今回は、Step4 です。Step3 で作成したコードをベースに編集を行います。ここでは、Twitter API についての説明を省略しますので、Twitter API については、Step1、Step2 をご参照ください。
講座の最終目標
Twitter のツイート データを Azure Data Lake Storage Gen2 (ADLS Gen2) に Parquet 形式のファイルとして自動的に蓄積し、Azure Synapse Analytics (Serverless SQL / Apach Spark) を使って分析できるようにします。ツイート データの継続的な取得と ADLS Gen2 へのデータ蓄積には、Azure Functions を利用します。

Step4 の目標
Azure Data Lake Storage Gen2 (ADLS Gen2) に Parquet ファイル を C# から出力できるようにすることが目標となります。Parquet 形式のファイルは、Hadoop (Azure HDInsight) / Spark (Azure Databricks, Azure Synapse - Apache Spark) / Azure Synapse - Serverless SQL など、ビッグデータ処理には欠かせないスケーラブルなカラムストア型ファイルになります。アプリ自体は、ローカル環境で動作するコンソール アプリケーションとなります。
開発環境 (OSS)
開発には、以下を利用します。OSS (無償) かつ クロス プラットフォームとなりますので、Windows / Mac / Linux などお好きな OS/デバイスをご利用ください。
- ツール : Visual Studio 2019 Community or VS Code
- ランタイム : .NET 5 or .NET Core 3.1
- 言語 : C#
C# コードの開発
今回の手順では、Visual Studio 2019 を利用します。
1. Step3 で作成したプロジェクトを開きます
Visual Studio 2019 を起動し、Step3 で作成したプロジェクトを開きます。
2. Azure Blob Storage (ADLS Gen2 含む) 入出力用 Nuget パッケージの取得
Visual Studio の「Nuget パッケージの管理」機能を使って、(Azure Storage Blob パッケージ) を取得します。

3. using ディレクティブの追加(コード)
ADLS Gen2 ストレージへの出力に必要なライブラリ分を追加します。
using System;
using System.IO;
using System.Threading.Tasks;
using System.Collections.Generic;
using Tweetinvi;
using Parquet.Data;
using Parquet;
using Azure.Storage.Blobs;
4. ADLS Gen2 ファイルパスの生成(コード)
Spark や Synapse Serverless SQL でスケーラブルな IO を実現できるように、日時によるパス (パーティション化) とファイル名が重ならないように GUID を伴うファイルパスを生成するようにします。
dt = DateTime.UtcNow;
blobFileName = $"./tweetdata/{dt.ToString("yyyy")}/{dt.ToString("MM")}/{dt.ToString("dd")}/{dt.ToString("HH")}/tw_{Guid.NewGuid().ToString("D")}.parquet";
5. メモリ ストリームの利用(コード)
Step3 でのローカル ファイル出力では、ファイル ストリームを使いましたが、ADLS Gen2 への出力を考慮して、Parquet ファイル作成にはメモリ ストリームを利用します。
Stream stream = new MemoryStream();
using (var parquetWriter = new ParquetWriter(schema, stream))
{
// create a new row group in the file
using (ParquetRowGroupWriter groupWriter = parquetWriter.CreateRowGroup())
{
groupWriter.WriteColumn(createdAtColumn);
groupWriter.WriteColumn(createdByColumn);
groupWriter.WriteColumn(sourceColumn);
groupWriter.WriteColumn(textColumn);
}
}
6. ADLS Gen2 Storage への出力(コード)
事前に ADLS Gen2 Storage (階層型 Blob Storage) とファイル システム (コンテナー) を作成しておきます。ストレージ アカウントの接続文字列とファイル システム名 (コンテナー名) を取得しておき、以下のパラメーターで利用します。手順 4 の Parquet ファイルを出力したメモリ ストリームを使って、ADLS Gen2 にファイルをアップロードします。
// Write to Blob (ADLS Gen2) storage
var connectionString = "<your ADLS Gen2 storage connection string>";
var blobServiceClient = new BlobServiceClient(connectionString);
var containerClient = blobServiceClient.GetBlobContainerClient("<your filesystem name>");
// Get a reference to a blob
BlobClient blobClient = containerClient.GetBlobClient(blobFileName);
stream.Position = 0;
await blobClient.UploadAsync(stream);
stream.Close();
7. コード全体
上記で主要なコードについて説明しましたが、以下はコード全体となります。Twitter API 認証用の TwitterClient のパラメーター、および、ADLS Gen2 出力用のパラメーター (ストレージ アカウントの接続文字列とファイル システム名) を置換してください。GitHub にも各ステップのコードを共有しています。
using System;
using System.IO;
using System.Threading.Tasks;
using System.Collections.Generic;
using Tweetinvi;
using Parquet.Data;
using Parquet;
using Azure.Storage.Blobs;
namespace TwitterStreamApiConsole
{
class Program
{
private static readonly int maxCount = 5;
private static int counter;
private static DateTime dt;
private static string blobFileName;
static void Main(string[] args)
{
Console.WriteLine($"***** Stream started. {DateTime.UtcNow}");
dt = DateTime.UtcNow;
blobFileName = $"./tweetdata/{dt.ToString("yyyy")}/{dt.ToString("MM")}/{dt.ToString("dd")}/{dt.ToString("HH")}/tw_{Guid.NewGuid().ToString("D")}.parquet";
counter = 0;
var tweets = new TweetsEntity();
tweets.CreatedAt = new List<DateTimeOffset>();
tweets.CreatedBy = new List<string>();
tweets.Source = new List<string>();
tweets.Text = new List<string>();
StartFilteredStream(tweets);
Console.ReadLine();
}
private static async void StartFilteredStream(TweetsEntity tweets)
{
// User client & stream
var client = new TwitterClient("<your API Key>", "<your API Secret>",
"<your Access Token>", "<your Access Token Secret>");
var stream = client.Streams.CreateFilteredStream();
// Add filters
stream.AddTrack("コロナ");
stream.AddTrack("大変");
// Read stream
stream.MatchingTweetReceived += (sender, args) =>
{
var lang = args.Tweet.Language;
// Specify Japanese & Remove bot tweets
if (lang == Tweetinvi.Models.Language.Japanese && args.Tweet.Source.Contains(">Twitter "))
{
Console.WriteLine("----------------------------------------------------------------------");
Console.WriteLine($"** CreatedAt : {args.Tweet.CreatedAt}");
Console.WriteLine($"** CreatedBy : {args.Tweet.CreatedBy}");
Console.WriteLine($"** Source : {args.Tweet.Source}");
Console.WriteLine($"** Text : {args.Tweet.Text}");
tweets.CreatedAt.Add(args.Tweet.CreatedAt);
tweets.CreatedBy.Add(args.Tweet.CreatedBy.ToString());
tweets.Source.Add(args.Tweet.Source);
tweets.Text.Add(args.Tweet.Text);
}
++counter;
if (counter > maxCount)
{
stream.Stop();
}
};
await stream.StartMatchingAllConditionsAsync();
Console.WriteLine("***** Stream stopped.");
await CreateParquetFile(tweets);
}
private static async Task CreateParquetFile(TweetsEntity tweets)
{
////////////////////////////////////////////////////////////////////////////////////////
/// Write Parquet file
/// https://github.com/aloneguid/parquet-dotnet
/// https://docs.microsoft.com/ja-jp/azure/storage/blobs/storage-quickstart-blobs-dotnet
////////////////////////////////////////////////////////////////////////////////////////
// create data columns with schema metadata and the data
var createdAtColumn = new Parquet.Data.DataColumn(
new DataField<DateTimeOffset>("CreatedAt"),
tweets.CreatedAt.ToArray()
);
var createdByColumn = new Parquet.Data.DataColumn(
new DataField<string>("CreatedBy"),
tweets.CreatedBy.ToArray()
);
var sourceColumn = new Parquet.Data.DataColumn(
new DataField<string>("Source"),
tweets.Source.ToArray()
);
var textColumn = new Parquet.Data.DataColumn(
new DataField<string>("Text"),
tweets.Text.ToArray()
);
// create file schema
var schema = new Schema(createdAtColumn.Field, createdByColumn.Field, sourceColumn.Field, textColumn.Field);
// create file
Stream stream = new MemoryStream();
using (var parquetWriter = new ParquetWriter(schema, stream))
{
// create a new row group in the file
using (ParquetRowGroupWriter groupWriter = parquetWriter.CreateRowGroup())
{
groupWriter.WriteColumn(createdAtColumn);
groupWriter.WriteColumn(createdByColumn);
groupWriter.WriteColumn(sourceColumn);
groupWriter.WriteColumn(textColumn);
}
}
// Write to Blob storage
var connectionString = "<your ADLS Gen2 storage connection string>";
var blobServiceClient = new BlobServiceClient(connectionString);
var containerClient = blobServiceClient.GetBlobContainerClient("<your filesystem name>");
// Get a reference to a blob
BlobClient blobClient = containerClient.GetBlobClient(blobFileName);
stream.Position = 0;
await blobClient.UploadAsync(stream);
stream.Close();
}
private class TweetsEntity
{
public List<DateTimeOffset> CreatedAt { set; get; }
public List<string> CreatedBy { set; get; }
public List<string> Source { set; get; }
public List<string> Text { set; get; }
}
}
}
8. デバッグ実行
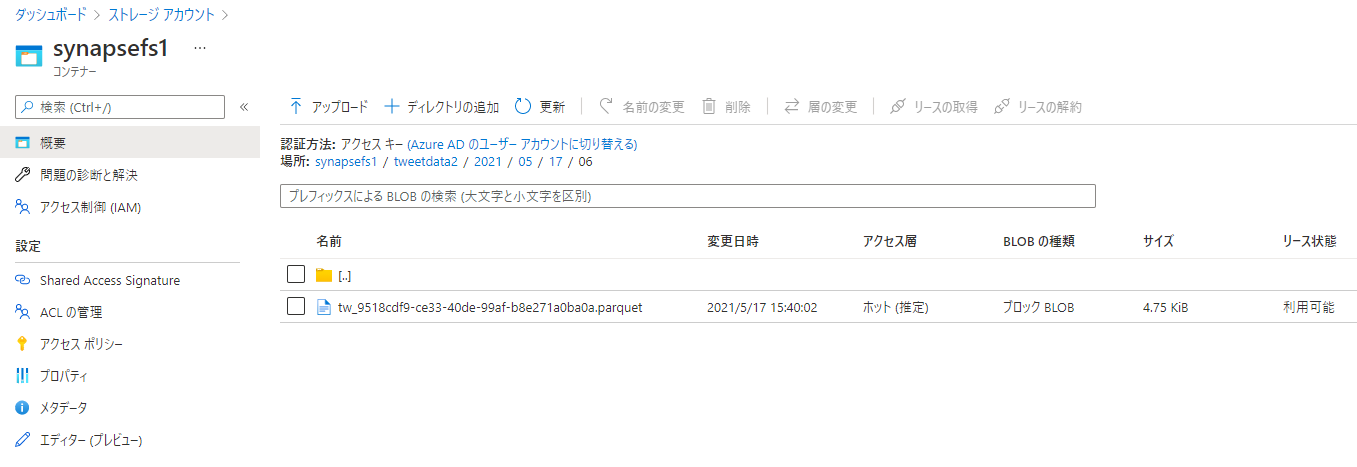
デバッグ実行して、ADLS Gen2 上に指定した日時パスを伴う Parquet ファイルが出力されていれば、成功です。お疲れ様でした。
次のステップへ
Step5 では、これまで作成してきたコンソール アプリケーションのコードをタイマーで起動する Azure Functions に載せ替えます。Azure Functions を利用することで、永続的な取り込みを実現します。
参照
Azure Storage Blob Nuget Package サイト
Apache Parquet for .Net Platform サイト
C# 向け Twitter API SDK (TweetinviAPI) Nuget Package サイト
TweetinviAPI - Filtered Stream API リファレンス
クロス プラットフォーム .NET 概要
Twitter 開発者向けサイト
Twitter API サイト
Visual Studio 2019 Community サイト
Visual Studio Code のサイト