この記事は NTTコミュニケーションズ Advent Calendar 2020 の14日目の記事です。
昨日は @nitky さんの記事でした。
DCASEとは
DCASE (Detection and Classification of Acoustic Scenes and Events) とは、音響シーン・音響イベントの分類・検出に関する技術・研究分野のことです。
DCASE Community が DCASE Challenge を主催しており、そのチャレンジ結果を報告する DCASE Workshop も Challenge に合わせて毎年開催されています。
音声や音楽に関する研究は古くから盛んに行われており、実用化されている技術も数多くありますが、音声・音楽以外の音(環境音など)を対象とした研究は、工場等での機械音の異常検知や動物の鳴き声検出等の特定ドメインにおける研究はもちろんあるものの、その研究対象の広さから体系的な研究は音声・音楽分野と比較しても進んでおらず、応用例も限られていると言えます。
環境音を対象とした研究の難しさを2点あげてみます。
1点目は、特定ドメインでの課題解決のために構築したデータセットが他の課題解決には使えず、研究内容が独立しやすいという点。
2点目として、汎用的なデータセットの構築が困難な点。(ラベル付けはどこまで細かくやればいい?、時間情報はどう与える?音の重なりは?)
まだ成熟していない研究分野ですが、近年の機械学習技術の進歩により、活発に研究が行われ始めています1。
DCASE Community は、独自化しやすい音響シーン・音響イベントの分類・検出に関する研究について議論する場として、共通のデータセットを構築し、異なる手法を比較できるようにすることを目的としています。
本記事では、DCASE Challenge が、試行錯誤を繰り返しながらどのように取り組まれてきたのかを、Challenge 内容を大別してそれぞれ説明することで紹介したいと思います。
DCASE Challenge の変遷
下表は、各年のDCASE Challenge にて出題されたタスクを勝手に分類したものです。
| 2013 | 2016 | 2017 | 2018 | 2019 | 2020 | |
|---|---|---|---|---|---|---|
| task1 | ASC | ASC | ASC | ASC | ASC | ASC |
| task2 | SED | SED | SED | AT | AT | Others |
| task3 | SED | SED | Others | SELD | SELD | |
| task4 | AT | SED | SED | SED | SED | |
| task5 | Others | AT | AT | |||
| task6 | Others |
2013年から2016年の間が空いていますが、DCASEコミュニティが作られて Challenge と Workshopが開催されるようになったのは2016年からで、その間の2年間は空白の期間になっています。
2013年の時点ではまだコミュニティも存在しておらず、IEEE AASP (Audio and Acoudtic Signal Processing) のコミュニティ後援の元、チャレンジが開催され、 WASPAA20132 にてチャレンジ結果などが発表されています3。
表中の略記は下記の通りです。
- ASC: Acoustic Scene Classification - 音響シーン分類
- SED: Sound Event Detection - 音響イベント検出
- SELD: Sound Event Localization and Detection - 音響イベント音源推定・検出
- AT: Audio Tagging - 音へのタグ付け
年々タスク数が増えていますが、内容を少しずつアップデートしながら前年から引き続いているタスク群について、その変遷を説明していきます。
Acoustic Scene Classification
Acoustic scene(音響シーン)について、DCASE 2020 Challenge の Organizer でもある井本先生はこのような表現で説明されています。4
音が収録された場所(例:電車,車,公園,屋内)や状況(例:会議中,非日常),周囲にいる人の行動(例:料理,掃除,会話)をまとめて音響シーン(Acoustic scene)と呼びます。
この世に存在しうる全ての音響シーンを列挙することは困難ですし、どのような粒度の音響シーンを推定するべきかは、解きたい課題によって変わってくると思われます。DCASE Challengeでは、場所や状況が異なる10-15種類の音シーンデータセットを構築して、手法の比較が行えるようにしています。
音響シーン分類は、シンブルな多クラス分類と捉えることができ、DCASEの中では最もシンプルなタスクと言えます。
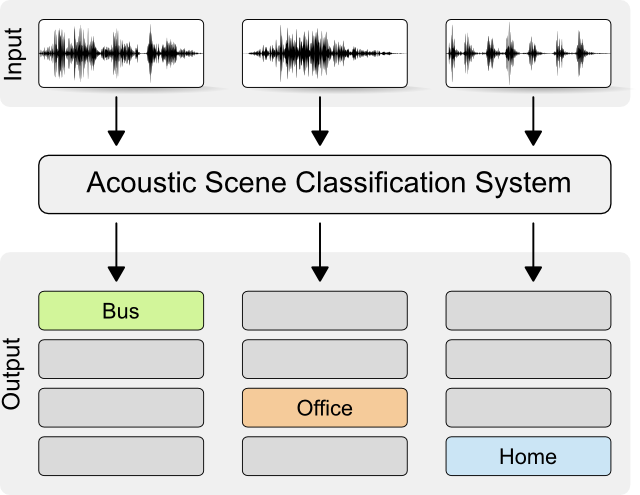 (DCASEのウェブサイトより)
(DCASEのウェブサイトより)
2013 Task1: Acoustic scene classification
このチャレンジのためにデータセットが新たに作成されています。
事前に定義されている音響シーンは下記10種類です。
2013 Task1 音響シーン一覧
- bus
- busystreet
- office
- openairmarket
- park
- quietstreet
- restaurant
- supermarket
- tube
- tubestation
データセットは学習用と評価用に分かれており、それぞれ各音響シーンごとに10ファイルのデータが含まれます。(1ファイルは30秒)
収録場所はロンドンで、夏と秋に収録したようです。収録方法はバイノーラルステレオマイクを使用し、収録場所も複数箇所に分かれているようです。
各音声ファイルの時間も固定されており、収録デバイスも1種類、クラス数も10種類であるため、シンプルな分類モデルを組むだけでそれなりの精度が出そうなタスクであると言えます。
2016 Task1: Acoustic scene classification
"TUT5 Acoustic scenes 2016 dataset" というデータセットが使用されています。
事前に定義されている音響シーンは下記15種類です。
TUT Acoustic scenes 2016 音響シーン一覧
- Bus - traveling by bus in the city (vehicle)
- Cafe / Restaurant - small cafe/restaurant (indoor)
- Car - driving or traveling as a passenger, in the city (vehicle)
- City center (outdoor)
- Forest path (outdoor)
- Grocery store - medium size grocery store (indoor)
- Home (indoor)
- Lakeside beach (outdoor)
- Library (indoor)
- Metro station (indoor)
- Office - multiple persons, typical work day (indoor)
- Residential area (outdoor)
- Train (traveling, vehicle)
- Tram (traveling, vehicle)
- Urban park (outdoor)
データセットは学習用と評価用に分かれており、2013とは異なり、7:3の比率になっています。
データ量も増えていて、1ファイル30秒というのは変わっていませんが、学習用データセットでは1クラスあたり78ファイル(39分)用意されています。収録デバイスは同様にバイノーラルマイクです。
クラス数が増えたため、難易度は前年よりも上がっていそうです。データ量は前年の約6倍になっています。
2017 Task1: Acoustic scene classification
"TUT Acoustic Scenes 2017" というデータセットが使用されています。
事前に定義されている音響シーンは、TUT Acoustic Scenes 2016 と同じです。
2016から何が変わっているかというと、1ファイルあたりの時間が30秒から10秒に変わったことと、追加でデータ収録を行った結果、2016版の学習用・評価用データが、2017版の学習用データにまとまっています。学習用データは1クラスあたり312ファイル(52分)となっています。
2018 Task1: Acoustic scene classification
この年のタスクは3個のサブタスクに分かれています。
一つ目(サブタスクA)は、従来と同様にバイノーラルマイクを使用して収録したデータセットを使用する形式です。
二つ目のサブタスク(サブタスクB)は、複数の異なる録音デバイスで収録したデータセットを用いる形式です。
三つ目(サブタスクC)は、参加者が自由に学習データを追加しても良いという形式でのチャレンジになります。(与えられるデータセットは一つ目のサブタスクと同じ)
バイノーラルマイクを使用することで人間の聴覚に近い形での収録したデータセットを使用していますがが、このような高品質の学習データを大量に用意することは困難です。
様々な録音デバイスで収録したデータを使用することで、デバイスごとのバイアスを考慮する必要がありますが、より多くのデータセットを用意することが可能になり、また応用にもつながりやすくなると考えられます。
サブタスクAでは、"TUT Urban Acoustic Scenes 2018" というデータセットを使用します。
事前に定義されている音響シーンは下記10種類です。
TUT Urban Acoustic Scenes 2018 音響シーン一覧
- Airport - airport
- Indoor shopping mall - shopping_mall
- Metro station - metro_station
- Pedestrian street - street_pedestrian
- Public square - public_square
- Street with medium level of traffic - street_traffic
- Travelling by a tram - tram
- Travelling by a bus - bus
- Travelling by an underground metro - metro
- Urban park - park
1ファイルあたり10秒で、学習データセットでは1クラスあたり 864ファイル(114分)となっています。
サブタスクBでは、"TUT Urban Acoustic Scenes 2018 Mobile" というデータセットを使用します。
事前に定義されている音響シーンはサブタスクAのものと同じです。
3種類の異なるデバイスで収録されたデータが混在しており、デバイスA(バイノーラルマイク)が1クラスあたり864ファイル、デバイスBとデバイスCが共に1クラスあたり72ファイルとなっています。
また、評価時には新たにデバイスDで収録されたデータが含まれます。
2019 Task1: Acoustic scene classification
この年のタスクも3個のサブタスクに分かれます。
サブタスクA: 学習データは単一デバイス(バイノーラルマイク)、評価データも同じデバイス
サブタスクB: 学習データは複数デバイス、評価データも複数デバイス(未知デバイス含む)
サブタスクC: 評価データの中に、学習データに含まれない音シーンが存在する
サブタスクAでは、"TAU6 Urban Acoustic Scenes 2019" というデータセットを使用します。
事前に定義されている音響シーンは2018年のものと同じです。
2018版と異なり、収録された都市の情報が追加されており、それに合わせてデータセットも拡充しています。
1ファイル10秒で、学習用データセットは、1クラスあたり1440ファイルです。評価用データセットには学習データには含まれない都市で収録したデータも含まれます。
サブタスクBでは、"TAU Urban Acoustic Scenes 2019 Mobile" というデータセットを使用します。
事前に定義されている音響シーンは2018年のものと同じです。
サブタスクAで使用したデータセットに加えて(デバイスA)、デバイスBとデバイスCのデータが追加されています(それぞれ1080ファイル)。
また、評価時には新たにデバイスDで収録されたデータが含まれます。
サブタスクCでは、"TAU Urban Acoustic Scenes 2019 Openset" というデータセットを使用します。
事前に定義されている音響シーンは2018年の10種類に、"unknown" というクラスを追加したのものです。
学習用データには、サブタスクAと同じ全部で14400ファイルに加えて、1450ファイルの unknown クラスのデータが含まれています。
また、2018年のサブタスクCのルールである、参加者が自由にデータを追加して良いというルールは、今回全てのサブタスクに適用されています。
2020 Task1: Acoustic scene classification
この年のタスクは2つのサブタスクに分かれています。
サブタスクA: 学習データは複数デバイス、評価データも複数デバイス(未知デバイス含む)
サブタスクB: クラス数を3つに縮小、モデルも縮小
過去実施されていた、単一デバイスによるサブタスクが削除される形になりました。
サブタスクAでは、"TAU Urban Acoustic Scenes 2020 Mobile" というデータセットを使用します。
事前に定義されている音響シーンは2019年のものと同じです。収録されている都市の情報も2019年と同様に与えられます。また、今回は実録音データに加えて、デバイスA(バイノーラルマイク)のデータを加工したデータも使用されます。1ファイル10秒で、学習用データは全部で64時間分です。評価用データには未知のデバイスの実データと未知のシミュレートデータが含まれます。
サブタスクBでは、"TAU Urban Acoustic Scenes 2020 3Class" というデータセットを使用します。
事前に定義されている音響シーンは、下記の通り10種類から3種類に変換されています。
TAU Urban Acoustic Scenes 2020 3Class 音響シーン一覧
- Indoor scenes - indoor: airport, indoor shopping mall, and metro station
- Outdoor scenes - outdoor: pedestrian street, public square, a street with a medium level of traffic, and urban park
- Transportation related scenes - transportation: traveling by bus, traveling by tram, traveling by underground metro
学習用データセットは合計40時間で、おそらくデバイスA(バイノーラルマイク)のもののみを利用しています。
このサブタスクは制約として、提出するモデルのパラメータサイズ上限を500KBと定めています。
Sound Event Detection
音響イベント分類では入力に対して1つのクラスを出力すれば良かったのですが、音響イベント検出では出力がより複雑になります。
事前に定義されている音響イベントそれぞれに対して、ある時刻にそのイベントが発生しているかどうか(0が発生していない、1が発生している)を推定して、時系列ベクトルデータとして出力します。
深層学習技術によって大きく進展した分野であると言えます。
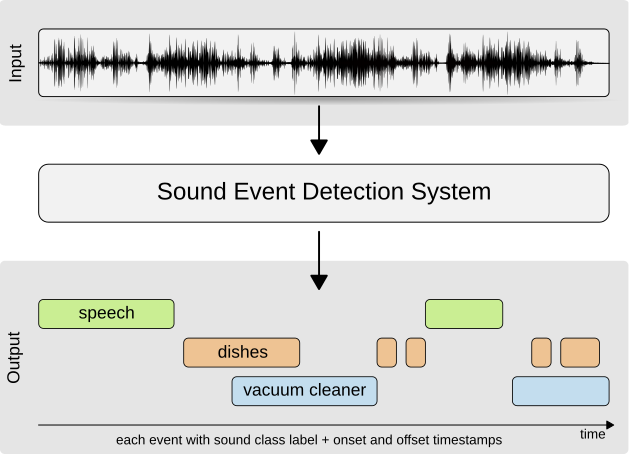 (DCASEのウェブサイトより)
(DCASEのウェブサイトより)
工事中
2013 Task2: Sound event detection
2016 Task2: Sound event detection in synthetic audio
2016 Task3: Sound event detection in real life audio
2017 Task2: Detection of rare sound events
2017 Task3: Sound event detection in real life audio
2017 Task4: Large-scale weakly supervised sound event detection for smart cars
2018 Task4: Large-scale weakly labeled semi-supervised sound event detection in domestic environments
2019 Task4: Sound event detection in domestic environments
2020 Task4: Sound event detection and separation in domestic environments
Sound Event Localization and Detection
音響イベント検出に加えて各イベントの音源の位置も推定しようというタスク。
2020年時点では音源の方向のみの推定にとどまっているようです。
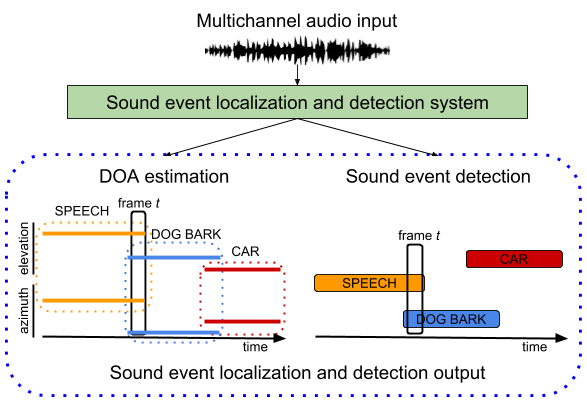 (DCASEのウェブサイトより)
(DCASEのウェブサイトより)
工事中
Audio Tagging
入力音に対して、それがどのような属性を持つのか推定するタスク。
出力がクラス数の長さをもつベクトルになります。
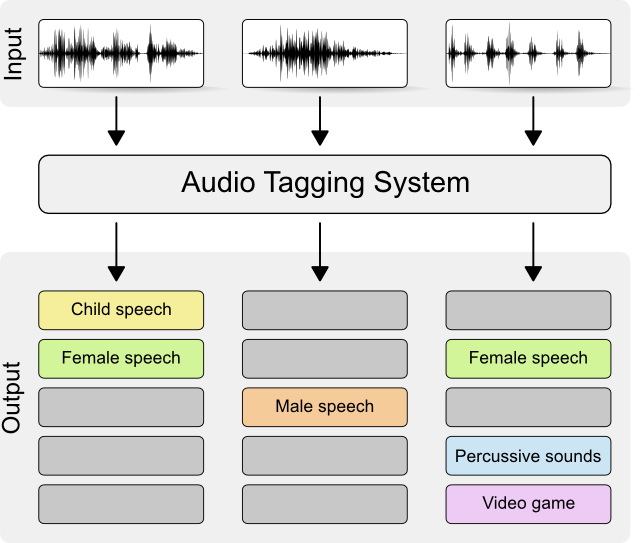 (DCASEのウェブサイトより)
(DCASEのウェブサイトより)
工事中
まとめ
DCASE という研究分野・コミュニティについて紹介しました。
チャレンジの推移をみていくと、データセットが少しずつ充実していき、またチャレンジの内容も積極的に更新されてきているのがわかります。
音響シーン分類のタスクだけみても、収録デバイスの多様化と収録地域の多様化を経て、より汎用的なアルゴリズムが求められるように変化していき、2020年にはモデルの複雑さに制約を加えるという新たな要素が追加されています。
2021年はどのようなタスクが設定されるのでしょうか?
この5年間で大きく進展してきている分野ですので、この記事をみて少しでも興味をもたれた方は、DCASE2020 Workshop(オンライン開催) の内容が Youtube に公開されていますので(Youtubeチャンネル)、是非ご覧ください。
-
わかりやすいスライド https://www.slideshare.net/yumakoizumi75/icassp-2019 ↩
-
IEEE Workshop on Applications of Signal Processing to Audio and Acoustics ↩
-
このときの Challenge Proposal を見ると、DCASEが CASA(Computational Auditory Scene Analysis) にとても関連した分野であると述べられています。CASAは計算機による音の情景分析と訳されますが、理論的にも非常に奥が深い分野です(個人の感想)。 ↩
-
Tampere University of Technology: タンペレ工科大学 ↩
-
Tampere University: 調べたところによると2019年にThe University of Tampere と TUT が合併してできた大学のようです。フィンランドにあります。 ↩