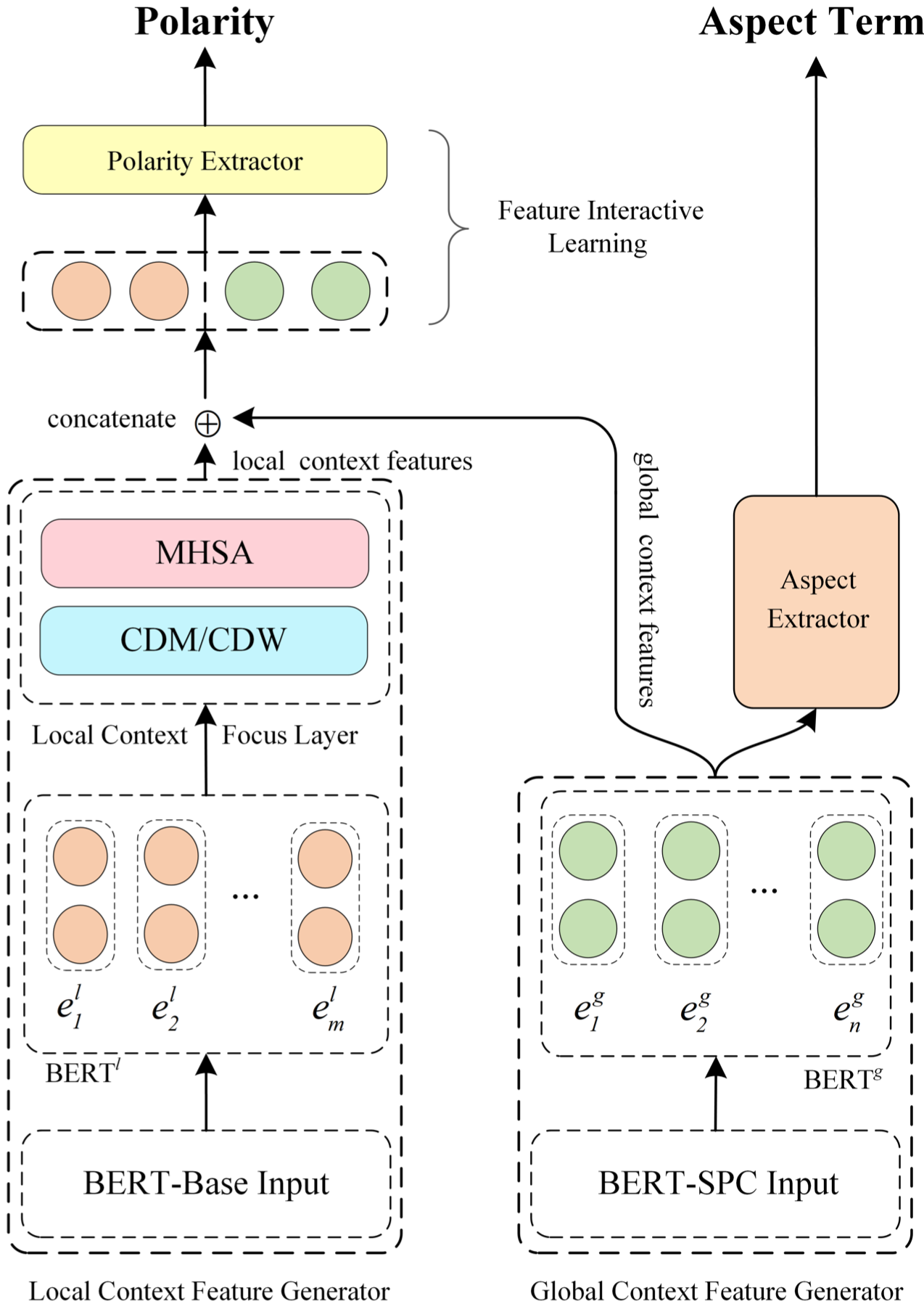
本論文では、上図のような構造をもつLCF-ATEPCというモデルを提案します。
LCF-ATEPCモデルは**Local Context Feature Generator(LCFG)、Global Context Feature Generator(GCFG)、Feature Interactive Learning Layer(FIL layer)**の三つのパーツで構成されます。
GCFGはグローバル文脈を抽出するパーツでBERT層で構成されます。GCFGから得た単語分散表現はグローバル文脈特徴量として極性判定器の入力として使われると共に、感情表現(Aspect Term)抽出器の入力としても使われます。
一方、LCFGの場合はpre-tained BERT層を通した後に、Local Context Focus Layer層で感情表現に関連するローカル文脈情報を抽出します。
FIL層は、LCFGから学習したローカル文脈特徴量とGCFGから学習したグローバル文脈情報を使い、各トークンの極性分類を行います。
BERT-Shared Layer
BERT層はpretained BERTモデルを用いてトークンの分散表現を取得し、それぞれのタスクに合うように$BERT^l$, $BERT^g$層を通してfine-tuningをして行きます。
分散表現変換に使われるpratained BERTモデルとして、LCFGではDevlin(2019)らが最初に提案したbasic BERTモデル(BERT-BASE)そのものを、GCFGは文ペア分類タスク(sentence-pair classification task)に特化されたBERTモデル(BERT-SPC)を使っています。
論文ではGCFGでBERT-BASEよりBERT-SPCを使うことで、APCタスクの精度が向上することがわかったと書いてありますが、その理由については述べていないです。ただ、直感的にBERT-SPCは文ペアタスクに特化して学習したモデルであるため、BERT-Baseよりは広い範囲のグロバール文脈を反映した分散表現になっているからではないかと勝手に浅く解釈しています。
Local Context Focus (メインアプローチ)
本研究では、入力文に複数の感情が含まれることを考え、ローカル文脈(local context)を抽出し、グローバル文脈と共に感情表現の極性分類に使っています。
Semantic-Relative Distance(SRD)
従来の研究ではATEとAPCを分けて処理していたため、aspect termを既知のものとして扱っていました。しかし、LCF-ATEPCではATEとAPCを同時に処理しようとしています。従って、入力文の全トークンがaspect termの候補になります。一方、経験上aspect termのローカル文脈にaspect termと関連する重要な情報が含まれていることが知られています。
以上のことから、本論文では**Semantic-Relative Distance(SRD)**とう概念を定義し、各トークンのローカル文脈の範囲を特定しようとしています。
SRDは、モデル入力文の中、aspect termであろうトークン(token)とそれ以外のトークンの距離を測るものであります。
SRD_i = |i - P_a| - \lfloor \frac{m}{2} \rfloor
- $i$: 入力文中トークンの位置
- $P_a$は感情表現(aspect term)の中間位置 ($a_i$: $i$番目のトークン, $p_i$: $a_i$の位置)
P_a = \begin{cases}
p_i & (感情表現が一つのトークン a_i からなる場合) \\
\frac{\Sigma_{k\in[i,j]} p_k}{(j-i+1)} & (感情表現が複数のトークン(a_i, a_{i+1}, ..., a_j)からなる場合)
\end{cases}
- $m$は感情表現の長さ
LCF-ATEPC法はSRDを用いて、ローカル文脈情報を取得するためのメカニズム: **context-feature dynamic mask (CDM)とcontext-feature dynamic weighting (CDW)**を定義します。
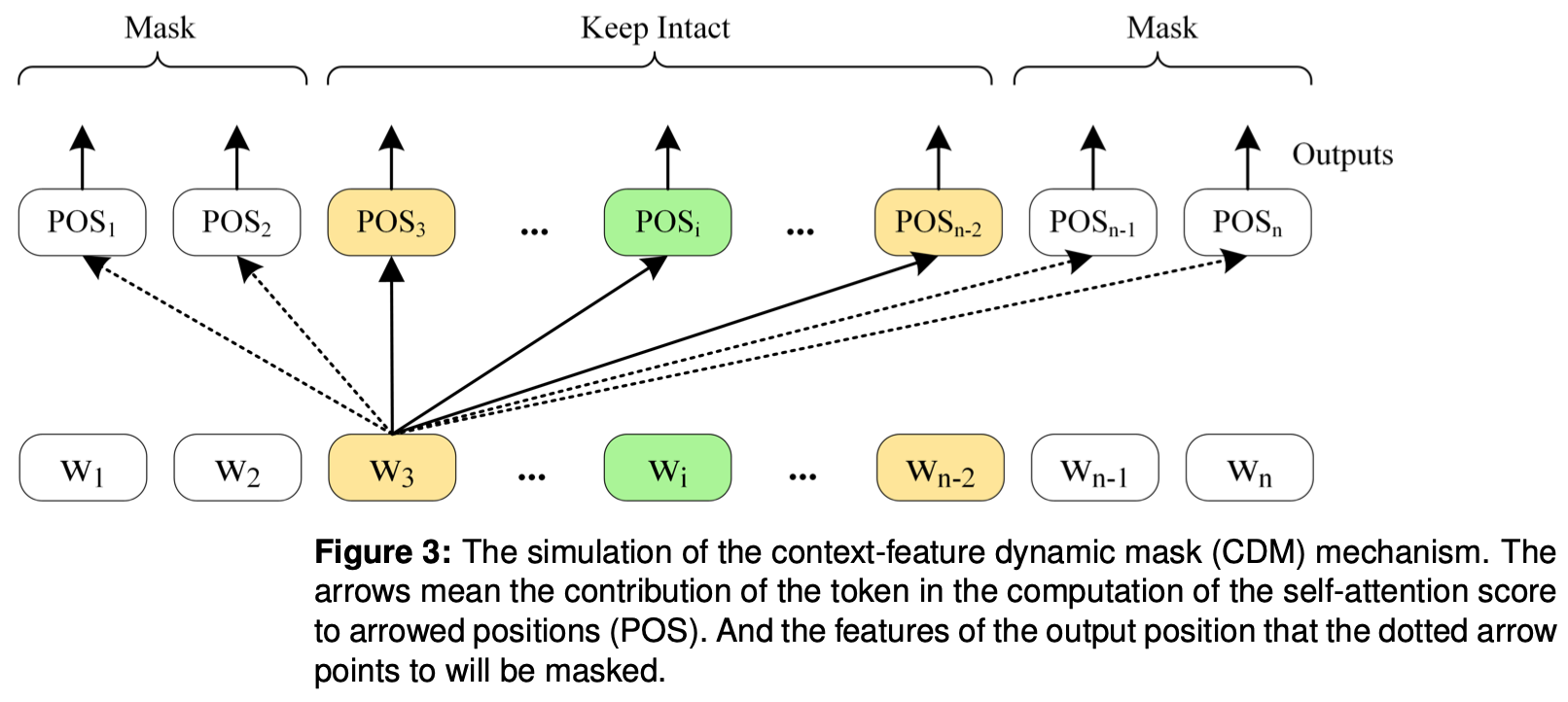
Context-features Dynamic Mask(CDM)
**Context-features Dynamic Mask(CDM)**はBERT層で学習された特徴量のうち、非ローカル文脈情報をもつ特徴量をマスキング(masking)することで、ローカル文脈情報のみを抽出します。
V_i = \begin{cases}
E & SRD_i \le \alpha \\
O & SRD_i \gt \alpha
\end{cases}
M = [V_1^m,V_2^m, ... V_n^m]
具体的に入力されたトークンリストに対して、マスキング行列を作成し、$BERT^l$層の出力にかけることでマスキング処理を行います。マスキング行列の各要素は上の式のように定義されていて、ある特定トークンに注目した場合、一定SRD値(上式中の$\alpha$)以内のトークンに該当するベクトルをones vector(全ての要素が1)に、それ以外のベクトルはzeros vector(全ての要素が0)に設定します。
つまり、トークン$i$との距離: $SRD_i$値が閾値$\alpha$より小さいトークンの場合、ローカル文脈情報をもつトークンとみなし、該当分散表現(正確には$BERT^l$からの出力ベクトル)をそのまま残し、それ以外トークンの分散表現にはzeros vectorを掛けてマスキングするということです。
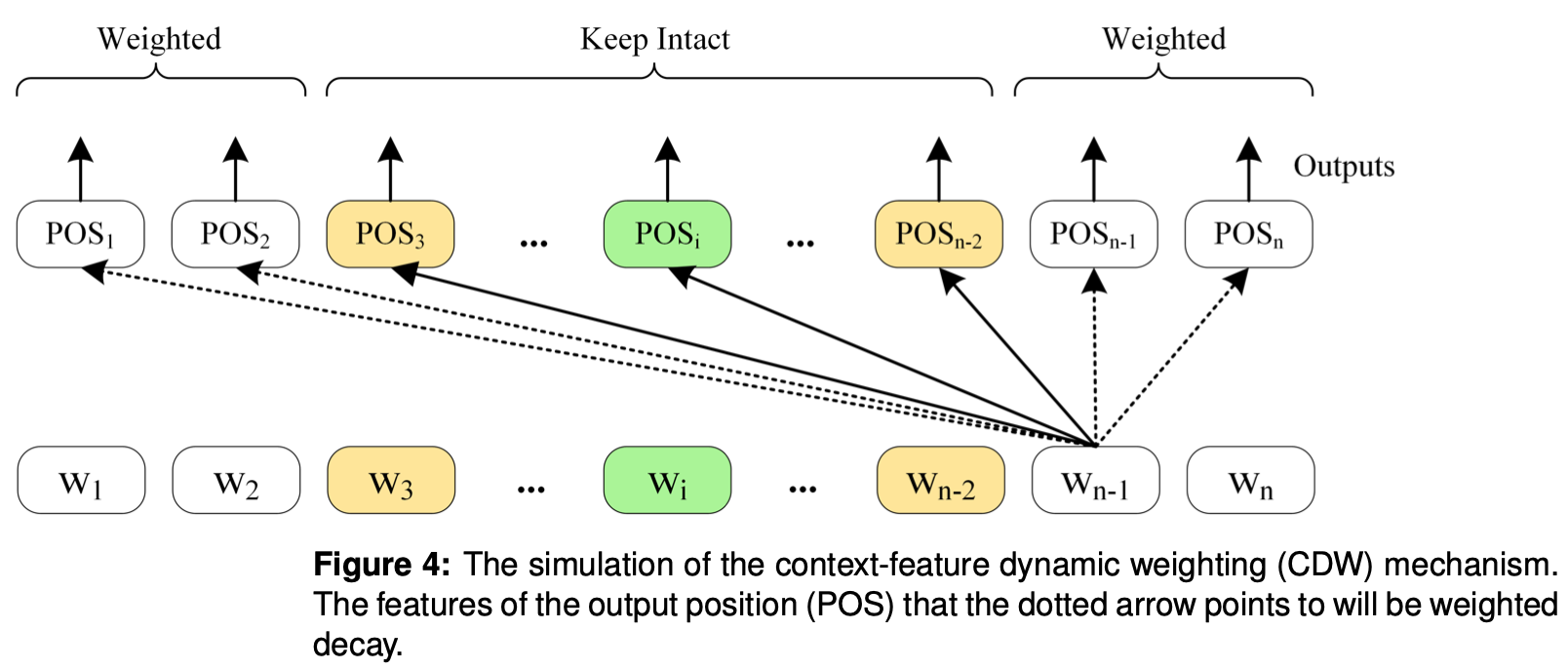
Context-features Dynamic Weighting(CDW)
**Context-features Dynamic Weighting(CDW)**はBERT層で学習された特徴量のうち、非ローカル文脈情報の重みを小さく設定することで、ローカル文脈情報を強調させる戦略をとっています。
V_i = \begin{cases}
E & SRD_i \le \alpha \\
\frac{n - (SRD_i - \alpha)}{n} \times E & SRD_i \gt \alpha
\end{cases}
W = [V_1^w,V_2^w, ... V_n^w]
CDWは非ローカル文脈情報を0にするのではなく、注目されたトークンとの距離SRD値によって減衰する重みを設定することで、非ローカル文脈情報の重みを弱くさせる機構となっています。
ロール文脈情報抽出のために、論文はCDM, CDWのほか、CDMとCDWの結果を連結したFusionという対策もとっています。
MHSA (Multi-Head Self-Attention)
LCFGはCDM/CDWで抽出されたローカル文脈に対し、トークン間の複雑な関係を考慮したMulti-Head Self-Attention機構で処理を行います。具体的に12個のヘットを使用、MHSAの解釈はこちらへ。
Feature Interactive Learning(FIL)
FIL層は、ローカル文脈情報とグローバル文脈情報を連結し、head-pooling処理を行います。head-poolingは入力文の最初のトークンに対応する位置にある特徴量を抽出する処理です。最後に、Polarity Extractor(極性抽出器)でhead-poolingの結果に対して全結合層を挟み、softmax操作をかけることで極性分類を行います。
Aspect Term Extractor (感情表現抽出)
Aspect Term Extractor (感情表現抽出)はトークン間の関係を気にせず、トークン単位で分類を行います。構成的にはPolarity Extractorと変わらず、全結合層 + softmaxとなっています。
実験
提案モデルの有効性を測るために
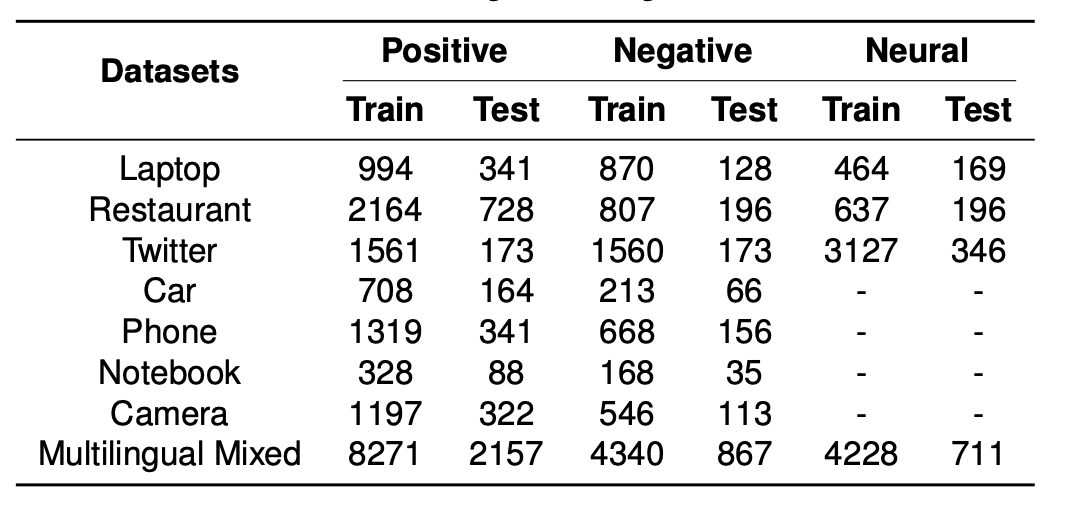
- 意味解析ワークショップで有名なSemEval 2014のデータセット(Laptops, Restaurant, Twitter)
- 中国語の商品レビューデータセット(Car, Phone, Notebook, Camera)
- 英語、中国語データをミックスして自作したデータセット(Multilingual Mixed)
など8つのデータセットに対して
- ATE, APCの精度比較
- ATE, APC単体タスクの効果測定
- Domain-adaption(ドメイン適応) BERT modelの効果測定
- SRDの感度検証
などの実験を行います。
データセット概要
データセットの詳細説明、データフォーマット、各種学習パラメータ、比較手法の詳細は割愛します。
精度比較
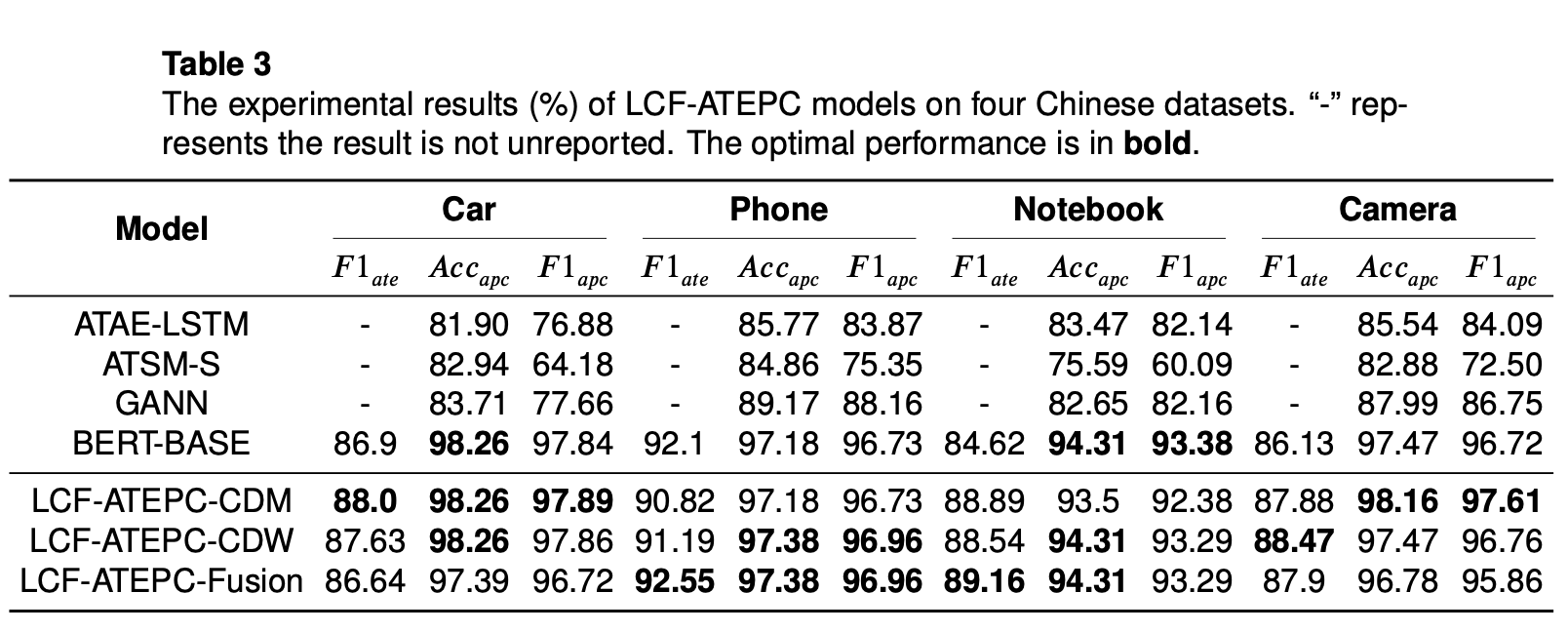
中国語データでの精度比較
英語データとミックスデータでの精度比較
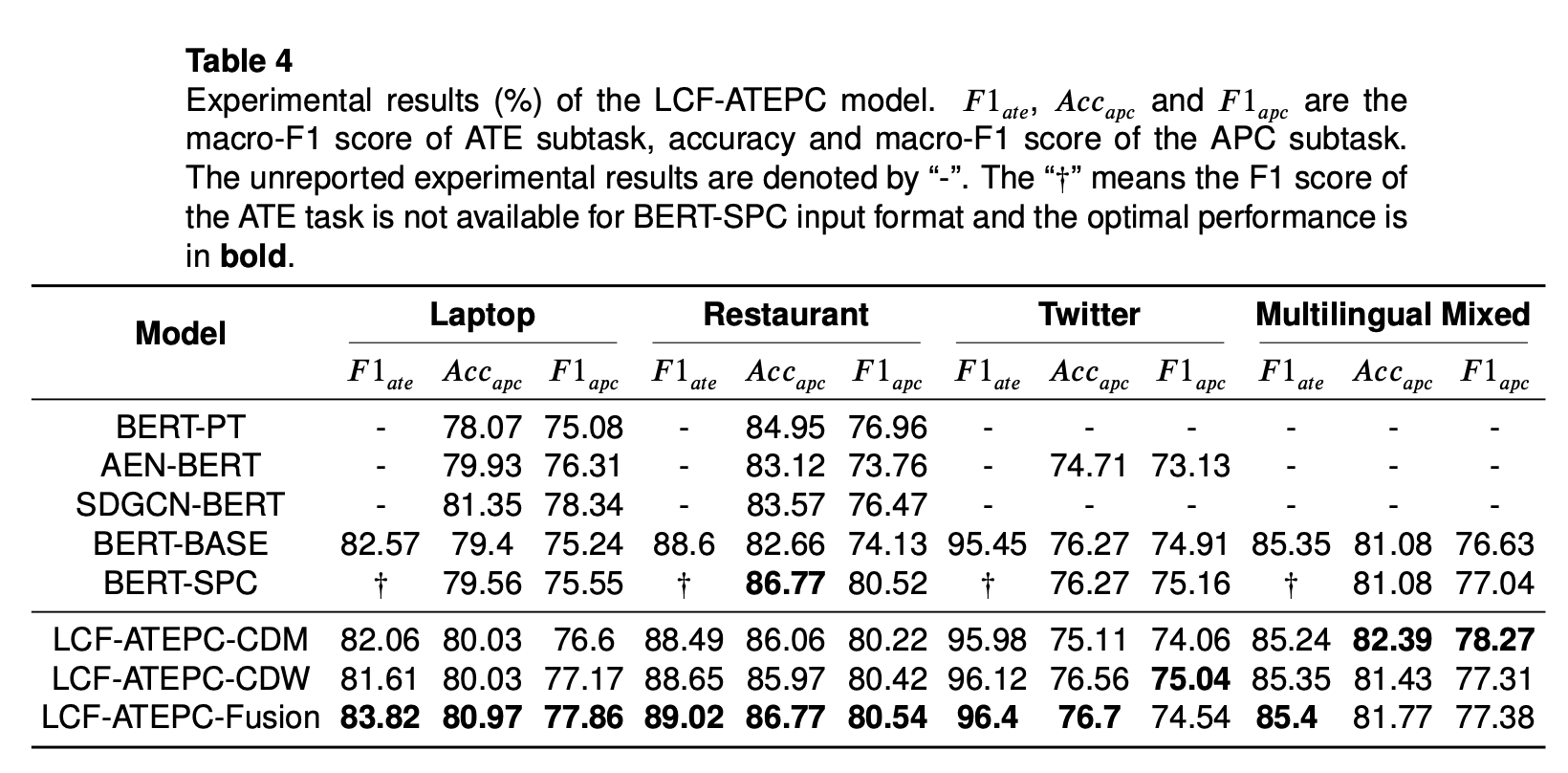
精度比較結果をみると、ローカル文脈抽出でfusion対策をとった方が、大部分の英語データセットにおいてベストな精度を出していることがわかります。一方、場合によってはCDM, CDWの方がより良い精度を出すときもあり、データの特徴によって、ローカル文脈抽出戦略をCDW, CDM, Fusionの中から選ぶ必要があることがわかります。
データの特徴を観察した結果、Phone, Notebookデータは一つのレビューに複数のaspectが含まれている場合、前後aspectで同じ感情を表していて、お互いに影響しあっている傾向であるようです。結果、ローカル文脈抽出で、ローカル文脈以外の情報をマスキング(CDM)するようりは減衰する(CDW)対策を取る方が良い予測結果になっていることがわかります。
上記に関して論文ではLaptop、Restaurantデータを例にあげていましたが、実験結果をみるとLaptop、Restaurantの精度はFUSION > CDM > CDW になっていました。さらに、実験結果からPhone、Notebookデータを観察した結果上のような傾向があったので、論文で間違って書いているのではと思っています。ただ、「ローカル文脈抽出戦略がデータセットの影響を受ける」部分は事実として存在すると思います。
最後に、中国語、英語の混合データセットに対しても高い精度を出していることがわかります。Multilingualに対応できるモデルだよと主張しつづも論文ではMixedデータに対して深ぼっていないです。
単体タスクの効果
上で述べたようにATEとAPC両タスクを同時に行うのがLCF-ATEPC法の特徴です。この実験では、片方のタスクのみに取り込ませた場合の精度をみています。
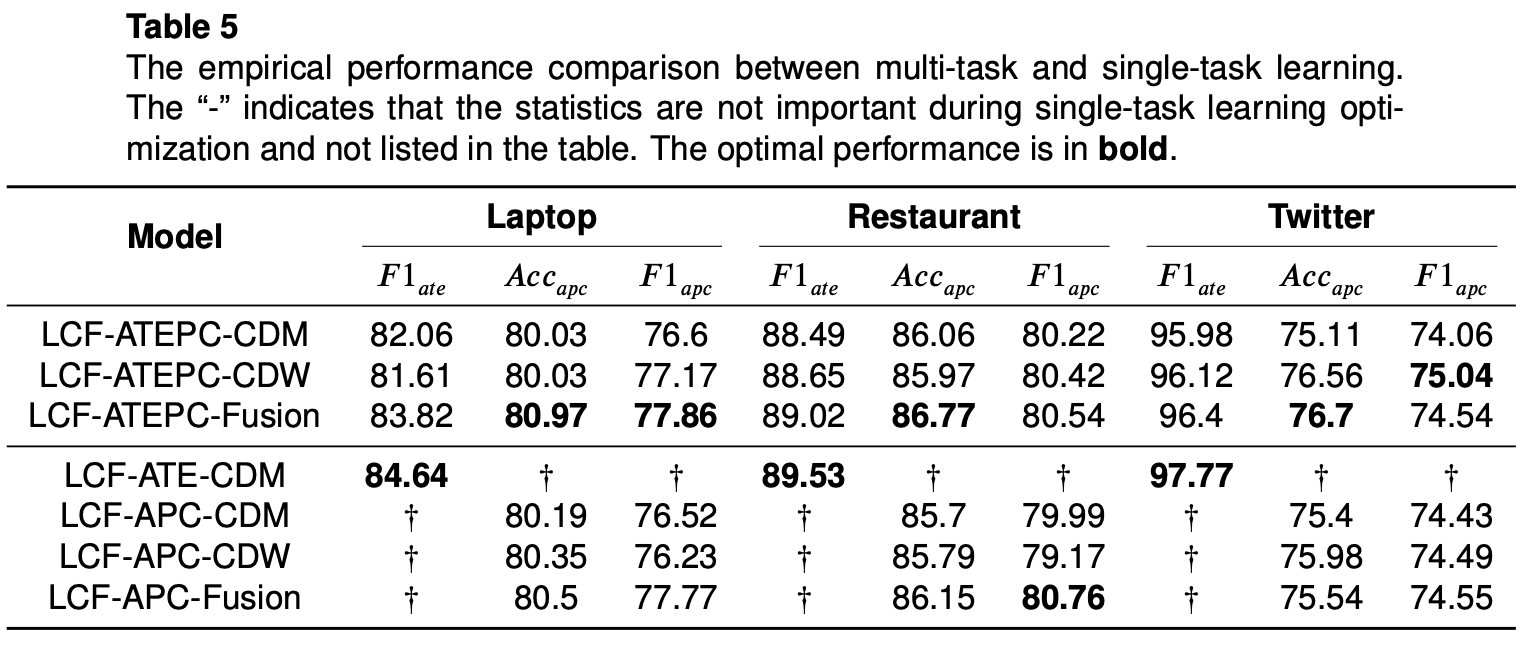
結果、ATEタスクのみに取り込んだ場合、両タスクを同時にやるよりは良い精度を出していることがわかります。一方、APC単体の場合両タスクを同時にやるより精度が低くなる結果となっています。
普通、マルチタスクモデルで各シングルタスクの損失関数を統合しなければならなく、シングルタスクほどよい結果を出さない可能性もあることを考えると納得のいける結果かと思われます。
Domain-adaption(ドメイン適応) BERT modelの効果測定
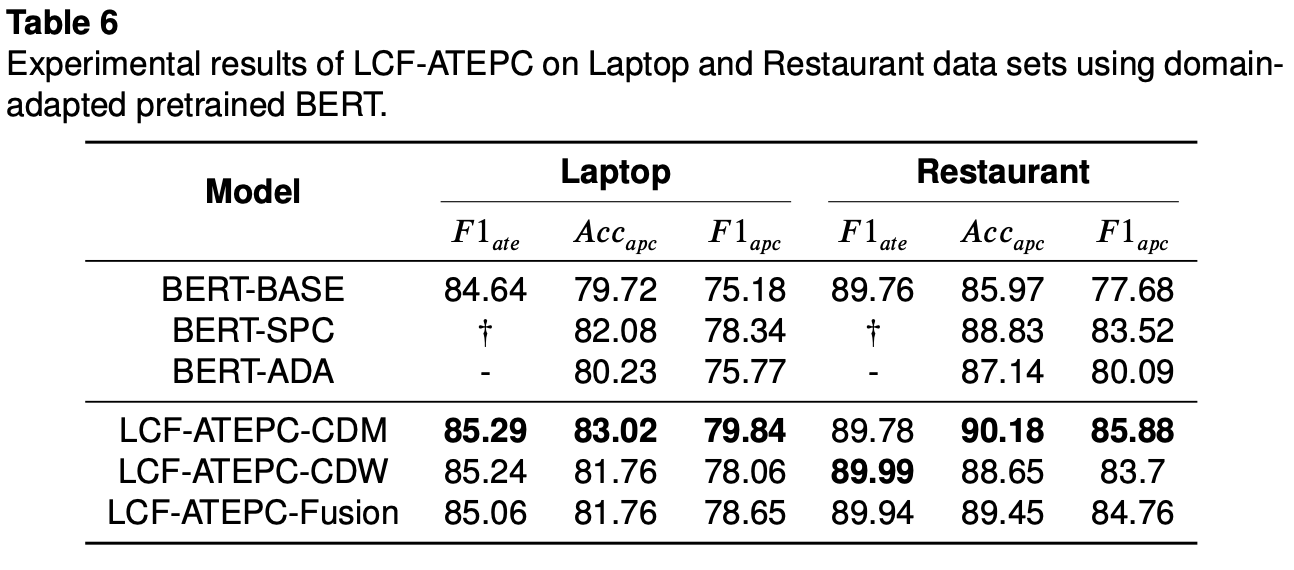
自然言語処理タスクでpretained BERTモデルを使う場合、精度向上のために
- タスクに合わせてfine-tuningを行う
- 似たようなタスク向けに改善されたモデルをpretainedモデルとして使う
などの対策をとることが考えられます。
本研究では、$BERT^g$層, $BERT^l$層を通してfine-tuningを行っているし、GCFGで文ペア分類タスク(sentence-pair classification task)に特化されたBERTモデル: BERT-SPCを使うことで精度向上を図っています。
上に加えて、本論文では似たデータで学習されたpretainedモデルを使うことで更なる精度向上が得られると主張しています。実験として、YelpというローカルビジネスレビューサイトのレストランレビューデータとAmazonのLaptopsレビューデータを用いて事前学習されたBERTモデルを使って学習に取り込んでいます。
結果、テーブル4と6の比較から明かな精度向上が見えています。まだ、RestaurantデータのAPCタスクにおいてLCF-ATEPC法が初めて90%の精度を達成したらしいです。
SRDの感度検証
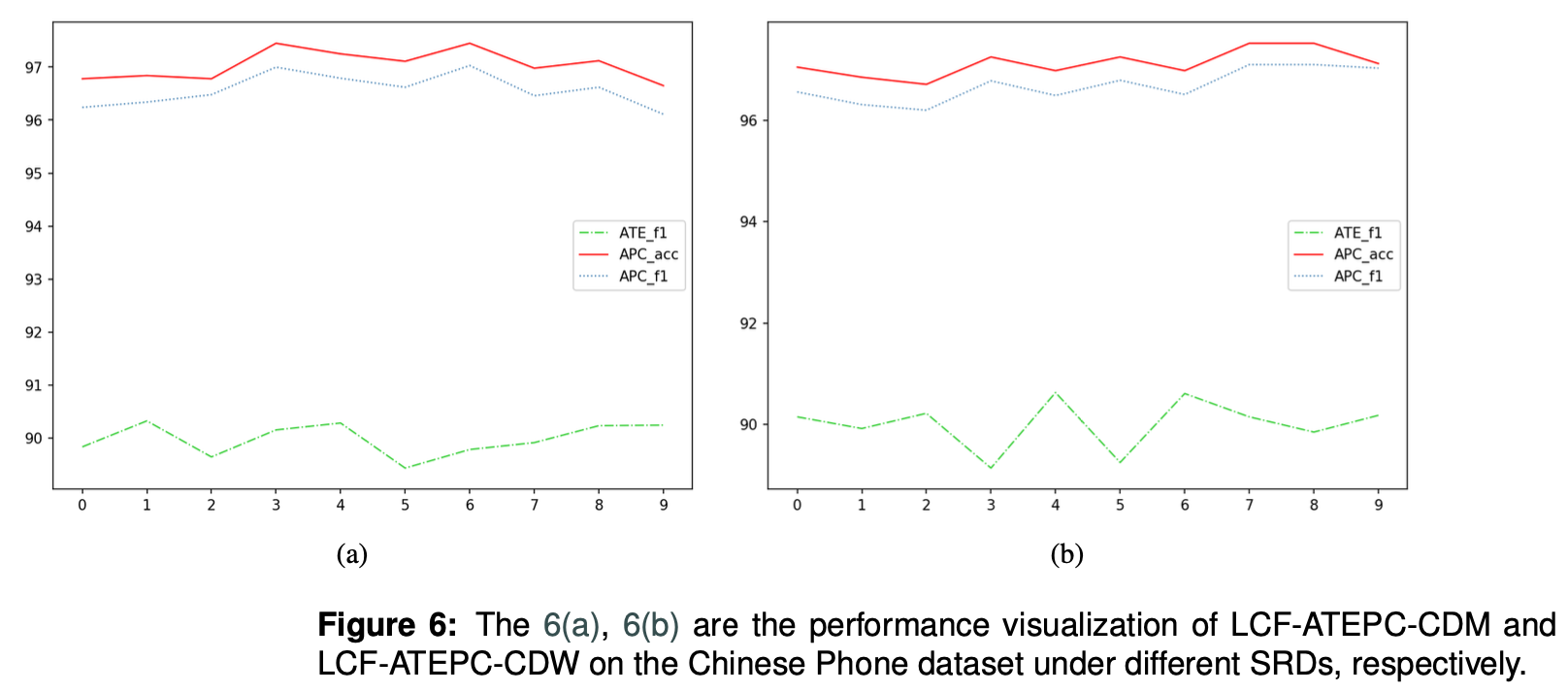
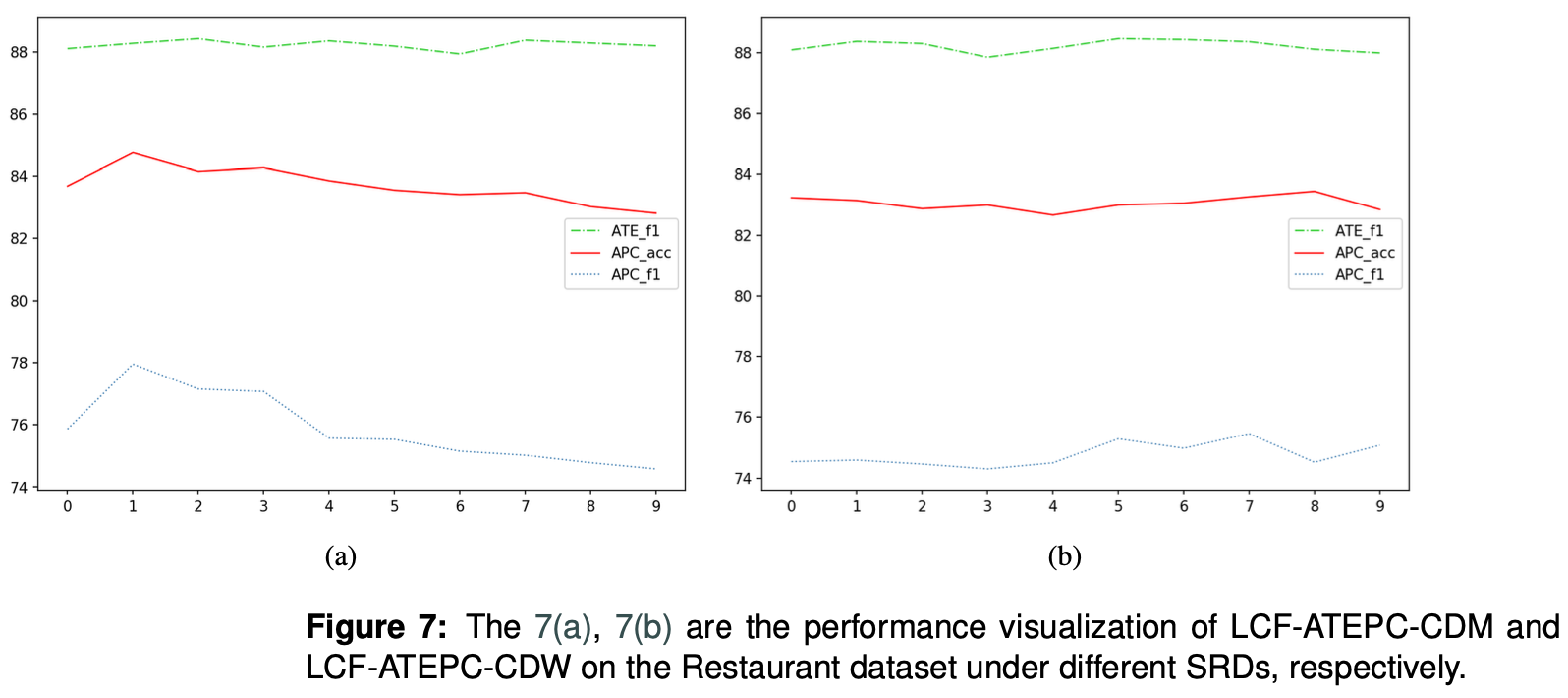
SRD閾値の精度に対する影響を測るために実施した実験結果です。この結果に対して、論文では深く触れていないですが、個人的に精度比較実験でPhoneデータの場合、複数aspectの間で影響しあう傾向があると言っていたが、SRD閾値が高くなるに連れてAPC精度が若干上がっている結果からも同じ傾向の影響があると言えるのではと思いました。
まとめ
以上で、今回は感情表現抽出とその極性判定、二つのタスクを同時に行えるモデル: LCF-ATEPCを紹介しました。LCF-ATEPC法は中国語、英語が混在するデータに対しても有効性を示していました。
個人的には、データセットの特徴に加え、言語(中国語、英語)の特徴も分析するとまだ面白い発見ができるのではないかと思いました。
次は実際に日本語での感情分析レポートが少ないことから、上記モデルを使って感情分析を行ってみようと思います。日本語向けのモデル修正、実験データの加工、学習・予測実験をすでにやっていますので、気になる方は気軽にお声がけください。
最後に、自分の理解度と調べた範囲の限界で間違ったことも書いてあるかもしれないので、ご指摘を頂けると嬉しいです。