TL;DR
僕がまともに触ったことがあるのはUnityくらいしかなかったので、Unityで機械学習できないかなーって探した結果、ml-agentsというものを見つけたので使ってみました!!
といっても、githubのリポジトリの中にドキュメントも入っているのでUnityを少し触ったことのある人なら、簡単にできるはずです。
対象読者
- Unityを少しでも触ったことがある人
実行環境
- Windows10Home
- Unity18.3.1f1
- Anaconda2018.12
- ml-agents-0.6.0a
セットアップ
とりあえず、Unity2017.4以降のUnityとPython実行環境、ML-Agentsを整えなければなりません。
PythonはAnacondaで環境を整えるのがいいかなと思います(ちょっと重い)。
Unityのダウンロード
以下、Unityの公式サイト
https://unity3d.com/jp
トップページから「Unityを入手」→下のほうにある「過去バージョンのUnity」で好きなバージョンのUnityをダウンロードできます。
ML-Agentsのクローン
https://github.com/Unity-Technologies/ml-agents
上記のURLから適当なフォルダにML-Agentsをクローンしましょう。バージョンは0.6.0aを使用しました。
TensorFlowSharpの設定
https://s3.amazonaws.com/unity-ml-agents/0.5/TFSharpPlugin.unitypackage
上記のURLからパッケージをダウンロードしてUnityにインポートします。その後、以下の操作をします。
・Edit > Project Settings > Player > Other Settings > Configuration > Scripting Define Symbols に "ENABLE_TENSORFLOW" と記述
・Edit > Project Settings > Player > Other Settings > Configuration > Allow 'unsafe' Code の項目があればチェックを入れる
Anacondaのダウンロード
以下、Anacondaの公式サイト
https://www.anaconda.com/download/
トップページからPython3.7バージョンをダウンロードします。64bitと32bitバージョンがありますが、実行するPCのメモリに余裕があるのなら64bitでもいいと思います。
インストール完了後、Anacondaを起動します。
左側のメニューからEnvironmentsを選択し、下のほうにあるCreateから新しい仮想環境を作成します。
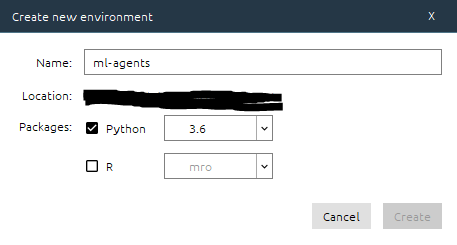
上の画面のように設定します。仮想環境の名前は任意なので何でもよいです。Pythonは確か3.7では動かなかったはずなので、3.6にしましょう。設定出来たら、Createを押します。
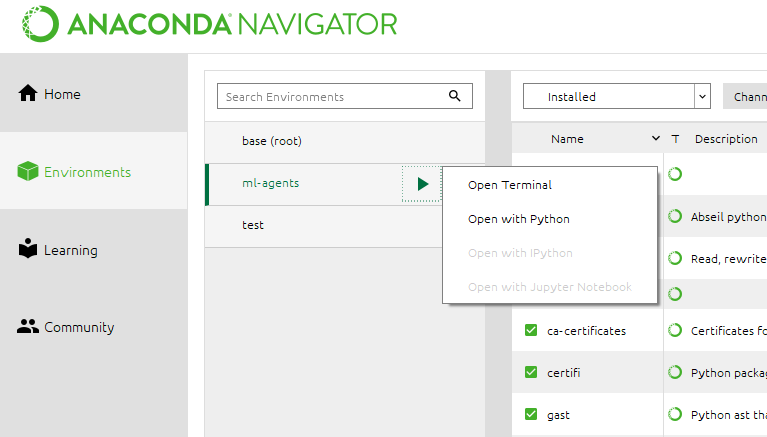
Environmentsに戻り、先ほど作成した仮想環境をクリックします。これで使用する仮想環境を変えることが出来ます。続いて、三角形のボタンを押すと上の画面のようなメニューが出てくると思うので、Open Terminalを押します。
ターミナルを開いてML-Agentsのフォルダまで移動します。ML-Agents/mlagents下のフォルダで、以下のコマンドを実行します。
$pip install .
実行後、機械学習を実行するためのライブラリがダウンロードされます。
これで、Unityによる機械学習の実行環境は整いました。
学習する環境を作る
今回は、リポジトリの中に既に作られている環境ではなく、ドキュメントのLearning-Environment-Create-New.mdに従って新しい環境を作り学習させてみます。目標は、下のように次々と現れるターゲットに向かってボールが向かっていくようにすることです。

では、やっていきます。
オブジェクト
Floor
- GameObject->3D Object->Planeで床を配置します。
- 名前はFloorにしておきます。
- 座標を(0, 0, 0)に設定します。
Target
- GameObject->3D Object->Cubeでターゲットを配置します。
- 名前はTargetにしておきます。
- 座標を(2, 0.5, 2)に設定します。
- Box ColliderのIs TriggerをTrueにしておきます。
RollerAgent
- GameObject->3D Object->Sphereでボールを配置します。
- 名前はRollerAgentにしておきます。
- 座標を(0, 0.5, 0)に設定します。
- RigidBodyをアタッチしておきます。
これで下のような感じになったと思います。(マテリアル等は好きなものをお選びください)

続いてスクリプトを書いていきます。
スクリプト
先ほどスクリプトを書いていくと言いましたが、実際に何を書いていくのか説明します。
Unity-ML-Agentsを使用していく上で私たちが自分たちで実装していかなければならないクラスは最低でも2つあります。
1つはAcademyクラスです。これは学習環境の初期化やリセット、制御をするために用います。例えば、迷路を抜けるモデルを作成するときに迷路の構造自体を変えないまま学習させてしまうと、その迷路に特化しただけで他の迷路に対応できないモデルが出来上がってしまいます。Academyクラスは学習環境自体を変化させなけばならないときに使用します。本記事ではAcademyクラスは使用しません。(Academyクラスは、私もドキュメントを読んだだけで実際には使ったことがありません。)
2つ目はAgentクラスです。これは制御対象にアタッチして、実際に学習をしたりモデルに基づいて制御したりします。制御対象の動きや動きによる評価などを記述します。
RollerAcademy
- スクリプトを書く前に空のGameObjectを作成します。名前はAcademyとします。
- 新しいスクリプトを作成します。名前はRollerAcademyとします。
- AcademyにRollerAcademyをアタッチします。
- 下のスクリプトを書きます。
using MLAgents;
public class RollerAcademy : Academy{}
今回はAcademyクラスでは目立ったような処理はしません。
RollerAgent
- 新しいスクリプトを作成します。名前はRollerAgentとします。
- GameObject側のRollerAgentにこのスクリプトをアタッチします。
- 下のスクリプトを書きます。
using UnityEngine;
using MLAgents;
public class RollerAgent : Agent
{
Rigidbody _rBody;
public Transform _target;
public float _SPEED = 10;
void Start()
{
_rBody = GetComponent<Rigidbody>();
}
public override void AgentReset()
{
if (this.transform.position.y < 0)
{
//If the Agent fell, zero its momentum
this._rBody.angularVelocity = Vector3.zero;
this._rBody.velocity = Vector3.zero;
this.transform.position = new Vector3(0, 0.5f, 0);
}
//Move the target to a new spot
_target.position = new Vector3(Random.value * 8 - 4, 0.5f, Random.value * 8 - 4);
}
public override void CollectObservations()
{
AddVectorObs(_target.position);
AddVectorObs(this.transform.position);
AddVectorObs(_rBody.velocity.x);
AddVectorObs(_rBody.velocity.z);
}
public override void AgentAction(float[] vectorAction, string textAction)
{
Vector3 controlSignal = Vector3.zero;
controlSignal.x = vectorAction[0];
controlSignal.z = vectorAction[1];
_rBody.AddForce(controlSignal * _SPEED);
float distanceToTarget = Vector3.Distance(this.transform.position, _target.position);
//Fell off platform
if (this.transform.position.y < 0)
{
SetReward(-0.5f);
Done();
}
if (distanceToTarget < 1.42f)
{
SetReward(1.0f);
Done();
}
}
}
割と長いように見えますね。一つずつ見ていきましょう。
メンバ変数
Rigidbody _rBody;
public Transform _target;
public float _SPEED = 10;
私はメンバ変数の頭にアンダーバーをつける癖があるのでこのような変数名になりました。それぞれ、
_rBodyはRollerAgentのrigidbodyを格納するもの
_targetはTargetのTransformを格納するもの
_SPEEDはRollerAgentの転がる速さ
という感じになります。
Start()
void Start()
{
_rBody = GetComponent<Rigidbody>();
}
このスクリプトはRollerAgentにアタッチされるので、開始時にRollerAgentのRigidbodyを取得しています。
AgentReset()
public override void AgentReset()
{
if (this.transform.position.y < 0)
{
//If the Agent fell, zero its momentum
this._rBody.angularVelocity = Vector3.zero;
this._rBody.velocity = Vector3.zero;
this.transform.position = new Vector3(0, 0.5f, 0);
}
//Move the target to a new spot
_target.position = new Vector3(Random.value * 8 - 4, 0.5f, Random.value * 8 - 4);
}
これは学習対象が目的を達成したときや失敗したときに、どのように環境をリセットするかを記述するものです。
このプログラムでは、RollerAgentが床から落ちたときに速度や角速度を0、位置を(0,0.5,0)にし、Targetの位置をランダムに出現させる処理をしています。
CollectObservations()
public override void CollectObservations()
{
AddVectorObs(_target.position);
AddVectorObs(this.transform.position);
AddVectorObs(_rBody.velocity.x);
AddVectorObs(_rBody.velocity.z);
}
これはAgentが自分の行動に対しての判断材料みたいなものを設定します。ドキュメントでは
Observation -特定のエージェントが利用できる環境の状態を説明する部分的な情報
という風に説明されています。
このプログラムでは、Targetの位置、RollerAgentの位置及びx,z方向への速度を設定しています。
AgentAction(float[] vectorAction, string textAction)
public override void AgentAction(float[] vectorAction, string textAction)
{
Vector3 controlSignal = Vector3.zero;
controlSignal.x = vectorAction[0];
controlSignal.z = vectorAction[1];
_rBody.AddForce(controlSignal * _SPEED);
float distanceToTarget = Vector3.Distance(this.transform.position, _target.position);
//Fell off platform
if (this.transform.position.y < 0)
{
SetReward(-0.5f);
Done();
}
if (distanceToTarget < 1.42f)
{
SetReward(1.0f);
Done();
}
}
この部分が一番重要な部分です。
この関数ではvectorAction[]とtextActionという引数を取ります。vectorActionは機械学習や私たちの操作によって決定されます。これは後に解説するBrainによって変化します。vectorActionはfloat型配列であり、ここに格納されている値によってAgentは行動を決定します。Agentの行動後、その行動が良かったのか悪かったのかを評価し、次の値を決定するのに用いられます。
このプログラムでは、vectorActionの0番目及び1番目をRollerAgentのx,z方向への力のかけ具合として扱っています。ここで注意してほしいのが、vectorActionの値は意味を持たないということです。学習アルゴリズムは評価値を元に適切な値をvectorActionに設定しているだけであって、それが何に使われるかは知らないということです。その後、RollerAgentへの評価値の設定を行っています。ここでは、RollerAgentとTargetが接触して入れば評価値1.0を与え、床から落ちてしまえば評価値-1.0を与えます。
Brainの追加
続いて、Brainを追加していきます。Brainとは、Agentによって送られた情報をもとにどのように決定を下すかを決定するものです。Brainの種類には、3種類あります。
・Player Brain:ユーザの操作によってAgentの行動を決定する。
・Heuristic Brain:ソースコードによって行動を決定する。
・Learning Brain:機械学習によって行動を決定する。
今回は、Player BrainとLearning Brainを使っていきたいと思います。
では、上のメニューからAssets > Create > ML-Agents > Player Brain, Learning Brainを選択してください。それぞれ、RollerBallBrain, RollerBallPlayerとします。
RollerBallBrain
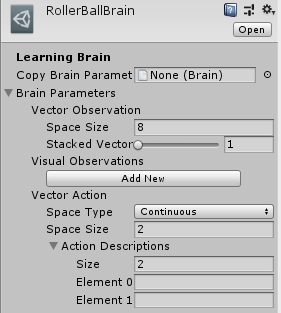
上図のように設定していきます。RollerBallBrainのinspectorを開いてください。
Brain Parameters > Vector Observation > Space Size を8にします。これは、RollerAgentスクリプトのCollectObservations()で設定される項目の数です。今回は、Targetの位置(x, y, z)で3、RollerAgentの位置(x, y, z)で3、RollerAgentのx,z方向の速度で2なので合計8となります。
Brain Parameters > Vector > Action > Space TypeをContinuous、Space Sizeを2にします。Space TypeはAgentActionの引数vectorAgentが実数の配列なのか、単一の整数なのかを示します。今回は実数の配列なのでContinuousとします。また、長さ2の配列なのでSpace Sizeは2となります。
RollerBallPlayer
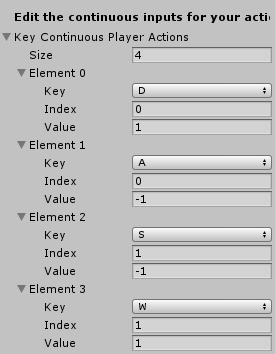
RollerBallPlayerにもRollerBallBrainと同じ項目があると思うので、同様に設定してください。ここではもう一つ、ユーザが自分で操作するためのキー設定を行います。Inspectorの下のほうにに上図のようなものがあるはずなので同様に設定してください。
その他設定
では、最後に諸々の設定を行っていきます。
RollerAgent(GameObject)
・Inspector > RollerAgent > Brain にRollerBallPlayerを設定
・Inspector > RollerAgent > Target にGameObjectのTargetを設定
Academy(GameObjects)
Inspector > RollerAcademy > Broadcast Hub に RollerBallBrain と RollerBallPlayerを設定(設定するための場所が足りない場合は Add New をクリック)
いざ実行!
ということで、一旦実行をしてみます。なにも問題がなければ、WASDでボール(RollerAgent)を操作できるはずです。Targetに触れたり床から落ちたりしてもエラーが出ないことを確認してください。でなければ、実際に学習させてみましょう。そのためにもう少し設定をします。
・RollerAgent > Brain をRollerBallBrain に設定
・RollerAcademy > Brains > RollerBallBrain の右側にある Control にチェックを入れる
続いて、ML-Agents/config/trainer_config.yamlを複製してconfig.yamlを作成します。config.yaml内の項目を以下のように変更します。
batch_size: 10
buffer_size: 100
最後に、Anacondaからml-agents環境に入り、ターミナルでML-Agents/まで移動し、以下のコマンドを実行します。
mlagents-learn config/config.yaml --run-id=RollerBall-1 --train
すると、以下のような画面になるかと思います。ならないときはCtrl-Cとかで止めてもう一回実行してみてください。
ML-Agents$ mlagents-learn config/config.yaml --run-id=RollerBall-1 --train
▄▄▄▓▓▓▓
╓▓▓▓▓▓▓█▓▓▓▓▓
,▄▄▄m▀▀▀' ,▓▓▓▀▓▓▄ ▓▓▓ ▓▓▌
▄▓▓▓▀' ▄▓▓▀ ▓▓▓ ▄▄ ▄▄ ,▄▄ ▄▄▄▄ ,▄▄ ▄▓▓▌▄ ▄▄▄ ,▄▄
▄▓▓▓▀ ▄▓▓▀ ▐▓▓▌ ▓▓▌ ▐▓▓ ▐▓▓▓▀▀▀▓▓▌ ▓▓▓ ▀▓▓▌▀ ^▓▓▌ ╒▓▓▌
▄▓▓▓▓▓▄▄▄▄▄▄▄▄▓▓▓ ▓▀ ▓▓▌ ▐▓▓ ▐▓▓ ▓▓▓ ▓▓▓ ▓▓▌ ▐▓▓▄ ▓▓▌
▀▓▓▓▓▀▀▀▀▀▀▀▀▀▀▓▓▄ ▓▓ ▓▓▌ ▐▓▓ ▐▓▓ ▓▓▓ ▓▓▓ ▓▓▌ ▐▓▓▐▓▓
^█▓▓▓ ▀▓▓▄ ▐▓▓▌ ▓▓▓▓▄▓▓▓▓ ▐▓▓ ▓▓▓ ▓▓▓ ▓▓▓▄ ▓▓▓▓`
'▀▓▓▓▄ ^▓▓▓ ▓▓▓ └▀▀▀▀ ▀▀ ^▀▀ `▀▀ `▀▀ '▀▀ ▐▓▓▌
▀▀▀▀▓▄▄▄ ▓▓▓▓▓▓, ▓▓▓▓▀
`▀█▓▓▓▓▓▓▓▓▓▌
¬`▀▀▀█▓
INFO:mlagents.learn:{'--curriculum': 'None',
'--docker-target-name': 'Empty',
'--env': 'None',
'--help': False,
'--keep-checkpoints': '5',
'--lesson': '0',
'--load': False,
'--no-graphics': False,
'--num-runs': '1',
'--run-id': 'RollerBall-1',
'--save-freq': '50000',
'--seed': '-1',
'--slow': False,
'--train': True,
'--worker-id': '0',
'<trainer-config-path>': 'config/config.yaml'}
INFO:mlagents.envs:Start training by pressing the Play button in the Unity Editor.
上のような画面になったら、Unity側の実行ボタンを押します。すると学習が始まります。
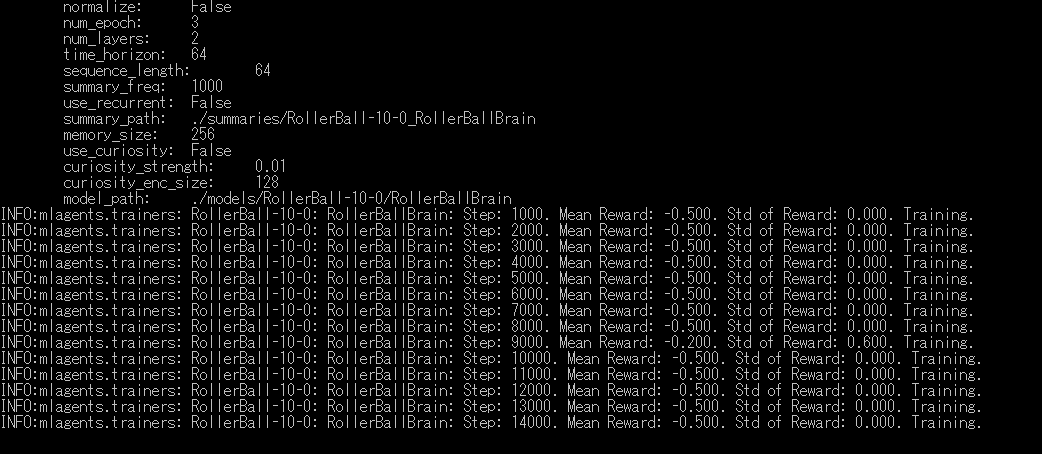
上の図は学習途中のターミナルの画面です。学習状況を示してくれています。各項目について説明します。
・Step:学習ステップの回数
・Mean Reward:ステップ中の評価値の平均
・Std of Reward: ステップ中の評価値の標準偏差
という風になります。ってことは上の図は完全に失敗ということになりますね。みなさんの学習はうまくいったでしょうか。
学習モデルを使う
最後に、実際に学習によって得たモデルを用いてボールを動かしてみましょう。もし、先ほどの学習を最後まで実行していればモデルが作られているはずです。ML-Agents/models/RollerBall-1-0/RollerBall-1.bytesが学習モデルとなりますので、これをScriptやSceneが保存されているフォルダ内にコピーします。続いて、次の操作を実行します。
・RollerBallBrain > Model に RollerBall-1を設定
・RollerAcademy > RollerBallBrain の右側の Controlのチェックを外す
これで実行ボタンを押せば、ボールが自動でTargetを追いかけてくれるはずです。
あとがき
機械学習なんて非常に敷居が高いと思っていましたが、Unityでも機械学習ができるんだなーと今更思いましたね。まだまだTensorFlowとかの理解が足りなので、少しずつやっていくことにしていきます。