概要と狙い
本記事では代表的な画像認識AIであるGoogle Cloud Vision APIにロールシャッハ・テストを用いることで、現在の画像認識AIの立ち位置を普段人工知能が評価されている土俵とは異なった見地から照らします。
注意書き
ロールシャッハ・テストは濫用したり我流で行なうべきでなく、実施には専門家が必要です。この記事はあくまで好奇心に基づいた子どもの遊びであることを十分に理解した上でお読みください。この記事を読んだことにより今後のロールシャッハ・テストの結果に影響を及ぼすこともありえますので予めご了承ください。
準備
Google Cloud Vision API
https://cloud.google.com/vision/
ロールシャッハのインクブロット
https://commons.wikimedia.org/wiki/Rorschach_inkblot_test
前説1 - 深層学習における画像認識
まずは画像認識について簡単に説明します。そもそも深層学習で用いられるニューラル・ネットワークという仕組みはその名が示すとおりニューロン(神経細胞)の網目=神経回路網を真似て作られたものですが、画像認識でよく用いられる畳み込みネットワーク(CNN)は特に視神経の作りを参考にしています。
人の視覚システムは網膜から取り入れた光の刺激を視神経が処理することでその形や色や動きなどの認識を行なっています。目から入った信号は一度後頭部の視神経にまわり、その後は頭の上側(背側経路)と下側(腹側経路)の二手にわかれて処理されます。こうして信号が伝達されるなかで、はじめはフラットなデータだったものが、高度な構造や属性をもった情報として形成されていきます。
視神経のはじめの部分では、ニューロンは特定の方向を向いた棒状のものなど、極めて単純なパターンに強く反応します。それぞれのニューロンは別々のパターン認識特性を備えており、それを組み合わせて複雑な形を認識するにいたります。ここには位置関係に厳密な単純型細胞と、あいまいさを許容する複雑型細胞があります。畳み込みネットワークはこうした特性をヒントに、単純型細胞を畳み込み層として、複雑型細胞をプーリング層として設計されています。
今回用いるCloud Visionがどういったモデルになっているかはわかりませんが、概ね上のような構造を踏襲しているものと思われます。また既に厖大な学習が行なわれており、数百万の分類ができると言われています。例えばサラダの画像を見せると、単純に「サラダ」と答えるのではなく、個々のオブジェクトを検出することが可能です。
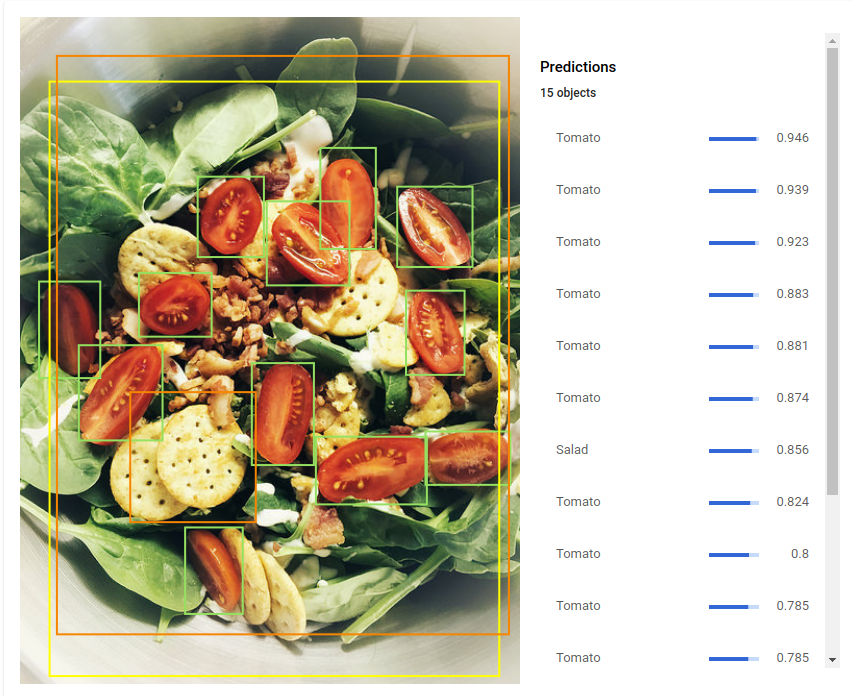
画像クレジット: H. Michael Karshis(CC BY 2.0、アノテーション入り UI で表示)
前説2 - ロールシャッハ・テストは分類か投影か
ロールシャッハ・テストはインクブロットという図版(紙にインクを垂らし、折りたたんで線対称にしたもの)を見せて「これは何に見えますか?」と聞くところから始まります。聞いて終わりではなく、その結果に対して追加の質問や励まし、そして結果に対する解釈が行われる点は今回の実験と異なりますが、スタートは一致しています。
ロールシャッハ・テストは突き詰めて言えばオブジェクト検出、つまり画像認識の一種ですから、ふだんから画像認識に親しんでいる方々からすれば、これがなぜ臨床心理として有効なのか疑問に思うかもしれませんので、それを説明しておきたいと思います。
きっとマシンラーニングに精通した人であれば「それはオブジェクト検出タスクであり、くだされる結果はモデリングと学習データによる」と思われるでしょう。この予想の半分はあたっています。実際にロールシャッハ・テストは発達の具合を観るためにも行われており、それは画像認識の精度を測っているわけです。(とはいえロールシャッハ・テストに正解・不正解があるわけではないので、精度の測り方も機械学習のやり方とは異なるのですが、それはいったん脇においておきます)
一方ですべてが分類の問題に帰すかといえばそうではありません。見せられた図柄が十分に曖昧なものであれば(つまりロールシャッハ・テストに用いるようなものであれば)、そこには心理学で「投影」と言われる現象が起こることが経験的にわかっています。投影とは、人が自身の裡に抱える資質や欲望や感情や葛藤をそれとは知らずに自己の外部に見出すことをいいます。ネガティブなときは何もかもが悲観的に感じられるように、人の知覚はその精神の影響を大きく受けるのです。
昔はロールシャッハ・テストにはつねに投影が起こっていると見た人たちもありましたが、現在はそうではなく、どの程度投影が起こるのかは人や図版によって異なると考えられています。一般に子どものほうが投影を起こしにくく、反応全体の三分の一程度と言われていますし、大人でも半分程度に過ぎません。それでは、人工知能は果たして投影を起こすでしょうか。そうしたことを今日は確認していきたいと思います。
前説3 - 投影と考えられる反応
ほとんどの人が牛と判断するイラスト(つまり牛のイラストです)を見せて「牛」と答えたとしたら、それはやはり画像分類に過ぎません。投影とみなせる反応は、大まかにわけて以下の3つがあります。
1. 運動反応
運動反応というのは図版を文字通り「運動している」とみなす反応です。図版自体は静止画ですから人が踊っているように見えるとか、動物がものを食べているように見えるという反応があるときは、その人の見方が図版に動きを付与していると考えます。
2. 形態水準がマイナスの反応
多くの人が見なかったものを見たケースを指します。たとえばほとんどの人にとって牛に見える図版が馬に見えるとか、牛以外描かれていないにも関わらず牛がUFOに攫われているというふうに見える場合には、やはりその人の抱える思いやイメージが、図版に描かれている以上の情報を与えてしまっていることになります。
3. 言語修飾されている反応
文字通り修飾されているものです。牛のような図版を見て「幸せそうな、しかしどこか虚ろな表情を浮かべながらボングを吸っている牛」と判断したら、そこにも受検者の心的イメージが投影されていると考えられます。
以上のような投影と考えられる反応以外にも形、色、濃淡、材質、立体、その他空白をどう見たかに至るまで、実際のテストでは専門家が反応を記録し、解釈に役立てています。
実験結果
それではお待ちかねの実験結果です。実際にはAPIで叩くことが多いと思いますが、わかりやすさのためにブラウザでの実行結果を表示します。10枚のインクブロットすべてで検査を行ないましたが、ここではそのうち図版Ⅲ、図版Ⅴ、図版Ⅶの実験結果のみを貼り付けておきます。
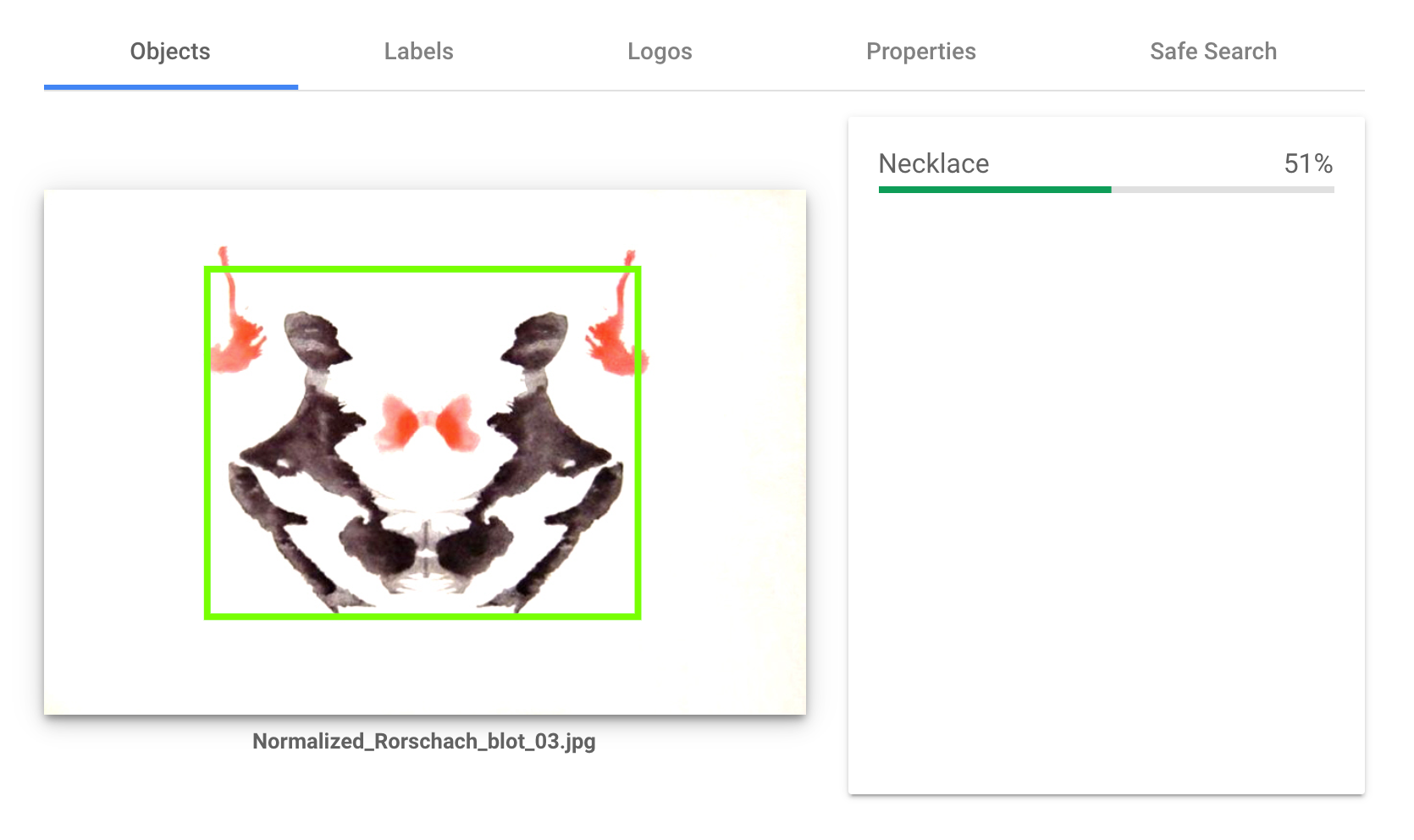
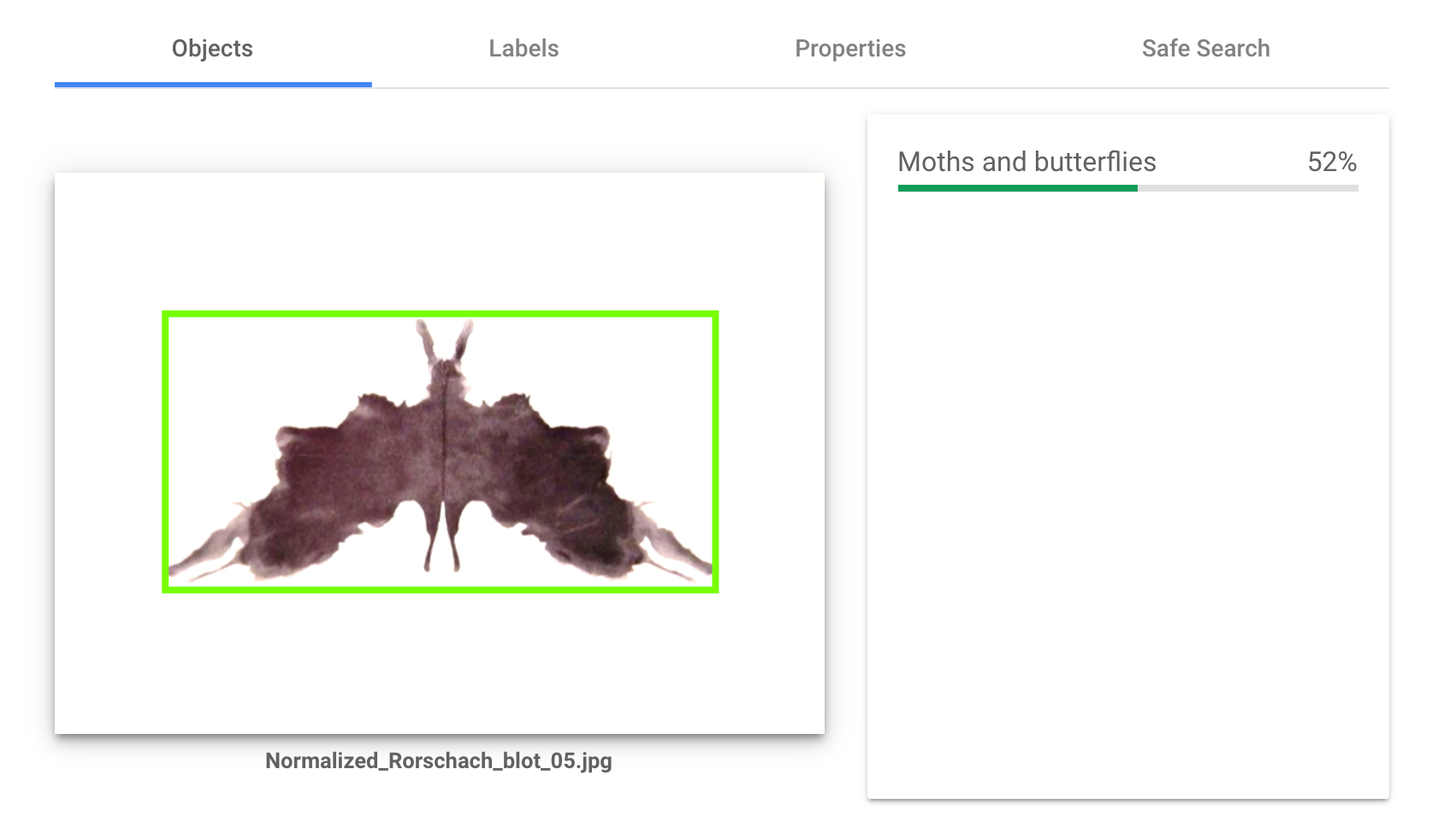
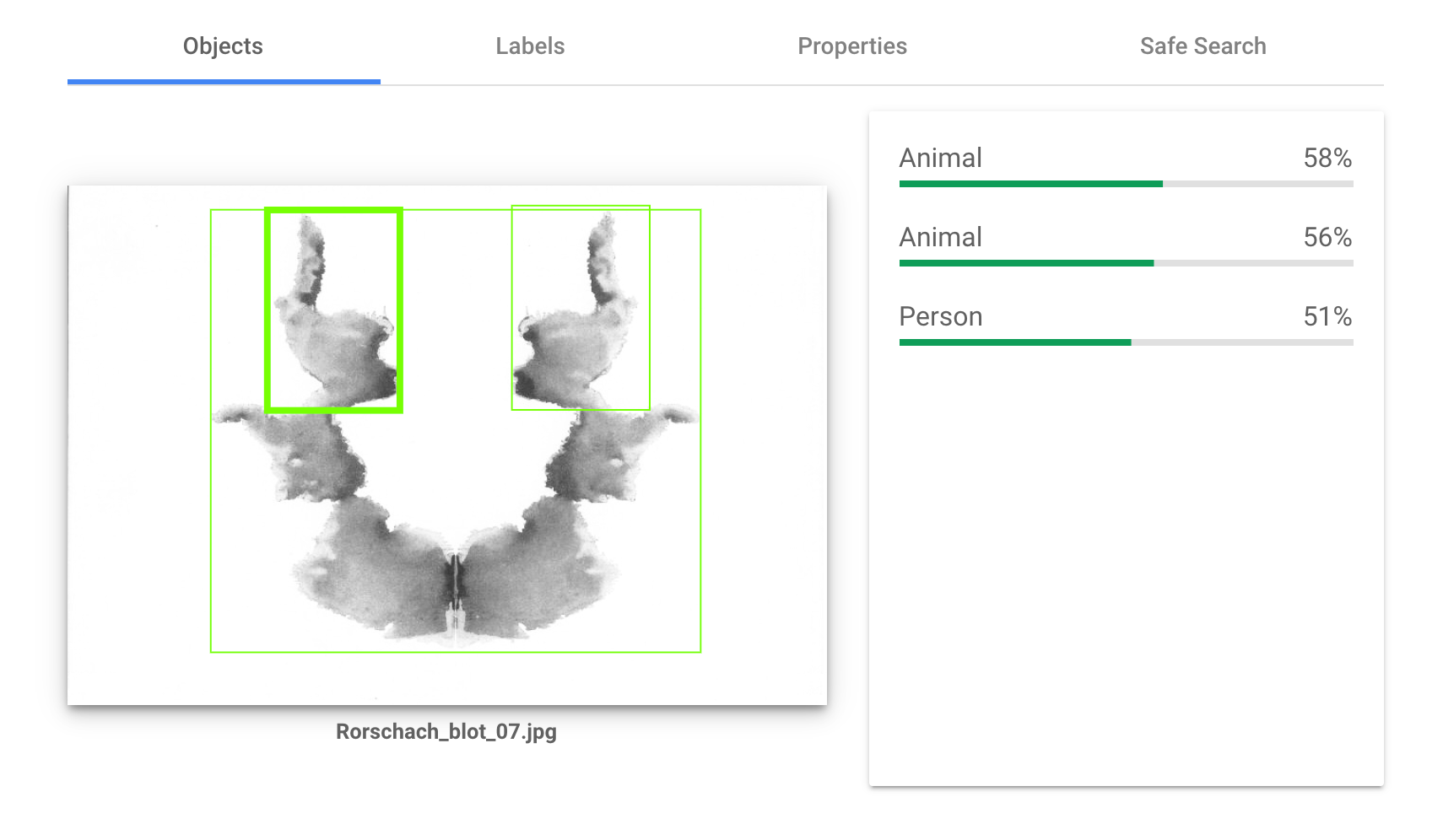
Cloud Visionのオブジェクト検出はとても興味深いものでした。オブジェクト検出においては何も検出しないかたった一つのオブジェクトを検出するケースがほとんどでしたが、その検出物はとても多岐に渡っており、事前に予想したものと違っているものが数多くありました。
またLabelsという項目では、たとえば風景画を調べさせると「風景画」「空」「雲」「夕焼け」といった項目があがるのですが、今回は「ペインティング」「アート」「ドローイング」といったものがほとんどで、いわば正確にこの図版の特徴を言い当てていました。10枚全てにおいてCloud Visionは「何かが描かれたペインティング」だと見ていたということになります。もしかするとこれを「ロールシャッハ・テストの図版」だと言い当ててくるかとも予想していましたが、そういったことはありませんでした。
検出するもののパターンとしては
- 人間
- 動物(蛾、単に動物)
- 衣服(ラケット、スカーフ、ネックレス、帽子)
- 家財道具(彫刻、照明)
があり、動物と衣服が多く検出されました。
実験結果と考察 - Cloud Visionは何を見たのか
まず抑えておきたいことはCloud Visionがこうした図版について、実際にオブジェクトを検出したということです。貼り付けたキャプチャの図版を見ていただければわかるとおり、これらは単にインクブロットであり、何かをスケッチしたり、写生したものではありません。それにも関わらずCloud Visionは場合によっては複数のオブジェクトを見出すことができました。またそれらは輪郭をもたないような曖昧なものではなく、明確なオブジェクトとして検出されました。
そして最も重要なことは反応がすべて「形態反応」であるということです。これは受検者の個人的な心理をまったく使わずに、「そこにある事実」だけを使って、自分のことを何も語らずに行なうことができる反応です。残念なことに、投影は見受けられませんでした。形態反応が反応の多くを占めるパーソナリティは「ハイラムダ・スタイル」と呼ばれ、このような人はシンプルなやり方を好む傾向を示しており、複雑さを好まず、ルールや決まったルーティンに従って物事を遂行するのを好むと言われています。Cloud Visionは(そしておそらく多くの画像分類器は)こうしたパーソナリティを備えた人工知能であると見立てられます。
これは人工知能であれば当然の帰結であると思われる方もいるでしょうが、そうではなく、人が人工知能をそのようにデザインしているのだと見たほうがよいでしょう。昨今は大喜利AIや、より人間に近づけたファジーなAIが登場してきたように人工知能のオルタナティブなデザインというのは十分にありえます。今後は運動反応や言語修飾を伴ったオブジェクト検出が可能になるような画像分類器が出現し得るでしょうし、もう既にあるのかもしれません。
また今回予想外に興味深かったのは、衣服が多く見られたという点です。人そのものの検出は決して多くありませんでしたが、人のまわりにあるものをCloud Visionは多く見出しました。これは単に学習の偏りでしょうか。もしくは人の認識そのものが(つまり人の認識するこの世界総体が)そのような偏りを持っているのでしょうか。この結果について、わたしたちはどう受け止めることができるでしょう。
まとめ - 人は機械を模倣する
「ある絵が何を表しているか」――この問いの答えは絵の側に、つまり「対象」にあるのでしょうか。それともそれを見ている側である「主体」にあるのでしょうか。
画像分類器はそれを「対象」にあると考えます。つまり画像分類や物体検出には「正解」があり、人工知能はその正解を精度高く当てるために進化を重ねます。正解はあくまで人間が定めますが、それも個人の恣意によって定まってはならず、多くの人間が納得できるような回答が正解とされます。
ロールシャッハ・テストでは「主体」にあると考えます。インクブロット自体はなんでもないイラストであり、それそのものに宿った正解なる対象はそもそもからして存在しません。始まりの質問はいつも「これは何に見えますか」であり、見ることから認識が始まります。
両者はどちらも極端なケースであり、わたしたちの生きる現実はそのあいだに存在しています。認識は主体と客体(対象)のどちらかに依存することなく、主客の関係から発生します。雨の呼び方の数が言語によって異なるように、認識は主体の多様性を抜きにして語れるものではありません。であれば、画像認識にだって本来はそのような主体のゆらぎが関与するはずです。そんなとき、人工知能はついに主体として、つまり「主体性」を獲得するのでしょう。そんな日の到来が楽しみでなりません。