はじめに
ソートアルゴリズムの一つとしてヒープソートというものがあります。ちょっと興味を持って調べてみたので、その結果をまとめてみました。最後にヒープソートをKotlinで実装しています。
ヒープソートは最悪計算量、平均計算量ともに$O(n log n)$と高速です。また、不安定ソートであることや、内部ソートであるといった特徴があります。
マージソートやクイックソートほどの存在感はないかもしれませんが、イントロソートの一部としてC++などの標準ライブラリで採用されている実績があります。
ヒープについて
ヒープソートはヒープというデータ構造を使用してソートを行います。ヒープはデータ構造の一種です。
ヒープ(heap)とは、データ構造の一種で、木構造(ツリー構造)のうち、親要素が子要素より常に大きい(あるいは小さい)という条件を満たすもの。
通常は二分木です。たとえばこういうデータ構造です。
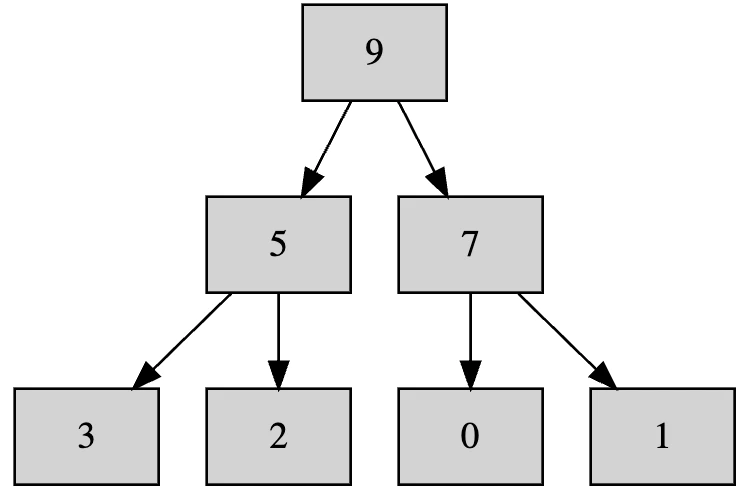
ヒープの特徴として、単純な配列で表現可能という点があります。
たとえば上記のヒープを配列で表現すると、以下のようになります。
[9, 5, 7, 3, 2, 0, 1]
上から下、左から右に並べただけですね。これの良いところとしては、ある要素の親の位置と子の位置を計算で求められるという点があります。つまり探さなくていいので、親や子に定数時間で(要するに高速に)アクセスできます。
ある要素の位置が$i$だとします。添字は0から始まる前提です。その場合、親の位置は$(i - 1) // 2$(小数点以下切り捨て)、左の子の位置は$i * 2 + 1$、右の子の位置は$i * 2 + 2$となります。
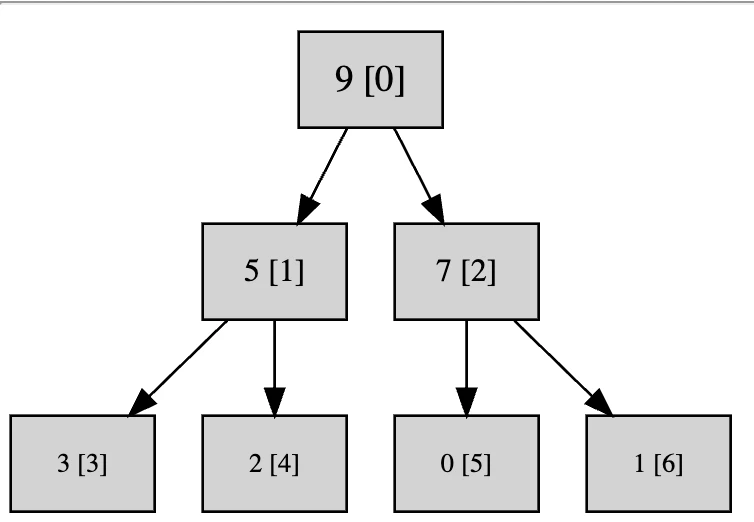
たとえば7の位置は2です。親は$(2 - 1) // 2$で0、左の子は$2 * 2 + 1$で5、右の子は$2 * 2 * 2$で6となります。
また、このように表現するとヒープの中の最大値は常に配列の先頭要素です。最大値を一瞬で習得できるということです。いかにもソートに応用できそうですね。
ヒープを構築する
ヒープを使ってソートするには、無秩序に並んだ配列からヒープを作る必要があります。その方法について説明を試みます。
先ほど見たのは既にヒープになっている配列でした。その配列は、もともとは以下のような配列だったとします。
[0, 1, 7, 3, 5, 9, 2]
二分木で表すとこうなります。

このままだとヒープではありません。これをヒープにするには、大小関係が食い違う部分を変更していけばいいですね。素朴に考えると上からやっていきたくなりますが、右下からやるほうが効率がいいです。
まずはここです。
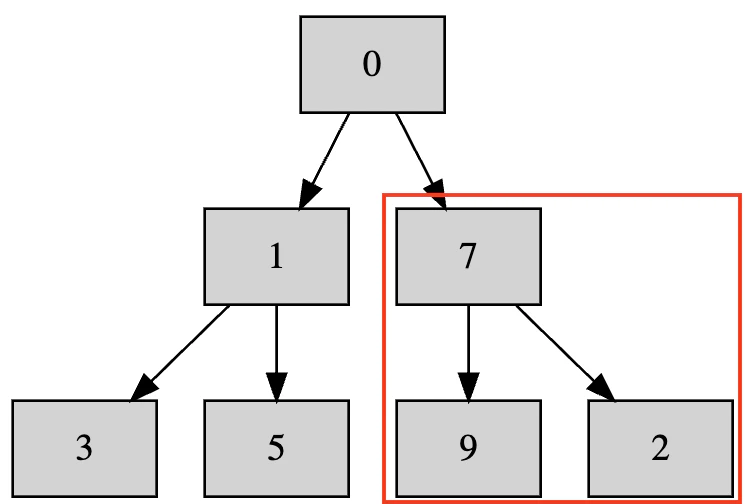
7と9の大小関係が異なるので入れ替えます。

次はここです。

3と5のいずれも1より大きいですが、3ではなく5と入れ替えます。3と入れ替えると、3が親で5が子になってしまって不整合になるからです。
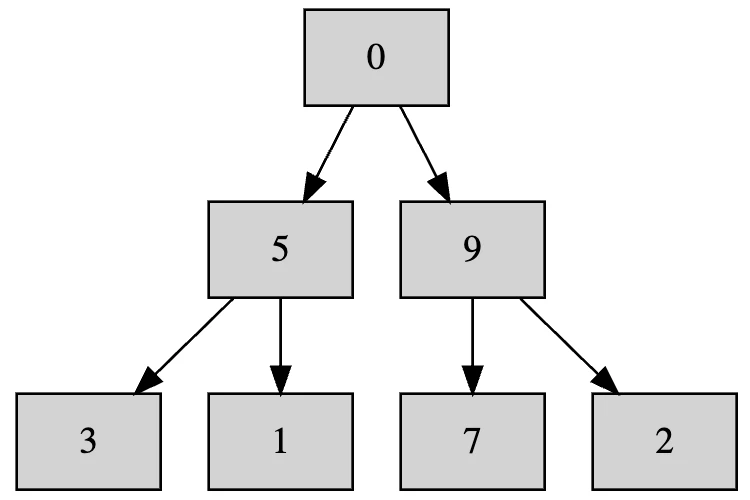
次はこちら。

先ほどと同様に0と9を入れ替えます。
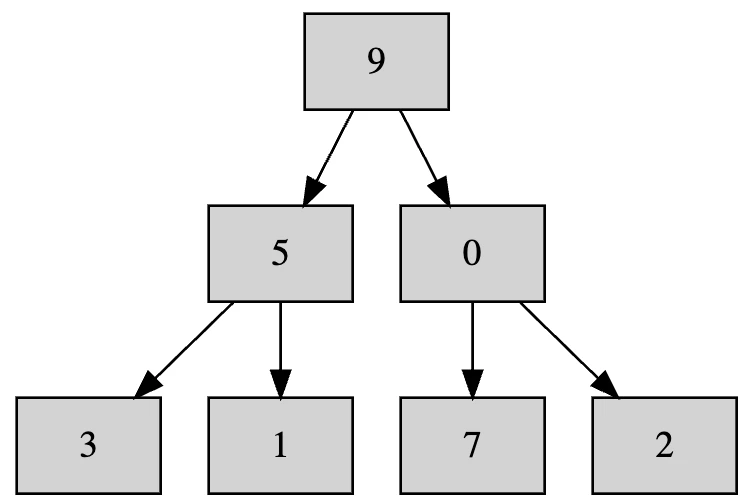
これで終わりかというとまだです。入れ替えを行なった場合、大きい要素が上に行くのはいいのですが、小さい要素が下に行くと、それによって不整合が生じるかもしれません。なので、入れ替えを行なったら下に移動した要素を親とした場合にどうなっているかも再帰的に調べていく必要があります。最初の2回についてはそれより下に子がなかったので気にしなくてもよかったのですが。
ということで見てみると、7より小さい0が親になっているのでおかしいです。
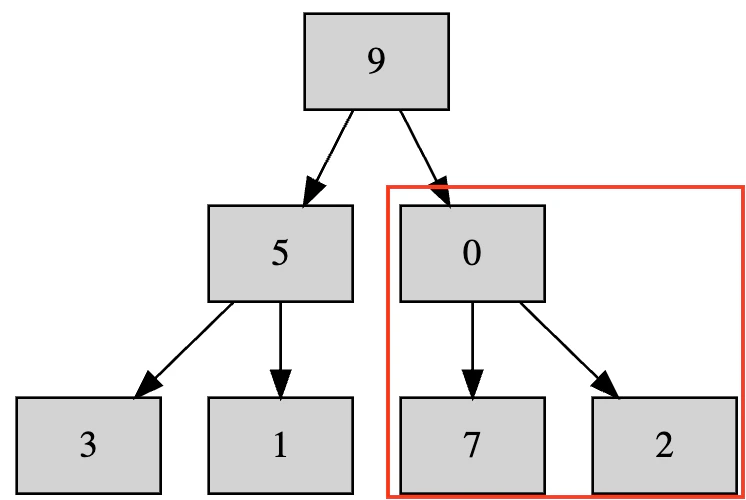
ということで入れ替えます。
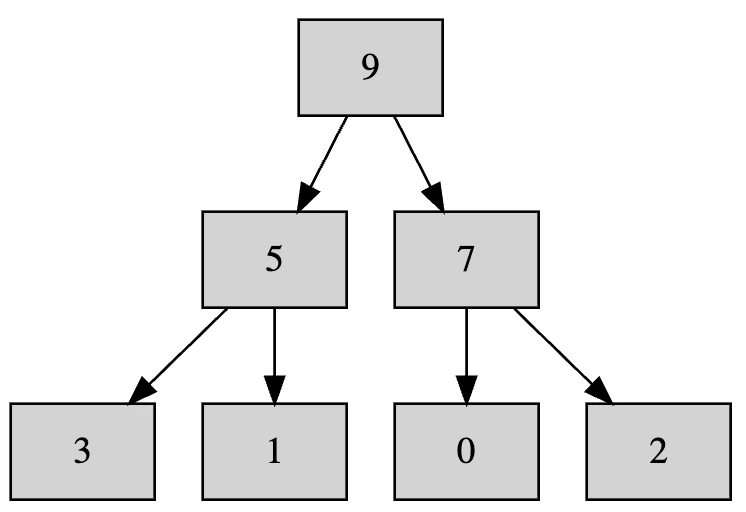
下に移動した後の0に子がいるのであれば再帰的に調べていく必要がありますが、今回は下に子はいないのでこれで終わりです。
よく見ると最初にお見せしたヒープと少し違うのですが、大小関係は合っているのでこれはこれで正しいヒープです。ソートするのに支障はありません。
ヒープソート
いよいよソートします。ここまでの話がわかっていれば、あとは簡単です。ヒープソートは以下の手順で実行します。
- 配列をヒープにする
- 最大値を取り出して結果の配列に入れる
- ヒープを再構築する
- 再度最大値を取り出して結果の配列の前に入れる
- ヒープを再構築する
- (ヒープが空になるまで繰り返す)
具体的に見てみます。
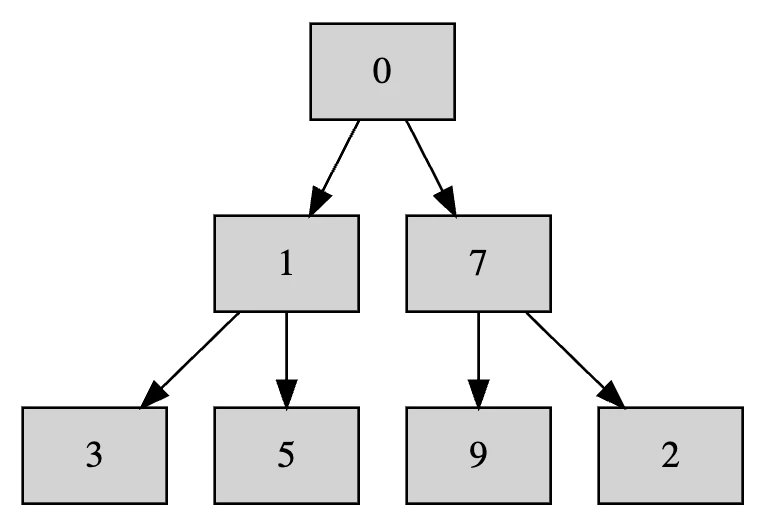
まずはこれをヒープにします。手順は先ほど見たとおりです。

続いて、最大値である9を取り出して結果の配列に詰めます。
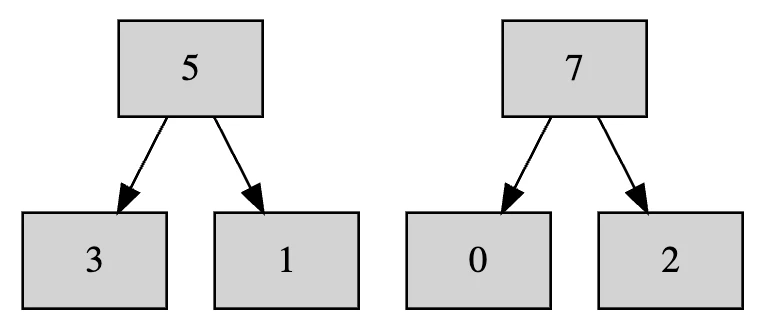
[9]
これで一旦ヒープとしては崩壊します。これをヒープとして再構築します。ひとまず仮で右下の要素を根にします。
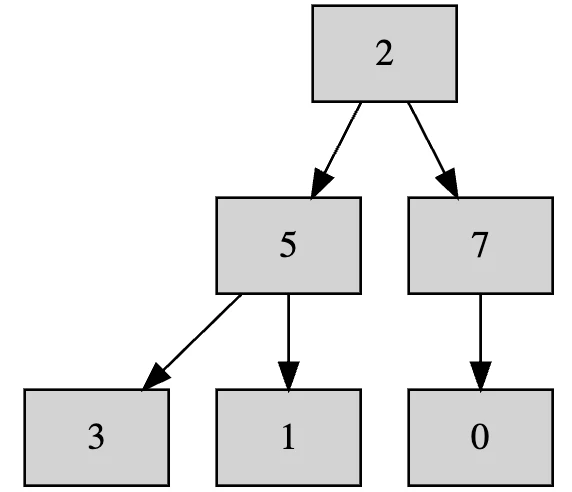
そして2が正しい位置に沈むまで再帰的に入れ替えを行います。
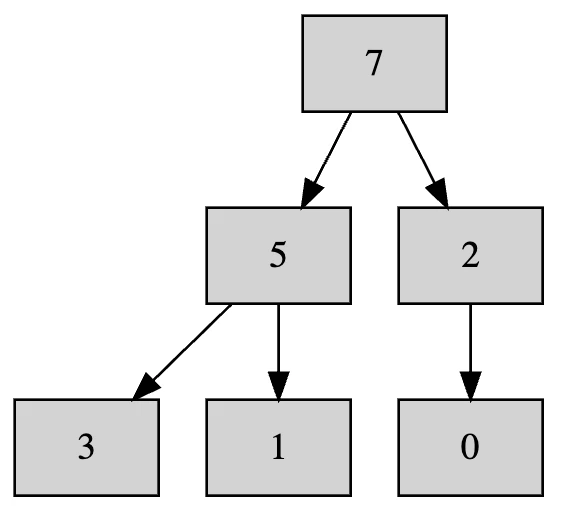
今回はたまたま1回の入れ替えでヒープになりましたが、2回以上続くこともあります。
あとはこれの繰り返しです。
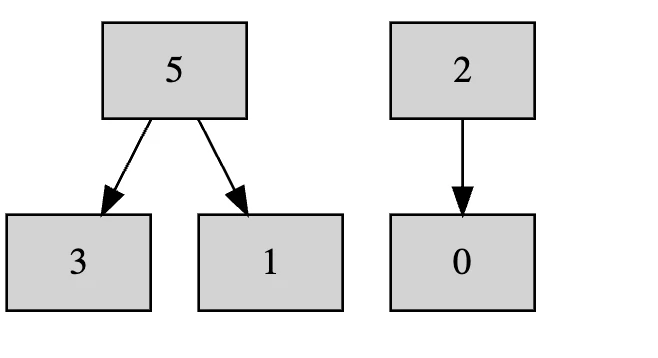
[7, 9]
最後までやると長くなるのでここまでにしますが、このようにしてソートができます。
計算量について
実装する前に計算量について考えてみます。まず無秩序な配列をヒープ化する処理ですが、この計算量は$O(n log n)$です。
ある要素を正しい位置まで沈めるには、最悪の場合は高さに比例した処理回数となります。ただ、二分木なので高さは$O(log n)$程度で、要素が大量だとしても大した高さになりません。要素数が倍になっても高さは倍にはならず、1増えるだけです。
要素一つに対してそれですが、全体をヒープにするにはその処理を各要素に対して行う必要があります。全要素かはさておき、処理対象の要素数は全体の要素数に比例して増えます。つまり$O(n)$です。
全体の処理回数としては上記のかけ合わせなので、ヒープ化処理の全体の計算量としては$O(n log n)$になります。
続いて実際のソート処理の計算量です。最大値を取り出してヒープを再構築、の繰り返しでできるのでしたね。まず最大値の取り出しですが、上で見た通りこれは$O(1)$で可能なのでボトルネックになりません。ヒープの再構築ですが、これは新たに根になった要素一つに対して実行すればいいので$O(log n)$です。ヒープをいちいち作り直すと考えると遅そそうに思えますが、部分的に作り直すだけなのでそれ自体は十分に高速です。
それで、「最大値を取り出してヒープを再構築」の操作はおおむね全体の要素と同じ回数だけ実行します。なのでそれの計算量は$O(n)$です。ソート処理の全体としては上記とのかけ合わせなので、計算量は$O(n log n)$です。
配列のヒープ化とソートのいずれの計算量も$O(n log n)$なので、ヒープソート全体の計算量も$O(n log n)$となります。$O(n log n)$の操作が2回なので、定数倍としては重いかもしれません。
実装
長くなりましたが、ようやく実装です。
まずは配列内要素の入れ替えのためのユーティリティが欲しいです。
// 配列内の任意の2要素の入れ替え
fun swap(array: IntArray, i: Int, j: Int) {
if(i != j) {
val tmp = array[i]
array[i] = array[j]
array[j] = tmp
}
}
続いて、ある1要素を指定してそれを正しい位置まで沈める処理です。これがコアの処理ですね。
先ほどの説明だとソート時に最大値を取り出すと表現しましたが、実装上は配列の後ろに移動することでそれを実現したほうがメモリ使用量を減らせます。そのためには、後ろへ移動した最大値については、ヒープの再構築処理の対象外にする必要があります。そのために、配列の末尾の位置は引数で渡すようにします。
// 1要素について、大小関係関係が正しい位置まで沈める
fun heapify(array: IntArray, parentIndex: Int, end: Int) {
// 親、左の子、右の子のうちの最大値の位置
var largestIndex = parentIndex
// 左の子の位置
val leftChildIndex = parentIndex * 2 + 1
// 右の子の位置
val rightChildIndex = parentIndex * 2 + 2
// 左の子との比較
if(leftChildIndex <= end && array[largestIndex] < array[leftChildIndex]) {
largestIndex = leftChildIndex
}
// 右の子との比較
if(rightChildIndex <= end && array[largestIndex] < array[rightChildIndex]) {
largestIndex = rightChildIndex
}
// 親が最大ではなかった場合
if(array[parentIndex] != array[largestIndex]) {
// 入れ替え
swap(array, parentIndex, largestIndex)
// 入れ替えて下に行った要素の子に対しても再帰的に処理する
heapify(array, largestIndex, end)
}
}
続いて配列全体をヒープにする処理です。上記の関数を各要素に対して実行します。全要素を見てもいいのですが、実際には真ん中から先頭まで見れば十分です。子の位置は$(i * 2 + 1)$と$(i * 2 + 2)$でしたね。$i$が配列の要素数の半分より大きい場合にその計算を実行すると必ず配列の末尾の位置を超えることから、配列の要素数の半分より先の位置にある要素には子はいないと言えます。
// 配列全体をヒープにする
fun heapify(array: IntArray) {
// 処理の開始位置
// 要素数の半分より右の要素に子がいることはないので、真ん中から先頭まで見ていけばいい
val index = array.size / 2
for(i in index downTo 0) {
heapify(array, i, array.size - 1)
}
}
最後にソート処理です。前述の通り、最大値の取り出しを配列内の後ろの要素との入れ替えで実現しています。
// ヒープソート
fun heapSort(array: IntArray) {
// 配列全体をヒープにする
heapify(array)
// ソート処理
for(i in array.size - 1 downTo 0) {
// 先頭要素(最大値)を後ろに移動するために入れ替え
swap(array, 0, i)
// 新たに先頭になった要素を正しい位置まで沈める(ヒープの再構築)
// 後ろに移動した最大値を処理対象にしないようにする
heapify(array, 0, i - 1)
}
}
全体は以下の通りです。
// 配列内の任意の2要素の入れ替え
fun swap(array: IntArray, i: Int, j: Int) {
if(i != j) {
val tmp = array[i]
array[i] = array[j]
array[j] = tmp
}
}
// 1要素について、大小関係関係が正しい位置まで沈める
fun heapify(array: IntArray, parentIndex: Int, end: Int) {
// 親、左の子、右の子のうちの最大値の位置
var largestIndex = parentIndex
// 左の子の位置
val leftChildIndex = parentIndex * 2 + 1
// 右の子の位置
val rightChildIndex = parentIndex * 2 + 2
// 左の子との比較
if(leftChildIndex <= end && array[largestIndex] < array[leftChildIndex]) {
largestIndex = leftChildIndex
}
// 右の子との比較
if(rightChildIndex <= end && array[largestIndex] < array[rightChildIndex]) {
largestIndex = rightChildIndex
}
// 親が最大ではなかった場合
if(array[parentIndex] != array[largestIndex]) {
// 入れ替え
swap(array, parentIndex, largestIndex)
// 入れ替えて下に行った要素の子に対しても再帰的に処理する
heapify(array, largestIndex, end)
}
}
// 配列全体をヒープにする
fun heapify(array: IntArray) {
// 処理の開始位置
// 要素数の半分より右の要素に子がいることはないので、真ん中から先頭まで見ていけばいい
val index = array.size / 2
for(i in index downTo 0) {
heapify(array, i, array.size - 1)
}
}
// ヒープソート
fun heapSort(array: IntArray) {
// 配列全体をヒープにする
heapify(array)
// ソート処理
for(i in array.size - 1 downTo 0) {
// 先頭要素(最大値)を後ろに移動するために入れ替え
swap(array, 0, i)
// 新たに先頭になった要素を正しい位置まで沈める(ヒープの再構築)
// 後ろに移動した最大値を処理対象にしないようにする
heapify(array, 0, i - 1)
}
}
テスト
手元でデータを作ってテストしてもいいのですが、性能を確かめることまで考えるとちょっと面倒です。幸い、もっと楽な方法があります。それは、競技プログラミングの問題の解答コードとして投げることです。
たとえば以下のような問題があります。
問題内容の解説はしませんが、素直に解くのであればソートが必要な問題だということがわかれば十分です。また、入力される配列が大きいため、計算量が$O(n^2)$とかだと遅すぎて不正解になるというのがポイントです。
たとえば、この問題では最大で20万件の要素をソートすることになります。計算量が$O(n^2)$の場合、ざっくりいえば400億回の計算が必要となって非常に遅いです。
一方、計算量が$O(n log n)$であればざっくり400万〜500万回程度でしょうか。競技プログラミングに馴染みがないとそれでも遅そうに思えるかもしれないですが、超ざっくり言えばだいたい1億以下くらいならセーフです。なので400万〜500万回程度なら全く問題ありません。
計算量が$O(n^2)$であるソートアルゴリズムとして、たとえばバブルソートがあります。以下はバブルソートで実装して実行時間超過で不正解となった解答です。

テストケースが27個あるうち4個については正解していますが、残りの23個については実行時間超過で不正解となったという結果です。これを全てAC(正解)にしたいわけです。
以下は前掲のヒープソートのコードをそのまま使った解答です。
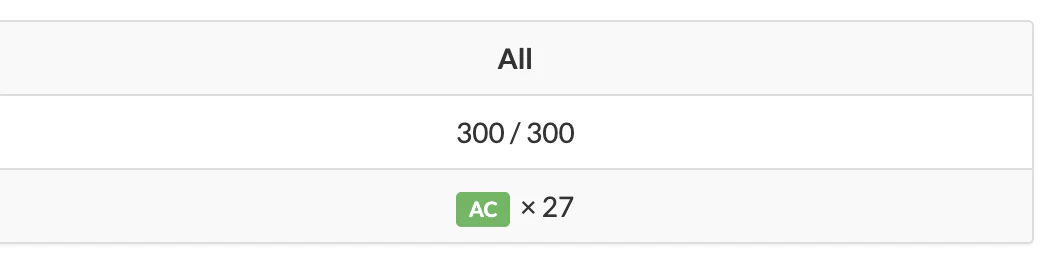
全てACになりました。これで前掲のコードは(少なくともこの問題の27個のテストケースに対しては)正しい結果となり、かつ十分に高速であることが示せました。
おわりに
ソートアルゴリズムの実装は楽しい!