アドベントカレンダー、遅ればせながら投稿させていただきます!!
私は今、Paizaにハマっています。
レベル別のプログラミングの問題に回答することで、自分自身のレベルを図ることができるサービスですね。
しかし、Paiza公式の結果画面では、
- どの言語で挑戦して
- 採点結果が何点だったか
を各問題毎に一覧表示してくれる機能が現在ありません。
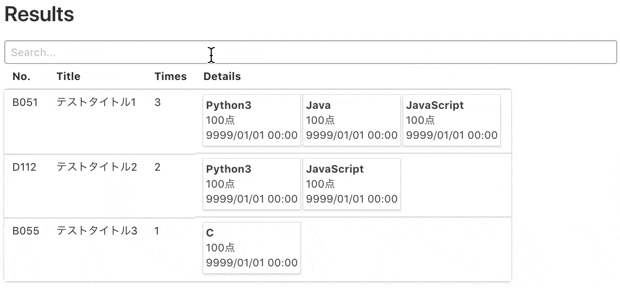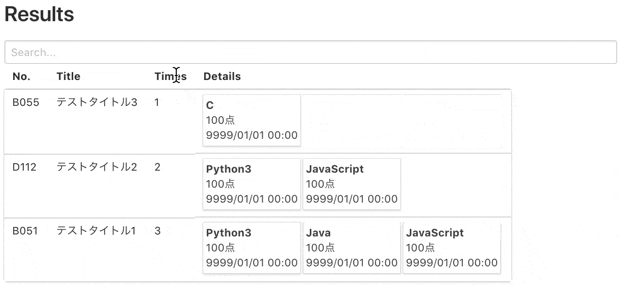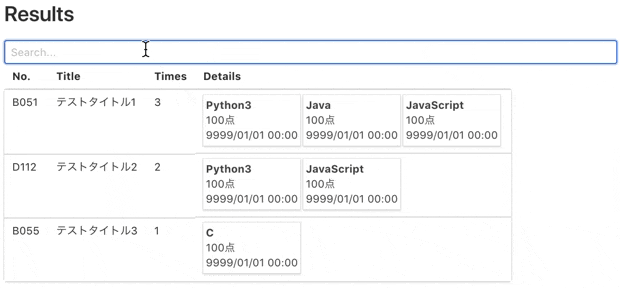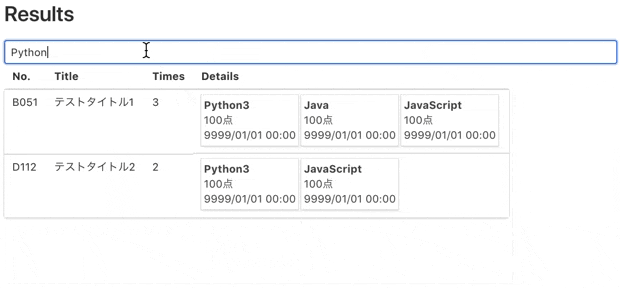
そこで、自分が各問題毎の結果を知ることができるPaizanalyzerというサービスを作ってみました(データはダミーにしてあります)。
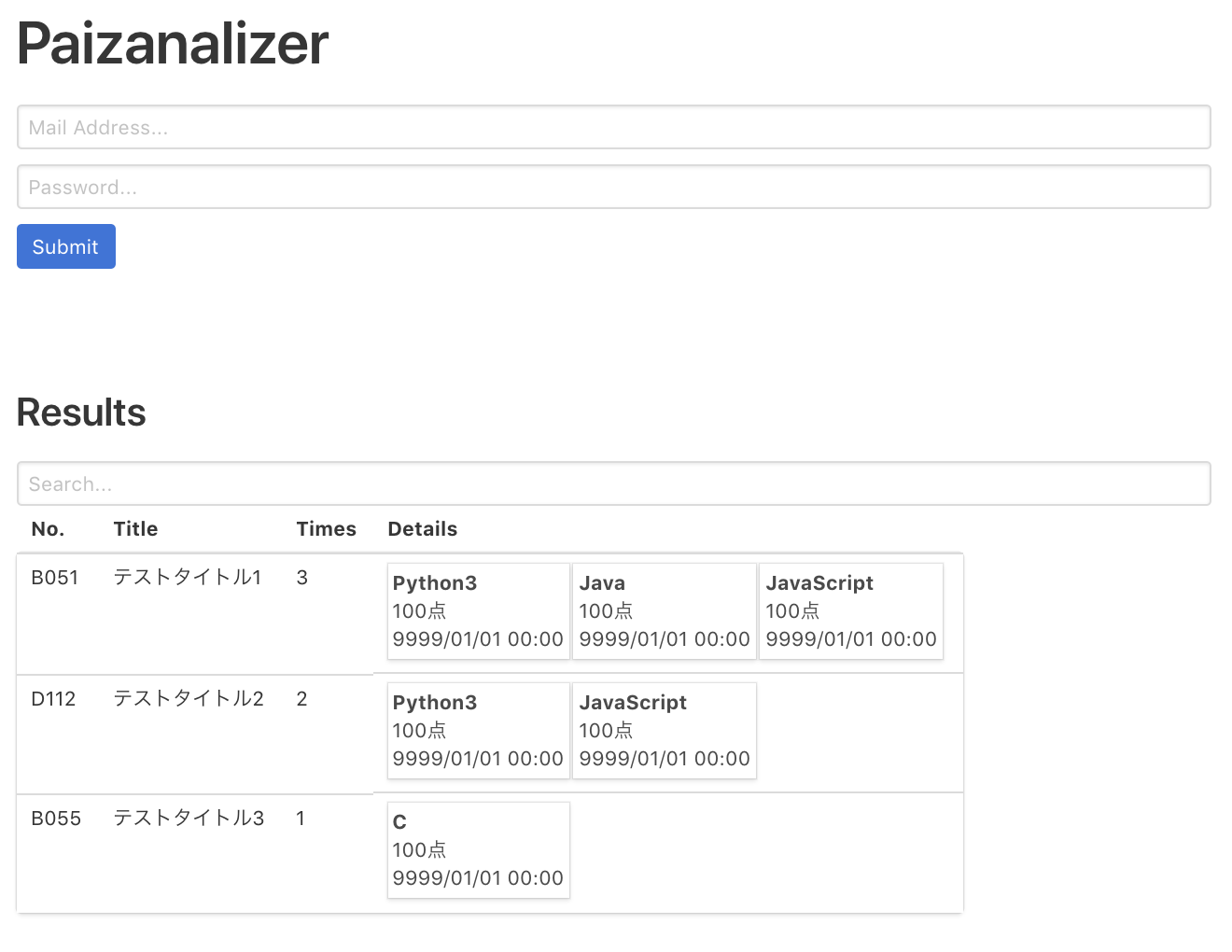
入力されたメールアドレス、パスワードを基に自分自身の結果をスクレイピングしてきます。
スクレイピング結果をテーブル & カード形式にして表示してくれます。
各カラム毎に並び替え表示や語句検索も可能です。
技術的には
- Selenium
- Flask
を使用しています。

今回のPythonのAdvent Calendar では、このアプリの内容解説、及び作成する際に引っかかったポイント・調べたポイントを共有できればと思っています。
スクレイピング - bs4 & Selenium
今回、スクレイピングするにあたり、Seleniumを使用しています。Pythonではスクレイピングの際、主に
- Beautiful Soup
- Selenium
の2つが使われることが多いです。今回は結果を取得する際に、ボタンを押して動的に要素を表示する必要があったため、Seleniumを使用します。
※ @ukisoft さんがAdventで書かれていた方法を使用すればbs4でも行けるかもしれません。そちらも後日確認してみます。
https://qiita.com/ukisoft/items/a6cee061e5f50dec3530
ログインに必要な情報を集める
https://paiza.jp/login/
の該当部分を調べてみると以下のようになっています。
<form class="new_user" id="new_user" action="/user_sessions" accept-charset="UTF-8" method="post">
<input name="utf8" type="hidden" value="✓">
<input type="hidden" name="authenticity_token" value="74DhqUn9wjuAWfAVJbxKTzJ34tRfKoupXUcEdC6yC1JD/+4oqn2CXQqFYTdL0zxIQAJaNGbEK0di5tRRDUlo2g==">
<div class="form-group">
<label class="control-label" for="user_email">メールアドレス</label>
<div>
<input class="form-control" type="text" name="user[email]" id="user_email">
</div>
</div>
<div class="form-group">
<label class="control-label" for="user_password">パスワード</label>
<div>
<input class="form-control" type="password" name="user[password]" id="user_password">
</div>
</div>
(中略)
<div class="form-group">
<input type="submit" name="commit" value="ログインする" class="btn btn-primary btn-block btn_login">
</div>
(中略)
</form>
<input name="utf8" type="hidden" value="✓">があるので、どうやらRailsで記述されているようですね。
Selenium で input情報を入力・送信
今回はSeleniumを使用するので、素直に記述していきます。
SeleniumはWebブラウザを利用します。ヘッドレスブラウザ (画面表示されずにブラウジングが可能なWebブラウザ)として、chromeを使用します。
ライブラリをインポートする
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
Selenium, 及び ChromeDriver をインストールしていない場合はpipを利用してあらかじめインストールしておいてください(記事の最後にAppendixとしてコマンドを記載してあります)。
Chrome ブラウザを準備する
options = Options()
options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=options)
browser.implicitly_wait(3)
options.add_argument('--headless')をコメントアウトすれば、ヘッドレスモードではなくなるため、Webブラウザが通常通り起動します。
また、implicity_wait()を指定することで、指定ドライバを見つけるまでの時間の上限を設定しています。
(参照)http://www.seleniumqref.com/api/python/time_set/Python_implicitly_wait.html
ログインをする
def input_form(css_selector, val):
el = browser.find_element_by_css_selector(css_selector)
el.clear()
el.send_keys(val)
# ログインページにアクセス
login_url = 'https://paiza.jp/login'
browser.get(login_url)
input_form('#email', [メールアドレス])
input_form('#password', [パスワード])
form = browser.find_element_by_css_selector('#regist_btn')
form.submit()
print('login successful')
ちなみに、Seleniumでよく使うものは以下の通りです。
# Webブラウザを指定する
browser = webdriver.Chrome()
# CSSセレクタを基に要素を取得
el = browser.find_element_by_css_selector([CSSセレクタ])
# インプットのvalに値をセットする
el.send_keys(val)
# フォームを送信する
el.submit()
補足: Beautiful Soupによる ログイン実装
今回はBeautifulSoupを使用しませんでしたが、
from bs4 import BeautifulSoup
login_info = {
'utf8': '✓',
'user[email]': user.info('email'),
'user[password]': user.info('password')
}
session = requests.Session()
# authenticity_tokenを取得する
url = 'https://paiza.jp'
res = session.get(url)
soup = BeautifulSoup(res.text, 'html.parser')
auth_token = soup.find(attrs={'name': 'authenticity_token'}).get('value')
login_info['authenticity_token'] = auth_token
# ログイン処理をする
login_url = 'https://paiza.jp/user_sessions'
res = session.post(login_url, data=login_info)
print(res.text)
authenticity_tokenをあらかじめ取得した上でログイン処理を行う必要があるので注意が必要です。
(参考)
Rails セキュリティガイド
Qiitaのログインが必要なページのスクレイピング (2018.2時点)
セッション とは
必要情報を取得し、辞書型に格納する
{'問題番号': ['テストタイトル1', [['言語', '日時', 'スコア'],['言語2', '日時', 'スコア']...],....}
の形で辞書型の変数dataにデータを格納していきます。
paizaでは初回の挑戦結果が https://paiza.jp/career/mypage/results に、再チャレンジの結果は https://paiza.jp/career/mypage/retry-results にそれぞれ表示されます。なので、それぞれのページにアクセスし、情報を取得します。
また、再チャレンジ結果は"続きを表示する"ボタンを押す必要があるので、Seleniumを使って押しています。
browser.get('https://paiza.jp/career/mypage/results')
time.sleep(1)
print('move to my page')
results = browser.find_elements_by_css_selector('div.basicBox')
results_num = len(results)
count = 0
for result in results:
title = result.find_element_by_css_selector('a').text.split(':')
date = result.find_element_by_css_selector('.boxT > .boxTR').text.split(':')
details = [r.text for r in result.find_elements_by_css_selector('.boxM > div.inrTxt > span')]
if len(title) >= 2 and len(details) >= 9:
# data[問題番号] = [タイトル,[ [言語,日時,スコア] ] ]
data[title[0]] = [title[1],[[details[2],date[1],details[8]]]]
print('{} / {} finished...'.format(count, results_num))
count += 1
browser.get('https://paiza.jp/career/mypage/retry-results')
is_viewmore_button = True
while is_viewmore_button:
try:
form = browser.find_element_by_css_selector('#view_more > form > input.ch_button')
form.submit()
time.sleep(1)
except:
is_viewmore_button = False
results = browser.find_elements_by_css_selector('#retry_results > div.basicBox')
results_num = len(results)
count = 0
for result in results:
title = result.find_element_by_css_selector('a').text.split(':')
date = result.find_element_by_css_selector('.boxT > .boxTR').text.split(':')
details = [r.text for r in result.find_elements_by_css_selector('.boxM > div.inrTxt > span')]
if len(title) >= 2 and len(details) >= 6:
print(details)
# data[問題番号] = [言語,日時,スコア]
data[title[0]][1].append([details[1],date[1],details[5]])
print('{} / {} finished...'.format(count, results_num))
count += 1
ブラウザを閉じる
ブラウザを閉じることを忘れないでください。
browser.quit()
FlaskでWebサーバーを準備する
import astをしている理由は、先ほど生成した辞書型をテキストファイルとして保存しているためです。データーベースを作成・保存していないのは私の怠慢です←
import ast
ast.literal_eval([文字列])
from flask import Flask
from flask import g
from flask import render_template
from flask import request
from flask import Response
from module import paiza
import ast
def get_data():
data_path = 'data/data_dict.txt'
try:
with open(data_path) as f:
s = f.read()
return ast.literal_eval(s)
except:
return None
app = Flask(__name__)
@app.route('/', methods=['GET','POST'])
def paizanalyzer():
if request.method == 'GET':
data = get_data()
return render_template('index.php', data = data)
elif request.method == 'POST':
paiza.get_data(request.form['mail'],request.form['pass'])
data = get_data()
return render_template('index.php', data = data)
def main():
app.debug = True
app.run(host='127.0.0.1', port=5000)
if __name__ == '__main__':
main()
テーブルにデータを書き出す
<table class="table is-hoverable">
<thead>
<tr>
<th class='sort' data-sort='no'>No.</th>
<th class='sort' data-sort='ttl'>Title</th>
<th class='sort' data-sort='times'>Times</th>
<th class='sort' data-sort='details'>Details</th>
</tr>
</thead>
<tbody class='list'>
{% for key in data %}
<tr>
<td class='no'>{{ key }}</td>
<td class='ttl'>{{ data[key][0] }}</td>
<td class='times'>{{ data[key][1] | length }}</td>
<td class='details' style='display:flex; flex-wrap:wrap;'>
{% for card in data[key][1] %}
<div class="card" style='margin-right:4px; margin-bottom:4px'>
<div style='margin:4px'>
<p><b>{{ card[0] }}</b></p>
<p>{{ card[2] }}</p>
<p >{{ card[1] }}</p>
</div>
</div>
{% endfor %}
</td>
</tr>
{% endfor %}
</tbody>
</table>
これで完成です!
完成版のソースコードはgithubにあります。
https://github.com/cha1ra/paizanalizer
フロント部分の実装についてはまた別記事にまとめようと思います!!
Appendix: 事前準備
Seleniumをインストールする
pip install selenium
You are using pip version 10.0.1, however version 18.1 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
こんな風に怒られた場合は、素直に従いましょう。
pip install --upgrade pip
Chrome Driverをダウンロードする
brew cask install chromedriver
無事にインストールされていれば、--versionコマンドでバージョンが表示されます。
chromedriver --version
ChromeDriver 2.45.615355 (...)
※「caskってなんぞ?」っていう人はこちらの記事が詳しいです。
https://qiita.com/guitar_char/items/3aca4950bf0adcdf419d
つまり、
homebrewの拡張で、MacのGUIアプリケーションもコマンド一発で管理してしまおうというもの。
です。