前書き
こんにちは。LAPRAS Advent Calendar 2020 25日目担当のdonaldchiです。
今回は弊社に溜まっている(エンジニア, 求人)のマッチング情報を用いて、ニューラルネットワークベースのマッチングモデルをざっくり作ってみた話をしたいと思います。
背景
弊社は「LAPRAS」(C向け)、「LAPRAS SCOUT」(B向け)、「LAPRAS CAREER」、「LAPRAS Freelance」などさまざまなサービスを提供しています。
LAPRASはインターネット上でオープンになっている情報を集め、エンジニア個々人のポートフォリオを自動生成します。ポートフォリオページには、アルゴリズムからのタグ、技術力スコアなどの生成情報もあれば、ポジション、職務経歴、やりたいことなどエンジニアが自分で入力したデータもあります。
(他の機能についてはぜひ自分のポートフォリオページにてご確認ください。)
一方, LAPRAS SCOUTはB向けサービスとなっていて、採用活動をやって企業からエンジニアのポートフォリオページをベースにスカウトメール、twitter DM、興味通知機能などを使って優秀なエンジニアにアプローチすることを可能にします。
従って弊社にはエンジニアと企業、さらにエンジニアと企業のマッチング情報が大量に集まっています。 今回はこのマッチング情報をベースにニューラルネットワークベースのマッチングモデルを作り、分析してみました。
データ
エンジニア情報
LAPRAS(C向けサービス)はエンジニアのアウトプットを分析し、タグと呼ばれるキーワードを抽出します。さらに該当キーワードを得点化した値をタグレベルと呼びます。
例えば、私の場合は主に機械学習、自然言語処理のQiita文章やGithub Repositoryが「いいね」をもらっているので私には「機械学習」、「自然言処理」のようなタグが生成され、高得点を得ています。
従って登録者のタグを望めると該当登録者の職種、興味分野、得意な言語、技術傾向などを大まかに掴むことが可能です。今回の実験ではエンジニアのデータとして、LAPRAS登録者のタグ情報と入力してもらったポジション、やりたいこと、職務経歴情報を使います。
求人情報
LAPRAS SCOUT(B向けサービス)顧客の公開求人情報をクロールし、構文解析して得たポジション、必須条件、歓迎条件、事業内容、言語、フレームワークなどの情報を使います。
実装
エンジニアの職種、給与、技術レベルなどの情報をベースに求人情報へのフィルタリングを行った上、マッチングを行うとより精度の良い結果になるかと思いますが、今回の場合求人情報への前処理をいっさい行わず、単純なモデルを作ります。
モデル構造
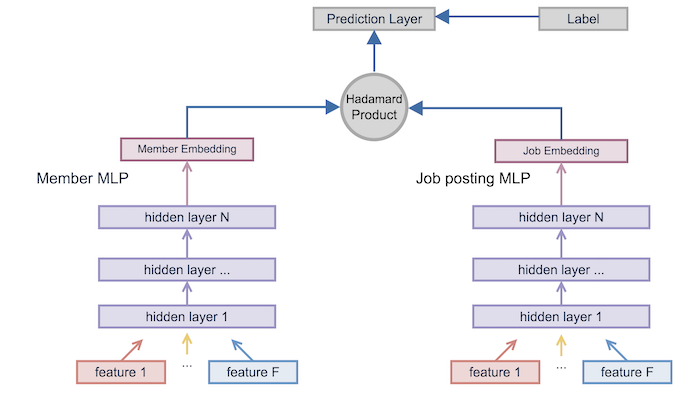
(Pensieve: An embedding feature platform from Linkedin Engineering Blog)
今回の実験ではLinkedinでDeep Structured Semantic Models (DSSM)をベースに提案したマッチングモデルをそのまま使います。
上のブログ記事によると、さらに文脈情報も考慮し、ピラミッド構造をもつモデル構造に拡張した結果より良い結果になったようですが、今回のタスクの場合
- エンジニア情報は色んなアウトプットから得たタグ情報であるため、前後タグ間の文脈情報は薄いはず
- 同じアウトプットから抽出され、並べられた場合に文脈情報があるとしても、特徴量エンジニアリングの時にngramのtfidf値を計算することにより、一定部分の文脈情報は考慮したことになる
という理由から単純なMLP(Multilayer Perceptron)構造を使うことにしました。
特徴量
本モデルでは特徴量としてtf-idf値を使います。エンジニアはポジション、タグ、やりたいこと、職務経歴からなる文章、求人情報は事業内容、必須条件、歓迎条件、言語、フレームワークからなる文章だと考え、それぞれの代表的なキーワードとtfidf値を計算しベクトル化します。
次元圧縮
上記操作で得たベクトルだとcorpusに含まれる単語分膨大なベクトル(今回: 16464次元)になるため、モデルに入力する前に次元圧縮(今回: 128次元に圧縮)を行いました。
圧縮アルゴリズムとして、MiniBatchSparsePCA、SparsePCA、TruncatedSVD、DictionaryLearningなどさまざまな手法を試し、最適な手法を選んでいます。
タグレベル
データの説明で言及したように、LAPRASはタグ抽出だけでなく、タグレベルも計算しています。今回の場合タグのtfidf値だけではなく、タグレベルを考慮した時の実装も共に行いました。タグレベル考慮は単純にタグのtfidf値にタグレベル値をかけることで実現しました。
実験結果
データ
| データ項目 | データ量 |
|---|---|
| エンジニア情報 | 1172件 |
| 求人情報 | 4136件 |
| マッチング情報 | 2312件 (うち:マッチング成功 364件) |
精度
最適なモデルを調べるため、エンジニアデータ、タグレベル考慮有無、ダウンサンプリング有無などいろんな変更を加えながら精度を比較しました。
| エンジニア情報内訳 | タグレベル | ダウンサンプリング | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|---|
| タグ、ポジション、やりたいこと | 考慮しない | しない | 0.70 | 0.20 | 0.49 | 0.29 |
| タグ、ポジション、やりたいこと | 考慮しない | する | 0.71 | 0.32 | 0.40 | 0.36 |
| タグ、ポジション、やりたいこと | 考慮 | しない | 0.72 | 0.18 | 0.36 | 0.24 |
| タグ、ポジション、やりたいこと、職歴 | 考慮しない | しない | 0.61 | 0.17 | 0.55 | 0.26 |
結果、高性能ではないですが、ベースラインモデルとしては充分な結果になりました。特に、「タグ、ポジション、やりたいこと」を使い、「タグレベル考慮なし、ダウンサンプリングをする」という条件を加えた時に一番現実的な結果となっていました。ただ、ダウンサンプリングを加えた場合、もともと少ながったデータ量がさらにへるため、汎用性が高くない可能性はあります。
エンジニアデータについては、職歴に言語、フレームワーク、事業分野データが含まれているため、職歴データを加えることで更なる精度向上を狙いましたが、Recallは高くなるものの、精度が低くなるという結果になりました。
(更なる調査は必要ですが、)考えられる理由として
- 職歴をトークン化する時に使ったMeCab辞書がエンジニアアウトプット解析時に使った辞書と違く、得られたトークンの種類が違う
- 今回の実験では職種、言語、フレームワーク、事業分野などの情報に対する名寄せ処理を行っていなく、表記揺れが発生している
などがあります。
タグレベルを考慮した場合、少しの精度向上はありましたが、precision、recallが下がる結果になっていました。 タグレベルを考慮した場合、特徴量として強調されるのはアルゴリズムが抽出したタグで、エンジニアのポジションややりたいことなどの情報はそのままになります。従って実験結果から今回のアルゴリズムが、ポジションややりたいことが精度への貢献をちゃんと考慮していることがわかります。
類似度計算結果との比較
本モデルはエンジニアと求人情報のtf-idf値からなるベクトルを用いてエンジニア、求人情報の分散表現を取得し、分散表現のアダマール積(Hadamard Product)を用いてマッチング結果をシミュレーションしています。
エンジニア、求人情報のtf-idf値からなるベクトル作成時に同じcorpusをベースにしているため、結果的に同じ次元数、同じ要素の順序をもつベクトルが得られます。従って、単純にエンジニアベクトルと求人情報ベクトルの類似度を計算し、類似度の高いマッチング結果を推薦するアプローチも考えられます。
類似度ベースアプローチでは以下のような感じでテストデータに対して予測ラベル付けを行い、今回のモデルと比較します。
- 特定エンジニアと求人情報の類似度でtop5に入る求人に(特定エンジニア、求人情報、1)と正解ラベルをつける
- 特定エンジニアと求人情報の類似度が一定閾値以上の場合(特定エンジニア、求人情報、1)と正解ラベルをつける
| モデル | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| 類似度(top5) | 0.87 | 0 | 0 | 0 |
| 類似度(0.3以上) | 0.79 | 0.16 | 0.17 | 0.16 |
| 本モデル | 0.70 | 0.20 | 0.49 | 0.29 |
エンジニア情報と求人情報の類似度アプローチにおいて、類似度高い順top5を基準に予測を行った場合、正例とラベル付けられる例は0件でprecision、recall、F1値共に0でした。一方で、類似度の閾値0.3を基準に予測を行った結果、精度は高いものの、precision, recall, F1値は本モデルに下回っていました。
従って、本モデルでエンジニア、求人情報の分散表現を学習することで、単純な類似度計算とまだ違う情報も学習していることが確認できました。
まとめ
今回は弊社に集まっているエンジニア、求人、マッチング事例情報を用いてエンジニアと求人のマッチング結果を予測するニューラルネットワークモデルを構築してみました。
結果、高性能ではないですが、ベースラインモデルとしては充分なモデルを構築することができました。
今回の実験で「LAPRASアウトプットから抽出したタグには求人マッチングに適応できる情報が一定部分含まれてある」ことがわかりました。
しかし、懸念点としてデータ量が少なく汎用的なモデルになっているかが残ります。最悪の場合、データ量の不足で汎用性がなく、未知の実データでは使うものにならない結果を出す可能性もあるかと思われます。従って、次のアクションとしては実データで予測してみて人力でみた時に納得の行くに結果になっているかを確認することを考えています。
今回の実験に関して気になるところやご指摘などある場合はコメント欄に書いて下さると嬉しいです。