はじめに
概要
こちらは富士通クラウドテクノロジーズ Advent Calendar 2021の16日目の記事です。
15日目は@aokuma さんの社内 GitLab の大型マイグレーションを行った話という記事でした。
自己紹介
みなさん、こんにちは
FJCTアドベントカレンダーは初登場となります、 @digfield です。
昨年、10月にニフクラの基盤を利用した法人向けメールサービスの担当の部署に配属されました。
担当業務は、メールサービスに用るサーバの運用です。
文系出身で知識と経験が浅いながらも、少しずつチームに貢献できるよう、日々精進しております。
今回は、私が行った業務の一つであります、zabbixでサービス用のサーバの死活監視環境の整備についてご紹介させて頂きます。
本業務のゴール
メールサービスを運用するにあたって、送信・配送用のサーバであるSMTPサーバ、受信用のサーバであるPOPサーバは欠かせません。
もちろん、これらのサーバが外部から疎通が取れなくなってしまい、いわゆる使用不可能になってしまえば、サービス自体が成り立たなくなってしまいます。
このような状況をいち早く捕捉すべく、またこのような状況がどれくらいの間続いていたのかを知ることができるような死活監視の環境を整備することが本業務のゴールです。
実現方法
環境
- zabbix-server用サーバ:CentOS Linux release 7.1
- zabbix-agent用サーバ:CentOS Linux release 7.1
- zabbix-serverのバージョン:zabbix_server 3.2.6
- zabbix-agentのバージョン:zabbix_agentd 3.2.6
監視対象のサーバとポート番号について
- 以下のサーバとポートの組それぞれに対し、死活監視の環境を行うことになります
| サーバ | ポート番号 |
|---|---|
| サービスで用いる各SMTPサーバ | 465(SMTPoverSSLモード), 25, 587 |
| サービスで用いる各POPサーバ | 995(POPoverSSLモード), 110 |
死活監視用のスクリプトについて
server_monitor.sh
# !/bin/bash
# 疎通確認の試行の定義の関数
# 疎通確認はncコマンドで行うものとする。
# コマンドラインでサーバー名とポート番号を引数で渡し、最大3回疎通確認を行う。
# タイムアウトは5秒とする。
# 成功すれば、ループを抜ける。
retry() {
MAX_RETRY=3
TIME_OUT=5
n=0
until [ $n -ge $MAX_RETRY ]
do
date_and_targetserver=$(echo "`date "+%Y-%m-%d %H:%M:%S "` $1 $2")
if [ $2 == 465 -o $2 == 995 ]; then
nc_result=$(nc -w 5 -v $1 -z $2 --ssl 2>&1> /dev/null)
else
nc_result=$(nc -w 5 -v $1 -z $2 2>&1> /dev/null)
fi
result=$?
echo $date_and_targetserver" "$nc_result >> $log
if [ $result == 0 ] ; then
break
fi
n=$[$n+1]
done
if [ $n -ge $MAX_RETRY ]; then
result=fail
fi
}
# ロックファイルの名前を定義
lockfile=/var/tmp/file.lock.$1.$2
# ロックファイルがあれば、「2」を出力し、処理終了
if [ -f $lockfile ]; then
echo 2
exit
fi
# ロックファイル作成
touch $lockfile
# ログファイルの定義
log=/var/log/server_monitor/server_monitor_log
# コマンドラインからの引数(サーバー名とポート番号)を渡し、関数実行
retry $1 $2
# 成功すれば、「0」を出力し、失敗(3回疎通確認に失敗)すれば、「1」を出力
if [ $result == 0 ] ;
then
echo 0
else
echo 1
fi
# ロックファイル削除
rm -f $lockfile
スクリプトに関する補足説明を行います。
- ncコマンドに関して、監視対象のポートがSSLモードかそうでないか仕様が変わってくるのでポート番号にて条件を分岐しております。
- 後ほどロギングに関する説明を行いますが、実行時間・監視対象サーバとポート番号・実行結果をロギングするようにしております。
- 同じ監視対象サーバとポート番号の監視のプロセスがドッキングしないように、ロックファイルの作成、そしてロックファイルがあれば処理を終える仕組みを拵えております。
ロギングに関して
-
ロギングの目的:仮に監視が失敗するような事象が起こった場合に、どのような理由で疎通確認に失敗しているのかの切り分けがしやすいようにするためです。
-
以下ログの例です。
疎通確認が成功している場合(SSLモード)
2021-12-16 14:34:54 {サーバ名} {ポート番号} Ncat: Version 7.50 ( https://nmap.org/ncat ) Ncat: SSL connection to {IPアドレス}:{ポート番号}. Ncat: SHA-1 fingerprint: {フィンガープリントの内容} Ncat: 0 bytes sent, 0 bytes received in 0.01 seconds.
疎通確認が成功している場合(非SSLモード)
2021-12-16 20:01:09 {サーバ名} {ポート番号} Ncat: Version 7.50 ( https://nmap.org/ncat ) Ncat: Connected to {IPアドレス}:{ポート番号}. Ncat: 0 bytes sent, 0 bytes received in 0.01 seconds.
タイムアウトにより、疎通確認が失敗している場合
2021-12-16 14:34:59 {サーバ名} {ポート番号} Ncat: Version 7.50 ( https://nmap.org/ncat ) Ncat: Connection timed out.
ホストネームが見つからず、疎通確認が失敗している場合
2021-12-16 14:34:56 hogehoge {ポート番号} Ncat: Version 7.50 ( https://nmap.org/ncat ) Ncat: Could not resolve hostname "hogehoge": Name or service not known. QUITTING.
logrotateに関して
- logrotateを行う目的:一日ごとにログファイルを入れ替え、書き込みを行わなくなったログファイルに日付の文字列の付与を行い、一週間の保管期間が経ったログファイルは削除するため
logrotateの設定ファイル(/etc/logrotate.d/server_monitor)
/var/log/server_monitor/server_monitor_log {
daily
rotate 7
missingok
dateformat .%Y-%m-%d
}
zabbixの設定の流れ
1. zabbix-agentをインストールしているサーバの/usr/lib/zabbix/scripts/配下に、先ほどご紹介した監視用のスクリプト(server_monitor.sh)を設置します
# chmod 0755 server_monitor.sh
# mkdir /usr/lib/zabbix/scripts/
# cp -pv ./server_monitor.sh /usr/lib/zabbix/scripts/server_monitor.sh
2. 以下のユーザーパラメータの設定ファイルを同サーバの/etc/zabbix/zabbix_agent.d/配下に設置します
server_monitor.conf
UserParameter=server_monitor[*], /usr/lib/zabbix/scripts/server_monitor.sh $1 $2
# cp -pv ./server_monitor.conf /etc/zabbix/zabbix_agentd.d/server_monitor.conf
3. zabbix-agentの設定ファイルのtimeoutの時間をデフォルトの3秒から20秒に変更します(疎通確認が失敗する時にスクリプトが強制終了してしまうため)
# cd /etc/zabbix
# today=`date '+%Y%m%d'`
# sed -e "/^# Timeout=3/a Timeout=20" -i.${today} zabbix_agentd.conf
4. 当該のサーバと紐づいているzabbix-server側で、監視したいサーバ名・ポート番号の組の数だけアイテムの設定します
アイテム設定画面
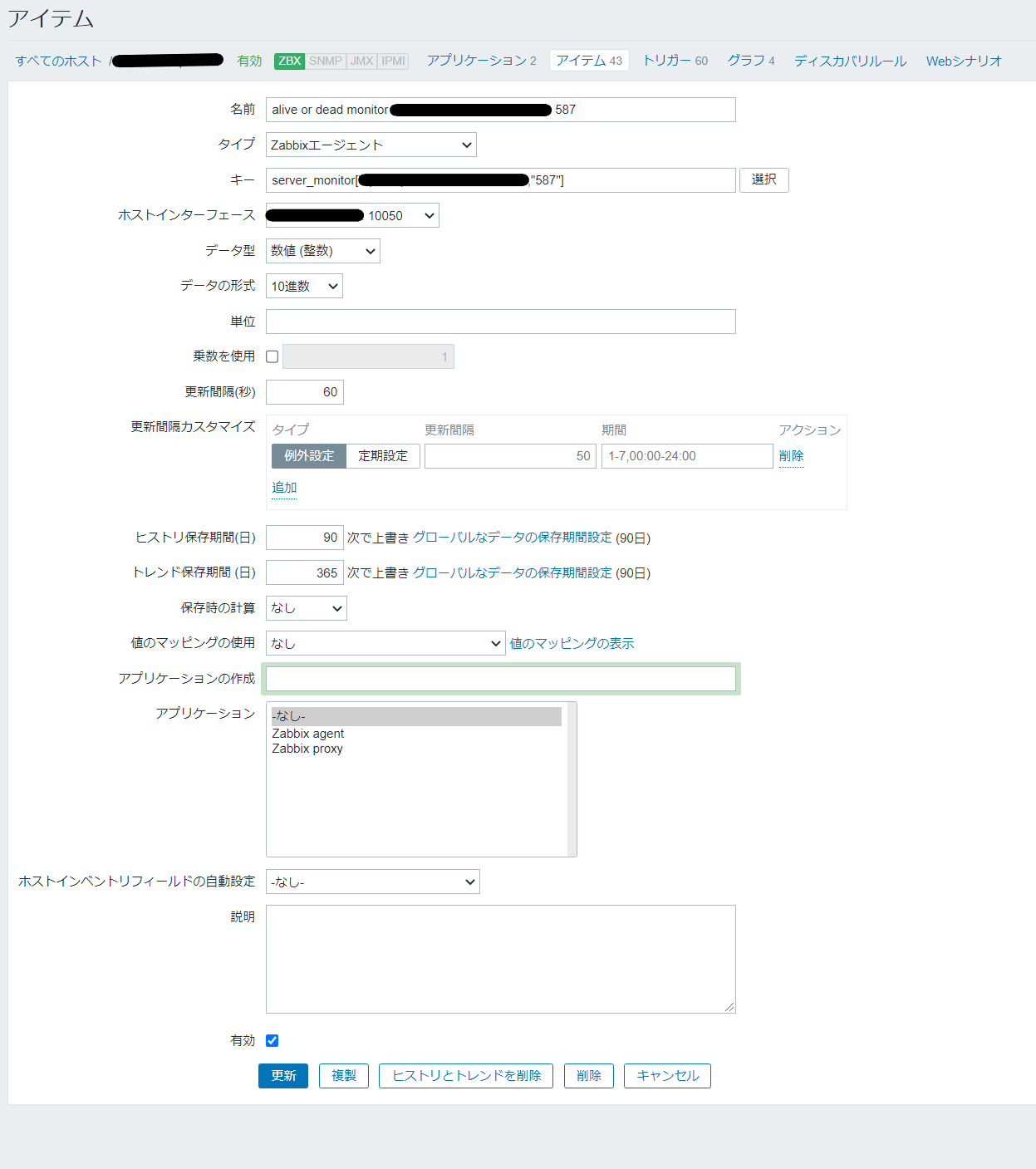
特に重要だと思う点をピックアップします
- キー:server_monitor["{サーバー名}","{ポート番号}"]
- 先ほど設定したユーザーパラメータのおかげで、キー名からSMTPサーバ・POPサーバのサーバ名・ポート番号のパラメータを指定できます
- データ型:数値(整数)
- 返り値が数値なので、ここも数値にしなくてはなりません
- 更新間隔:60秒
5. zabbix-server側でトリガーの設定をします
トリガー設定画面
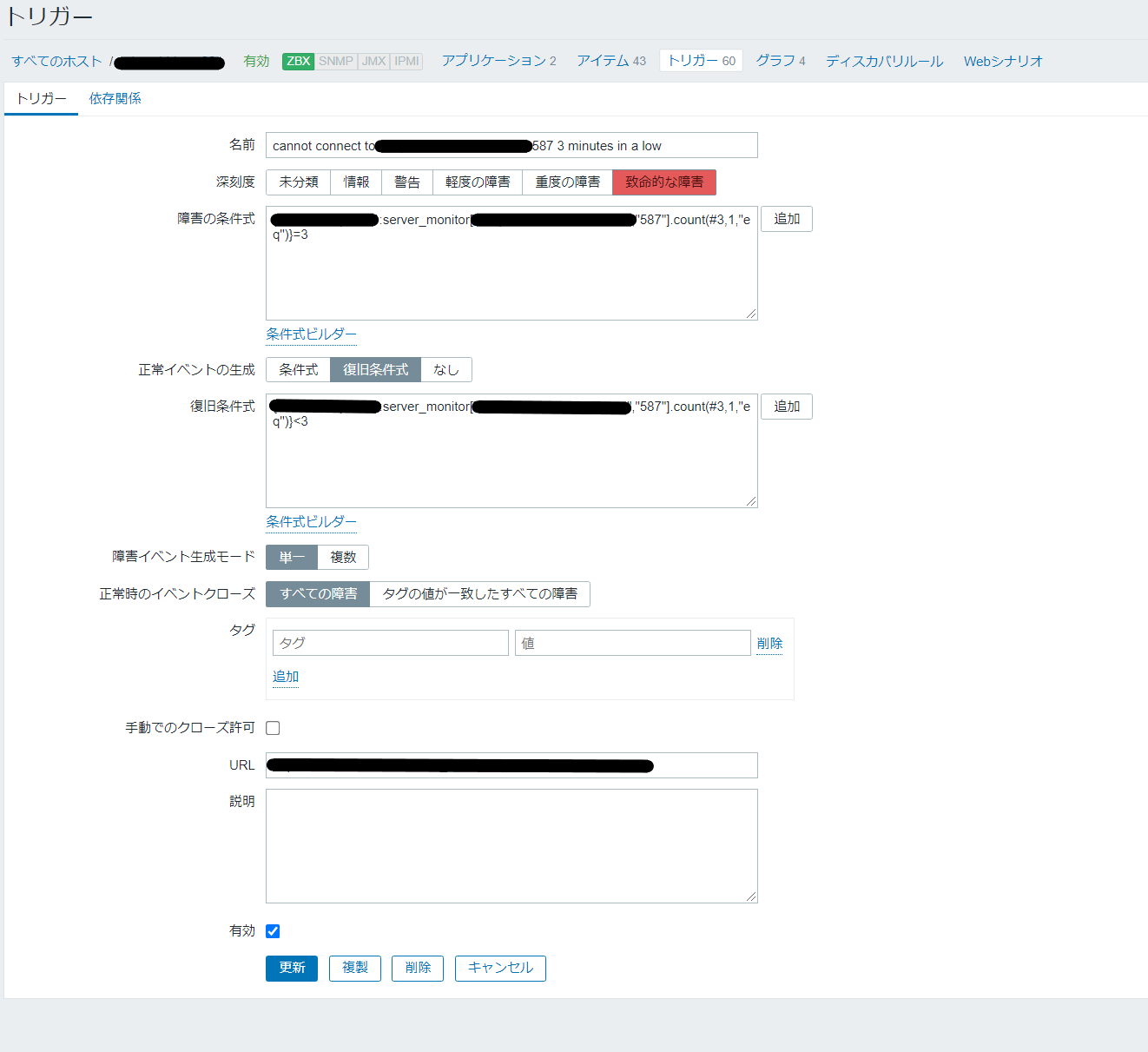
特に重要だと思う点をピックアップします
- 障害の条件式:
{{zabbix-agent設置のサーバ名}:server_monitor["{サーバ名}","{ポート番号}"].count(#3,1,"eq")}=3
3分連続で疎通が全く取れない(返り値が「1」である)状況が続けば深刻度が「致命的な障害」のアラートを出す - 復旧の条件式:
{{zabbix-agent設置のサーバ名}:server_monitor["{サーバ名}","{ポート番号}"].count(#3,1,"eq")}<3
3分連続で疎通が全く取れない(返り値が「1」である)状況が途切れたら、アラートの復旧を行う
6. アラートとトリガーの設定を各々に複製して行います
アラートの通知に関して
- zabbixにて、以下の方法で上記のアラートの発生と復旧の旨と当該時間の通知が来るようになっております
- 昼間:slackのチャンネルに通知されます
- 夜間と休日:電話が鳴るようになっています
今後の課題
zabbix設定の簡素化
先ほどの実現方法のzabbix設定の流れの項番6の各々に複製して行う動作を今回手作業で行ってしまいましたが、これだと非常煩雑であり、抜け漏れや設定ミスの可能性が高くなってしまいます。
このような煩雑な手順を簡素化するために、zabbixAPIを用いたスクリプトを作成するなどの動きをチームとして行っています。
まとめ
上記を行った結果、以下のことが実現しました
- サービスで用いるSMTP/POPサーバとの疎通が取れなくなる状態をリアルタイムで捕捉することができるようになりました
- それらの状態が継続した時間を分単位で捕捉することができるようになりました
明日は、@toyo_mura さんの記事になります。お楽しみに!!