以前、下の記事で平成6年にその当時にあったPCとVisual Basicを使って機械学習で京都の衛星画像を解析したもとの、令和になってから同じ解析をPythonを使って行った比較をご紹介しました。
前回の記事では、2020年のデータをPythonで解析しました。今回はその当時使った1992年の衛星画像と同じデータを入手できましたので、Pythonを使って解析し30年ほど前に行ったVisual Basicで行った解析と比較してみます。
前回のおさらい
平成6年に研究で使ったデータは、以下の通りです。
- ランドサット5号: 1992年4月21日
- 分解能: 30m (30メートル以上のものを見分けることとができます。)
- 解析都市: 京都市近郊
- 解析範囲: 縦501、横325ピクセル(山崎ジャンクションから左京区北白川ぐらいの範囲を長方形で切り取ったぐらいです)
- 使用バンド: 1-7
- 解析に使用した言語: Visual Basic2.0
- 解析年: 1994年、平成6年
1992年のデータの取得
今回の解析のために同じ1992年のデータを次のサイトからダウンロードしました。解析範囲は前述の前回の解析と同じで、使用したバンドなども全く同じです。
平成6年に大学の研究室経由で取得したデータは、前回の記事でも書いているように若干反時計回りに傾いていましたが、今回取得したデータはそれが修正されていました。
Pythonで解析
前回使用したPythonのプログラムで解析をしていきます。コードは前回の記事と同じものを使用しています。
クラスター数10で解析
前回の記事では2020年のデータをクラスター数10と限って解析していたので、まずは同じ条件で解析をしてみました。
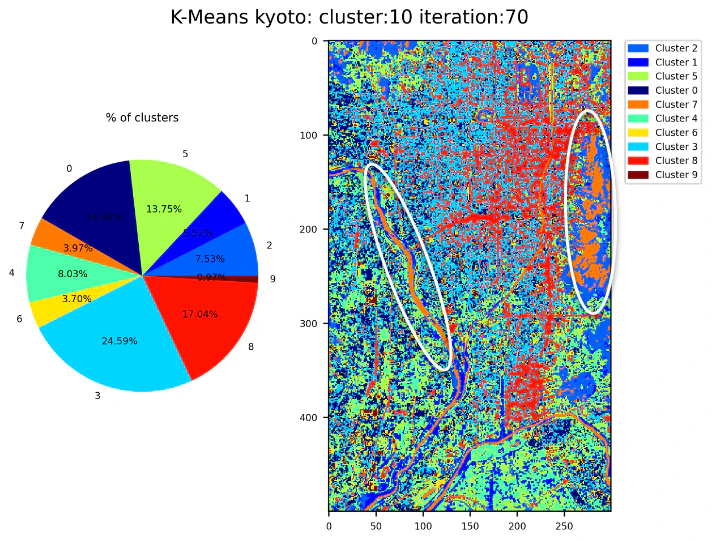
結果としては、上の画像で分かる様に桂川の水域部分と東山の森林部分の区別が出来ていませんでした。これではクラスター7の分類が明らかに不正確となるので、クラスター数を増やすためにエルボー法でクラスタ数を求めてみました。
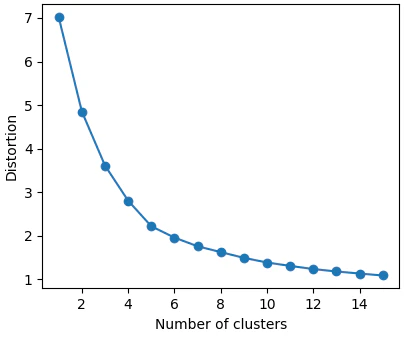
前回2020年のデータでも同じ結果でしたが、はっきりとどのあたりが一番良いかというのは今回使用したデータではわかりませんでした。結果的には水域と森林が区別できるクラスター数12までクラスター数を増やして解析をしました。
クラスター数12で1992年のデータを解析
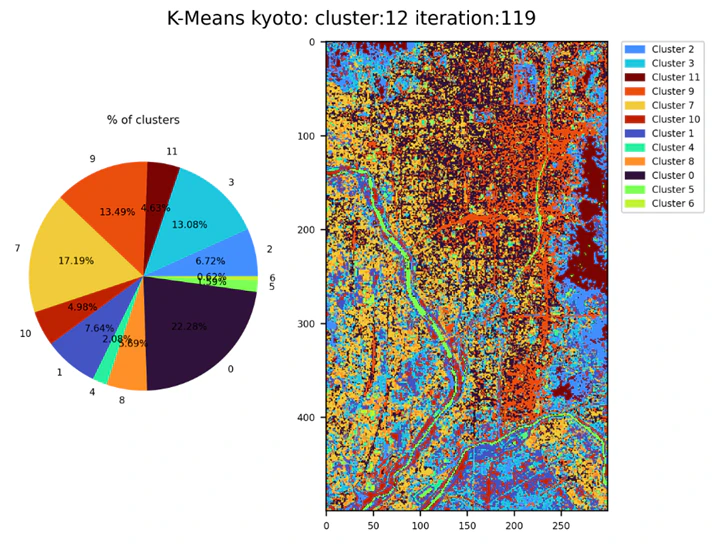
クラスター数10で解析した時と違い森林部分と川がはっきりと違いがみられました。
解析結果
| クラスタ番号 | 土地被覆分類 | 割合 |
|---|---|---|
| 0 | 市街地・住宅地 | 22.28% |
| 7 | 住宅地 | 17.19% |
| 9 | 市街地 | 13.49% |
| 3 | 水田 | 13.80% |
| 1 | 芝・緑地・水田 | 7.64% |
| 2 | 広葉樹林・果樹園 | 6.72% |
| 10 | 荒地・水辺 | 4.98% |
| 11 | 針葉樹林 | 4.63% |
| 8 | 住宅地 | 5.69% |
| 4 | 土・畑 | 2.08% |
| 5 | 水 | 1.59% |
| 6 | 工場 | 0.62% |
クラスター0,7,8の違い
同じ住宅地でも、いくつか別々のクラスターができました。クラスター0は市内中心部で、市街地と住宅地が混在しているところのようです。
| クラスタ番号 | 土地被覆分類 | 割合 |
|---|---|---|
| 0 | 市街地・住宅地 | 22.28% |
| 7 | 住宅地 | 17.19% |
| 8 | 住宅地 | 5.69% |
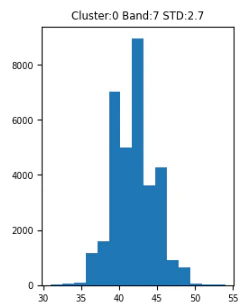
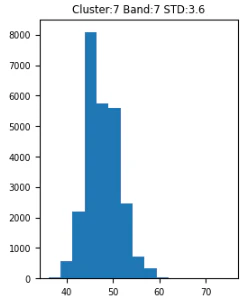
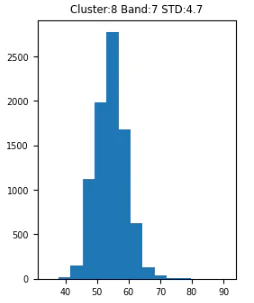
バンド7の各クラスターの分布を比較するとクラスター0は35-50に対して7,8は40-60,70で分布しています。バンド7は高層建築などを見分けるのにつかわれるバンドでその差が出たのかと思われます。
クラスター0は市内中心部に多く分布しており市外よりも高層部が多いのであろうと考えられます。
| 0 | 7 | 8 |
|---|---|---|
 |
 |
 |
Visual Basicで解析
前回の記事で紹介した、Visual Basicで解析した結果です。細かい考察は”Visual Basic2.0で機械学習”をご覧ください。
| 土地被覆分類 | 割合 |
|---|---|
| 住宅地 | 25.7% |
| 市街地 | 24.7% |
| 水田・畑 | 10.3% |
| 森林 | 9.8% |
| 水田 | 9.0% |
| 荒地 | 4.5% |
| 草地 | 2.5% |
| 水域 | 1.2% |
| 未分類 | 11.9% |
PythonとVisual Basicで解析した結果の比較
データは若干の傾きの違いもありますが同じなので、違いがあるとすれば機械学習の差であったり、プログラミングの違いだと思います。

- 一番の違いは前回同様やはり計算時間の差です。Visual Basicの解析では40時間以上かかったのがPythonの解析は1分で終了しています。計算回数も22回と119回と大きく違います。
- 市街地は、Pythonの場合、クラスター0を便宜上半分を市街地、残りを住宅地とするとクラスター9と合計で 22.28/2+13.49 = 24.63%、Visual Basicの場合は25.7%となりかなり近い割合で振り分けられています。
- 住宅地も同様に計算すると、クラスター8 5.69 + クラスター7 17.19 + クラスター0 22.28/2 = 34.02%、Visual Basicの場合は25.7%ですので9%近くの誤差が出ています。
- 水・水域はPythonで1.59%、Visual Basicで1.2%、荒地もPythonで4.98%、Visual Basicで4.5%とまずまずの結果です。
- 水田・畑、草地はPythonでクラスター3、水田13.80%、クラスター1、芝・緑地・水田7.64%、クラスター4、土・畑2.08%の合計で23.52%、Visual Basicで水田・畑10.3%、水田9.0%、草地2.5の合計で21.8%となりました。4月21日のデータなので水田はまだ田植え前で水張もおそらくされていない時期であり、畑と草地との区別は難しいようです。
- 森林部分はPythonでクラスター2、広葉樹林・果樹園6.72、クラスター11、針葉樹林4.63の合計11.35%、Visual Basicで9.8%となり、これもまずまずの結果になりました。
- Visual Basicでは未分類が11.9%ありましたが、今回は何とか全部のクラスターを分類できました。住宅地が9%近くの誤差が出ているのを考えると、未分類だったところは住宅地近辺であったのかもしれません。
巨椋池付近の開発
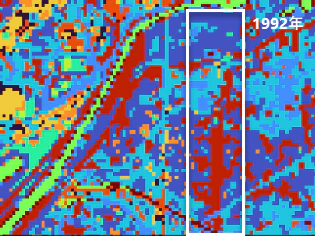
前回の記事でも触れましたが、1992年当時はまだ第二京阪が完成していなく巨椋池付近では市街地として認識されている箇所は少ないです。白線で囲まれた部分ですが、これはクラスター10の荒地として分類されています。
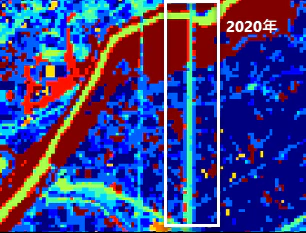
前回記事の2020年のデータで解析した同じ部分では、はっきりと市街地として分類されており他のクラスターともはっきりと区別されています。
これを「今昔マップ on the web」より作成した1988年までの地図と、1993年以降の地図と比較すると黒枠で囲まれたところが、1988年以前は水田扱いだったのに1993年以降は荒地に代わっています。このことから推察すると1992年の段階で開発がそれなりに進んでいたのだと考えられます。それが機械学習の分析でも荒地として分類されているようです。
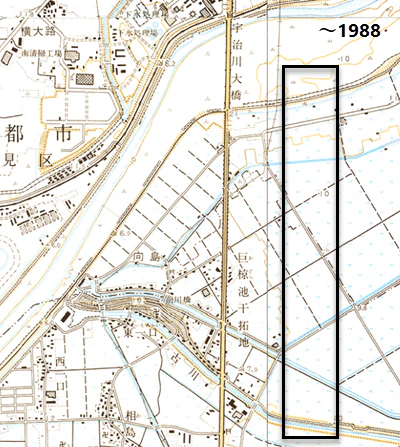
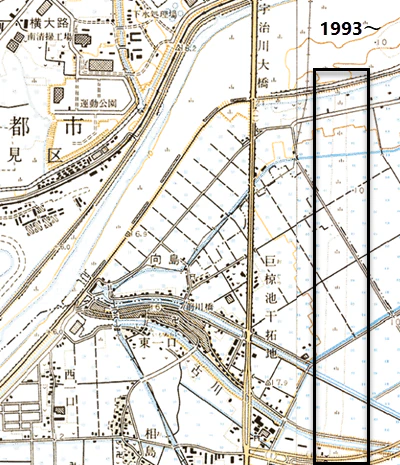
まとめ
- 同じデータを使っていてもやはり、技術が進んでいる分Pythonで解析した結果のほうが、より正確で分類などもかなり行いやすかったです。
- 1994年、平成6年にVisual Basicで行った解析では判っていなかった、巨椋池付近の第二京阪の開発の様子が今回の解析で判りました。
- 同じデータを使ってプログラムだけの違いで比較しているので、解析の差や機械学習の結果の差などもわかりやすく出たと思います。ただ、27年前に行った解析でもそれなりの結果が出ていたのは良かったと思っています。
- また前回では判別されなかった工場といったクラスターも判別することができました。
参考文献および注釈
- ランドサットデータについて (https://landbrowser.airc.aist.go.jp/landbrowser/index.html)
- “ The source data were downloaded from AIST’s LandBrowser, (https://landbrowser.airc.aist.go.jp/landbrowser/). Landsat 7/8 data courtesy of the U.S. Geological Survey.”
- 1992年のデータについて (https://earthexplorer.usgs.gov/)
- Landsat 5 data - courtesy of the U.S. Geological Survey
- Visit the USGS at https://usgs.gov.
- 「今昔マップ on the web」 https://ktgis.net/kjmapw/index.html