1. はじめに
本記事では、当社「DNPドキュメント構造化AI(※1)」で生成された構造化データを活用する方法の一例として、構造化データを活用したRDBでのデータ管理及び検索・分析システムの実装について紹介したいとおもいます。
※1「DNPドキュメント構造化AI」は、企業内の非構造化文書を、生成AIが正確に理解・活用できる“AIリーダブルなデータ”に変換する、DNP独自開発のAIソリューションです。詳細は以下サービスページをご覧ください。
👉DNPドキュメント構造化AI(AI-Ready Data)
2. 現状の課題と検証アプローチ
WordやPDFなど、社内フォルダ内に散在する文書データをデータベースに集約し、一元管理するシステムへのニーズは高まっていると感じます。しかし、実際にRDBでの管理を検討する際、以下のような課題により、なかなかシステム構築に踏み切れないケースが多いのではないでしょうか。
【課題】
1. 文書が様々なフォーマットで存在するため、RDBへの登録時にデータの一貫性確保(正規化処理)が困難
2. 複数の関連文書を横断して分析する際に、テーブル構成が複雑になり、LLMを用いた分析が期待通りに機能しない
そこで今回は、これらの課題に対して構造化データを活用することで、どの程度解決できるかを検証していきます。
【検証内容】
検証1. 異なるフォーマットからの情報抽出(文書形式が異なっても、同一の項目として情報を取得できるか)
検証2. 文書間の関連性を活用した分析(複数の関連文書から必要な情報を適切に抽出・分析できるか)

3 実装
ここからは実際の実装内容について、構造化データの処理部分を中心に記載していきます。
技術スタック
実装環境:Python
主要ライブラリ:
Streamlit(WebアプリUI)
openai/azure-openai(LLM/embedding APIクライアント)
DB:PostgreSQL
バージョン: ankane/pgvector:v0.5.1(PostgreSQL + pgvector拡張入りDockerイメージ)
拡張: pgvector(ベクトル型カラム・類似検索対応)
LLM(大規模言語モデル)/ Embedding
Azure OpenAI(gpt-4o-20241120, text-embedding-3-large)
サンプルデータ
検証用に、以下のような架空のデータを用意しました。
まず、作業工程管理票です。各生産機で確認項目が異なり、記載内容にも違いがあるという、実際の現場でよくある複雑なデータ構造を想定しています。このデータをそのまま構造化し、DBに登録します。
- 作業工程管理票
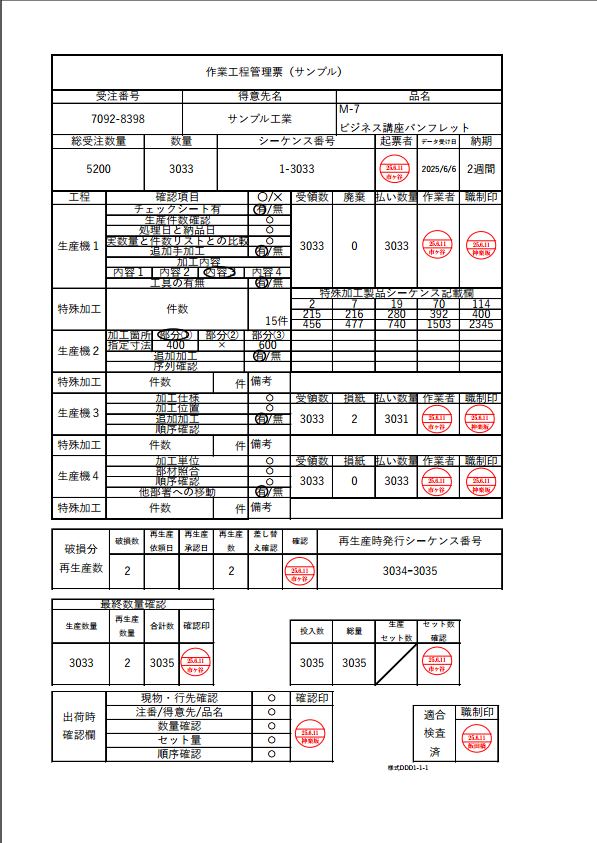
次に、横断的な分析を行うための関連文書として、破損報告書を用意しました。作業工程管理票の生産機3で記録されている損紙「2」に対応する報告書を2種類のフォーマットで作成しています。これは「検証1. 異なるフォーマットからの情報抽出」のための意図的な設定です。


これらのデータは、以下のように構造化データに変換し、RDBに登録して使用します。
<!-- 破損報告書の構造化データ例 -->
<structual-data>
<article>
<title>破損報告書1(サンプル)</title>
<section>報告書ID</section>
<text>2025060701</text>
<section>発生場所</section>
<text>東京工場 生産機3</text>
<section>当時の状況</section>
<text>製品の角潰れ、表面の軽微な傷</text>
<section>発生事由</section>
<text>梱包作業中の不注意による落下</text>
<section>対処内容</section>
<text>破損品の確認と隔離; 得意先への状況報告と代替品の再生産手配</text>
</article>
</structual-data>
DBスキーマ
今回使用するテーブルのスキーマ構成について説明します。
通常のRDBでは、データの一貫性を保つために詳細な正規化が必要となりますが、今回は構造化データの特性を活かし、最小限のカラムのみ(主キー、外部キーなど)を定義し、その他の情報は全て構造化データ(context)として格納しています。
※なお、ベクトル検索のためのベクトル化カラムも実装していますが、今回の検証の主題ではないため、詳細は割愛させていただきます。
-- 作業工程管理票 管理テーブル
CREATE TABLE work_process_documents (
work_process_doc_uid SERIAL PRIMARY KEY, --UID
sequence_number VARCHAR(255) UNIQUE,
content TEXT,-- 記載内容(構造化データが入ります)
document_path VARCHAR(500), -- ドキュメント格納パス (PostgreSQL/doc/配下)
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 報告書 管理テーブル
CREATE TABLE damage_reports (
report_uid SERIAL PRIMARY KEY, --UID
order_sequence_number VARCHAR(255) REFERENCES work_process_documents(sequence_number), --作業工程管理票に紐づく外部キー
content TEXT NOT NULL, -- 記載内容(構造化データが入ります)
content_embedding VECTOR(3072), -- text-embedding-3-large用の3072次元(ベクトル検索用)
document_path VARCHAR(500), -- ドキュメント格納パス (PostgreSQL/doc/配下)
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
以下はTABLEへのINSERT文の一部となります。
-- 作業工程関連文書データの投入(一部抜粋)
INSERT INTO work_process_documents (order_number, sequence_number, content, document_path)
VALUES
('7092-8398', '1-3033', '<structual-data>
<article>
<title>作業工程管理票(サンプル) 1</title>
<section>作業工程管理票(サンプル)</section>
<!-- 中略 -->
<text>\n| 工程 | 確認項目 | 〇/✕ |\n|:---:|:---:|:---:|\n| 生産機2 | 加工箇所 | 部分① |\n| 生産機2 | 指定寸法 | 400×600 |\n| 生産機2 | 追加加工 | 有 |\n| 生産機2 | 序列確認 | |\n| 特殊加工 | 件数 | 件 |\n| 特殊加工 | 備考 | |\n</text>
<text>\n| 工程 | 確認項目 | 〇/✕ | 受領数 | 廃棄 | 払い数量 | 作業者 | 職制印 |\n|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|\n| 生産機3 | 加工仕様 | 〇 | 3033 | 2 | 3031 | | |\n| 生産機3 | 加工位置 | 〇 | 3033 | 2 | 3031 | | |\n| 生産機3 | 追加加工 | 有 | 3033 | 2 | 3031 | | |\n| 生産機3 | 順序確認 | | 3033 | 2 | 3031 | | |\n| 特殊加工 | 件数 | 件 | | | | | |\n| 特殊加工 | 備考 | | | | | | |\n</text>
<!-- 中略 -->
<text>様式DDD1-1-1</text>
</article>
</structual-data>', 'PostgreSQL/doc/work_process/process_1-3033.pdf');
-- 報告書データの投入(一部抜粋)
INSERT INTO damage_reports (order_sequence_number, content, document_path) VALUES
('1-3033', '
<structual-data>
<article>
<title>破損報告書1(サンプル)</title>
<section>報告書ID</section><text>2025060701</text>
<section>発生場所</section><text>東京工場 生産機3</text>
<!-- 中略 -->
</article>
</structual-data>', 'doc/damage_reports/damage_report_2025060701.png');
破損報告書の構造化データ処理
構造化された報告書の中身を確認するシステムプロンプトは以下の通りです。
def extract_structured_info(self, report_content: str) -> Optional[Dict[str, str]]:
"""LLMを使用して報告書から構造化された情報を抽出"""
if not self.azure_client:
st.error("Azure OpenAIクライアントが利用できません")
return None
try:
# Azure OpenAI GPTデプロイメント名を環境変数から取得
gpt_deployment = os.getenv("AZURE_OPENAI_DEPLOYMENT_NAME", "gpt-4")
st.write(f"🔧 使用LLMモデル: {gpt_deployment}")
system_prompt = """
あなたは製造業の破損報告書から情報を抽出する専門家です。
与えられた報告書の内容から、以下の項目を抽出してJSON形式で回答してください。
項目名が以下と異なる場合があります。意味合いを考慮して適切に抽出してください。
情報が明記されていない項目は「未記載」として返してください。
抽出項目:
- 報告書ID ※報告書を識別する一意のID
- 部署 ※報告書を提出した部署
- 報告者 ※報告書を提出した人の名前
- 報告日 ※報告書が提出された日
- 発生場所 ※破損が発生した場所
- 発生日 ※破損が発生した日
- 管理部署 ※報告書を管理する部署
- 管理者名 ※報告書を管理する人の名前
- シーケンス番号 ※報告書のシーケンス番号
- 物品名 ※破損した物品の名前
- 数量 ※破損した物品の数量
- 状況 ※破損の状況
- 理由 ※破損の理由
- 処理内容 ※破損に対する処理内容
回答形式:
{
"報告書ID": "値",
"部署": "値",
"報告者": "値",
"報告日": "値",
"発生場所": "値",
"発生日": "値",
"管理部署": "値",
"管理者名": "値",
"シーケンス番号": "値",
"物品名": "値",
"数量": "値",
"状況": "値",
"理由": "値",
"処理内容": "値"
}
"""
これにより、多少の項目揺れがあっても統一された項目名で出力されるようになります。(LLMによる処理なので絶対ではありませんが...)
作業工程管理票と報告書の構造化データ処理
構造化された作業工程管理票と報告書中身を横断的に分析するシステムプロンプトは以下の通りです。
def analyze_with_context(self, report_content: str, related_documents: List[str],
user_question: str) -> Optional[str]:
"""関連する構造化データを含めた包括的分析"""
context_prompt = f"""
以下の構造化データを分析してください:
【破損報告書(構造化データ)】
{report_content}
【関連する作業工程管理票(構造化データ)】
{chr(10).join(related_documents)}
これらの構造化データの関連性を理解し、以下の質問に答えてください:
{user_question}
構造化データのタグ構造(<section>、<text>、<img>など)を活用して、
データ間の関連性を正確に把握して分析してください。
"""
今回のアプリでは報告書を先に検索させるため、報告書が決まればそれに紐づく作業工程管理票のデータを外部キーで取得できるようになっています。このプロンプトではその取得した構造化データを代入してLLMに渡しています。
4. 検証
では、ここから実装したアプリケーションの検証結果について説明します。以下が実装したUIの全体像です。

検証1:異なるフォーマットからの情報抽出
まず、この検索クエリで「不注意による事故」と入力して検索します。
すると以下の通り、登録されている破損報告書2つのうち、記載内容に「不注意による落下」と記載されている報告書のほうが高い類似度で検索されました。
※右側には報告書(damage_report_2025060701.png)と、その報告書に紐づく作業工程管理票(process_1-3033.pdf)が表示されています。

ここから本題です。
現在の記載内容(画像の灰色になっている個所)は人が読むにはわかりにくいため、LLMにデータを抽出させます。「AIで情報を抽出」を押すと、上記で指示したシステムプロンプトに従い、以下のように整形されたデータを表示してくれました。
※比較のため、元ドキュメント画像を表示させています。

同じように、もう一つの報告書も同様にAIで情報を抽出・表示させてみます。

見比べると、どちらも項目名に適した情報を抽出してくれているように見えます。2つの報告書は違うフォーマットですが、構造化データにしてLLMで処理させることにより、同一項目としてデータを抽出することができました。
検証2:文書間の関連性を活用した分析
今度は、この報告書に紐づく作業工程管理票から構造化データを取得し、報告書と合わせてLLMに内容を分析してもらいます。
先ほどの検索結果のうち、「分析」タブを押して分析画面を表示させ、入力欄に「この破損の原因は何ですか?作業工程のどこに原因があると思われますか?」と入力し、分析実行してみます。

※比較のため、関連ドキュメントの画像を表示させてます
LLMの回答を詳しく見ていきます。
1つ目のポイントは、「作業工程の分析・順序確認の欠如」の章での指摘です。LLMは『順序確認が未記載となっており...』と分析していますが、これは実際のサンプルデータを確認しても該当箇所の記載が存在しないため、正確な分析ができていると判断できます。
2つ目のポイントは、「梱包作業中の不注意による落下」という指摘です。この内容は破損報告書に記載されている情報であり、LLMが複数の文書から必要な情報を適切に抽出し、関連付けて分析できていることを示しています。
このように、LLMは異なる文書間の情報を正確に把握し、統合的な分析が行えていることが確認できました。
5. まとめ
本記事では、構造化データとベクトル検索を組み合わせた文書の情報抽出、分析について検証を行ってみました。
検証の結果、2つの重要な知見が得られました。
1つ目は、異なるフォーマットの文書であっても、構造化データを活用することで統一的な情報抽出が可能であることが確認できた点です。特筆すべき点として、従来のRDBシステム構築で必要とされていた完全な正規化処理を行わなくても、構造化データの特性を活かすことで実用的なシステムが構築可能であることが分かりました。ただし、どの部分のデータを非正規化のまま扱うかについては、以下の観点から慎重な検討が必要です:
- データの更新頻度
- 検索・分析時の性能要件
- データの一貫性維持の重要度
2つ目は、RDBの外部キーによるリレーション管理を活用することで、文書間の関連性を明確に定義・保持した状態でLLMによる分析が確認できた点です。これにより、LLMの曖昧な回答(ハルシネーション)のリスクを低減することがある程度できるかもしれません。特に複数文書を横断した分析においては、この正確な関連性の保持が分析結果の信頼性向上に大きく寄与すると思われます。
とはいえ、今回の検証ではシンプルな階層構造のデータのみを扱っています。実際の業務文書では、2階層ではなく3階層、4階層と、より複雑な関連性を持った文書構成となっているケースも多いと考えられます。そのような複雑な階層構造においても同様の精度を実現できるかについては、引き続き検討が必要と感じました。
本実装が、皆様のAI-Ready Data活用の参考となれば幸いです。
ここまで読んでいただき、ありがとうございました。