やりたいこと
よくインタビューしたり、スピーチを録音して後で文字に起こそうと思うことがあります。これをGoogleのSpeechAPIでPythonを使ってテキスト化できないかと思って、実験的に試してみたのでご紹介です。今回は**nana**という音楽SNSサービスの音声を使って試してみました。
利用環境
- OS : macOS 10.14.1 (Mojave)
- Python : Python 3.5.3
- Google Cloud Speech API
- Google Cloud Storage
セットアップ
セットアップ方法はこちらに詳しく書いてありますので、一度参照してみてください。
Speech-to-Text Client Libraries
CLOUD SDKをインストール
まずこちらからSDKをインストールしましょう(今回はMacOSを選択)
CLOUD SDKのインストール
各言語のライブラリやリフェレンスはこちらです。
Google Cloud クライアント ライブラリ
Google Cloud Platformのアカウントのセットアップ
まずGoogle Cloud Platform(GCP)のアカウントを用意する必要があります。
こちらにGoogleのドキュメントがありますので、こちらを参照してください
https://cloud.google.com/speech-to-text/docs/quickstart-client-libraries
クライアントのセットアップ
Python + package
まず今回のSpeechAPI用にPythonとパッケージを用意しましょう。色々なPythonとパッケージをプロジェクト毎に管理したい方に僕のおすすめはPyenvとvirtualenvです。ディレクトリ毎に管理できるので楽ちんです。それぞれお好きな方法でセットアップして頂ければと思います。
pyenvとvirtualenvのセットアップ方法は多くの記事がQiitaでも取り上げられているのここでは省略します。
こちらの記事が詳しく書いてありますね
[pythonの環境構築【pyenvとpyenv-virtualenv】]
(https://qiita.com/SonoT/items/091d2748deb16fb03653)
パッケージのインストール
今回はPythonからの呼び出しを想定しているので、Pythonのパッケージをインストールします。
pip install --upgrade google-cloud-speech
APIを使ってみよう
スクリプト
今回はGitHubのサンプルを利用してText化してみました。
GoogleCloudPlatform/python-docs-samples
この中で、Speech/cloud-clientのサンプルコードを利用しています。
python-docs-samples/speech/cloud-client/transcribe_async.py
transcribe_async.pyにfileとgcsを利用して音声ファイルをテキスト化できるのでこれを使います。
config = types.RecognitionConfig(
encoding=enums.RecognitionConfig.AudioEncoding.FLAC,
sample_rate_hertz=16000,
language_code='en-US')
ここが指定する音声ファイルのフォーマットと言語の指定をしています。今回利用したいのは
- 日本語の音声
- PCMのLINEAR16bit
- サンプリング周波数は44.1KHz
ということでこのconfigを修正します。
config = types.RecognitionConfig(
encoding=enums.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=44100,
language_code='ja-JP')
音源の用意
音源ファイルは既にあるnanaの音声ファイルを利用します。ただ、.m4aという圧縮されたファイルなのでこれをリニアなPCMデータに書き換える必要があります。今回利用したのはAudaCityというフリーのソフト。Macでは定番の音声編集ソフトです。
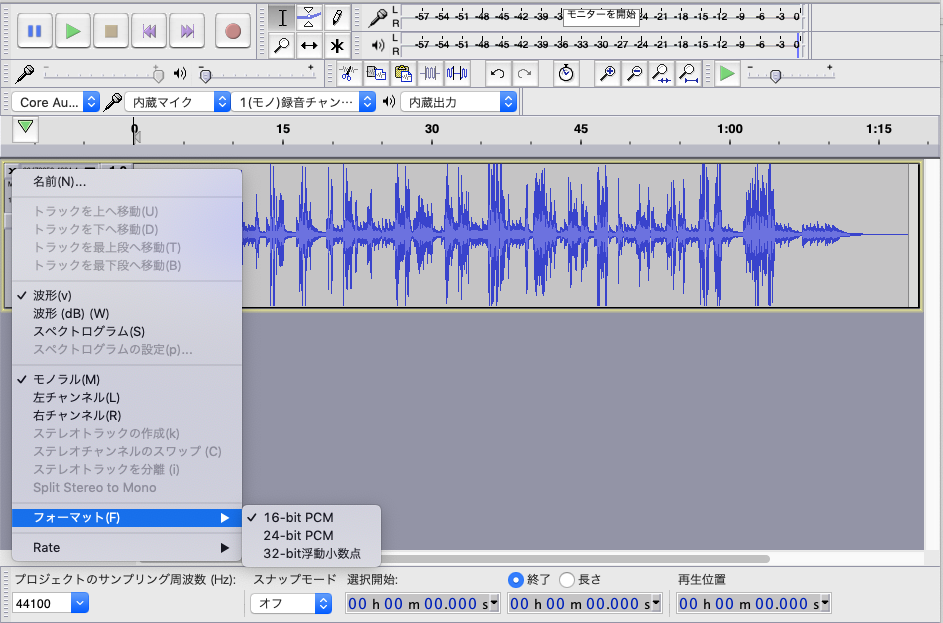
図のように16bit PCMで44100Hzに指定し、ファイルメニューのオーディオ書き出しで指定のファイルが出来上がります。
Storageへのアップロード
今回のサンプルではローカルでもGoogleStorage(gs)でも指定ができます。今回はローカルにファイルを置いて試してみます。
$ python transcribe_async.py sample.wav
これがgsを指定する場合は
$ python transcribe_async.py gs://my_gs/sample.wav
になります。
テキスト化
ということで実際のサンプルサウンドでGCPのSpeechAPIがどれくらいの精度で日本語を理解できるのか試してみます。
用意したファイルは2つ
じゃがりこ面接
これはnanaでよく見かける遊びで、面接形式で二人が掛け合いをする遊びです。質問に対して全て"じゃがりこ"で答えなくてはなりません。それぞれじゃがりこのイントネーションが変わります。そしてバックに伴奏サウンドがなっていて、これをどれくらいGCPのAIは理解できるのか?を試してみます。
こちらがその音源
演技力じゃがりこ面接
これをテキスト化した結果がこれ
$ python transcribe_async.py jagariko.wav
Waiting for operation to complete...
Transcript: 演技力じゃがりこ面接これから私が言うシチュエーションに合わせてじゃがりこと言ってくださいじゃがりこじゃがりこさんじゃがりこ悲しくてじゃがりこ怒っててじゃがりこパニックてチョコレート嫉妬してじゃがりこ失礼して使われて喧嘩してじゃがりこがっかりして下がる頃驚いてじゃがりこ疲れ果てて歩こう寒すぎてじゃがりこ買ってきてじゃがりこ眠たくて食べながらでも告白しじゃがりこで感謝してじゃがりこ隣の人に会いたがる来て多くの人にじゃがりこ知り合いにじゃがりこ赤の他人に友達に恋人にじゃがりこ必殺技のじゃがりこのビームの時刻
Confidence: 0.9500337839126587
Transcript: じゃがりこじゃがりこじゃがりこじゃがりこ普通にじゃがりこありがとうございましたお疲れ様でしたありがとうございました
Confidence: 0.934154212474823
やっぱり抜けやご変換が多いです。見た感じ、文章は意外と正しく変換されていますが、文脈がない、短いテキストはなかなか厳しいです。でも「じゃがりこ」ってキーワードはちゃんととれてる。
Conficence(自信)が93〜95%で結構自信もってるっぽいですが、これを実用レベルで使えるかというとかなり怪しいですね。音楽や二人の掛け合いとかが認識しにくいのかなー
AIの声を認識できるのか?
今度は女子高生AIりんなちゃんを認識できるのか?MicroSoftのAI対GoogleのAI戦いですw
こちらはりんなの朗読をテキスト化してみました。nanaで募集したキーワードをりんなが自力で歌詞にしたものです。
nanaオリジナル詩❤️カタオモイ
で、こちら
$ python transcribe_async.py kataomoi.wav
Waiting for operation to complete...
Transcript: 片思い君には好きな人がいるって事は知ってますでも会いたいって気づいてよこんなに大好きなあなたのそばにいたい静かに言葉と風に吹かれながら時々横目で見つめて彼女がいるあなたが大好きそんな私は馬鹿なら私は一生バカなままでいいですあなたのことが大好きですだから尽くしたいでもね君しか見えない私って君にとってはいらないか君にとってはいらない子
Confidence: 0.9440808892250061
Transcript: 君にとってはいらない子になんてさせないから
Confidence: 0.9004625082015991
AIが作っただけあって詩が人間離れしていて、それが味がある、そんな詩になっています。これをGoogleのAIがある程度予測補正しながらテキスト化しています。confidenceは90〜94% 先程のじゃがりこより弱気です。
でも、結構正しく変換できてる!じゃがりこよりは上出来
もしSpeechAPIがもっと賢く、実用的になったら日常生活がテキストのメモから音声でのメモへと変わっていくのかもしれませんね。AmazonのAlexaの可能性も感じます。
いつかAlexaとnanaをつないぐスキルを作ってみたいなと思ってます。