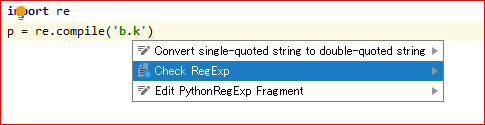
pycharmに「正規表現チェックツール」の呼び出す方法
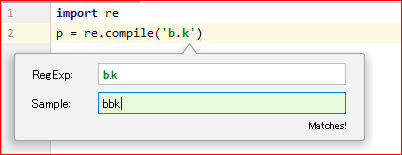
- カーソルは正規表現パターンの文字列中に置いて、「Alt+Enter」を押下して下記のポップアップウインドウズを呼び出すことができる
正規表現のメタ文字リファレンス
- 文字クラス
| pattern | 説明文 | サンプル |
|---|---|---|
| [abc] | a、b、または c (単純クラス) | pattern_01_01 |
| [^abc] | a、b、c 以外の文字 (否定) | pattern_01_01 |
| [a-zA-Z] | a から z または A から Z (範囲) | pattern_01_01 |
| [a-d[m-p]] | a から d、または m から p:[a-dm-p] (結合) | pattern_01_01 |
| [a-z&&[def]] | d、e、f (交差) | pattern_01_05 |
| [a-z&&[^bc]] | b と c を除く a から z:[ad-z] (減算) | pattern_01_06 |
| [a-z&&[^m-p]] | m から p を除く a から z:[a-lq-z] (減算) | pattern_01_07 |
- 定義済文字クラス
| pattern | 説明文 | サンプル |
|---|---|---|
| . | 任意の文字 (行末記号とマッチする場合もある) | pattern_02_01 |
| ¥d | 数字: [0-9] | pattern_02_02 |
| ¥D | 数字以外: [^0-9] | pattern_02_03 |
| ¥s | 空白文字: [ ¥t¥n¥x0B¥f¥r] | pattern_02_04 |
| ¥S | 非空白文字: [^¥s] | pattern_02_05 |
| ¥w | 単語構成文字:[a-zA-Z_0-9] | pattern_02_06 |
| ¥W | 非単語文字: [^¥w] | pattern_02_07 |
- 境界表現エンジン
| patten | 説明文 | サンプル |
|---|---|---|
| ^ | 行の先頭 | pattern_03_01 |
| $ | 行の末尾 | pattern_03_02 |
| ¥b | 単語境界 | pattern_03_03 |
| ¥B | 非単語境界 | pattern_03_04 |
| ¥A | 入力の先頭 | pattern_03_05 |
| ¥G | 前回のマッチの末尾 | pattern_03_06 |
| ¥Z | 最後の行末記号がある場合は、それを除く入力の末尾 | pattern_03_07 |
| ¥z | 入力の末尾 | pattern_03_08 |
- 最長一致数量子
| pattern | 説明文 | サンプル |
|---|---|---|
| X? | X、1 または 0 回 | pattern_04_01 |
| X* | X、0 回以上 | pattern_04_02 |
| X+ | X、1 回以上 | pattern_04_03 |
| X{n} | X、n 回 | pattern_04_04 |
| X{n,} | X、n 回以上 | pattern_04_05 |
| X{n,m} | X、n 回以上、m 回以下 | pattern_04_06 |
- 最短一致数量子
| pattern | 説明文 | サンプル |
|---|---|---|
| X?? | X、1 または 0 回 | pattern_05_01 |
| X*? | X、0 回以上 | pattern_05_02 |
| X+? | X、1 回以上 | pattern_05_03 |
| X{n}? | X、n 回 | pattern_05_04 |
| X{n,}? | X、n 回以上 | pattern_05_05 |
| X{n,m}? | X、n 回以上、m 回以下 | pattern_05_06 |
- 強欲な数量子
| pattern | 説明文 | サンプル |
|---|---|---|
| X?+ | X、1 または 0 回 | pattern_06_01 |
| X*+ | X、0 回以上 | pattern_06_02 |
| X++ | X、1 回以上 | pattern_06_03 |
| X{n}+ | X、n 回 | pattern_06_04 |
| X{n,}+ | X、n 回以上 | pattern_06_05 |
| X{n,m}+ | X、n 回以上、m 回以下 | pattern_06_06 |
参照したサイト
正規表現サンプル集
Regular Expression Test Drive
Pythonの正規表現モジュールreの使い方(match、search、subなど)
Java正規表現の使い方
基本的な正規表現一覧
サンプルソース(編集中)
サンプルの共通部分
reg_import.py
import re
pattern_01_01
reg_sample_01_01.py
# %% [abc]a、b、または c (単純クラス)
print(re.findall(r'[abc]', 'bbbacdef')) # ['b', 'b', 'b', 'a', 'c']
# [^abc]a、b、c 以外の文字 (否定)
print(re.findall(r'[^abc]', 'bbbacdef')) # ['d', 'e', 'f']
# [a-zA-Z]a から z または A から Z (範囲)
print(re.findall(r'[a-zA-Z]', 'Aa@Zz')) # ['A', 'a', 'Z', 'z']
# [a-dm-p]a から d、または m から p:[a-dm-p] (結合)
print(re.findall(r'[a-dm-p]', 'abcefmopq')) # ['a', 'b', 'c', 'm', 'o', 'p']
pattern_02_01
reg_sample_02_01.py
# %% 「.」任意の文字 (行末記号とマッチする場合もある)
# bから始まってkで終わる3桁の文字列
print(re.findall(r'b.k', 'bk')) # []
print(re.findall(r'b.k', 'bok')) # ['bok']
# 「*」直前のパターンを0回以上繰り返し
# bから始まってkで終わる2桁以上の文字列
print(re.findall(r'b.*k', 'bk')) # ['bk']
print(re.findall(r'b.*k', 'bok')) # ['bok']
print(re.findall(r'b.*k', 'bk bok book boook')) # ['bk bok book boook']
print(re.findall(r'b.*k', 'bbb')) # []
# 「+」直前のパターンを1回以上繰り返し
# bから始まってkで終わる3桁以上の文字列
print(re.findall(r'b.+k', 'bk')) # []
print(re.findall(r'b.+k', 'bok')) # ['bok']
print(re.findall(r'b.+k', 'bk bok book boook')) # ['bk bok book boook']
pattern_02_02
reg_sample_02_02.py
# %% 「\d」半角数字
# 半角数字1文字
print(re.findall(r'\d', '1234')) # ['1', '2', '3', '4']
print(re.findall(r'\d', 'a234')) # ['2', '3', '4']
# %% 「\d+」数字列
# 「+」直前のパターンを1回以上繰り返し
print(re.findall(r'\d+', '1234abc')) # ['1234']
print(re.findall(r'\d+', 'a1234abc')) # ['1234']
# %% 「\d{4}」4桁の数字
# 「{n}」直前のパターンをn回繰り返し
print(re.findall(r'\d{4}', '1234abc')) # ['1234']
print(re.findall(r'\d{4}', '123abc')) # []
# %% 「{n,}」直前のパターンをn回以上繰り返し
print(re.findall(r'\d{4,}', '1234 567890')) # ['1234', '567890']
print(re.findall(r'\d{4,}', '〒123-4567')) # ['4567']
# %% 「{n,m}」直前のパターンをn~m回以上繰り返し(最長一致)
# 最長一致なので、10桁の文字列を探して、なければ、9桁、8桁…の順に検索します。
print(re.findall(r'\d{4,10}', '1234 901234567890')) # ['1234', '9012345678']
print(re.findall(r'\d{4,10}', '123 4567')) # ['4567']
# %% 「?」直前の繰り返し指定を最短一致にする。
print(re.findall(r'\d{4,10}?', '1234 1234567890')) # ['1234', '1234', '5678']
print(re.findall(r'\d{4,10}?', '123 4567')) # ['4567']
pattern_02_03
reg_sample_03_02.py
# %% 「\D」半角数字以外
print(re.findall(r'\D', 'TEL:03-1234-5678')) # ['T', 'E', 'L', ':', '-', '-']
print(re.findall(r'\D', '1年1組')) # ['年', '組']