はじめに
にゃーん😺💕
総務省「日本産業分類」CSVをあるだけ取ってくるやつです。
このコードは何がいいのか
- 階層がちょっと深い
- 現行と過去があって提供コンテンツにばらつきがある
- マーケティング実務で役に立つ=ほしいのは、最新の「分類項目名」CSVだけ
- 日本標準産業分類は数年おきに改定がある=ほしい先のURLが変わる
- ファイル名の採番がお役所独自のもので覚えていられない
- ソースコードを少し変えれば、公開されているPDFも取得できる
上記にすべて対応しています。
動作環境
- Python 3.7.3
- Debian GNU/Linux 10 \n \l (#RaspberryPi 4)
コード開陳
# !/usr/bin/env python3
# coding: utf-8
### import
import os
import re
import sys
import requests
from bs4 import BeautifulSoup
import urllib.request
### variables
base_url = "https://www.soumu.go.jp/toukei_toukatsu/index/seido/sangyo/index.htm"
outputtxtlist = "./txt/sangyoguidelist.txt"
outputcsvlist = "./txt/sangyocsvlist.txt"
outputcsvdir = "./csv/"
outputcsvfile = "*.csv"
aelements = ""
prefixurl = "https://www.soumu.go.jp"
postfixurl = "[0-9]{2,3}index.htm"
### parser (01)
html = requests.get(base_url)
html.encoding = "shift_jis"
soup = BeautifulSoup(html.text, "html.parser")
aelements = soup.find_all("a")
#### if outputlist_file exists
if os.path.exists(outputtxtlist):
os.remove(outputtxtlist)
if os.path.exists(outputcsvlist):
os.remove(outputcsvlist)
### parse and writeout sangyolist.txt (stage 03)
for i in aelements:
ahrefurl = i.get("href")
if ahrefurl is not None:
mpost = re.search(r"[0-9]{2,3}index.htm", ahrefurl)
if mpost and "http" not in ahrefurl:
with open(outputtxtlist, mode="a") as f:
f.write(prefixurl + ahrefurl + "\n")
f.close()
### get links with specific postfix such as csv or pdf (stage 04)
with open(outputtxtlist) as f:
lines = f.readlines()
f.close()
for j in lines:
html = requests.get(j.rstrip("\n"))
html.encoding = "shift_jis"
soup = BeautifulSoup(html.text, "html.parser")
aelements = soup.find_all("a")
for k in aelements:
ahrefurl = k.get("href")
if ahrefurl:
mpost = re.search(r"csv", ahrefurl)
if mpost:
with open(outputcsvlist, mode="a") as f:
f.write(prefixurl + ahrefurl + "\n")
f.close()
### download csv file(s) and save locally as binary (stage 05)
with open(outputcsvlist) as f:
lines = f.readlines()
f.close()
for m in lines:
mstripped = m.rstrip("\n")
csvfilename = os.path.basename(mstripped)
with urllib.request.urlopen(mstripped) as webf:
data = webf.read()
with open(outputcsvdir + csvfilename, mode="wb") as localf:
localf.write(data)
localf.close()
webf.close()
### end of this script
実行方法
'''
$ python3 getsangyolist.py
'''
10秒かからないと思います。
アウトプットは、./txt配下と./csv配下に保存されます。
出力
sangyoguidelist.txt
$ cat sangyoguidelist.txt
https://www.soumu.go.jp/toukei_toukatsu/index/seido/sangyo/19index.htm
https://www.soumu.go.jp/toukei_toukatsu/index/seido/sangyo/14index.htm
https://www.soumu.go.jp/toukei_toukatsu/index/seido/sangyo/59index.htm
https://www.soumu.go.jp/toukei_toukatsu/index/seido/sangyo/51index.htm
https://www.soumu.go.jp/toukei_toukatsu/index/seido/sangyo/47index.htm
https://www.soumu.go.jp/toukei_toukatsu/index/seido/sangyo/42index.htm
https://www.soumu.go.jp/toukei_toukatsu/index/seido/sangyo/38index.htm
https://www.soumu.go.jp/toukei_toukatsu/index/seido/sangyo/32index.htm
https://www.soumu.go.jp/toukei_toukatsu/index/seido/sangyo/29index.htm
https://www.soumu.go.jp/toukei_toukatsu/index/seido/sangyo/28index.htm
https://www.soumu.go.jp/toukei_toukatsu/index/seido/sangyo/26index.htm
https://www.soumu.go.jp/toukei_toukatsu/index/seido/sangyo/24index.htm
https://www.soumu.go.jp/toukei_toukatsu/index/seido/sangyo/H25index.htm
https://www.soumu.go.jp/toukei_toukatsu/index/seido/shokgyou/21index.htm
./txt 配下。
CSVのリンク元の案内ページの一覧です。
最新のH25年版は H25 とあるやつです。そこは実務の運用解決でお願いします。
これのコピペでもマニュアルに役立つかと思います。
sangyocsvlist.txt
$ cat sangyocsvlist.txt
https://www.soumu.go.jp/main_content/000420038.csv
https://www.soumu.go.jp/main_content/000587432.csv
https://www.soumu.go.jp/main_content/000587431.csv
./txt 配下。
元の案内ページに貼られたリンクです。ここから落としてきます。
最新のH25年版は 000420038.csv です。そこは実務の運用解決でお願いします。
これのコピペでwget / curlしても役立つかと思います。
取得したファイル
81289 Sep 26 12:20 000420038.csv
12491 Sep 26 12:20 000587431.csv
12491 Sep 26 12:20 000587432.csv
./csv 配下。
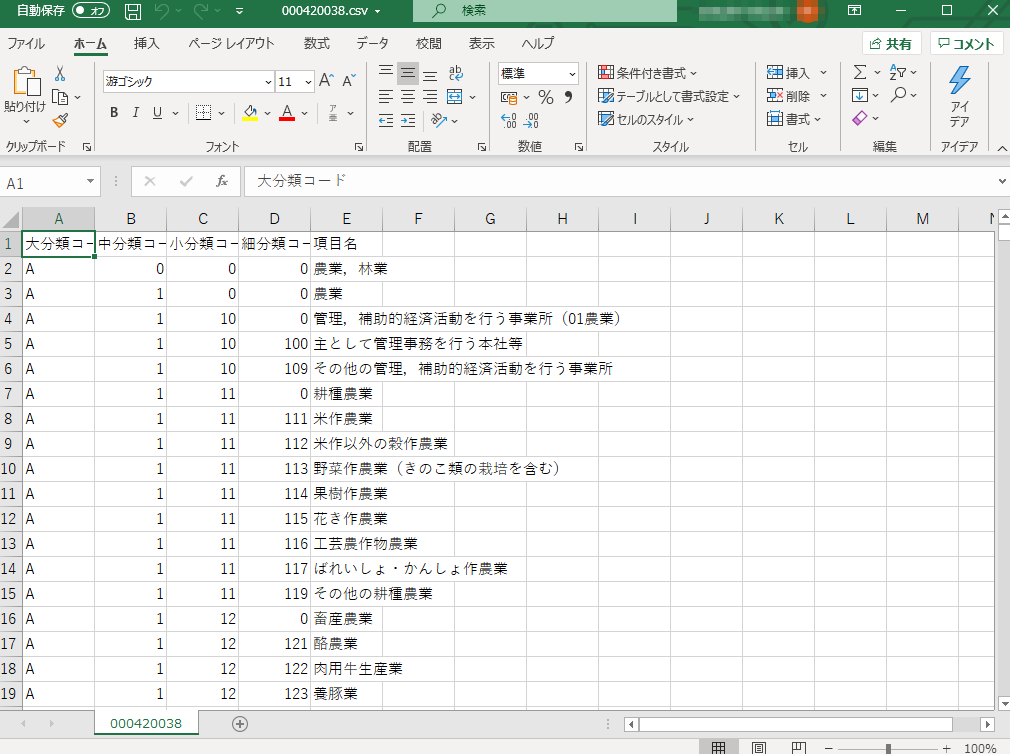
文字化けしません
sambaするなどして共有した先でダブルクリックでExcelで開いてGoです。
おしまい
(´(ェ)`)「デジタル庁が5年かかるとかいっているので、むしゃむしゃしてやった。まったく反省していない」
よかったですね。にゃーん。😺💕