この記事はリンク情報システムの2018年アドベントカレンダーのリレー記事です。
engineer.hanzomon というほぼ勝手に命名したグループのメンバによってリレーされます。(リンク情報システムのFacebookはこちらです)
4日目は大伍がお届けします。
なんだか長い記事になってしまいました。
はじめに
「コンピュータシステムの理論と実装」をバイブルとしてCPU実装から始めて、アセンブラ、VM、コンパイラを自作し、最終的に簡易なアプリケーションを動かすことを目指します。
過去、バイブル通りに一通り実装しましたが、バイブルでは著者が提供するシミュレータ上で動かすことになります。
今回のトライではFPGAを用いて実際のハードウェアで動作可能とし、さらに少々カスタマイズを施した俺々コンピュータを作成します。
まずは歩みの第一弾として以下の感じでカウンタを7セグLEDに出力してみます。

経緯など
「コンピュータシステムの理論と実装」はNANDから始めて、モニタとキーボードを持つコンピュータシステムを作る神本です。
この本は本当に良い本で僕のバイブルの一冊であり、以前カバンの中でお茶がこぼれてビチョビチョになったせいかも知れませんがいい感じでボロボロ、パリパリになりつつあります。

「コンピュータシステムの理論と実装」では独自HDLでCPUを作成し、アセンブラ、VM変換器・VM言語、コンパイラも作成して、コンピュータシステムを理解していく事になります。
巷にはホストコンピュータ無しでロジックICからすべてを積み上げていってコンピュータを作った猛者もいます。原始からのコンピュータの歴史をなぞるような、または海で生命が生まれて進化してゆく様を見るような面白い話ですよね。
僕自身は低レイヤやFPGAは素人なので、強い人から見たらナニコレ的な記述が多くなると思います。
また、バイブルの内容をFPGAで動くように移植しただけになる可能性もありますが、それはそれで良しとします。さらに、実装を進めるにあたり行き詰った場合にネットに落ちている答えをカンニングしています。
CPU実装やコンパイラの話などは、少なくとも僕の仕事の範疇ではお金にならない趣味の領域です。巷のFPGA界隈では生のHDLで何かを作る事は非常に少なく、SoCの一部としてCPUと組み合わせてFPGAを利用し、またHDLは書かずに(C言語とかで書く)高位合成を利用する事が主流です(と感じています)。
なので今回のトライは本当に基礎学習的な話であり、世間と乖離した全然お金のにおいがしないネタとなります(笑)。
ただし、、、数年に一度はそういったスキルが発揮できるタイミングがあるものです。そういったスキルは普段の素振りによってムキムキの筋肉があるからこそ発揮できるものと思います。
想定読者
・ムキムキ筋肉に興味がある
・低レイヤに興味がある
・すべて独自実装することに興味がある
・「コンピュータシステムの理論と実装」の読者、または興味がある人
・巨人たちの掌の上から少しでも出たい
【注意】
「コンピュータシステムの理論と実装」をこれから読む方は以降の内容が若干のネタバレを含んでいるのでご注意ください。
とは言っても素人の戯言ではあるので大したことないです。
構成
なんだか妙に前置きが長くなりましたが始めます。
今回の開発環境などは以下です。
・FPGA
AlteraのCycloneIIIが載っているDE0というボードを使用します。
・Verilog
HDLはVerilogを使用します。
Verilogで回路を記述し、CPU、RAM、ROMを構築していきます。
・QuartusIIの13、ModelSim
QuartusIIは論理合成する際に使用します。
ModelSimはシミュレーションで使用します。
ちなみにQuartusIIのエディタは中々の古めかしさなので使用しません。VSCodeでコードを書いて論理合成だけでQuartusIIを使用します。
これだけでCPU実装を試すことが出来ます。ソフトウェア系の人にとってはDE0などのボードを買えばあとは無料なので敷居が低く入りやすいと思います。
前提
・Verilog自体の説明はしません。
・QuartusII、ModelSimの説明もしません。
・DE0(CycloneIII)を使用する為、QuartusIIはver13を利用することになります。
QuartusはPrimeとか新しいものがでているのですが、CycloneIIIの論理合成が可能なver13を使用するしかないです。
第一回目で実装すること
アドベントカレンダーの1記事だけでは書ききれず、時間もないので数回に分けます。
本記事は第一回目として、カウンタを動かすところまで行きます。
1. ブール論理回路
2. ブール算術
3. 順序回路
4. 機械語
5. CPU
6. コンピュータシステム
7. DE0の7セグLEDでカウンタ表示を行う
1. ブール論理回路
コンピュータの中の小さな粒々を作っていきます。
バイブルではNANDを元にANDやOR、NOTなどの論理回路を作成します。
Verilogを使用するとそういったプリミティブな回路は演算子だけで事済みますが、今回は素から作成することをテーマに、できるだけ粒々も作っていきます。
NAND
module _Nand(
input wire a,
input wire b,
output wire out);
assign out = ~(a & b);
endmodule
上記はVerilogで記述したNAND回路です。
NANDについては回りくどいですが、Verilogの & 演算子 と ~ 演算子を使用して敢えて実装します。
バイブルにおいてもNANDは根源として扱われており、自作回路?を作成していません。
module名の先頭に「_」を付与して「_Nand」としています。
これはQuarusIIで定義されている「Nand」との衝突を回避するためです。
後述のNOTやANDについても同理由で _Not, _And と命名しています。
一応、最初なのでNANDの説明をすると、NANDの真理表は以下です。
| a | b | Nand(a, b) |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
NANDの字面から分かる通り「Not And」です。
a と b の AND(&) の結果をNOT(反転 ~) することでNANDした結果が得られます。
NOT
module _Not(
input wire in,
output wire out);
_Nand nand1(
.a(1'b1),
.b(in),
.out(out));
endmodule
NOTです。
NANDの aを1固定、bにNOTの入力値を配線することでNOT値が得られます。
つまり、NANDの真理表の下2つを利用しています。
| a | b | Nand(a, b) |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 0 | 1 これと |
| 1 | 1 | 0 これ |
NANDのa,b両方にNOTの入力値を配線する方法もあります。これの方がエレガントな感じがします。
AND
module _And(
input wire a,
input wire b,
output wire out);
wire nandOut;
_Nand nand1(.a(a), .b(b), .out(nandOut));
_Not not1(.in(nandOut), .out(out));
endmodule
ANDです。
NANDの結果を反転させることでANDが得られます。そりゃそうだ。
2回NANDすることでANDを得る方法もあります。
OR
module _Or(
input wire a,
input wire b,
output wire out);
wire not1Out, not2Out, andOut;
_Not not1(.in(a), .out(not1Out));
_Not not2(.in(b), .out(not2Out));
_And and1(.a(not1Out), .b(not2Out), .out(andOut));
_Not not3(.in(andOut), .out(out));
endmodule
ORは少々記述量多いですね(笑)。
①まず、a と b を反転させます。
②a と b でANDを取ります。
③そのAND結果を反転させるとORが取れます。
横につなげて書くと以下のイメージです。
いい感じで入力のa, bからORが取れていますね。
| a | b | Not(a) | Not(b) | And(a, b) | Not(結果) | |||
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | ⇒ | 1 | 1 | ⇒ | 1 | ⇒ | 0 |
| 0 | 1 | ⇒ | 1 | 0 | ⇒ | 0 | ⇒ | 1 |
| 1 | 0 | ⇒ | 0 | 1 | ⇒ | 0 | ⇒ | 1 |
| 1 | 1 | ⇒ | 0 | 0 | ⇒ | 0 | ⇒ | 1 |
Mux, And16, Not16, Mux16、XOR、他
マルチプレクサであるMux、多入力のAnd16などのゲートについても同じ要領で実装していきます。
テストベンチについて
各回路ごとにテストベンチを作成してテストを行います。
FPGA(HDL)はデバッグがしづらい為、修正を行ったらテストベンチを実行してデグレがないことを小まめに確認します。
幸い、バイブルには各回路ごとにテストケース的なファイルが提供されている為、これを元にテストベンチを作成します。
2. ブール算術
ブール算術で作成した回路を使って加算器やALUなどを実装します。
半加算器
module HalfAdder(
input wire a, // 値1
input wire b, // 値2
output wire sum, // 結果
output wire carry); // キャリーフラグ
_Xor xor1(.a(a), .b(b), .out(sum));
_And and1(.a(a), .b(b), .out(carry));
endmodule
1ビットと1ビットを足し算する半加算器です。
加算結果 sum は XOR することで得られます。
桁上がり carry は a と b の AND で取ります。
全加算器
module FullAdder(
input wire a, // 値1
input wire b, // 値2
input wire c, // 下位の桁上がり
output wire sum, // 加算結果
output wire carry); // 桁上がり
wire ha1Sum;
wire ha1Carry;
wire ha2Carry;
HalfAdder ha1(a, b, ha1Sum, ha1Carry);
HalfAdder ha2(ha1Sum, c, sum, ha2Carry);
_Or or1(.a(ha1Carry), .b(ha2Carry), .out(carry));
endmodule
全加算器です。
下からの桁上がりを考慮したものを全加算器と言います。
まず、1つ目の半加算器で a と b の加算結果Aを取得します。
2つ目の半加算器で加算結果A と c を加算します。この結果が全加算器の sum になります。
ha1 と ha2 の2つの半加算器の carry の OR が全加算器の carry となります。
加算器
module Add16(
input wire[15:0] a, // 値1
input wire[15:0] b, // 値2
output wire[15:0] out); // 結果
wire[15:0] carry;
FullAdder fa1(a[0], b[0], 1'b0, out[0], carry[0]);
FullAdder fa2(a[1], b[1], carry[0], out[1], carry[1]);
FullAdder fa3(a[2], b[2], carry[1], out[2], carry[2]);
FullAdder fa4(a[3], b[3], carry[2], out[3], carry[3]);
FullAdder fa5(a[4], b[4], carry[3], out[4], carry[4]);
FullAdder fa6(a[5], b[5], carry[4], out[5], carry[5]);
FullAdder fa7(a[6], b[6], carry[5], out[6], carry[6]);
FullAdder fa8(a[7], b[7], carry[6], out[7], carry[7]);
FullAdder fa9(a[8], b[8], carry[7], out[8], carry[8]);
FullAdder fa10(a[9], b[9], carry[8], out[9], carry[9]);
FullAdder fa11(a[10], b[10], carry[9], out[10], carry[10]);
FullAdder fa12(a[11], b[11], carry[10], out[11], carry[11]);
FullAdder fa13(a[12], b[12], carry[11], out[12], carry[12]);
FullAdder fa14(a[13], b[13], carry[12], out[13], carry[13]);
FullAdder fa15(a[14], b[14], carry[13], out[14], carry[14]);
FullAdder fa16(a[15], b[15], carry[14], out[15], carry[15]);
endmodule
16ビットの加算器です。
全加算器(FullAdder)を16個並べることで16ビットの加算器になります。
各 FullAdder の carry を上位の FullAdder に渡すことで桁上りを表現しています。
最上位の(16ビットを超過する)キャリーは無視します。
負数の扱い
今回のシステムは2の補数で数値を扱います。
2の補数は符号(+、-)を意識することなく、足し算ができるすごく便利なものです。
例えば2の補数において、4ビットで表現される -1 は2進数で「1111」になります。
これに 1 を加えると「0000」になります。
逆に「0001」(1)から -1 すると「0000」(0)、さらに -1 すると「1111」(-1)、さらに -1 すると「1110」(-2)となります。
これを見る側が最上位ビットが 1 だったらマイナスで、、と読み取ることでマイナス値を扱っています。
負数の値が2進で見ると分かりづらかったり、最上位ビットがある意味符号的な意味を持つので1ビット分損しますが、それを上回る利便性です。
インクリメンタ
module Inc16(
input wire[15:0] a, // 値
output wire[15:0] out); // 結果
Add16 add(a, 16'd1, out);
endmodule
インクリメントだけを行う回路です。
内部で1インクリするAdd16を配線しているだけです。
ALU
コンピュータらしさ漂うALU(Arithmetic Logic Unit:算術論理演算器)です。
module ALU(
input wire[15:0] x, // 値x
input wire[15:0] y, // 値y
input wire zx, // 入力xをゼロにする
input wire nx, // 入力xを反転する
input wire zy, // 入力yをゼロにする
input wire ny, // 入力yを反転する
input wire f, // 関数コード(1:加算、0:And演算)
input wire no, // 出力outを反転する
output wire[15:0] out, // 結果
output wire zr, // out=0 の場合にtrue
output wire ng); // out<0 の場合にtrue
// 入力xをゼロにする
wire [15:0] zxX;
assign zxX = zx ? 16'b0 : x;
// 入力xを反転する
wire[15:0] notZxX;
Not16 not16x(.in(zxX), .out(notZxX));
wire[15:0] nxX;
assign nxX = nx ? notZxX : zxX;
// 入力yをゼロにする
wire [15:0] zyY;
assign zyY = zy ? 1'b0 : y;
// 入力yを反転する
wire[15:0] notZyY;
Not16 not16y(.in(zyY), .out(notZyY));
wire[15:0] nyY;
assign nyY = ny ? notZyY : zyY;
// 関数コード(1:加算、0:And演算)
// 1:加算 用
wire [15:0] workAdd16;
Add16 add16(
.a(nxX),
.b(nyY),
.out(workAdd16));
// 0:And演算 用
wire[15:0] andXY;
And16 and16(.a(nxX), .b(nyY), .out(andXY));
// 関数実行
wire[15:0] fOut;
assign fOut = f ? workAdd16 : andXY;
// 出力outを反転する
wire[15:0] fNotOut;
Not16 not16forOut(.in(fOut), .out(fNotOut));
assign out = no ? fNotOut : fOut;
// out=0 の場合にtrue
assign zr = (out == 16'd0) ? 1'b1 : 1'b0;
// out<0 の場合にtrue
assign ng = (out[15] == 1'b1) ? 1'b1 : 1'b0;
endmodule
基本的には入力 x, y をその他の入力で反転したり足し算したりする回路です。
input の上げている種類があれば、その組み合わせでコンピュータの基本的な計算は賄えることになります。
また、ここまでの回路もそうですがこれは組み合わせ回路なので、クロックとか関係なく入力信号の変動が即座に出力に伝わります。
このALUは数回のフィルター的な回路によって出力信号を変動させるイメージでしょうか。
①入力 zx により、x を強制的にゼロにします。
②入力 nx により、x を反転させます。
③入力 yx により、x を強制的にゼロにします。
④入力 ny により、x を反転させます。
⑤入力 f により、x,y を足し算するか、Andします。
⑥入力 no により、out を反転させます。
⑦出力 zr は、out がゼロの場合に 1 を出力します。
⑧出力 ng は、out < 0の場合に 1 を出力します。
ALUは今回のコンピュータのコア部分の一つとなります。
後述の機械語の内容により、ALUに与える入力信号が制御されることになります。
試しに x と y の OR を取ってみます。ALU の入力fは加算と AND しかないので、OR なんてできるのでしょうか。
①~④は x, y の変化、⑤以降は out の変化を見る感じで下記の表を参照ください。
表のヘッダ部分は Or を計算する際の入力値です。
| ①zx=0 | ②nx=1 | ③zy=0 | ④ny=1 | ⑤f=0 | ⑥no=1 | out | |
|---|---|---|---|---|---|---|---|
| x,y= 0,0 |
0, 0 | 1, 0 | 1, 0 | 1, 1 | 1 | 0 | 0 |
| x,y= 1,0 |
1, 0 | 0, 0 | 0, 0 | 0, 1 | 0 | 1 | 1 |
| x,y= 0,1 |
0, 1 | 1, 1 | 1, 1 | 1, 0 | 0 | 1 | 1 |
| x,y= 1,1 |
1, 1 | 0, 1 | 0, 1 | 0, 0 | 0 | 1 | 1 |
ちゃんとOrの結果が得られました。
3. 順序回路
レジスタ、RAM、カウンタなどの回路を実装します。
順序回路は回路の中で値の保持などを行い、過去に入力された値によって出力が決定される回路です。
ビット
module Bit(
input wire clk, // clk
input wire in, // in値
input wire load, // load
output wire out); // out
reg val; // 1ビットの値を保持
// クロックの立ち上がりでloadが1の時にin値を保持
always @(posedge clk) begin
if(load == 1'b1) begin
val <= in;
end
end
// 保持しているvalを出力
assign out = val;
endmodule
1ビットを保持する回路です。
load が 1 の時に内部の1ビットを書き換えます。
レジスタ
module Register(
input wire clk, // clk
input wire[15:0] in, // in値
input wire load, // load
output wire[15:0] out); // out
Bit bit0(.clk(clk), .in(in[0]), .load(load), .out(out[0]));
Bit bit1(.clk(clk), .in(in[1]), .load(load), .out(out[1]));
Bit bit2(.clk(clk), .in(in[2]), .load(load), .out(out[2]));
Bit bit3(.clk(clk), .in(in[3]), .load(load), .out(out[3]));
Bit bit4(.clk(clk), .in(in[4]), .load(load), .out(out[4]));
Bit bit5(.clk(clk), .in(in[5]), .load(load), .out(out[5]));
Bit bit6(.clk(clk), .in(in[6]), .load(load), .out(out[6]));
Bit bit7(.clk(clk), .in(in[7]), .load(load), .out(out[7]));
Bit bit8(.clk(clk), .in(in[8]), .load(load), .out(out[8]));
Bit bit9(.clk(clk), .in(in[9]), .load(load), .out(out[9]));
Bit bit10(.clk(clk), .in(in[10]), .load(load), .out(out[10]));
Bit bit11(.clk(clk), .in(in[11]), .load(load), .out(out[11]));
Bit bit12(.clk(clk), .in(in[12]), .load(load), .out(out[12]));
Bit bit13(.clk(clk), .in(in[13]), .load(load), .out(out[13]));
Bit bit14(.clk(clk), .in(in[14]), .load(load), .out(out[14]));
Bit bit15(.clk(clk), .in(in[15]), .load(load), .out(out[15]));
endmodule
16ビットのレジスタです。壮観ですね。
Bitを16個並べることで16ビットのレジスタになります。
メモリ
メモリについては、Registerを8個並べたRAM8、RAM8を8個並べたRAM64、、…というようにRAM16Kまで積み上げていくのですが、これを愚直に作成すると回路が大きくなりすぎて?QuarutusIIでの論理合成が終わりません。というか、論理合成中にハードディスクにスワップ行き過ぎてダメでした。
バイブルでもRAM64Kは作者謹製の速いやつ使えとあるので、今回はサイズが小さいRAMは作成せず、4KのRAMから作成しました。
RAM4KをVerilog的に作成し、それを8個並べてRAM16Kとして実装とすることにしました。
RAM4K
module RAM4K(
input wire clk, // clk
input wire[15:0] in, // in値
input wire[11:0] address, // アドレス
input wire load, // write enable
output wire[15:0] out); // out
reg[15:0] RAM[4096-1:0];
initial begin
integer ii;
for(ii = 0; ii < 4096; ii = ii + 1) begin
RAM[ii] <= 16'd0;
end
end
always @(posedge clk) begin
if(load == 1'b1) begin
RAM[address] <= in;
end
end
assign out = RAM[address];
endmodule
16ビットのregを4K分の配列としています。
initialでクリアしていますが、多分不要ですね。
RAM16K
module RAM16K(
input wire clk, // clk
input wire[15:0] in, // in値
input wire[14:0] address, // アドレス
input wire load, // write enable
output wire[15:0] out); // out
// アドレスをセレクタとして、load値をload0~3に振り分ける
wire load0,load1,load2,load3;
DMux4Way dmux4(
.in(load),
.sel(address[13:12]),
.a(load0), .b(load1), .c(load2), .d(load3));
// load0~3でRegister0~3をロード、またはリードする
wire[15:0] out0,out1,out2,out3;
RAM4K ram0(.clk(clk), .in(in), .load(load0), .address(address[11:0]), .out(out0));
RAM4K ram1(.clk(clk), .in(in), .load(load1), .address(address[11:0]), .out(out1));
RAM4K ram2(.clk(clk), .in(in), .load(load2), .address(address[11:0]), .out(out2));
RAM4K ram3(.clk(clk), .in(in), .load(load3), .address(address[11:0]), .out(out3));
// リードしたout0~3をアドレスをセレクタにしてoutに出力する
Mux4Way16 mux8(
.a(out0), .b(out1), .c(out2), .d(out3),
.sel(address[13:12]),
.out(out));
endmodule
RAM16KはRAM4Kを4個使って実装します。
1入力4出力デマルチプレクサである DMux4Way を通して、address の上位2ビットで load0~3 のどれかを 1 にします。
その load0~3 と address の下位12ビットで読み書きする最終的なRAMを絞り込んでいます。
リードした値は、16ビット4入力マルチプレクサ(Mux4Way16)で出力値をoutに送り出します。
PC(プログラムカウンタ)
module PC(
input wire clk, // clk
input wire[15:0] in, // in値
input wire inc, // incliment flg
input wire load, // write enable flg
input wire reset, // reset flg
output wire[15:0] out); // out
// インクリメント
wire[15:0] regOut, incOut;
Inc16 inc16(.a(regOut), .out(incOut));
// inc値により、Register値かインクリメント値かをregOrIncOutに配線
wire[15:0] regOrIncOut;
Mux16 mux1(.a(regOut), .b(incOut), .sel(inc), .out(regOrIncOut));
// load値により、Reg/Inc値かin値をloadOutに配線
wire[15:0] loadOut;
Mux16 mux2(.a(regOrIncOut), .b(in), .sel(load), .out(loadOut));
// reset値により、loadOutか0かをtoRegに配線
// toRegはInc16にフィードバックされる
wire[15:0] toReg;
Mux16 mux3(.a(loadOut), .b(16'b0), .sel(reset), .out(toReg));
Register reg1(.clk(clk), .in(toReg), .load(1'b1), .out(out));
assign regOut = out;
endmodule
カウンタは少々ややこしいですね。
図にしてみました。
-
リセット
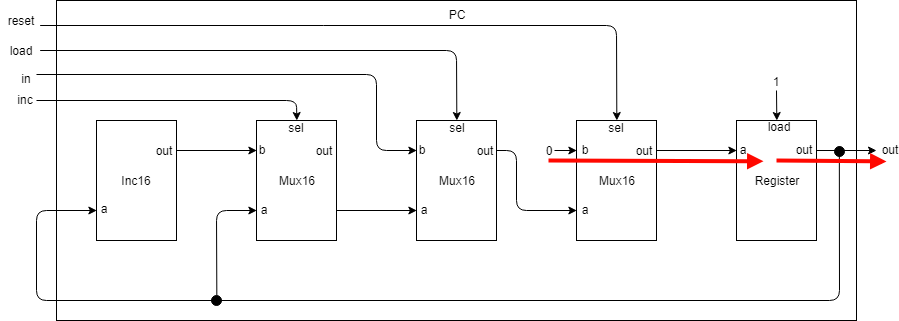
PCの入力resetがOnの場合にMux16にて入力bのゼロが出力されます。(Mux16は入力selが0の場合にaを出力、1の場合にbを出力します)
それがRegisterに一旦保持されます。
PCからのゼロ出力は次のクロックの際に出力されます。(赤線を途切れさせているのは次クロックでの出力を意図しています) -
インクリメント
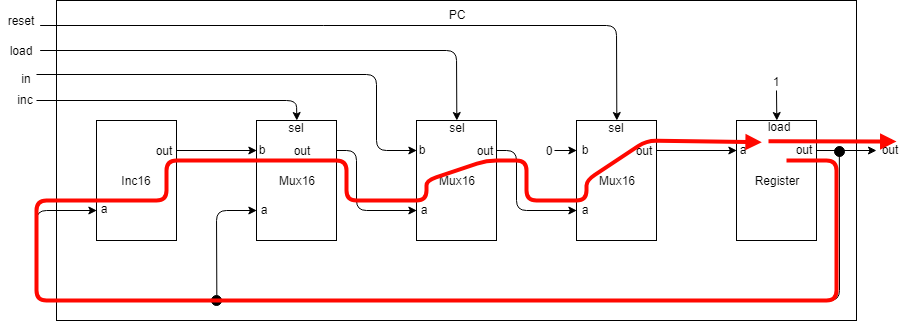
インクリメントの場合はPCに以下を入力します。
・reset = 0
・load = 0
・inc = 1
・in = なんでも
まず、Registerに保持されていた値がInc16に入力され、インクリメントされた値がoutから出力されます。
PC入力incが1の為、Mux16はインクリメント値であるbの値を出力します。
真ん中のMux16のsel入力(load)は0の為、aを出力します。
あとは見たままの感じでPCのoutにインクリメント値が出力されます。 -
ロード
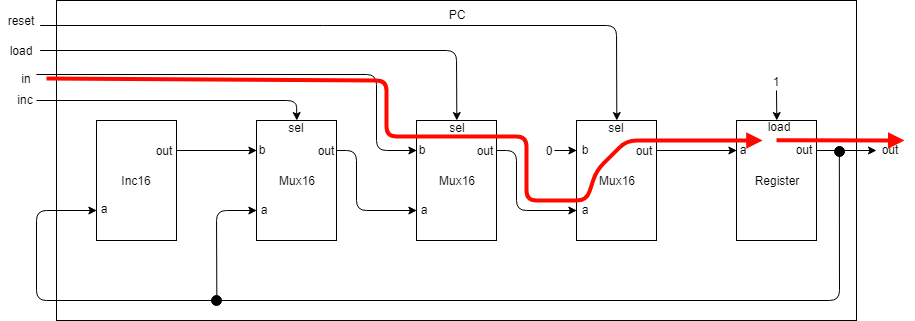
PCに保持させる値をロードさせる場合はPCに以下を入力します。
・reset = 0
・load = 1
・inc = 0
・in = 12345などの値
PC入力load=1が真ん中のMux16に入力されます。selに1が入るので、bの値、つまりPC入力のinが出力されます。
あとは見たままの感じでRegisterに値がロードされます。次のクロックでロードされた値が出力されることになります。
4. 機械語
機械語は16ビットで記載します。
大きくはA命令とC命令の2種類があります。
- A命令は、CPUのAレジスタにメモリのアドレス、または定数値を指定します。
- C命令は、①計算と②その結果をどこに格納するか③どこにジャンプするかの3つを指定します。
フォーマットは以下の感じです。
- A命令
0vvvv vvvv vvvv vvvv
・先頭ビットを0にします。
・以降のビット(上記の v )はアドレスか数値などの定数を指定します。
従って、表現できるアドレス、定数は15ビットになります。
- C命令
1xx a cccccc ddd jjj ※命令の種別の区切りでスペースを入れています。
・先頭ビットを1にします。次の2、3ビット目 xx は使いません。
・a は後述のcomp部の挙動を指定するフラグです。
0 の場合はAレジスタの値を定数と見なして計算を行う
1 の場合はメモリからの入力値(後述の inM)で計算を行う
・cccccc はcomp部です。どのレジスタを使用してどのような計算を行うか指定します。
c1 c2 c3 c4 c5 c6 という並びです。
c1~c6 はALUにそのまま入力されます。
c1 → zx へ
c2 → nx へ
c3 → zy へ
c4 → ny へ
c5 → f へ
c6 → no へ
つまりこれらの組み合わせにより各種計算を行う形です。
・ddd はdest部です。計算結果をどこに格納するかを指定します。
d1 d2 d3 という並びです。
Aレジスタ、Dレジスタ、M(メモリ出力)の3種類を組み合わせて指定します。
d1が 1 の場合は「A」、Aレジスタに結果を格納します。
d2が 1 の場合は「D」、Dレジスタに結果を格納します。
d3が 1 の場合は「M」、CPU出力のoutMに結果を出力します。(後述)
Aのみや、ADMすべてを指定することが可能です。
・jjj はjump部です。
j1 j2 j3 です。
jump部で指定された条件が真の場合にAレジスタのアドレスをプログラムカウンタに設定します。
Jumpさせる場合は事前にAレジスタにJump先を設定しておく必要があります。
j1が 1 、ALU出力が < 0 の場合にプログラムカウンタを変更する。
j2が 1 、ALU出力が = 0 の場合にプログラムカウンタを変更する。
j3が 1 、ALU出力が > 0 の場合にプログラムカウンタを変更する。
jump部は Or で判定します。
従って、jump部すべてが 1 の場合は、ALU出力がいかなる場合でもJumpを行います。
逆にすべて 0 の場合はJumpなしになります。
機械語については、アレンジ無しでバイブルそのままなので多くは書きません。
ただし、以下に 7=3+4 を計算する機械語を例示しておきます。
0: 0_000000000000010 // A命令:3 をAレジスタに格納する
1: 111_0_110000_010_000 // C命令:Aレジスタの値をDレジスタに格納する
2: 0_000000000000011 // A命令:4 をAレジスタに格納する
3: 111_0_000010_010_000 // C命令:AレジスタとDレジスタの値で加算を行い、結果をDレジスタに格納する
4: 0_000000000000000 // A命令:0 をAレジスタに格納する
5: 111_0_001100_001_000 // C命令:Dレジスタの値をCPU出力のoutMに出力する
6: 0_000000000000110 // A命令:6 をAレジスタに格納する
7: 111_0_000000_000_111 // C命令:強制的にAレジスタの値をプログラムカウンタに格納する
// つまり、6~7番地で永久ループする
5. CPU
まずは図です。
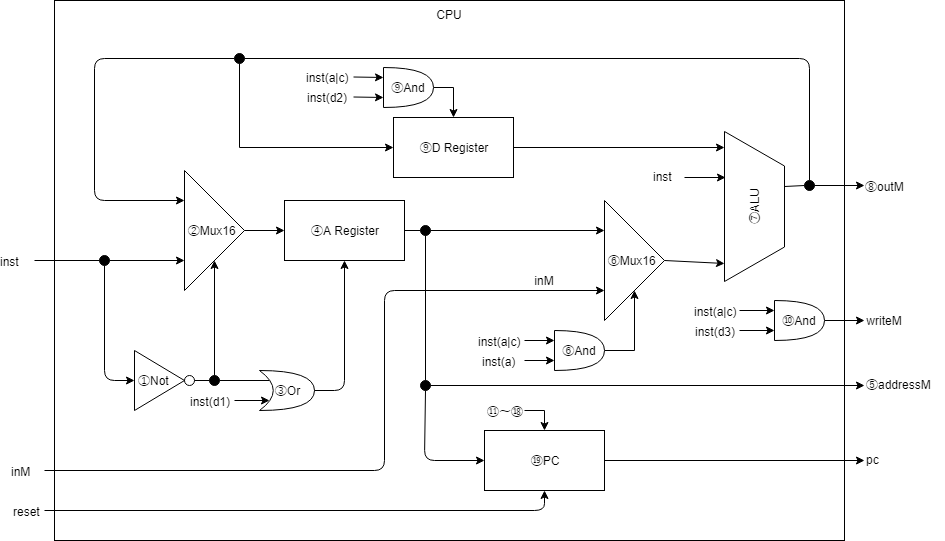
CPU.svの全量は少々長いので折りたたんでます
module CPU(
input wire clk, // clk
input wire[15:0] inM, // メモリ入力
input wire[15:0] inst, // instruction(実行する命令)
input wire reset, // reset
output wire[15:0] outM, // メモリ出力
output wire writeM, // M書き込みを行うか
output wire[14:0] addressM, // データメモリ中のMのアドレス
output wire[14:0] pc); // プログラムカウンタ出力
// ①A命令か?
wire isAinst;
Not notIsAinst(.in(inst[15]), .out(isAinst));
// ②A命令の場合は、そのアドレス(かデータ)、C命令の場合はALUの出力を toA に配線。
wire[15:0] aluOut, toA;
Mux16 mux16toA(.a(aluOut), .b(inst), .sel(isAinst), .out(toA));
// ③A命令の場合か、C命令のdestのd1がOnの場合
// (Aレジスタに計算結果を格納する命令の場合)は、Aレジスタにロードさせる
wire isAload;
wire[15:0] aOut;
_Or orIsAload(.a(isAinst), .b(inst[5]), .out(isAload));
// ④Aレジスタ
// A命令の場合か、C命令のdestのd1がOnの場合
//(Aレジスタに計算結果を格納する命令の場合)は、Aレジスタにロードさせる
Register aReg(.clk(clk), .in(toA), .load(isAload), .out(aOut));
// ⑤Aレジスタの出力は addressM としてCPUから出力
assign addressM[14:0] = aOut[14:0];
// ⑥ALUへの入力信号の準備
// C命令でcompのaがOnの場合、メモリ入力(inM)の値、
// それ以外はAレジスタの値をALUへの入力とする
wire isCompAon;
wire[15:0] AM;
_And andIsCompAon(.a(inst[15]), .b(inst[12]), .out(isCompAon));
Mux16 mux16AM(.a(aOut), .b(inM), .sel(isCompAon), .out(AM));
//
// ⑦ALU
//
wire aluOutIsZero, aluOutIsNega;
wire[15:0] d_out;
ALU alu(
.x(d_out), // Dレジスタの値を入力する
.y(AM), // Aレジスタか、inMの値を入力する
.zx(inst[11]), // c1: 入力xをゼロにするか
.nx(inst[10]), // c2: 入力xを反転するか
.zy(inst[9]), // c3: 入力yをゼロにするか
.ny(inst[8]), // c4: 入力yを反転するか
.f(inst[7]), // c5: 関数コード(1は加算、0はAnd)
.no(inst[6]), // c6: 出力outを反転するか
.out(aluOut), // out
.zr(aluOutIsZero), // out==0 の時On
.ng(aluOutIsNega)); // out<0 の時On
// ⑧ALUの出力は CPU出力の outM としても出力する
assign outM = aluOut;
// ⑨Dレジスタ
// C命令でdestのd2がOn(Dレジスタに計算結果を格納する命令)の場合は、
// ALUの出力をDレジスタにロードさせる
wire isDload;
_And andIsDload(.a(inst[15]), .b(inst[4]), .out(isDload));
Register dReg(.clk(clk), .in(aluOut), .load(isDload), .out(d_out));
// ⑩C命令でdestのd3がOn(Memory[A]に計算結果を格納する命令)の場合は、
// CPU出力 writeM をOn(メモリ書き込みをOn)
_And andWriteM(.a(inst[15]), .b(inst[3]), .out(writeM));
//
// プログラムカウンタの制御
//
// ⑪C命令でj3がOn(out > 0)が命令されているか?
wire isPositive, isNotZero;
_Not notIsPositive(.in(aluOutIsNega), .out(isPositive));
_Not notIsNotZero(.in(aluOutIsZero), .out(isNotZero));
wire instJgt, isGt;
_And andInstJgt(.a(inst[15]), .b(inst[0]), .out(instJgt));
_And andIsGt(.a(isPositive), .b(isNotZero), .out(isGt));
// ⑫PCを書き換えるか判定する為の材料(GT)
wire isPcLoadJgt;
_And andIsPcLoadJgt(.a(instJgt), .b(isGt), .out(isPcLoadJgt));
// ⑬C命令でj2がOn(out == 0)が命令されているか?
wire instJeq;
_And andInstJeq(.a(inst[15]), .b(inst[1]), .out(instJeq));
// ⑭PCを書き換えるか判定する為の材料(EQ)
wire isPcLoadJeq;
_And andIsPcLoadJeq(.a(instJeq), .b(aluOutIsZero), .out(isPcLoadJeq));
// ⑮C命令でj1がOn(out < 0)が命令されているか?
wire instJlt;
_And andInstJlt(.a(inst[15]), .b(inst[2]), .out(instJlt));
// ⑯PCを書き換えるか判定する為の材料(LT)
wire isPcLoadJlt;
_And andIsPcLoadJlt(.a(instJlt), .b(aluOutIsNega), .out(isPcLoadJlt));
// ⑰PCを書き換えるか判定する為の材料(GE)
wire isPcLoadJGe;
_Or orIsPcLoadJGe(.a(isPcLoadJgt), .b(isPcLoadJeq), .out(isPcLoadJGe));
// ⑱PCを書き換えるか
wire isPcLoad;
_Or orIsPcLoad(.a(isPcLoadJlt), .b(isPcLoadJGe), .out(isPcLoad));
// ⑲プログラムカウンタ
wire[15:0] pcOut;
PC pc1(.clk(clk), .in(aOut), .load(isPcLoad), .inc(1'b1), .reset(reset), .out(pcOut));
assign pc[14:0] = pcOut[14:0];
endmodule
各所のコードについて図と合わせて説明します。
①A命令かを判別するNot
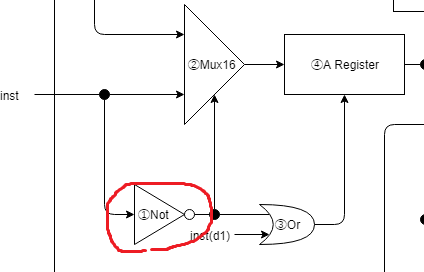
// ①A命令か?
wire isAinst;
Not notIsAinst(.in(inst[15]), .out(isAinst));
A命令/C命令の判別ビットである、instructionの先頭ビットを反転させて②のMuxに入力させています。
後続の回路でA命令かどうかの判別を楽にするためにisAinstワイヤを作っておく感じです。
②Aレジスタへの入力を決定するMux16
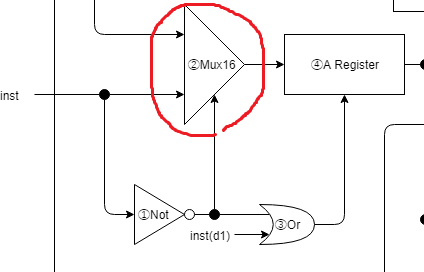
// ②A命令の場合は、そのアドレス(かデータ)、C命令の場合はALUの出力を toA に配線
wire[15:0] aluOut, toA;
Mux16 mux16toA(.a(aluOut), .b(inst), .sel(isAinst), .out(toA));
①の isAinst の信号を元にAレジスタへの入力を決定させます。
A命令の場合はアドレス/定数、C命令の場合はALU出力をAレジスタへ入力します。
③Or
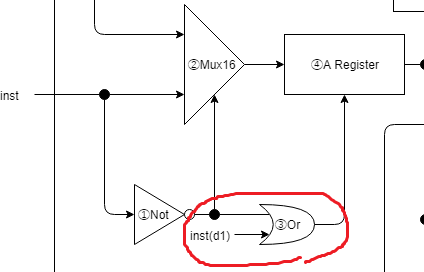
// ③A命令の場合か、C命令のdestのd1がOnの場合
// (Aレジスタに計算結果を格納する命令の場合)は、Aレジスタにロードさせる
wire isAload;
wire[15:0] aOut;
_Or orIsAload(.a(isAinst), .b(inst[5]), .out(isAload));
①の A命令、またはC命令のd1(Aレジスタに計算結果を格納する命令の場合)がOnの場合、Aレジスタへの入力loadをOnにします。
②のMuxにて、ALU出力をAレジスタに配線していましたが、それを最終的にC命令のd1でload制御しています。
④Aレジスタ
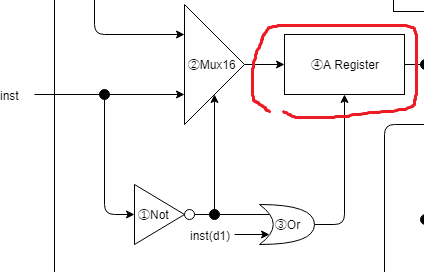
// ④Aレジスタ
Register aReg(.clk(clk), .in(toA), .load(isAload), .out(aOut));
機械語のA命令、またはC命令の計算結果をAレジスタを保持することになります。
ただし、後者の場合はC命令d1ビットがOnの場合のみになります。
ここまでで何回か繰り返し書いていますが、Aレジスタで保持する値は、A命令のアドレス/定数、もしくはC命令での計算結果のいずれかになります。
⑤addressMの出力
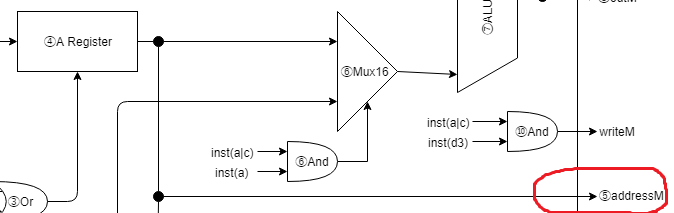
// ⑤Aレジスタの出力は addressM としてCPUから出力
assign addressM[14:0] = aOut[14:0];
Aレジスタの値を addressM として出力します。
出力された addressM は他の outM, writeM と組み合わせてCPUの外で使用されます。
outM が値、addressMがメモリのアドレス、writeM がメモリのライトOnのフラグとなります。
つまり、addressM は必ず出力されますが、writeM がOffの場合は不定の値が出力されることになります。
⑥Mux16
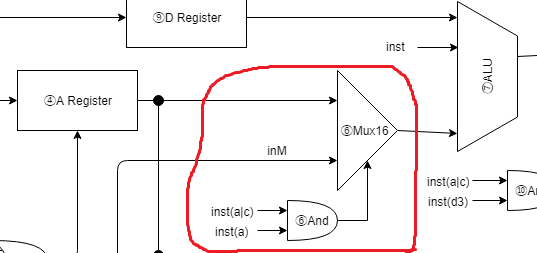
// ⑥ALUへの入力信号の準備
// C命令でcompのaがOnの場合、メモリ入力(inM)の値、
// それ以外はAレジスタの値をALUへの入力とする
wire isCompAon;
wire[15:0] AM;
_And andIsCompAon(.a(inst[15]), .b(inst[12]), .out(isCompAon));
Mux16 mux16AM(.a(aOut), .b(inM), .sel(isCompAon), .out(AM));
ALU入力の下準備です。
instの15ビット目と12ビット目でAndを取り、isCompAon に配線します。
instの15ビット目が On の場合は、instがC命令であることを示します。
instの15ビット目が On で、さらにinstの12ビット目も On の場合は、inM の値を計算で用いることを指示しています。
次にMux16にて、isCompAon をセレクタにしてAレジスタ値か inM値をALUに配線します。
⑦ALU
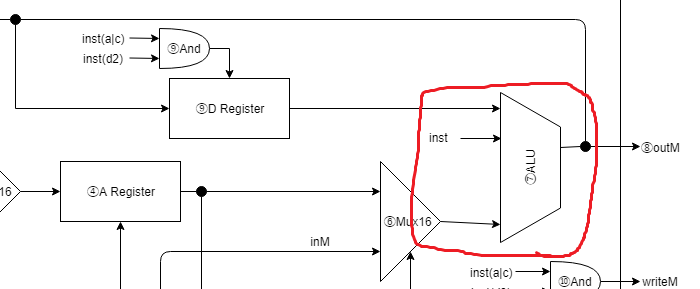
wire aluOutIsZero, aluOutIsNega;
wire[15:0] d_out;
ALU alu(
.x(d_out), // Dレジスタの値を入力する
.y(AM), // Aレジスタか、inMの値を入力する
.zx(inst[11]), // c1: 入力xをゼロにするか
.nx(inst[10]), // c2: 入力xを反転するか
.zy(inst[9]), // c3: 入力yをゼロにするか
.ny(inst[8]), // c4: 入力yを反転するか
.f(inst[7]), // c5: 関数コード(1は加算、0はAnd)
.no(inst[6]), // c6: 出力outを反転するか
.out(aluOut), // out
.zr(aluOutIsZero), // out==0 の時On
.ng(aluOutIsNega)); // out<0 の時On
ALUには x, y を計算対象の値として入力します。
x にはDレジスタの値、y にはAレジスタ、もしくは inMの値を入力します。
y への値は⑥で作ったAMを配線することで上記を実現しています。
それ以外の zx などの入力値は機械語からのinstructionをそのまま入力します。
⑧outM
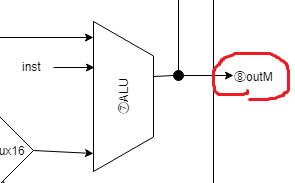
// ⑧ALUの出力は CPU出力の outM としても出力する
assign outM = aluOut;
見たままです。ALUの出力をCPUの出力 outM に配線しています。
先ほども似たことを書きましたが、outM は writeM がOffの場合は不定の値が出力されることになります。
⑨Dレジスタ
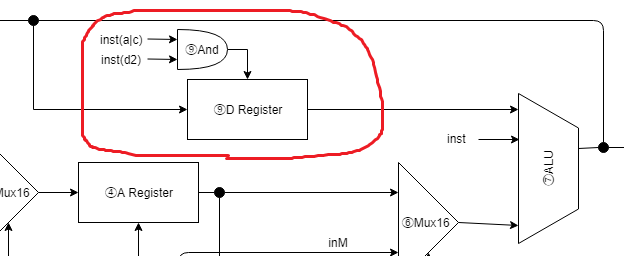
// C命令でdestのd2がOn(Dレジスタに計算結果を格納する命令)の場合は、
// ALUの出力をDレジスタにロードさせる
wire isDload;
_And andIsDload(.a(inst[15]), .b(inst[4]), .out(isDload));
Register dReg(.clk(clk), .in(aluOut), .load(isDload), .out(d_out));
DレジスタはALUの計算結果を保持します。
上記コードのコメントの通り、ALUの計算結果をDレジスタに格納する指令がC命令から来ている場合に、Dレジスタへロードさせています。
⑩And
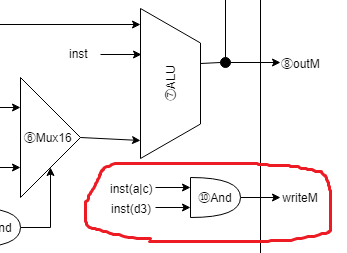
// ⑩C命令でdestのd3がOn(Memoryに計算結果を格納する命令)の場合は、
// CPU出力 writeM をOn(メモリ書き込みをOn)
_And andWriteM(.a(inst[15]), .b(inst[3]), .out(writeM));
これもコメントの通り、メモリへの書き込み指令がC命令から来ている場合は、CPU出力 writeM に1が出力されるようにしています。
⑪ジャンプの判定・GT( > )判定
// ⑪C命令でj3がOn(out > 0)が命令されているか?
wire isPositive, isNotZero;
_Not notIsPositive(.in(aluOutIsNega), .out(isPositive));
_Not notIsNotZero(.in(aluOutIsZero), .out(isNotZero));
wire instJgt, isGt;
_And andInstJgt(.a(inst[15]), .b(inst[0]), .out(instJgt));
_And andIsGt(.a(isPositive), .b(isNotZero), .out(isGt));
ALU出力の zr, ng(出力がゼロか?ゼロ以外か?)を参照して、ALU出力がゼロ超過か判定しています。
判定結果後続で利用されます。
⑫GTの結果でカウンタを書き換えるか?
// ⑫PCを書き換えるか判定する為の材料(GT)
wire isPcLoadJgt;
_And andIsPcLoadJgt(.a(instJgt), .b(isGt), .out(isPcLoadJgt));
GTが真の場合にプログラムカウンタを書き換えるか判定しています。
判定結果は後続で利用されます。
⑬⑭ジャンプの判定・EQ( == )判定
// ⑬C命令でj2がOn(out == 0)が命令されているか?
wire instJeq;
_And andInstJeq(.a(inst[15]), .b(inst[1]), .out(instJeq));
// ⑭PCを書き換えるか判定する為の材料(EQ)
wire isPcLoadJeq;
_And andIsPcLoadJeq(.a(instJeq), .b(aluOutIsZero), .out(isPcLoadJeq));
同様にイコール判定とカウンタ書き換え判定を行います。
⑮⑯ジャンプの判定・LT( < )判定
// ⑮C命令でj1がOn(out < 0)が命令されているか?
wire instJlt;
_And andInstJlt(.a(inst[15]), .b(inst[2]), .out(instJlt));
// ⑯PCを書き換えるか判定する為の材料(LT)
wire isPcLoadJlt;
_And andIsPcLoadJlt(.a(instJlt), .b(aluOutIsNega), .out(isPcLoadJlt));
Less Than も同様です。
⑰ジャンプの判定・GE( >= )判定
// ⑰PCを書き換えるか判定する為の材料(GE)
wire isPcLoadJGe;
_Or orIsPcLoadJGe(.a(isPcLoadJgt), .b(isPcLoadJeq), .out(isPcLoadJGe));
GTとイコール判定を利用してGE判定を行います。
⑰PCを書き換えるかの最終判定
// ⑱PCを書き換えるか
wire isPcLoad;
_Or orIsPcLoad(.a(isPcLoadJlt), .b(isPcLoadJGe), .out(isPcLoad));
ここまでのGT、EQ、LT、GEのいづれかが1の場合にプログラムカウンタを書き換える判定になります。
⑲プログラムカウンタ
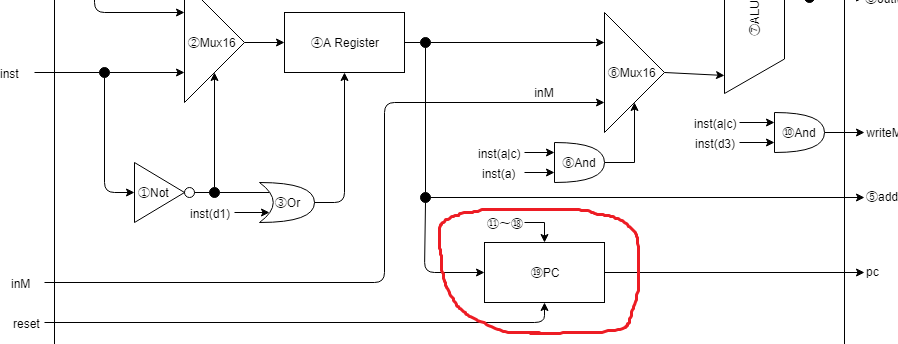
// ⑲プログラムカウンタ
wire[15:0] pcOut;
PC pc1(.clk(clk), .in(aOut), .load(isPcLoad), .inc(1'b1), .reset(reset), .out(pcOut));
assign pc[14:0] = pcOut[14:0];
⑪~⑱の判定が真だった場合、Aレジスタの値でカウンタを書き換えます。
偽の場合はカウントアップします。
プログラムカウンタからの出力は、pcとしてCPUから出力します。
CPUの説明は以上です。
単純なCPUですが、実際にCPUがどのような仕事をしているか基本部分が分かるので非常に有益と思います。
6. コンピュータシステム
CPUとRAMとROMを繋げてコンピュータをつくります。
ROMには機械語でカウントアッププログラムを仕込みます。
module Computer(
input wire clk, // clk
input wire reset, // reset
output wire[14:0] debug_pc, // デバッグ用・PC
output wire[15:0] debug_inst, // デバッグ用・inst
output wire[14:0] debug_addressM, // デバッグ用・addressM
output wire[15:0] debug_outM, // デバッグ用・outM
output wire debug_writeM // デバッグ用・writeM
);
reg[15:0] inst;
wire[15:0] outM, inM;
wire[14:0] pc;
wire[14:0] addressM;
wire writeM;
// プログラムカウンタが指す命令をROMから取得する
always @(posedge clk) begin
inst <= InstructionRom(pc);
end
CPU cpu(
.clk(clk),
.inM(inM),
.inst(inst),
.reset(reset),
.outM(outM),
.writeM(writeM),
.addressM(addressM),
.pc(pc));
RAM16K ram16k(
.clk(clk),
.in(outM),
.address(addressM),
.load(writeM),
.out(inM));
// 命令ROM
function [15:0] InstructionRom;
input [15:0] addr;
begin
case (addr)
// カウンタ
// Dレジスタを約31,250クロックに1回インクリメント
// インクリメントしたDレジスタの値はメモリへの出力値とする
0: InstructionRom = 16'b0_000_0000_0000_0000; // @0
1: InstructionRom = 16'b111_0_110000_010_000; // D=A :to _D_
2: InstructionRom = 16'b111_0_011111_011_000; // D+1 :to _DM
31250: InstructionRom = 16'b0_000_0000_0000_0010; // @2
31251: InstructionRom = 16'b111_0_101010_000_111; // 0;JMP
default : InstructionRom = 16'b0_000_0000_0000_0000; // NOP(@0)
endcase
end
endfunction
// for debug
assign debug_pc = pc;
assign debug_inst = inst;
assign debug_addressM = addressM;
assign debug_outM = outM;
assign debug_writeM = writeM;
endmodule
出力の debug_* はModelSimでデバッグする際の配線です。
ただし今回は、debug_outM と debug_writeM については、実際にDE0で動かす際にも使用します。
コード的には、clk の立ち上がり(alwaysの箇所)で、InstructionRomから機械語を読み込み、CPUのinstructionに繋げています。
RAMは置いていますが、今回は使っていません。
InstructionRom内の機械語は以下の感じです。
0: A命令 Aレジスタにゼロを入れる
1: C命令 Aレジスタの値(ゼロ)をDレジスタにコピーする
2: C命令 Dレジスタの値+1、outMに出力
3~31249: 処理なし(実際にはAレジスタにゼロ設定している)
31250: A命令 Aレジスタにアドレスである2を設定
31251: C命令 強制ジャンプ(Aレジスタに2が入っているので、2番地にジャンプ)
つまり、Dレジスタを永遠とインクリメントするプログラムです。
インクリメント結果はCPUのoutMに出力します。
DE0のクロックは50MHzなので、50,000,000 / 31,250 で、1秒間に約1,600回Dレジスタがインクリメントされるプログラムです。
DE0の7セグLEDは4つあって16進表示、桁上がりありで表示させるので、1,600 / 16 で1秒間に100回、2つ目のLEDがインクリされます。
3つ目のLEDは1秒間に約6.25回インクリ、4つ目は0.39回/秒インクリです。
7. DE0の7セグLEDでカウンタ表示を行う
今回のラストです。
module HardWare(
input clk,
input [2:0] btn,
input [9:0] sw,
output [9:0] led,
output [7:0] hled0,
output [7:0] hled1,
output [7:0] hled2,
output [7:0] hled3
);
wire[14:0] debug_pc, debug_addressM;
wire[15:0] debug_inst, debug_outM;
wire debug_writeM;
// コンピュータ本体
Computer computer(
.clk(clk),
.reset(0),
// 以下、デバッグ用の配線
.debug_pc(debug_pc),
.debug_inst(debug_inst),
.debug_addressM(debug_addressM),
.debug_outM(debug_outM),
.debug_writeM(debug_writeM)
);
// カウンタを動かすための実装
reg[15:0] count = 0;
always @(posedge clk) begin
// メモリ書き込みが 1 の場合に outM 値を count に保持
if (debug_writeM == 1'b1) begin
count <= debug_outM;
end
end
// DE0の7セグLEDへCPUからのoutMを出力する
HexSegDec hsd0(count[3:0], hled0);
HexSegDec hsd1(count[7:4], hled1);
HexSegDec hsd2(count[11:8], hled2);
HexSegDec hsd3(count[15:12], hled3);
assign led = 0;
endmodule
今回作成した回路とDE0を接続する為のトップモジュールです。
DE0から供給されるクロックを clk として受けます。
出力は hled0 ~ hled3 です。これらはDE0の7セグLEDに配線します(QuartusのPinPlanerで配線します)。
クロックの立ち上がりにて、Computer からの出力debug_writeM が 1 の時に、インクリ値である debug_outM を count に入れます。
count の数値を HexSegDec で7セグLED用にデコードして、hled0~hled3 に配線しています。
(HexSegDec はググると出てくるのでコード載せてません)
ここまでのHDLをQuartusで論理合成し、DE0に入れるとLEDカウンタが動きます。

次回
第2回はアセンブラ以降について記事を作成する予定です。
今回は第1回としてアドベントカレンダーで書きましたが、2回目以降は通常の記事で記載していきます。
(追記)その2-アセンブラはこちら
明日
そして、明日のアドベントカレンダーは@p3ngu1nさんでっす!
@p3ngu1nさんは秋のTech Connect Autumn!でいっぱいイイね!してくれた足長おじさん的な人です。