こちらの記事の続きです!
Slackから質問を投げるとChromaDBに検索をかけ、関連情報をもとにGeminiから回答が返ってくるところまで確認ができています。
次は事前データを更新しやすくしたいので改良してみました。
事前データ(更新前)
documents = [
"おれはジャイアン",
"おまえのものはおれのもの、おれのものはおれのもの",
]
質問と回答結果

事前データ(更新後)
new_documents = [
"ドラえもんは未来から来たロボット猫です。",
"ジャイアンは実はやさしいです",
]
質問と回答結果

コード
from slack_bolt import App
from slack_bolt.adapter.socket_mode import SocketModeHandler
import os
from dotenv import load_dotenv
import chromadb
import google.generativeai as genai
import time
import schedule
load_dotenv()
genai.configure(api_key=os.getenv("GEMINI_API_KEY"))
chroma_client = chromadb.Client()
collection = chroma_client.create_collection(name="japanese_documents")
SLACK_BOT_TOKEN = os.getenv('SLACK_BOT_TOKEN')
SLACK_APP_TOKEN = os.getenv('SLACK_APP_TOKEN')
app = App(token=SLACK_BOT_TOKEN)
documents = [
"おれはジャイアン",
"おまえのものはおれのもの、おれのものはおれのもの",
]
ids = ["id1", "id2"]
def add_documents_to_chroma(documents, ids):
try:
collection.add(documents=documents, ids=ids)
print("データがChromaDBに追加されました。")
except Exception as e:
print(f"エラーが発生しました: {e}")
add_documents_to_chroma(documents, ids)
def check_data_in_collection():
all_documents = collection.get()
print("現在のコレクションの内容:")
for doc in all_documents["documents"]:
print(doc)
def update_data_periodically():
new_documents = [
"ドラえもんは未来から来たロボット猫です。",
"ジャイアンは実はやさしいです",
]
new_ids = ["id3", "id4"]
add_documents_to_chroma(new_documents, new_ids)
check_data_in_collection()
def search_similar_documents(query_text):
try:
results = collection.query(
query_texts=[query_text],
n_results=2
)
return results
except Exception as e:
print(f"Error in searching documents: {e}")
return None
def get_gemini_response(question, context):
try:
model = genai.GenerativeModel("gemini-1.5-flash")
response = model.generate_content(
f"以下の情報をもとに質問に答えてください:\n{context}\n質問: {question}"
)
return response.text
except Exception as e:
print(f"Error in generating Gemini response: {e}")
return "Sorry, I couldn't fetch an answer at the moment."
@app.message("")
def handle_message(message, say):
user_message = message.get('text', '')
search_results = search_similar_documents(user_message)
if search_results and 'documents' in search_results:
# search_results['documents'] がリストのリストである場合があるためフラット化する
flat_results = [item for sublist in search_results['documents'] for item in (sublist if isinstance(sublist, list) else [sublist])]
# 結果を文字列として結合
context = "\n".join(flat_results)
gemini_response = get_gemini_response(user_message, context)
say(f"質問: {user_message}\n回答: {gemini_response}")
else:
say("関連する情報が見つかりませんでした。")
schedule.every(1).minutes.do(update_data_periodically)
def run_scheduled_tasks():
while True:
schedule.run_pending()
time.sleep(1)
if __name__ == "__main__":
from threading import Thread
threading_thread = Thread(target=run_scheduled_tasks)
threading_thread.daemon = True
threading_thread.start()
SocketModeHandler(app, SLACK_APP_TOKEN).start()
事前データの更新処理
今回はすぐ検証したかったので1分おきに自動更新をしています
schedule.every(1).minutes.do(update_data_periodically)
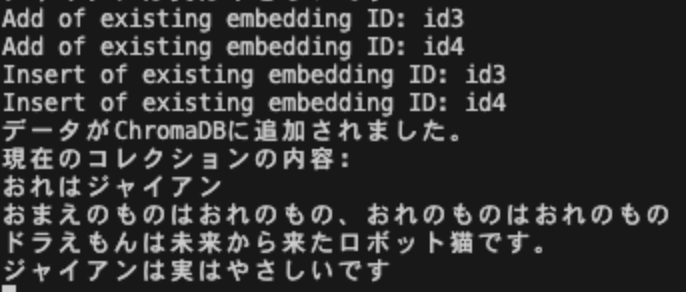
1分経つと以下のようなメッセージがターミナルに表示されます。

さらに1分経つとこのようなメッセージが。
おわりに
データベースを自動更新できるようになりました!
次は事前データの登録をSlackから行えるようにしたいですね![]()