TL;DR
seleniumの使い方
Chromeで起動方法
WebDriverインストール
chromeの設定画面でchromeのバージョンを確認します。
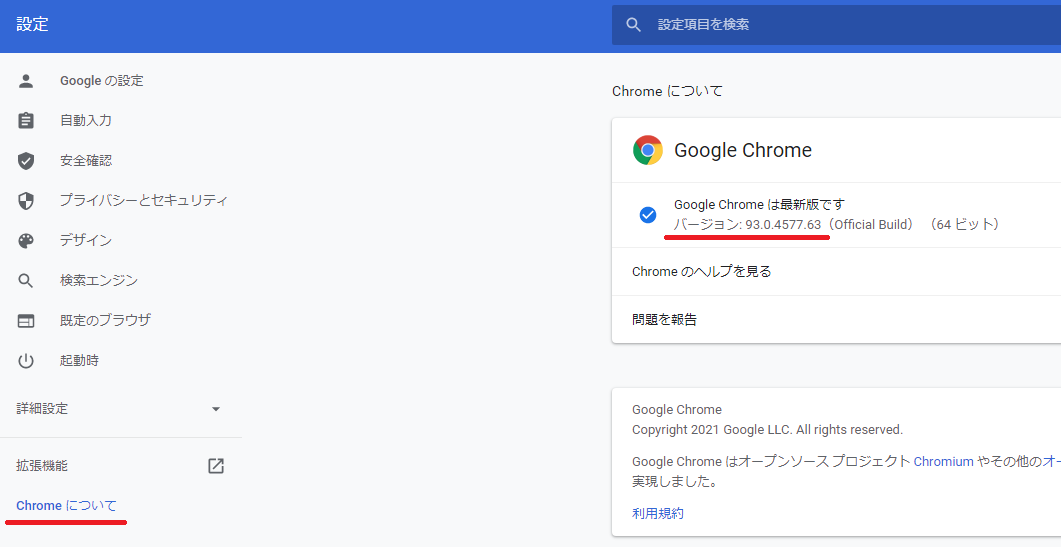
こちらからChromeのWebDriverをダウンロードします。
先程確認したバージョンを同じものを選びます。
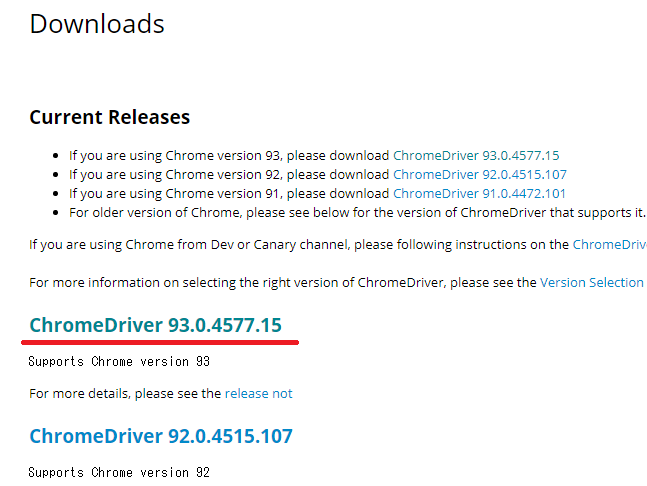

OSで選ぶ。
プログラミング
ライブラリインストール
$ pip install selenium
プロジェクトフォルダ直下にchromedriver.exeを入れます。
コード
from time import sleep
from selenium import webdriver
def main():
options = webdriver.ChromeOptions()
driver_path = "./chromedriver"
driver = webdriver.Chrome(executable_path=driver_path, options=options)
driver.get("https://www.yahoo.co.jp/") # ブラウザ起動
sleep(3) # 3秒間待機
print(f"ページタイトル:{driver.title}") # ページのタイトル
print(f"URL:{driver.current_url}") # 今いるページのURL
driver.quit() # ブラウザ終了
if __name__ == "__main__":
main()
ドライバーのパスは今回だとプロジェクトファイルの直下なので./chromedriverですが、開発環境の階層によって変えてください。
各要素の値を取得する
# cssでの指定
driver.find_element_by_css_selector("css")
# classでの指定
driver.find_element_by_class_name("classname")
# idでの指定
driver.find_element_by_id("id")
# xpathでの指定
driver.find_element_by_xpath("xpath")
# java ポップアップを消すときとか
driver.execute_script('document.querySelector("css").click()')
大抵の場合これdriver.find_element_by_css_selectorで事足りる。
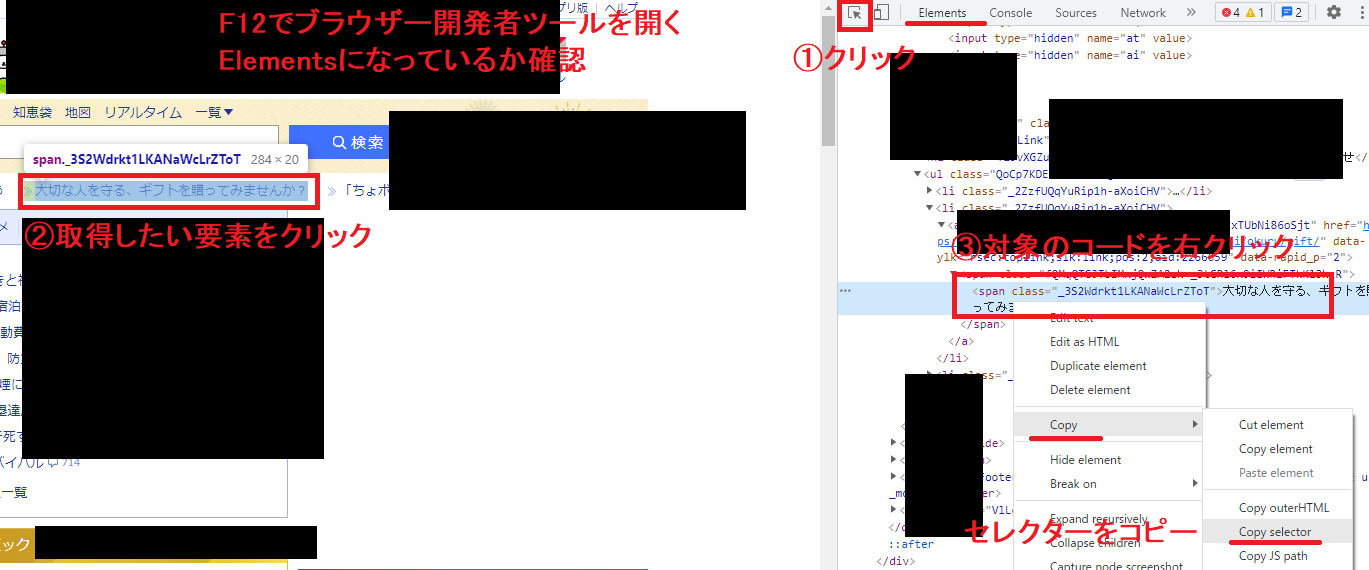
driver.find_element_by_css_selector("#TopLink > ul > li:nth-child(2) > a > span > span")
この要素の文字を取得したい場合は
element = driver.find_element_by_css_selector("#TopLink > ul > li:nth-child(2) > a > span > span")
print(element.text)
#TopLinkのように#がついているものはHTML上のid=TopLinkであることを指しています。
.ドットがついているものはclass=です。
HTML上でclassが複数あるもの
クラスが複数の場合。
例
<div class="yMWCYupQNdgppL-NV6sMi _3sAlKGsIBCxTUbNi86oSjt">~~~~~</div>
上記の値と取得したい場合は
各クラス名の先頭にドットをつけます。
driver.find_element_by_css_selector(".yMWCYupQNdgppL-NV6sMi._3sAlKGsIBCxTUbNi86oSjt")
ネストされているタグの取得方法
例
<div id="gegggew">
<span class="yMWCYupQNdgppL-NV6sMi _3sAlKGsIBCxTUbNi86oSjt">~~~~~</span>
</div>
上記の値と取得したい場合は
各クラス名の先頭にドットをつけます。
driver.find_element_by_css_selector("div#gegggew > span.yMWCYupQNdgppL-NV6sMi._3sAlKGsIBCxTUbNi86oSjt")
ネストされているときは「>」を使います。
要素が複数ある場合
elements = driver.find_elements_by_css_selector("#TopLink > ul > li")
elementがelementsに複数系になる。
リスト型で取得されるのでこれをfor文などで回したりする。
for el in elements:
print(el.text)
要素(ボタン)をクリックする
element = driver.find_element_by_css_selector("#TopLink > ul > li:nth-child(2) > a > span > span")
element.click()
リンクをクリックする(属性値取得)
リンクをクリックしたい場合はclickメソッドだとうまくいかないことがあるのでリンクのURLを取得してそのURLに飛ぶ処理を行う。
aタグがリンクの要素なのでまず対象のaタグの要素を取得する。
get_attributeメソッドを使って取得した要素の属性href=内の値(URL)を取得する。
element = driver.find_element_by_css_selector("#TopLink > ul > li:nth-child(2) > a")
url = element.get_attribute("href")
driver.get(url)
divの中のdata-asinの値を取得したいとき
<div data-asin="~~~~~~~">
element = driver.find_element_by_css_selector("div")
element.get_attribute("data-asin")
スクショ保存
w = driver.execute_script("return document.body.scrollWidth;")
h = driver.execute_script("return document.body.scrollHeight;")
driver.set_window_size(w, h)
driver.save_screenshot("./test.png")
WidthとHeightを全開に指定することによってスクロールしないと見えないところまで全部スクショしてくれる。
なので縦長な画像になる。
./test.pngの部分はファイル構成に合わせて。
開いたブラウザの範囲のみでよかったらdriver.save_screenshot("./test.png")だけでよい。
webdriver_manager便利!
chromedriver.exeはchromeがバージョンアップする度に新しいバージョンに入れ替える必要がある。
それの入れ替えなしに常に新しいバージョンのchromedriver.exeを自動で用意してくれるライブラリが存在する。
$ pip install webdriver_manager
from time import sleep
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
def main():
options = webdriver.ChromeOptions()
driver = webdriver.Chrome(ChromeDriverManager().install(), options=options)
driver.get("https://www.yahoo.co.jp/")
sleep(3)
elements = driver.find_elements_by_css_selector(
"._2j0udhv5jERZtYzddeDwcv article > a > div > div > h1 > span"
)
for el in elements:
print(el.text)
driver.quit()
if __name__ == "__main__":
main()
上記のコードそのままコピペで動きます。
はじめから教えろよと思いますよね。その通り!
でも場合によってはchromedriver.exeが必要な場面もあるのでseleniumを動かすにはchromedriver.exeが必要なんですよっていう知識が必要なんです。