AIを活用した漫画の彩色:基本的なセグメンテーションからキャラクター別学習までをざらっとまとめますが、今後大きなアップデートがあると思います。
現時点での概要と、サマリー
本記事では、AIを活用した漫画制作、特にベタ塗り(フラットカラーリング)プロセスの自動化と効率化について詳しく解説します。記事は2つの主要なパートで構成されています:
-
基本的なアプローチ:
- U-Netアーキテクチャを使用した画像セグメンテーションモデルの基本的な実装
- データセットの準備、モデルのトレーニング、推論プロセスの説明
- 実際の漫画制作ワークフローへの統合方法
-
高度なキャラクター別学習アプローチ:
- キャラクター固有の情報を学習し適用する拡張モデル
- キャラクター埋め込み、キャラクター認識を含む改良されたU-Netモデル
- 拡張データセットとトレーニングプロセス
- 実際の制作環境での応用例
subgraph "基本的なアプローチ"
A[線画の準備] --> B[データセットの作成]
B --> C[U-Netモデルの構築]
C --> D[モデルのトレーニング]
D --> E[基本的なセグメンテーション]
E --> F[初期カラーリング]
F --> G[アーティストによる調整]
end
subgraph "高度なキャラクター別学習アプローチ"
H[キャラクターデータベースの作成] --> I[キャラクター埋め込みの実装]
I --> J[キャラクター認識U-Netの構築]
J --> K[拡張データセットの作成]
K --> L[キャラクター認識モデルのトレーニング]
L --> M[キャラクター別セグメンテーション]
M --> N[キャラクター固有のカラーリング]
N --> O[アーティストによる微調整]
end
subgraph "継続的な学習と改善"
P[新規ページの処理] --> Q[キャラクター識別]
Q --> R[スタイルの適用]
R --> S[アーティストのフィードバック]
S --> T[モデルの更新]
T --> P
end
G --> M
O --> P
style A fill:#f9d5e5,stroke:#333,stroke-width:2px
style H fill:#eeac99,stroke:#333,stroke-width:2px
style P fill:#d6eaf8,stroke:#333,stroke-width:2px
この記事は、AI技術が漫画制作プロセスをどのように革新し、アーティストの創造性をサポートできるかを示すとともに、AI支援ツールの限界と人間の創造性の重要性についても言及していますが、本番利用経験はありません。
将来の、漫画家、編集者、そしてAI開発者にとって、ちょこっと参考になれば幸いです。
パート1: AIを活用した漫画彩色の基本的アプローチ
漫画制作は複数の段階を経る複雑なプロセスであり、その中でも「ベタ塗り」または「フラットカラーリング」は重要なステップです。従来、この作業は手動で行われており、時間と労力を要するものでした。AI技術、特に画像セグメンテーション技術を活用することで、このプロセスを大幅に効率化し、アーティストがより創造的な側面に集中できるようになります。
基本的なセグメンテーションモデル
1. モデルアーキテクチャ
基本的なアプローチとして、画像セグメンテーションタスクに適したU-Netアーキテクチャを使用します。U-Netは画像のローカルおよびグローバルな特徴を捉えることができるため、特に効果的です。
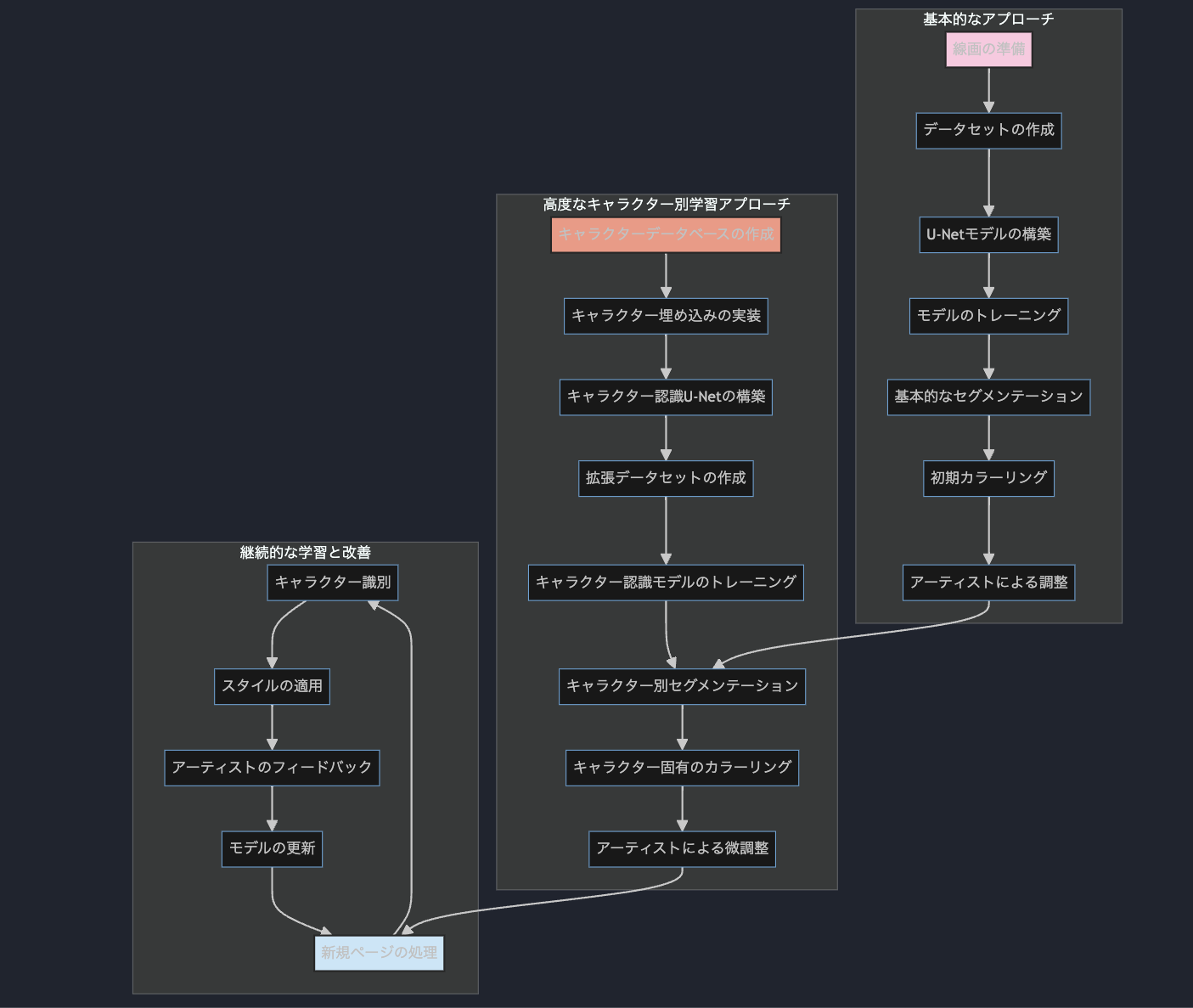
基本的なアプローチ:
線画の準備から始まり、データセットの作成、U-Netモデルの構築とトレーニングを経て、基本的なセグメンテーションと初期カラーリングを行います。
最後に、アーティストが調整を加えます。
高度なキャラクター別学習アプローチ:
キャラクターデータベースの作成から始まり、キャラクター埋め込みの実装、キャラクター認識U-Netの構築を行います。
拡張データセットを作成し、キャラクター認識モデルをトレーニングします。
これにより、キャラクター別のセグメンテーションとカラーリングが可能になり、アーティストがさらに微調整を加えます。
継続的な学習と改善:
新規ページの処理から始まり、キャラクター識別、スタイルの適用を行います。
アーティストからのフィードバックを受け、モデルを更新します。
このプロセスが循環的に続き、システムが継続的に学習・改善されていきます。
import torch
import torch.nn as nn
class UNet(nn.Module):
def __init__(self, n_channels, n_classes):
super(UNet, self).__init__()
# エンコーダー(ダウンサンプリング)
self.enc1 = self.conv_block(n_channels, 64)
self.enc2 = self.conv_block(64, 128)
self.enc3 = self.conv_block(128, 256)
self.enc4 = self.conv_block(256, 512)
# デコーダー(アップサンプリング)
self.dec4 = self.upconv_block(512, 256)
self.dec3 = self.upconv_block(512, 128)
self.dec2 = self.upconv_block(256, 64)
self.dec1 = self.conv_block(128, 64)
self.final = nn.Conv2d(64, n_classes, kernel_size=1)
def conv_block(self, in_c, out_c):
return nn.Sequential(
nn.Conv2d(in_c, out_c, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_c, out_c, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
def upconv_block(self, in_c, out_c):
return nn.Sequential(
nn.ConvTranspose2d(in_c, out_c, kernel_size=2, stride=2),
nn.Conv2d(out_c, out_c, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
def forward(self, x):
# エンコーダー
e1 = self.enc1(x)
e2 = self.enc2(nn.MaxPool2d(2)(e1))
e3 = self.enc3(nn.MaxPool2d(2)(e2))
e4 = self.enc4(nn.MaxPool2d(2)(e3))
# デコーダー
d4 = self.dec4(e4)
d3 = self.dec3(torch.cat([d4, e3], dim=1))
d2 = self.dec2(torch.cat([d3, e2], dim=1))
d1 = self.dec1(torch.cat([d2, e1], dim=1))
return self.final(d1)
2. データセットの準備
モデルをトレーニングするためには、漫画画像とそれに対応するセグメンテーションマスクのペアからなるデータセットが必要です。これらのマスクは、画像の異なる領域(例:キャラクター、背景、吹き出しなど)を異なる色や数値でラベル付けします。
from torch.utils.data import Dataset
from PIL import Image
import os
class MangaSegmentationDataset(Dataset):
def __init__(self, image_dir, mask_dir, transform=None):
self.image_dir = image_dir
self.mask_dir = mask_dir
self.transform = transform
self.images = os.listdir(image_dir)
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
img_path = os.path.join(self.image_dir, self.images[idx])
mask_path = os.path.join(self.mask_dir, self.images[idx].replace('.jpg', '_mask.png'))
image = Image.open(img_path).convert("RGB")
mask = Image.open(mask_path).convert("L")
if self.transform:
image = self.transform(image)
mask = self.transform(mask)
return image, mask
3. トレーニングプロセス
クロスエントロピー損失関数とAdamオプティマイザを使用した標準的なトレーニングループを使用します。
import torch.optim as optim
from torch.utils.data import DataLoader
def train_model(model, train_loader, val_loader, num_epochs, device):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
for epoch in range(num_epochs):
model.train()
for images, masks in train_loader:
images, masks = images.to(device), masks.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, masks.long().squeeze(1))
loss.backward()
optimizer.step()
# ここにバリデーションコードを追加
return model
# 使用例
model = UNet(n_channels=3, n_classes=5).to(device)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32)
trained_model = train_model(model, train_loader, val_loader, num_epochs=50, device=device)
4. 推論
トレーニングが完了したら、新しい漫画画像のセグメンテーションに使用できます。
def segment_manga(model, image_path, device):
image = Image.open(image_path).convert("RGB")
# 必要な前処理を適用
input_tensor = transform(image).unsqueeze(0).to(device)
model.eval()
with torch.no_grad():
output = model(input_tensor)
output = output.squeeze().cpu().numpy()
output = np.argmax(output, axis=0)
return output
# 使用例
segmentation_result = segment_manga(trained_model, "new_manga_image.jpg", device)
実際の応用
実際の漫画制作シナリオでは、この基本的なセグメンテーションモデルを以下のようにワークフローに組み込むことができます:
- 前処理: アーティストの線画をスキャンまたはシステムにインポートします。
- AIセグメンテーション: トレーニングされたモデルが線画を処理し、セグメンテーションマップを生成します。
- 色の割り当て: セグメンテーションマップに基づいて、異なる領域に初期色が自動的に割り当てられます。
- アーティストのレビュー: アーティストがAIが生成したフラットカラーリングをレビューし、必要に応じて調整を行います。
- 仕上げ: アーティストが陰影、テクスチャ、最終的な仕上げを加えて彩色プロセスを完了させます。
このアプローチにより、初期のフラットカラーリングにかかる時間を大幅に削減し、アーティストがより創造的な側面に集中できるようになります。
パート2: 高度なキャラクター別学習
基本的なセグメンテーションモデルを基に、キャラクター固有のデザインやカラースキームを学習し適用する、より洗練されたシステムを作成できます。この高度なアプローチでは、異なる漫画家の独自のスタイルや個々のキャラクターの特徴を考慮します。
1. キャラクター埋め込み
まず、キャラクター固有の情報を埋め込むシステムを作成します:
import torch.nn as nn
class CharacterEmbedding(nn.Module):
def __init__(self, num_characters, embedding_dim):
super(CharacterEmbedding, self).__init__()
self.embedding = nn.Embedding(num_characters, embedding_dim)
def forward(self, character_id):
return self.embedding(character_id)
2. キャラクター情報を組み込んだ修正U-Net
U-Netアーキテクチャを修正して、キャラクター固有の情報を組み込みます:
class CharacterAwareUNet(nn.Module):
def __init__(self, n_channels, n_classes, num_characters, embedding_dim):
super(CharacterAwareUNet, self).__init__()
self.unet = UNet(n_channels, n_classes)
self.character_embedding = CharacterEmbedding(num_characters, embedding_dim)
self.fusion_layer = nn.Conv2d(n_classes + embedding_dim, n_classes, kernel_size=1)
def forward(self, x, character_id):
unet_output = self.unet(x)
character_info = self.character_embedding(character_id).unsqueeze(2).unsqueeze(3).expand(-1, -1, unet_output.size(2), unet_output.size(3))
combined = torch.cat([unet_output, character_info], dim=1)
return self.fusion_layer(combined)
3. トレーニングデータの拡張
データセットにキャラクター情報を含めるように拡張する必要があります:
class EnhancedMangaDataset(Dataset):
def __init__(self, image_dir, mask_dir, character_info_file, transform=None):
# ... (前の初期化コード) ...
self.character_info = self.load_character_info(character_info_file)
def load_character_info(self, file_path):
# JSONファイルからキャラクター情報をロード
# 形式: {"image_name.jpg": {"character_id": 1, "name": "キャラクターA", ...}}
import json
with open(file_path, 'r') as f:
return json.load(f)
def __getitem__(self, idx):
# ... (画像とマスクをロードする前のコード) ...
character_id = self.character_info[self.images[idx]]["character_id"]
return image, mask, character_id
4. トレーニングプロセス
キャラクター情報を組み込むようにトレーニングプロセスを更新します:
def train_character_aware_model(model, train_loader, val_loader, num_epochs, device):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
for epoch in range(num_epochs):
model.train()
for images, masks, character_ids in train_loader:
images, masks, character_ids = images.to(device), masks.to(device), character_ids.to(device)
optimizer.zero_grad()
outputs = model(images, character_ids)
loss = criterion(outputs, masks.long().squeeze(1))
loss.backward()
optimizer.step()
# ここにバリデーションコードを追加
return model
5. キャラクター認識を含む推論
新しい画像にモデルを適用する際、キャラクターを指定する必要があります:
def segment_manga_with_character(model, image_path, character_id, device):
image = Image.open(image_path).convert("RGB")
# 必要な前処理を適用
input_tensor = transform(image