基本的なことを書きました。
データベースの概観
データベースの中にはテーブルがあり、テーブルどうしが保管されたデータを紐付けあうことでデータを管理している。テーブルは二次元表の形で、縦列をカラムと呼び、横列をレコードと呼ぶ。
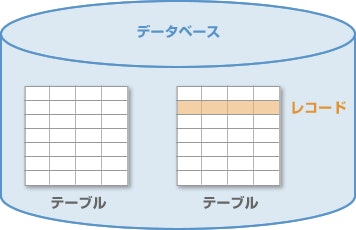
https://www.webolve.com/basic/aboutdb/ より
データベースの設計
次の二点を考える。
- データとして何を保存するのか?
- どのような形式で保存するのか?
データとして何を保存するのか?
最初にやること
- データを抽出
- エンティティを定義する(データを抽象化)
例:社員がページにアクセスすると、自分の所属部署と所属支店が表示されるページを作る
- 山田・宮越→社員の名前
- 広報部・営業部→所属部署
- 札幌・函館→所属支店
どのような形式で保存するのか?
| 名前 | 支店id | 支店名 | 部署id | 部署名 |
|---|---|---|---|---|
| 山田 | 1 | 札幌 | 1,2 | 広報部,営業部 |
| 宮越 | 3 | 函館 | 2 | 営業部 |
このような形でデータを保存しようとした場合、以下のようにまったく同じデータを保持する別人のデータを入れる必要が出た場合に、データを特定することが不可能になる。
| 名前 | 支店id | 支店名 | 部署id | 部署名 |
|---|---|---|---|---|
| 山田 | 1 | 札幌 | 1,2 | 広報部,営業部 |
| 山田 | 1 | 札幌 | 1,2 | 広報部,営業部 |
| 宮越 | 3 | 函館 | 2 | 営業部 |
この場合、社員にidを割り振ることで、仮に同じデータを持つ別人のデータが現れた場合にも対処が可能となる。
| 社員id | 名前 | 支店id | 支店名 | 部署id | 部署名 |
|---|---|---|---|---|---|
| 1 | 山田 | 1 | 札幌 | 1,2 | 広報部,営業部 |
| 2 | 山田 | 1 | 札幌 | 1,2 | 広報部,営業部 |
| 3 | 宮越 | 3 | 函館 | 2 | 営業部 |
テーブルの特徴
- テーブルは重複したデータを持つことができない
第一正規形
| 社員id | 名前 | 支店id | 支店名 | 部署id | 部署名 |
|---|---|---|---|---|---|
| 1 | 山田 | 1 | 札幌 | 1,2 | 広報部,営業部 |
| 2 | 宮越 | 3 | 函館 | 2 | 営業部 |
データを検索する際に、レコード毎にデータを一意に識別できる仕組みが必要となる。先程のデータは、部署id、部署名内に複数のデータが存在するため、社員idを用いてもレコードを一意に識別することができず、検索が困難である。そのため以下のように改変する。
| 社員id | 名前 | 支店id | 支店名 | 部署id | 部署名 |
|---|---|---|---|---|---|
| 1 | 山田 | 1 | 札幌 | 1 | 広報部 |
| 1 | 山田 | 1 | 札幌 | 2 | 営業部 |
| 2 | 宮越 | 3 | 函館 | 2 | 営業部 |
複数の部署に所属する人のデータのために行を追加することにより、社員idと部署idを用いてレコードを一意に定める(社員idと部署idが重複しない)ことが可能となる。このように、テーブル内において各レコードを一意に定めることを可能にする値を主キーという(ここでは社員idと部署id)また、このように検索に適したデータ形式を設計することを、正規化といい、そのようなデータ形式を正規形という。第一正規形とは、1つのセルに1つの値を持ち、主キーを用いてレコードを一意に定めることが可能なデータ形式である。
主キーのポイント
- データを検索する際に、レコード毎にデータを一意に識別できる仕組みが必要
- 主キーは、テーブル内のレコードを一意に識別して、紐付けるための値
- 主キーの値を指定すると、1行のレコードを特定できる
- 主キーは複数存在することもある
第二正規形
関数従属性とは
- 関数y=f(x)のように一つの値xが決まれば他の値yも一意に定まる性質
- すべての列が関数従属性を満たすようにテーブルを制作する
- テーブル上では主キーがy=f(x)のxにあたる値となる
- 主キーを決定することで、後続のデータが決定できる。(社員id→名前、支店id、支店名・部署id→部署名)
| 社員id | 名前 | 支店id | 支店名 | 部署id | 部署名 |
|---|---|---|---|---|---|
| 1 | 山田 | 1 | 札幌 | 1 | 広報部 |
| 1 | 山田 | 1 | 札幌 | 2 | 営業部 |
| 2 | 宮越 | 3 | 函館 | 2 | 営業部 |
第一正規化が完了したが、テーブル内において重複するデータの存在は言ってしまえば余計なものであり、また操作ミスによりデータベースに矛盾が生じやすい。
| 社員id | 名前 | 支店id | 支店名 | 部署id | 部署名 |
|---|---|---|---|---|---|
| 1 | 山田 | 1 | 札幌 | 1 | 広報部 |
| 1 | 山田 | 1 | 函館 | 2 | 営業部 |
| 2 | 宮越 | 3 | 函館 | 2 | 営業部 |
このデータベースを例にすると勤務先の変更でデータベースを書き換えるといった必要が出たときに、重複が存在すると何らかの操作ミスでデータの一部だけが書き換えられず残ってしまい、関数従属性が損なわれる事態になる可能性が高くなる。
このようなときは、主キーに関数従属的に対応するカラムだけを取り出し、分割すると良い。この例だと社員idとそれによって決まる名前・支店id・支店名を含むテーブルと、部署idとそれによって定まる部署名を含むテーブルに分ければ良い。
| 社員id | 名前 | 支店id | 支店名 |
|---|---|---|---|
| 1 | 山田 | 1 | 札幌 |
| 2 | 宮越 | 3 | 函館 |
| 部署id | 部署名 |
|---|---|
| 1 | 広報部 |
| 2 | 営業部 |
そして主キーだけを用いた新たなテーブルを作ることで、これらの情報を紐付けることができる。
| 社員id | 部署id |
|---|---|
| 1 | 1 |
| 1 | 2 |
| 2 | 2 |
このような分割により、重複した情報を減らすことで、矛盾の生じにくいデータベースを制作することが可能となる。1つの主キーに対応して値が決まるカラムがテーブル内の一部のみであり、残りのカラムでは別の主キーとの対応関係が成り立つ状態を部分関数従属という。
第二正規形とは
- 主キーと対応するカラムごとにテーブルを分割し、部分関数従属を無くす
- 第一正規形でのデータの重複に起因して、データベース内で矛盾が起こる可能性に対処する
- 1つのデータを変更したいときに書き換える箇所が1つだけとなるため、ミスが生じにくい
第三正規形
| 社員id | 名前 | 支店id | 支店名 |
|---|---|---|---|
| 1 | 山田 | 1 | 札幌 |
| 2 | 宮越 | 3 | 函館 |
第二正規形のときに分割された社員id側テーブルの関数従属性について社員id→支店id→支店名という二重の従属関係があることが分かる。このような構造を推移的関数従属という。推移的関数従属のデメリットとして、従属する側の属性のみを新たにデータベースに登録することができない点が挙げられる。このテーブルの例では、支店名は所属する社員(社員id)が無いと存在できないということになる。これを修正するためにはテーブルを更に分割する必要がある。
| 社員id | 名前 | 支店id |
|---|---|---|
| 1 | 山田 | 1 |
| 2 | 宮越 | 3 |
| 支店id | 支店名 |
|---|---|
| 1 | 札幌 |
| 2 | 旭川 |
| 3 | 函館 |
このように修正することで、第二正規形のデータベースを維持しながら推移的関数従属を排除し、社員idに依存せずに支店名のデータを登録することができるようになる。
完成形のデータベース
主キーとの関数従属性が存在し部分関数従属と推移的関数従属が無いことがポイント
| 社員id | 名前 | 支店id |
|---|---|---|
| 1 | 山田 | 1 |
| 2 | 宮越 | 3 |
| 支店id | 支店名 |
|---|---|
| 1 | 札幌 |
| 2 | 旭川 |
| 3 | 函館 |
| 社員id | 部署id |
|---|---|
| 1 | 1 |
| 1 | 2 |
| 2 | 2 |
| 部署id | 部署名 |
|---|---|
| 1 | 広報部 |
| 2 | 営業部 |
ER図
テーブルがたくさんあると見辛いため図を書いて中身と関係性を分かりやすくしたものである。テーブルどうしの関係としては1対1、1対多、多対多がある。制作にはdraw.ioを用いる。使い方はこの記事を参照。
1対1
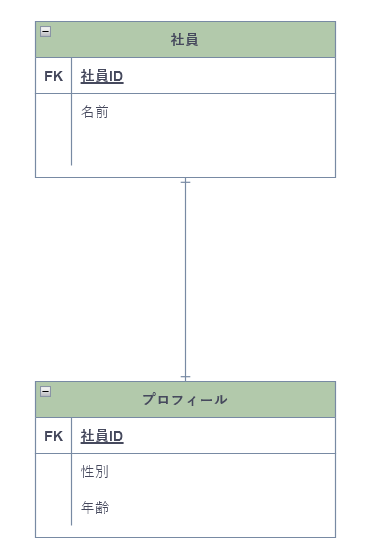
データベース双方のレコード(列)が1対1に対応する関係。推移的関数従属は起きないので1つのテーブルにまとめたほうが良く、この関係はあまり起きない。
1対多
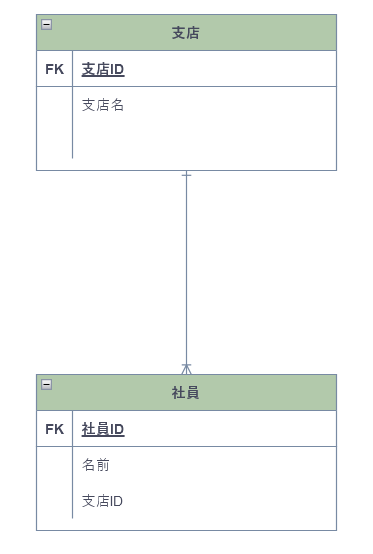
部署テーブルから見れば、部署テーブルの1つのレコードが同時に複数の社員テーブルのレコードと関連している(関連のないレコードもある)社員テーブルから見れば、社員テーブルの1つのレコードが部署テーブルの1つのレコードのみと関連している(関連のないレコードもある)正規化により生まれる。
- 例1)1:ブログの投稿者、多:ブログの投稿
- 例2)1:顧客、多:注文
- 例3)1:注文、多:注文明細
- 例4)1:部署、多:従業員
多対多
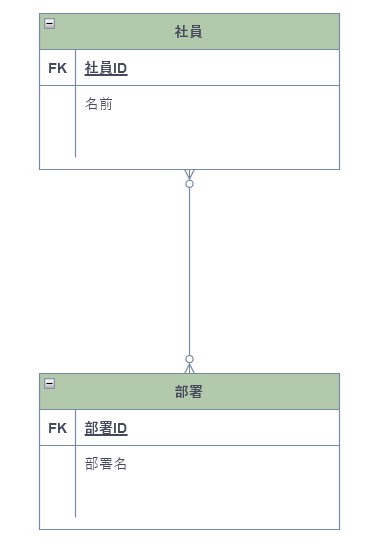
紐付けができない。例えば図に示された例ではそれぞれのテーブルに社員idと名前、部署idと部署名が書かれているがこれだけではどの社員がどの部署に配属されているかが分からず紐付けができない。これを紐付けるためには下図のようにどちらかのテーブルに部署idと部署名を載せる必要があるが、これによりできたテーブルは部分関数従属を持ち、第二正規化のできていないテーブルとなる。このようなテーブルを使うことは設計上NGである。
| 社員id | 名前 | 部署id | 部署名 |
|---|---|---|---|
| 1 | 山田 | 1 | 広報部 |
| 1 | 山田 | 2 | 営業部 |
| 2 | 宮越 | 2 | 営業部 |
- 例1)多:大学生、多:受講科目
- 1つの学生が複数の科目を選択でき、1つの科目は複数の学生によって選択される
- 例2)多:作曲者、多:楽曲
- 1つのアーティストが複数の楽曲を制作でき、1つの楽曲は複数のアーティストによって制作されることがある
- 例3)多:顧客、多:購入した製品
- 1つの顧客が複数の製品を購入でき、1つの製品は複数の顧客によって購入されることができます。
この場合中間テーブルを作ることで1対多の関係へ変換することが可能である。データベースの設計においては正規化を行うと自然に1対多の関係へ移っていくため、これを用いることが多い。
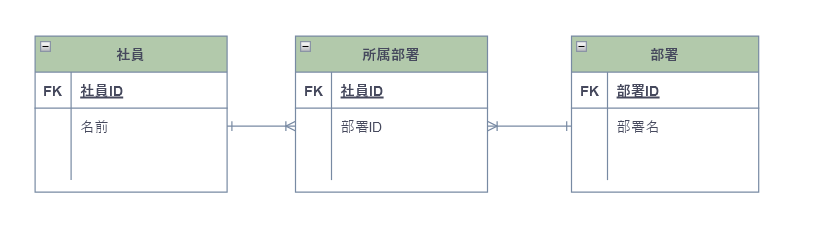
先程のデータベースをER図として表すとこのようになる
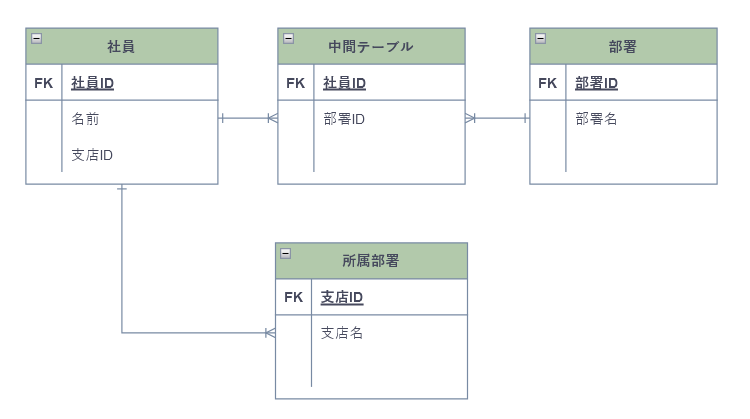
第三正規化されたデータベース
| 社員id | 名前 | 支店id |
|---|---|---|
| 1 | 山田 | 1 |
| 2 | 宮越 | 3 |
| 支店id | 支店名 |
|---|---|
| 1 | 札幌 |
| 2 | 旭川 |
| 3 | 函館 |
| 社員id | 部署id |
|---|---|
| 1 | 1 |
| 1 | 2 |
| 2 | 2 |
| 部署id | 部署名 |
|---|---|
| 1 | 広報部 |
| 2 | 営業部 |
テーブル定義
テーブルの定義時に決めること
- テーブル名
- カラム名
- データ型
- INT:整数
- VARCHAR:文字列
- DATE:日付
- PK(主キー)
- NOT NULL
- そのカラムにNULLデータを入れることを許すか
- デフォルト
- データを追加するとき、そのカラムに値を入れなかった場合に入力される値
先の例でテーブルを実際に作ってみる。
社員テーブル
| カラム名 | データ型 | PK | NOT NULL | デフォルト |
|---|---|---|---|---|
| id | INT | ◯ | ◯ | |
| name | VARCHAR(100) | ◯ | ||
| branch_id | INT | ◯ |
- VARCHAR(100)は最大文字数100文字という設定
部署テーブル
| カラム名 | データ型 | PK | NOT NULL | デフォルト |
|---|---|---|---|---|
| id | INT | ◯ | ◯ | |
| name | VARCHAR(30) | ◯ |
支店テーブル
| カラム名 | データ型 | PK | NOT NULL | デフォルト |
|---|---|---|---|---|
| id | INT | ◯ | ◯ | |
| name | VARCHAR(30) | ◯ |
中間テーブル
| カラム名 | データ型 | PK | NOT NULL | デフォルト |
|---|---|---|---|---|
| employee_id | INT | ◯ | ◯ | |
| department_id | INT | ◯ | ◯ |
中間テーブルのPKとしては、社員idと部署idの複合主キーを使うのが望ましい。PKは一意性(PKによってテーブル内の各レコードを一つ一つ識別できるということ)を持たなければならず、外部のテーブルのレコードと紐付けるための値となる必要がある。
| 社員id | 部署id |
|---|---|
| 1 | 1 |
| 1 | 2 |
| 2 | 2 |
中間テーブルは社員idと部署idの2つのカラムを持ち、社員idのみ、もしくは部署idのみをPKとして用いると、前者では1行目と2行目、後者では2行目と3行目の識別が不可能となる。しかし、両者をPKとして指定した場合は、所属部署を表すこのテーブルに同じ社員が同じ部署に所属しているというデータを2つ以上持たせることはないため、一意な識別が可能となる。また、外部の社員テーブル、部署テーブルとの紐付けにも2つのidが両方とも必要となる。
| 社員id | 名前 |
|---|---|
| 1 | 山田 |
| 2 | 宮越 |
| 部署id | 部署名 |
|---|---|
| 1 | 広報部 |
| 2 | 営業部 |
メモ
主キーの関数従属性とレコードを一意に定める性質を理解することが重要と感じた