はじめに
AWS Summit Tokyo 2019で開催されたAWS DeepRacer Leagueで表彰台に上がった3人(sola@DNP、OHNO@DNP、Take@DNPds)のモデルをログ分析ツールにかけてみたので結果を公開します。
ログ分析ツールはノートブックの形式で以下のAWS DeepRacerワークショップのGitHubで公開されています。
https://github.com/aws-samples/aws-deepracer-workshops/
また、ログ分析ツールの導入方法や使い方は
AWS DeepRacerのログ分析ツールを使ってみた
を参考にしてください。
注意
- 以下の内容は 2019 年 6 月 18 日時点のサンプルノートブックを対象にしています。その他のバージョンのノートブックでは利用できない可能性があります。
- ログの分析は、レースに出走し表彰台を飾ったモデルで、最後に実施したトレーニングおよび評価を対象にしています。
- 本記事は、あくまで個人の見解に基づいて記載しております。
ログ分析ツールの結果
1. Plot rewards per Iteration
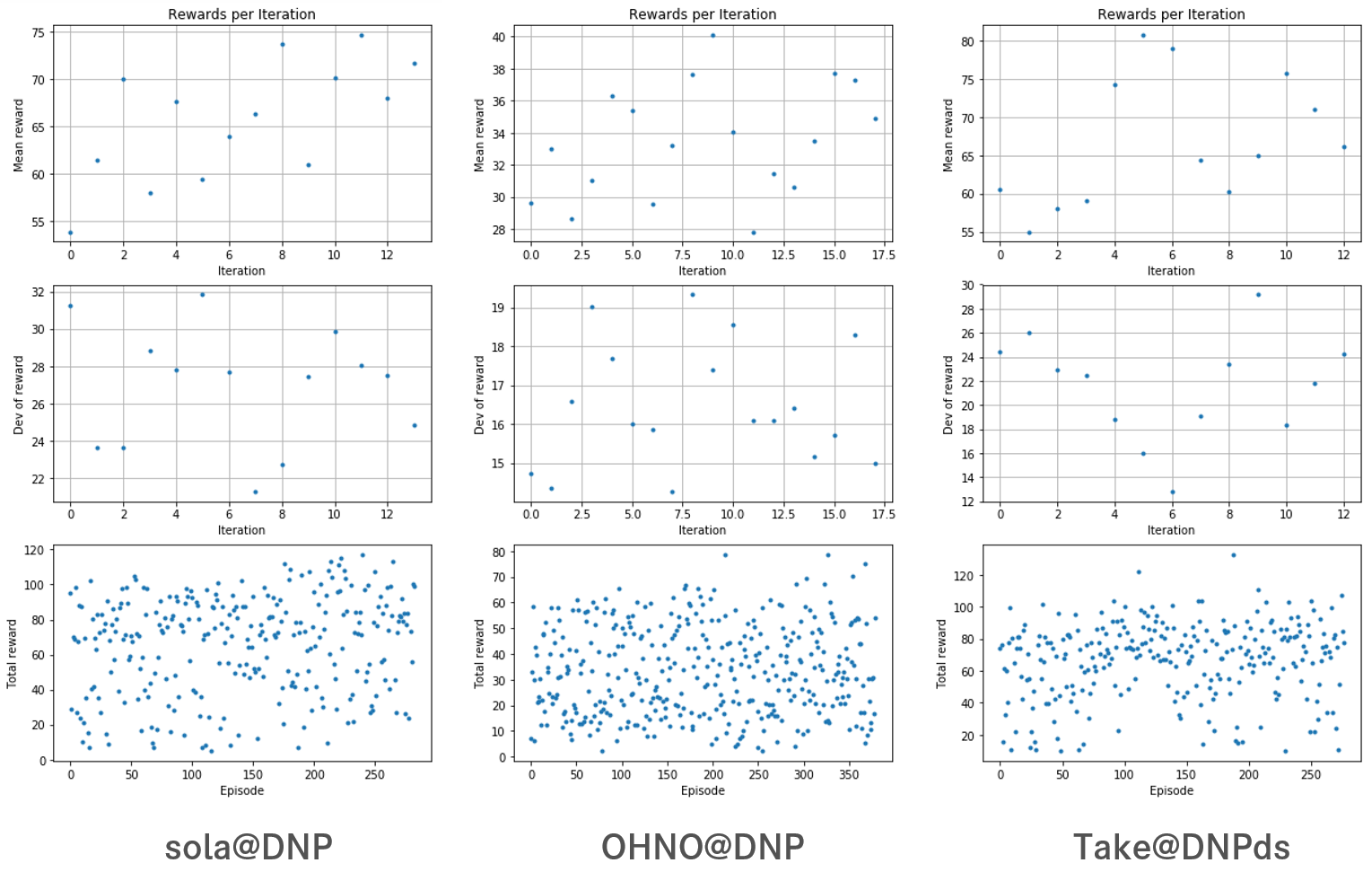
表示の都合上、同じ大きさにしていますが縦軸、横軸の数値がそれぞれ異なっています。
3つとも1stepあたりの最大報酬は1でした。
2. Reward distribution for all actions
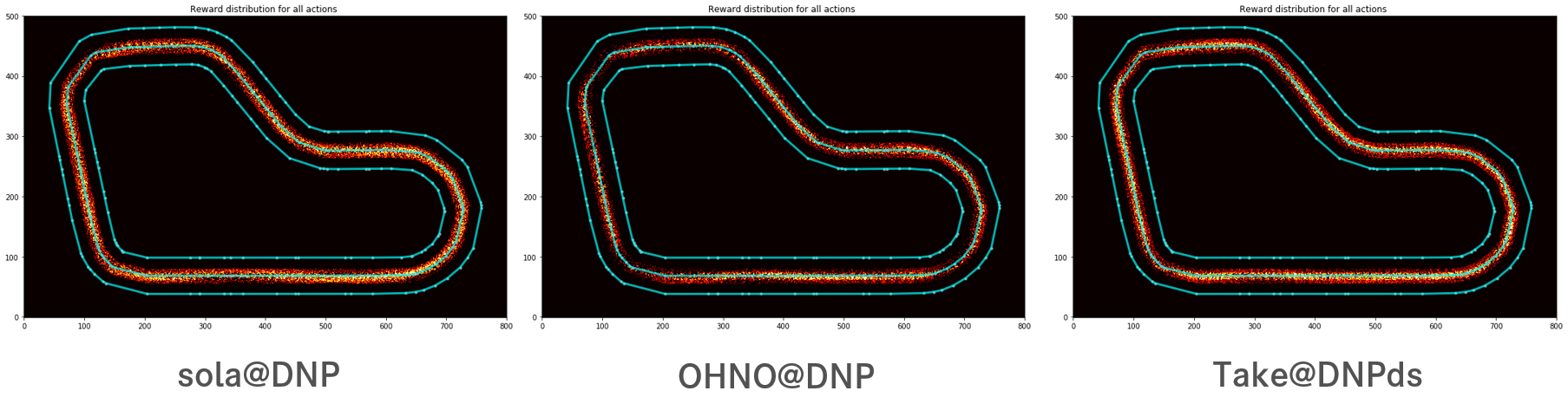
3. Path taken for top reward iteration
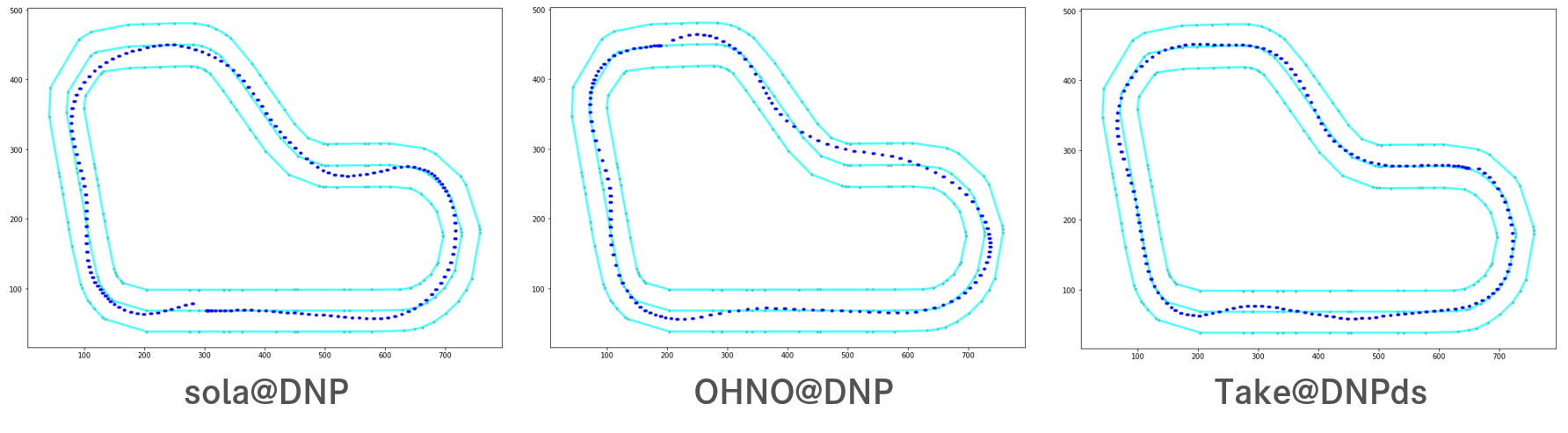
4. Path taken in a particular Iteration
5. Action breakdown per iteration and historgram for action distribution for each of the turns
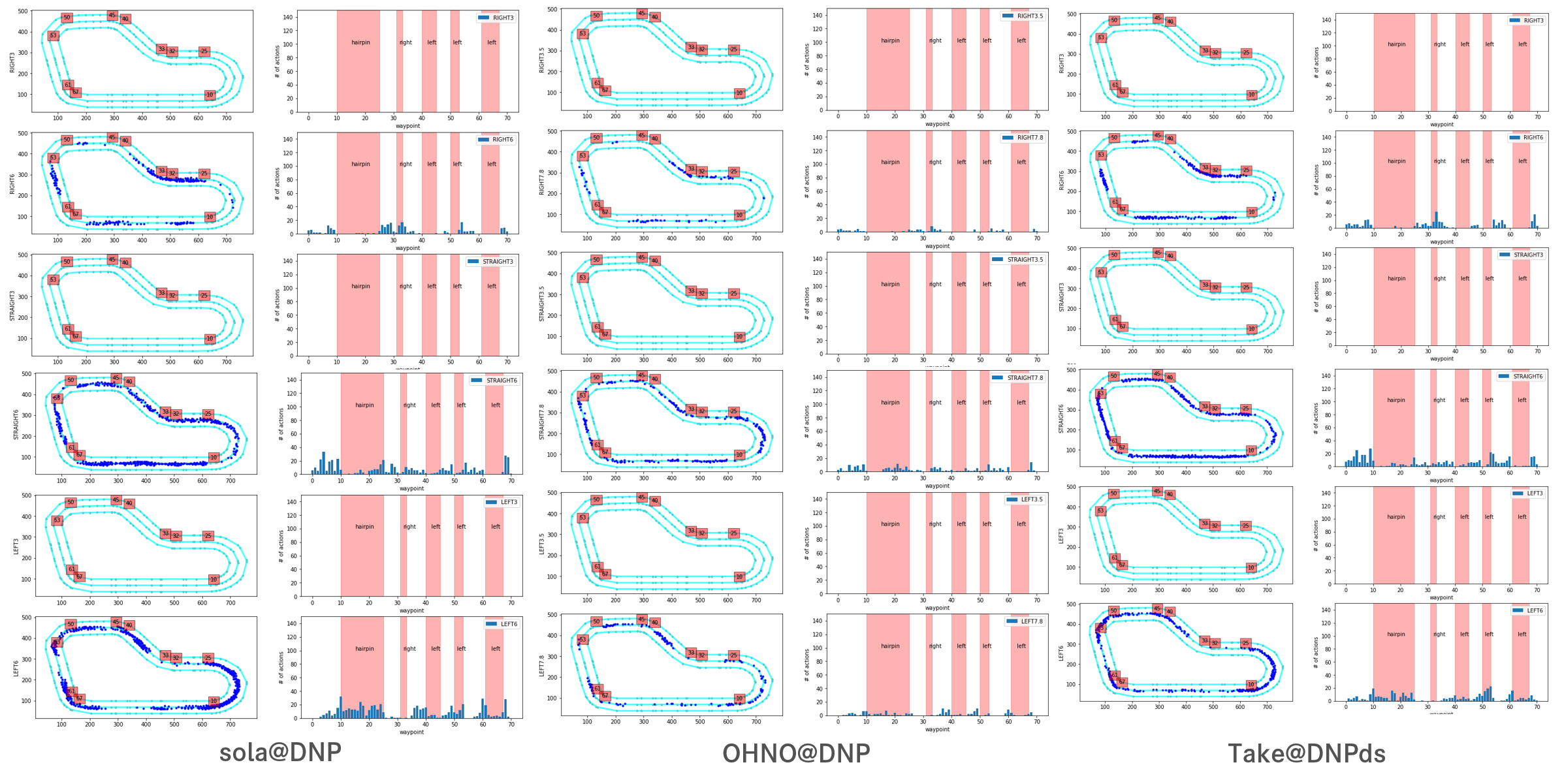
3つのモデル全てアクションスペースは6パターンでした。速度はヒストグラムの右上のラベルに数値で記載しています。
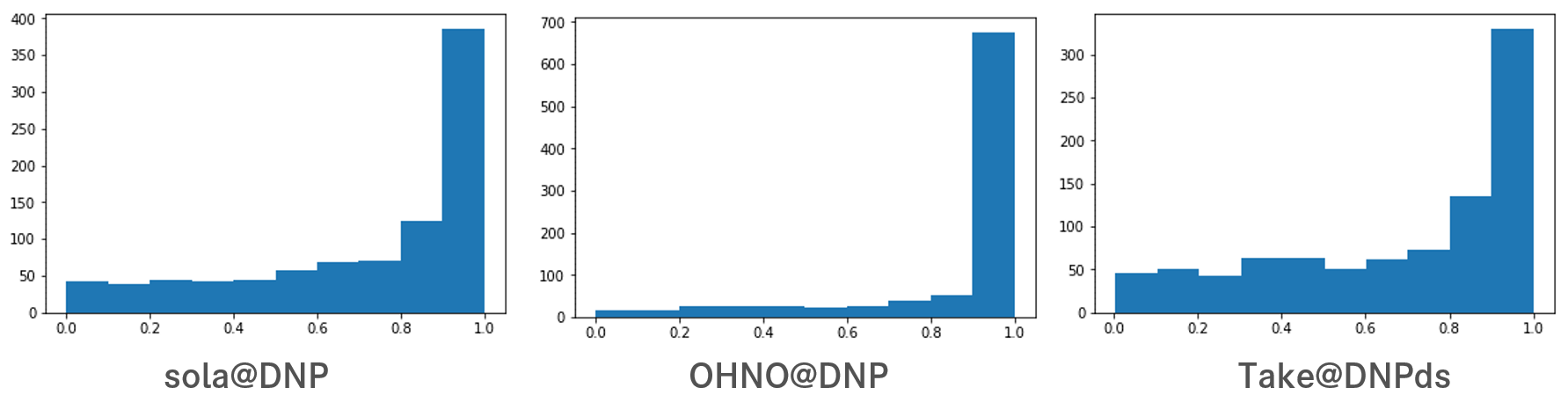
6. Simulation Image Analysis - Probability distribution on decisions (actions)
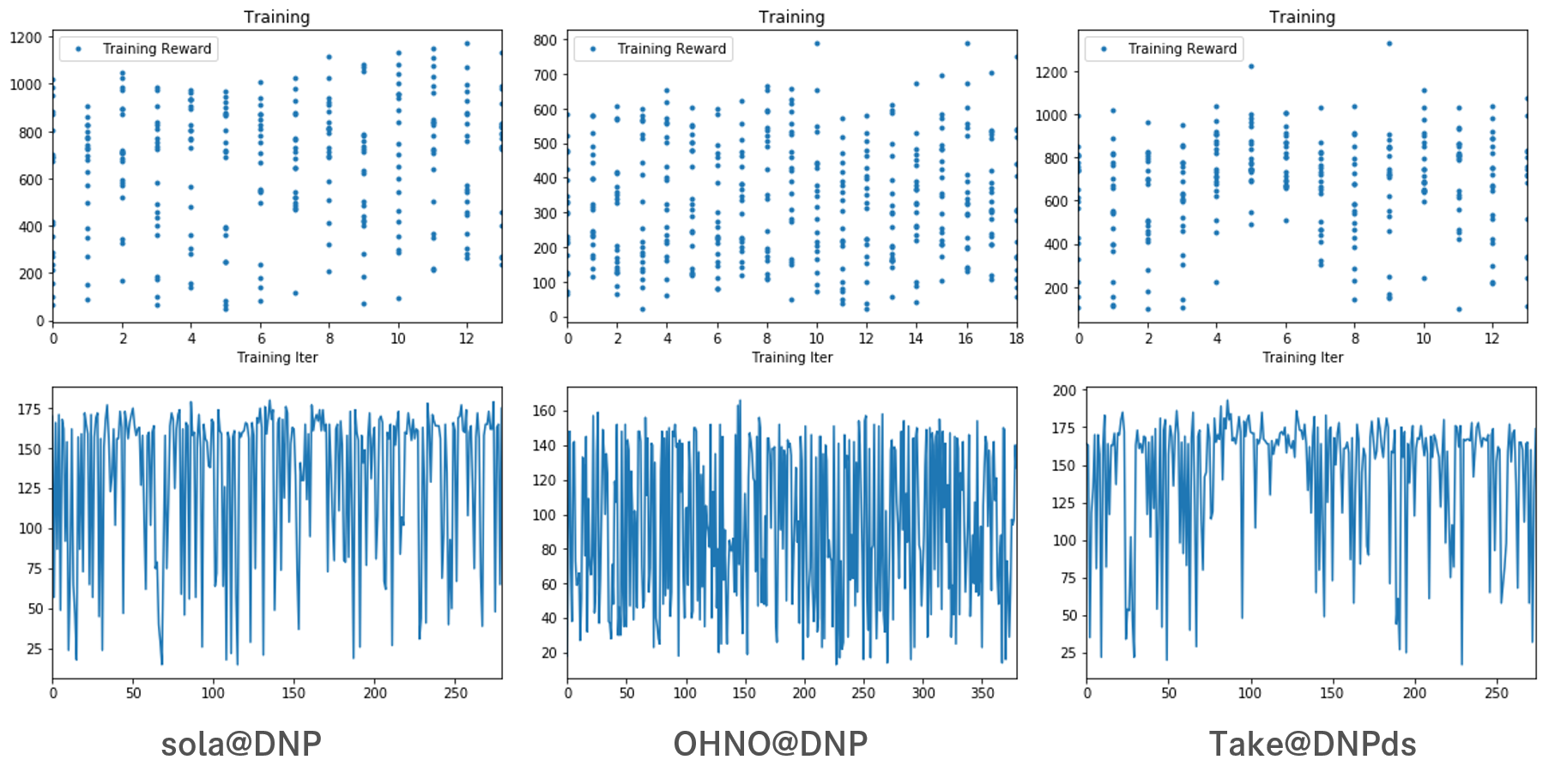
7. Model CSV Analysis
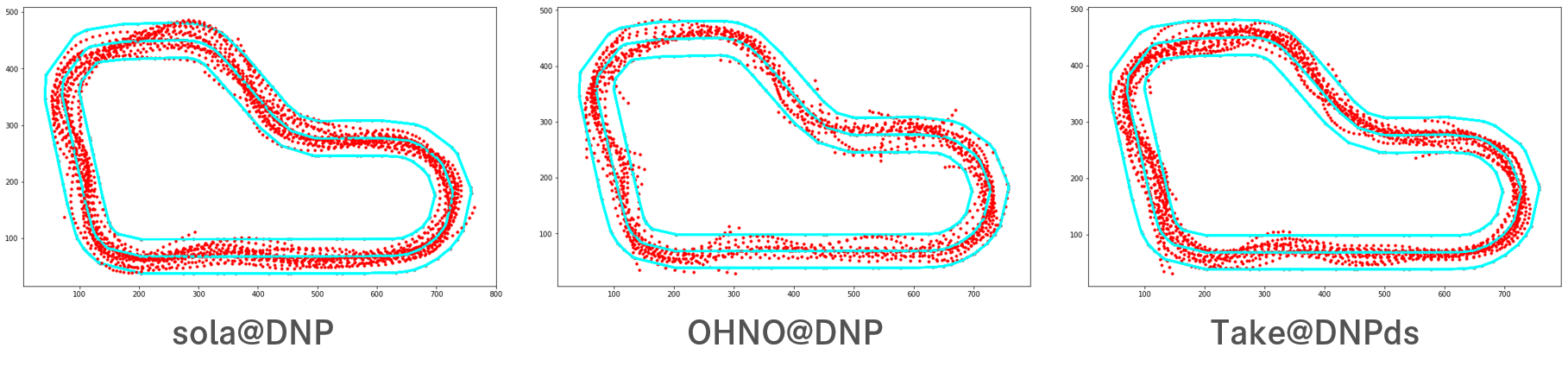
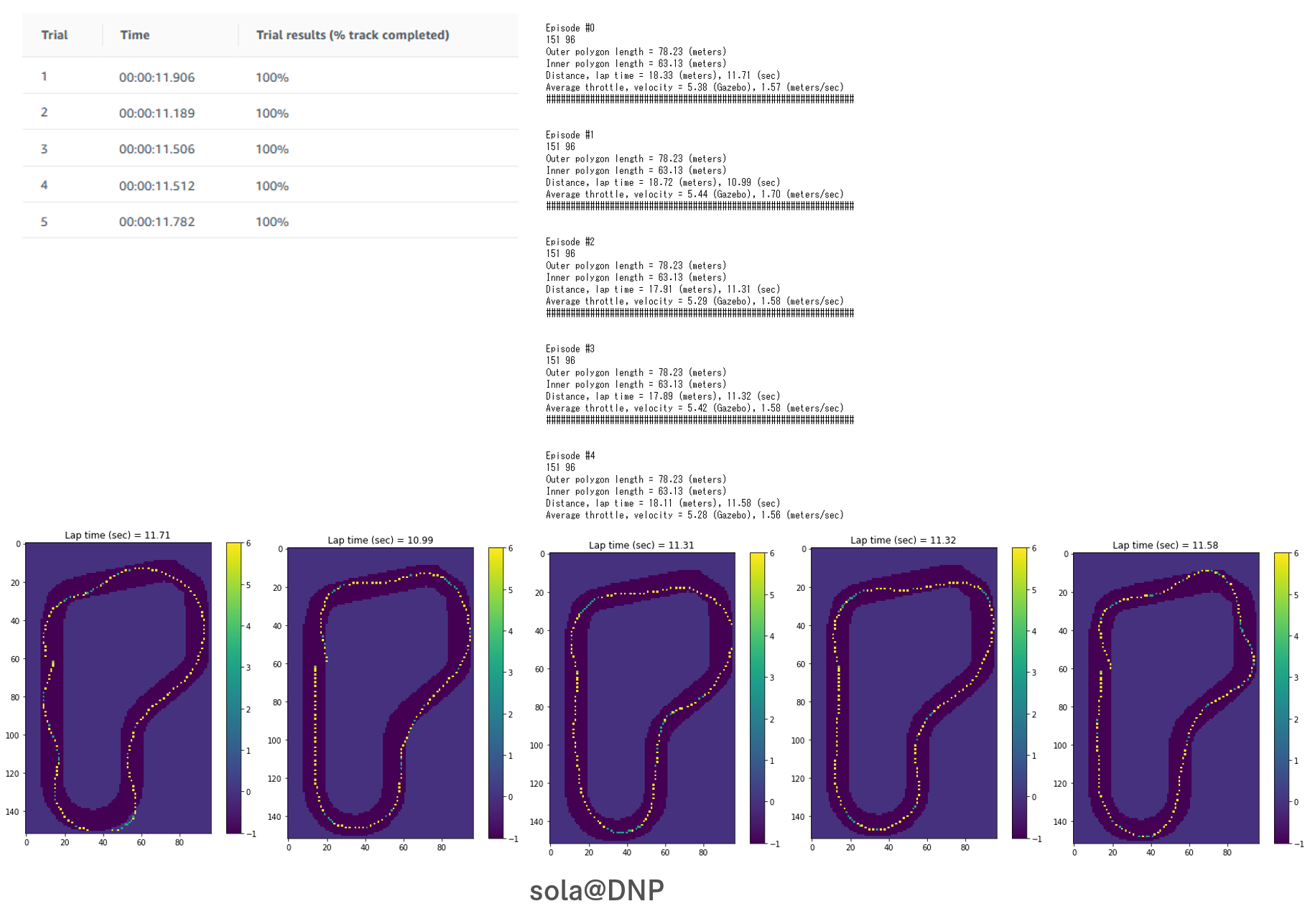
8. Evaluation Run Analysis
考察と感想
あくまで個人的な見解となりますが、3人の個性が分析結果にも現れているようでした。
sola@DNPの場合
インタビューでは「コースアウトしないような保守的なモデルを、、、」とのことですが、よく見ると大回りをすることで(走行距離は若干長くなりますが)、次のカーブでスピードを落とさず進む、大胆なアウトインアウトの傾向がトレーニングと評価でみられました。
※4. Path taken in a particular Iteration
※8. Evaluation Run Analysis
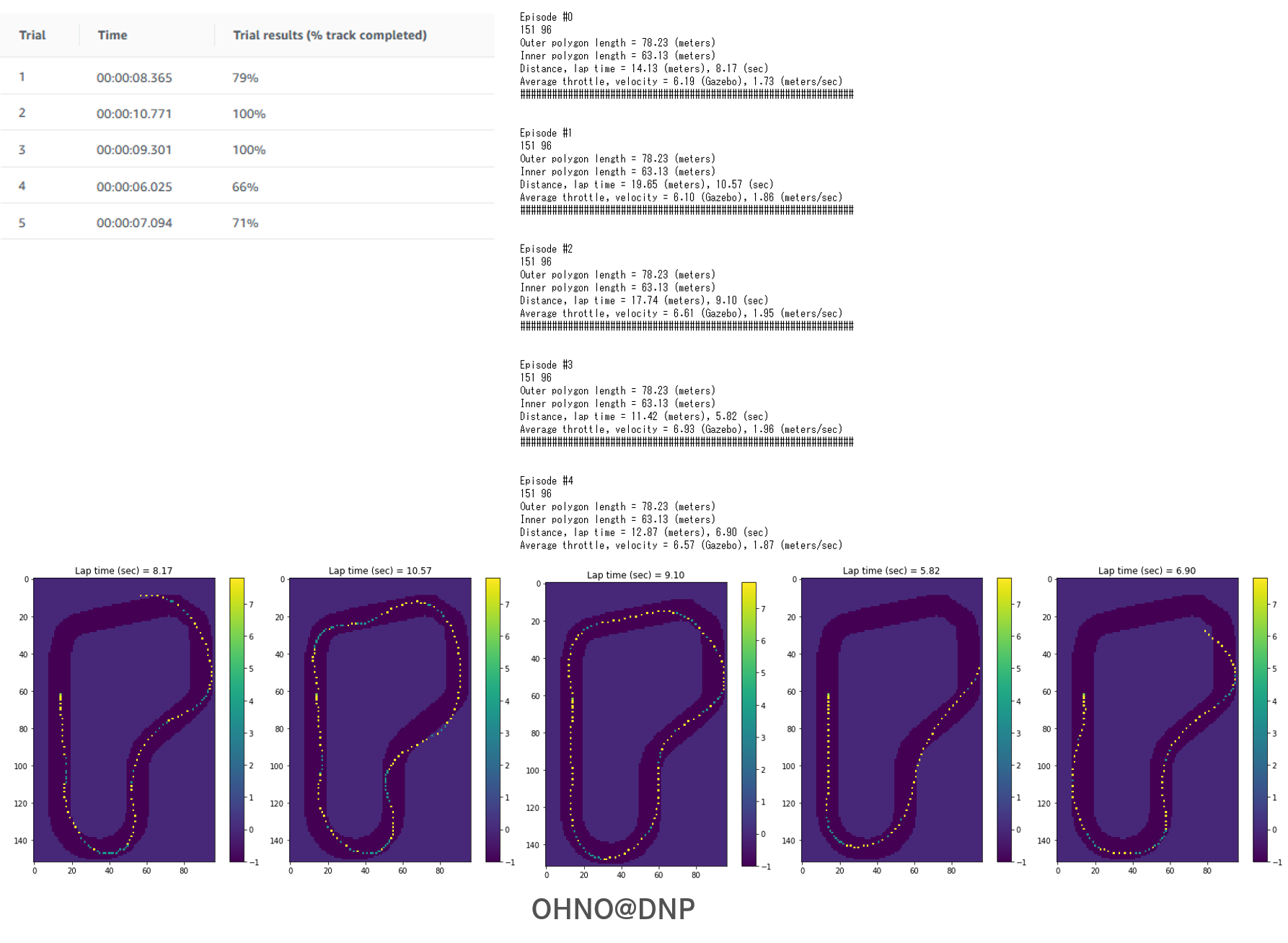
OHNO@DNPの場合
アクションスペースで設定しているスピードを見る限り、少しでも速く、0.1m/sでも速く、と攻めの姿勢ですが、アクションを決定する確率分布が他の二人よりずばぬけて高く、シミュレーションの評価結果に反して、sim2realへの走行も手堅く作っているようにうかがえます。
※5. Action breakdown per iteration and historgram for action distribution for each of the turns
※6. Simulation Image Analysis - Probability distribution on decisions (actions)
※8. Evaluation Run Analysis
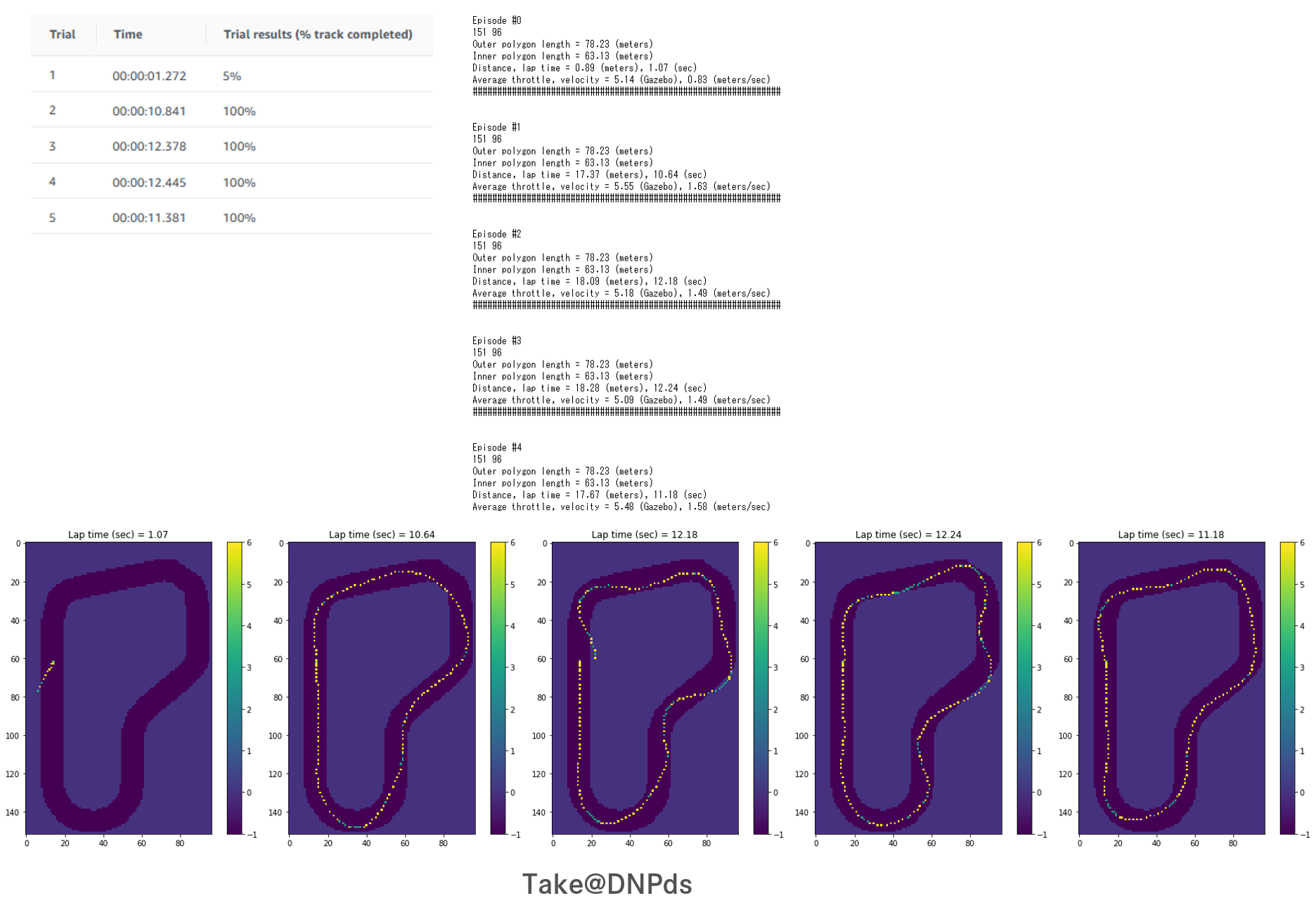
Take@DNPdsの場合
なにより清く正しく、ほぼセンターラインの真上を走行している軌跡は美しいです。
※3. Path taken for top reward iteration
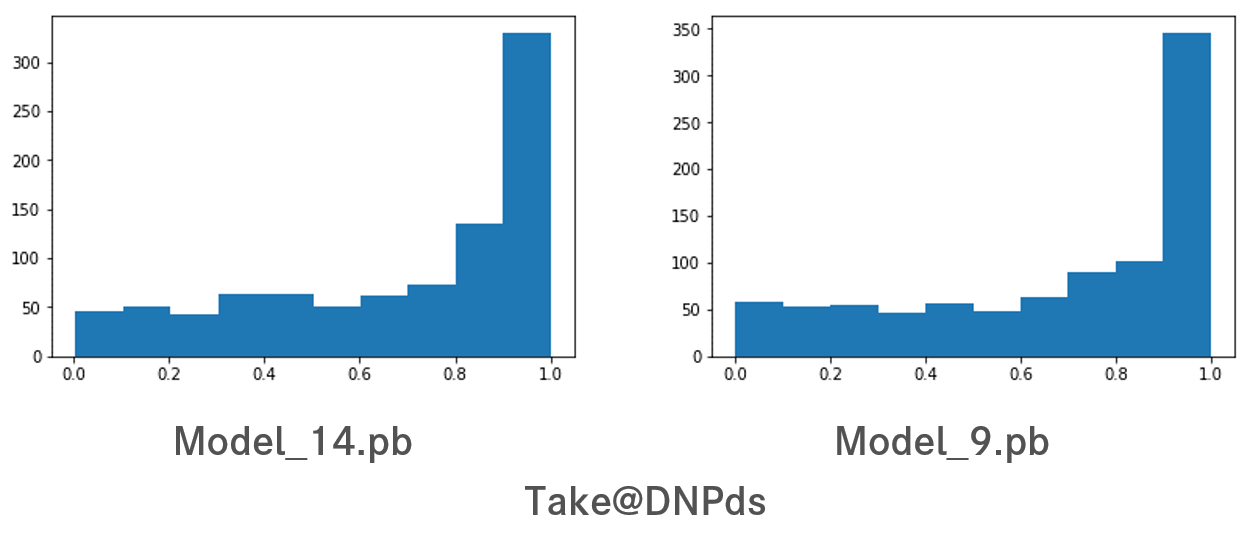
また、トレーニングの途中で報酬が高い平均とバラツキの少ない標準偏差の区間があったので、他の中間モデルのアクション決定の確率分布がどうなっているか気になったので取得してみたところ、最終モデル(左)より自信を持った選択ができそうなモデル(右)がありました。
もし、この中間モデルでチャレンジしていたら違う結果がでていたかもしれません・・・
その他
3人は社内レースでは別チームでライバルとして競い合い、それぞれモデルや方針も異なります。
分析結果から把握することはできませんが、全体のトレーニングでは3つのモデルとも
- 複数のコースを使ってトレーニングをする(過剰適合、過学習を防ぐ)
- クローンを繰り返す。1回目はある程度長めにトレーニングして、その後は短い時間(1時間くらい)で良いモデルを選択する
ということを実施していました。
Singapore SummitでAWS DeepRacerリーグに参加したときはシミュレーション評価で30秒の完走→実走行で12秒の完走というかけ離れた結果でしたが、今回の結果ではギャップが小さくなってきているようです。
最後に
社内にこのデータを公開した後に、SageMakerやJupyterNotebookを使ってみよう(自分のデータと比較したい)という人が増えました。
DeepRacerコンソール以外の、強化学習用のツールを使い始めるいいきっかけになればと思います。