はじめに
Container Engine for Kubernetes (OKE)のバージョンアップ手順として新しくon-demand node cycling機能が実装されました。これはWorker Nodeのアップグレード手順を簡素化してくれる機能です。
実際のところどうなのか確認してみます。
なお、この機能を使うためには「拡張クラスタ」である必要があります。
拡張クラスタは2023年3月にGAになった機能で、それ以前のクラスタは「基本クラスタ」と呼ばれています。
拡張クラスタと基本クラスタの違いはこちらをご参照ください。
環境の確認
今回は2ノードのクラスタを用意しました。
$ k get node
NAME STATUS ROLES AGE VERSION
10.0.10.13 Ready node 4h8m v1.25.4
10.0.10.218 Ready node 4h8m v1.25.4
Kubernetesのバージョンはv1.25.4で、これをv1.26.2に上げます。
OCIのコンソール上でバージョンアップができると表示されています。
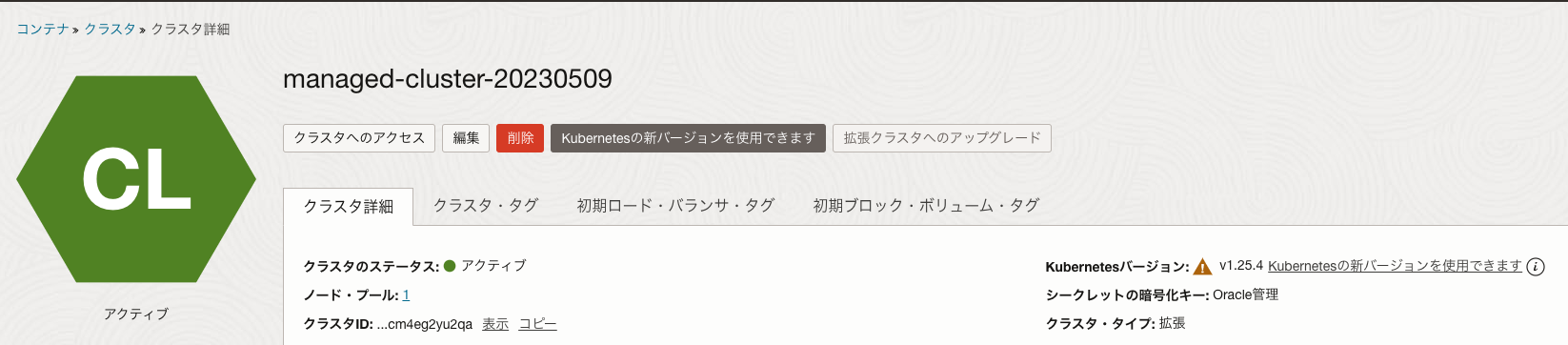
ちなみに、基本クラスタから拡張クラスタにアップグレードすることもできますので、基本クラスタを使っているけど、この機能を試してみたい場合には、コンソールから拡張クラスタへのアップグレードをクリックすると、拡張クラスタに変えることができます。(拡張クラスタから基本クラスタに変更することはできません)
なお、拡張クラスタは基本クラスタと違って、クラスタそのものが課金対象となりますのでご注意ください。
動作確認用にDeploymentで2つのPodを作成しています。
$ k get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-76d6c9b8c-9vdft 1/1 Running 0 49m 10.244.0.4 10.0.10.13 <none> <none>
nginx-76d6c9b8c-nc92w 1/1 Running 0 49m 10.244.0.131 10.0.10.218 <none> <none>
バージョンアップ
コントロールプレーン -> Worker Nodeの順にバージョンアップします。
コントロールプレーン
OCIのコンソールからKubernetesの新バージョンを使用できますをクリックします。
以下の画面でバージョンを選択して、アップグレードをクリックします。
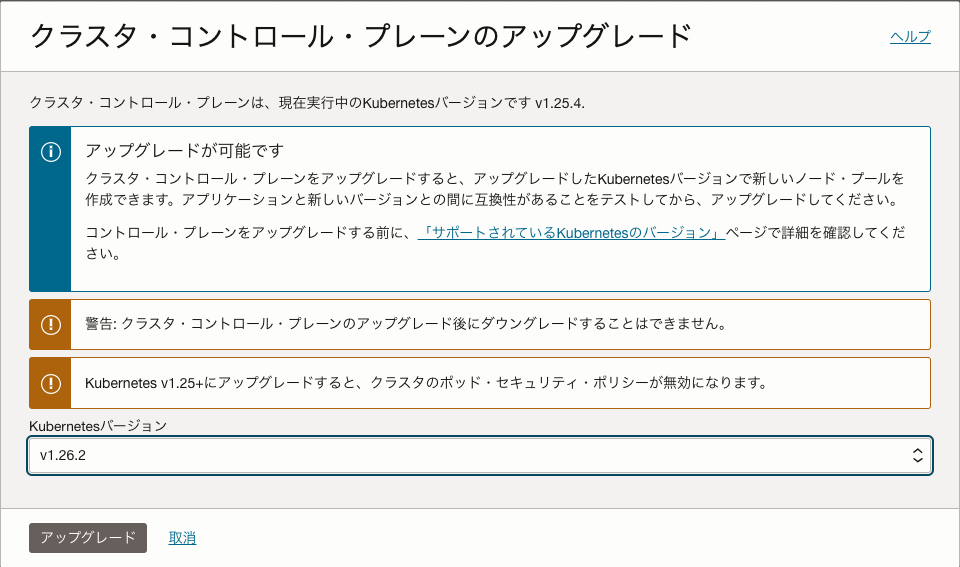
この画面になります。
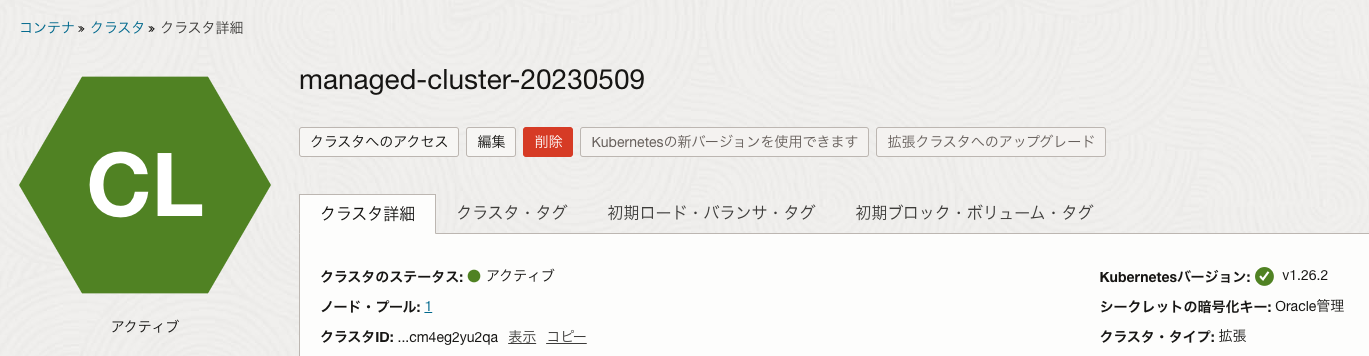
少し待つとアイコンがグリーンに変わって、v1.26.2にバージョンアップできたことが確認できます。
Worker Node
OKEのWorker Nodeはノードプールという単位でプロビジョニングされています。
クラスタのコンソールから、ノードプールの詳細画面に行きます。
現状では、ノードプールのバージョンはv1.25.4のままです。
この画面で編集をクリックします。

この画面のバージョンでv1.26.2を選択して、変更の保存をクリックします。
ノードプールのバージョンがv1.26.2に変わりました。

ここまでは基本クラスタでも同じで、ここからがon-demand node cyclingの手順になります。
OCIのコンソールでサイクル・ノードをクリックします。
この画面で最大サージと最大使用不可の数値を設定します。
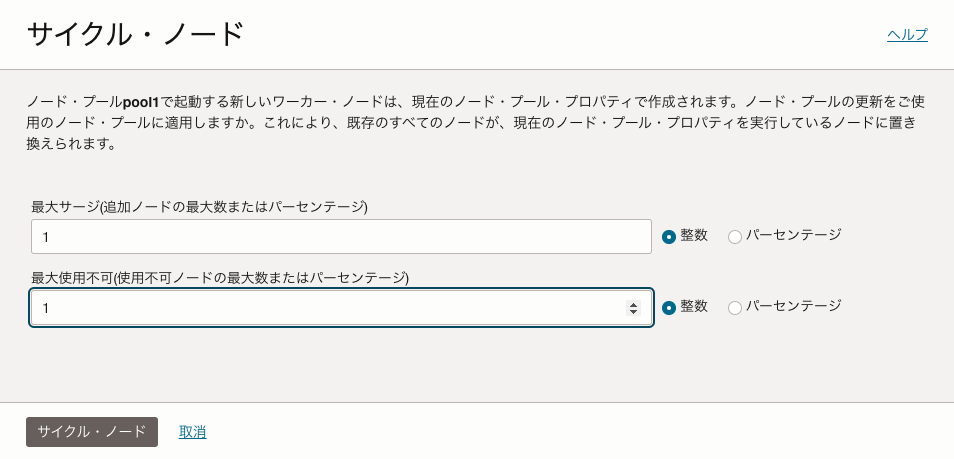
- 最大サージ
- バージョンアップ時に一度に追加するノード数の上限
- 最大使用不可
- バージョンアップ時に使用できないようにするノード数の上限
バージョンアップはそのノードのKubernetesのバージョンを上げるのではなく、新しいバージョンのノードを追加して、古いバージョンのノードを削除する動作になります。
そのため、バージョンアップ時に性能を落としたくない場合は、最大サージ数を1以上にして、最大使用不可を0にします。この場合は一時的にノード数が増えますので、その分コストがかかることになります。
逆に、バージョンアップ時にコストを増やしたくないのであれば、最大サージ数を0にして、最大使用不可を1以上にします。この場合は一時的にノード数が減りますので、性能(Podが起動できないなど)に影響が出る可能性があります。
今回はそれぞれ1ずつにしてみました。
コンソール上では以下のように新しいノードが追加されています。

ノードのバージョンアップ(入れ替え)が終わると以下のようになります。

ノードの動きをkubectlコマンドでも確認しました。
$ k get node -w
NAME STATUS ROLES AGE VERSION
10.0.10.13 Ready node 6h58m v1.25.4
10.0.10.218 Ready node 6h58m v1.25.4
10.0.10.218 Ready,SchedulingDisabled node 6h58m v1.25.4
10.0.10.218 NotReady,SchedulingDisabled node 6h59m v1.25.4
10.0.10.91 NotReady <none> 0s v1.26.2
10.0.10.91 NotReady <none> 51s v1.26.2
10.0.10.91 Ready <none> 54s v1.26.2
10.0.10.91 Ready node 73s v1.26.2
10.0.10.13 Ready,SchedulingDisabled node 7h1m v1.25.4
10.0.10.199 NotReady <none> 0s v1.26.2
10.0.10.199 NotReady <none> 20s v1.26.2
10.0.10.13 NotReady,SchedulingDisabled node 7h2m v1.25.4
10.0.10.199 NotReady <none> 62s v1.26.2
10.0.10.199 Ready <none> 66s v1.26.2
10.0.10.199 Ready <none> 68s v1.26.2
10.0.10.199 Ready node 90s v1.26.2
10.0.10.199 Ready node 2m35s v1.26.2
10.0.10.91 Ready node 4m14s v1.26.2
削除されてから追加しているような動きですね。
最終的にはこうなりました。
$ k get node
NAME STATUS ROLES AGE VERSION
10.0.10.199 Ready node 96s v1.26.2
10.0.10.91 Ready node 3m15s v1.26.2
Podの動きも確認しました。
$ k get pod -o wide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-76d6c9b8c-9vdft 1/1 Running 0 3h40m 10.244.0.4 10.0.10.13 <none> <none>
nginx-76d6c9b8c-f744z 1/1 Running 0 2m12s 10.244.0.5 10.0.10.13 <none> <none>
nginx-76d6c9b8c-9vdft 1/1 Running 0 3h41m 10.244.0.4 10.0.10.13 <none> <none>
nginx-76d6c9b8c-9vdft 1/1 Terminating 0 3h41m 10.244.0.4 10.0.10.13 <none> <none>
nginx-76d6c9b8c-f744z 1/1 Running 0 3m9s 10.244.0.5 10.0.10.13 <none> <none>
nginx-76d6c9b8c-f744z 1/1 Terminating 0 3m9s 10.244.0.5 10.0.10.13 <none> <none>
nginx-76d6c9b8c-tcbdd 0/1 Pending 0 0s <none> <none> <none> <none>
nginx-76d6c9b8c-tcbdd 0/1 Pending 0 0s <none> 10.0.10.91 <none> <none>
nginx-76d6c9b8c-tcbdd 0/1 ContainerCreating 0 0s <none> 10.0.10.91 <none> <none>
nginx-76d6c9b8c-44qhc 0/1 ContainerCreating 0 0s <none> 10.0.10.91 <none> <none>
nginx-76d6c9b8c-f744z 0/1 Terminating 0 3m10s 10.244.0.5 10.0.10.13 <none> <none>
nginx-76d6c9b8c-9vdft 0/1 Terminating 0 3h41m 10.244.0.4 10.0.10.13 <none> <none>
nginx-76d6c9b8c-44qhc 1/1 Running 0 35s 10.244.0.131 10.0.10.91 <none> <none>
nginx-76d6c9b8c-tcbdd 1/1 Running 0 35s 10.244.0.132 10.0.10.91 <none> <none>
最終的にはこうなりました。
$ k get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-76d6c9b8c-44qhc 1/1 Running 0 4m29s 10.244.0.131 10.0.10.91 <none> <none>
nginx-76d6c9b8c-tcbdd 1/1 Running 0 4m29s 10.244.0.132 10.0.10.91 <none> <none>
ノードが減ってから増える動作でしたので、最終的は2つのPodが一つのノードに寄せられた形になりました。
今回は2ノードのクラスタでしたのでこのようになりました。通常は3ノード以上だと思いますが、3ノード以上の場合には、最後に追加されたノードに(Daemonsetを除き)Podがない状態になると思います。
これを防ぎたいのであれば、追加してから削除する動作(「最大使用不可」を0)にする必要がありますね。
まとめ
今回確認したon-demand node cyclingを使わない場合は、ノードプールのバージョンを上げた後に以下の手順を手動で実施する必要があります。
- ノードの追加(スケール)
- kubectl drain
- ノードの削除
これをやらないで良いので、バージョンアップが楽になったと感じました。