記事公開後の追記
まずこちら第2回記事で成果物を得てそれから下記の話を、の流れでもOKです。
初めに
みなさんすばらしいfind/47というサイトはご存知でしょうか。
全国47都道府県の美しい風景画像が高画質で提供されています。当方調査によると2020年10月末日現在で日本全国合計1080種類あり、(画像にもよりますが)これをS, M, L, XLの解像度別にダウンロードすることが可能です。しかしながら公開されているアクセス数をざっと見た限りでは、十分に認知や活用がされているとはいえないようで、惜しまれます。
そこでこの記事(全2回+)では、Pythonを使用して(1)画像のリストを作成し、(2)ダウンロードし、さらに(3)Ubuntu/LXDEでvarietyを使い壁紙のオートチェンジ環境を実現する方法を紹介します。
レベル的には、「スクレイピングで実現したいことがあって、Pythonで実装し、確認する」入門的なものです。私自身、さほどのテクニックや最適化は図っていません。あらかじめご了承ください。最終的には、下記の画像のようなデスクトップを(個人的な趣味で)実現して満足する。それだけです。

留意事項
今回の第1回の記事では実行に影響ありませんが、画像のダウンロードには約10GBの空き容量が必要になります。第2回か第3回の記事で解像度を下げて画像のダウンロード容量を減らす方法について触れる予定です。
動作環境
各自適宜適当にやってください。
Ubuntu
$ cat /etc/issue
Ubuntu 20.04.1 LTS \n \l
Python
$ python3 --version
Python 3.8.5
installed by pip3
他にもあるかもしれません。コード冒頭を見て対応してください。
$ pip3 list
beautifulsoup4 4.8.2
requests 2.22.0
tqdm 4.50.2
動作概要とコード
動作概要
画像を保存するまでは6工程を経ます。今回の1/2記事では、そのうち1-3までの工程を行います。
具体的には、ダウンロード対象画像のリストを、ある程度の可読性の高い形でテキストファイルに出力します。まずページ送りを行いながら網羅的に可読性の低い形で作り(stage 01, インメモリ)、リストの各行にサイズ情報を付加し(stage 02, インメモリ)、CSV形式で出力します(stage 03, ファイル出力)。
ここまでで、何地方(0-7)の何県(0-46)の何というファイル名(注:拡張子なし)の何サイズ(xl, x, m, s)を取得し、そして合計で何枚の画像を取得できるのがか確定します。
コード(1)01_generate_urls.py
適宜適当なフォルダ(例、/home/nekoneko/codes/python/find47)を作り、その直下に01_generate_urls.pyのファイル名で保存してください。
# !/usr/bin/env python3
# coding+ utf-8
import csv
import re
import requests
import subprocess
import time
from bs4 import BeautifulSoup
# e.g. https://search.find47.jp/ja/images?area=kinki&prefectures=kyoto&page=3
# declare variables
base_url = 'https://search.find47.jp/ja/images?'
valid_urls = []
target_urls = []
areas = [ 'hokkaido', 'tohoku', 'kanto-koshinetsu', 'tokai-hokuriku', 'kinki',
'chugoku' , 'sikoku', 'kyushu-okinawa' ]
prefs_head_by_area = [ 0, 1, 7, 17, 24, 30, 35, 39 ]
prefs_count_by_area = [ 1, 6, 10, 7, 6, 5, 4, 8 ]
prefectures = [
'hokkaido' ,
'aomori' , 'iwate' , 'miyagi' , 'akita' , 'yamagata' ,
'fukushima',
'tokyo' , 'kanagawa' , 'saitama' , 'chiba' , 'ibaraki' ,
'tochigi' , 'gunma' , 'yamanashi' , 'niigata' , 'nagano' ,
'toyama' , 'ishikawa' , 'fukui' , 'gifu' , 'shizuoka' ,
'aichi' , 'mie' ,
'shiga' , 'kyoto' , 'osaka' , 'hyogo' , 'nara' ,
'wakatama' ,
'tottori' , 'shimane' , 'okayama' , 'hitoshima', 'yamaguchi',
'tokushima', 'kagawa' , 'ehime' , 'kochi' ,
'fukuoka' , 'saga' , 'nagasaki' , 'kumamoto' , 'oita' ,
'miyazaki' , 'kagoshima' , 'okinawa'
]
image_sizes = ['xl' , 'l' , 'm' , 's']
max_pages = 21
waiting_seconds = 6
# make output folder
command = ('mkdir', '-p', './txt')
res = subprocess.call(command)
# functions
def generate_target_urls():
for i in range(0,len(prefs_head_by_area)):
for j in range(prefs_head_by_area[i], \
prefs_head_by_area[i] + prefs_count_by_area[i]):
for k in range(1, max_pages):
target_url = base_url \
+ 'area=' + areas[i] \
+ '&prefectures='\
+ prefectures[j] \
+ '&page=' \
+ str(k)
time.sleep(waiting_seconds)
html = requests.get(target_url)
html.encoding = 'utf-8'
soup = BeautifulSoup(html.text, 'html.parser')
atags = soup.find_all('a')
for l in atags:
m = l['href']
n = '^/ja/i/'
o = re.match( n, m )
if o:
target_urls.append([i, j, m, 'z'])
else:
None
return
def update_details_in_target_urls():
base_image_url = 'https://search.find47.jp/ja/images/'
for i in target_urls:
for j in image_sizes:
time.sleep(waiting_seconds)
image_url = base_image_url + str(i[2][-5:]) + '/download/' + j
image_link = requests.get(image_url)
if image_link.status_code == 200:
target_urls[target_urls.index(i)][2] = str(i[2][-5:])
target_urls[target_urls.index(i)][3] = j
break
return
def write_out_to_csv_file():
with open('./txt/01.csv', mode = 'w', encoding = 'utf-8') as f:
for i in target_urls:
writer = csv.writer(f)
writer.writerow(i)
f.close()
return
# main routine
## generate target urls list as a text file with info in a simple format.
### stage 01
print('stage 01/03 started.')
generate_target_urls()
print('stage 01 completed.')
### stage 02
print('stage 02/03 started.')
update_details_in_target_urls()
print('stage 02 completed.')
### stage 03
print('stage 03/03 started.')
write_out_to_csv_file()
print('stage 03/03 completed.')
print('All operations of 01_generate_urls.py completed.')
# end of this script
コード(2)
作成した適宜適当なフォルダ(例、/home/nekoneko/codes/python/find47)の直下に47_finder.shのファイル名で保存してください。さらに、chmod +xしてください。
# !/bin/bash
cd /home/nekoneko/codes/python/find47
python3 ./01_generate_urls.py > ./txt/01.log 2>&1
# python3 ./02_download_jpgs.py > ./txt/02.log 2>&1
実行
cronに入れるなどして行うのがお勧めです。
ログファイルは./txt/01.logです。
8地域(北海道から九州沖縄まで)、全1080画像であることが確認できます。
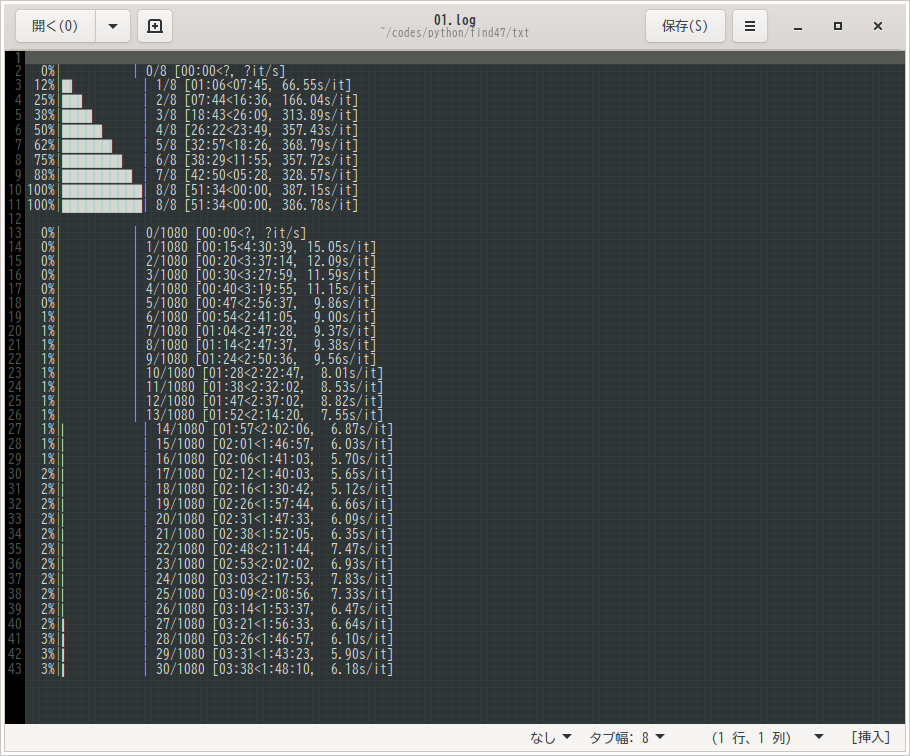
実行例
ちょっと違いますが下記のような形式でファイルが./txt/01.csvとして作られます(画面は開発中のものです)。
予想所要時間
今回のリスト作成に、10時間前後です。
次回の画像取得に、同様に10時間前後です。
今回のまとめ
すばらしいfind/47というサイトから、全国47都道府県の美しい風景画像をPythonを使って取得する手順を紹介する記事です。このうち、今回は対象URLをテキストファイルに出力するところまでをコード付きで説明しました。次回の記事では、今回得られたリストを元に、画像を取得します。