システム運用担当者
- システム運用の責任者でビジネス上重要なシステムを運用し組織に貢献する人。
- 実際は、何か障害があった時に夜中でも休みでも関係なく働く人たちです。
とは言っても、誰しも喜んで休日や夜中に障害対応をしたいと思っている人はいないと思います。そのためには、システムを監視(モニタリング)することが不可欠です。監視システムを取り入れることによって障害が発生した時にアラートを出して、例えば担当者に知らせるとか、サポートチームにメールを送るとかいろいろな方法があります。ですが、アラートを出して担当者に通知するだけでは、休日や夜中の対応が減るわけではありません。アラートの設定次第では、余分な確認作業が増えるだけになることもあります。
できれば、アラートが出た時に本当に対象のシステムに障害があるのか、今すぐ対応する必要があるのか、さらに言えば自動復旧することによってアラートそのものを出す必要もないようにすることはできないかなどを、すべて自動で行えるようにすれば障害対応に割かれる時間はかなり削減できます。
監視からアラート、セルフヒーリング(自動復旧)までJenkinsを使って行ってみたので、そのあたりをご紹介します。また、障害があってもダウンタイムをなくしデータロスを避けるためにはどうすればいいか考えたいと思います。
前提としては運用担当者の目線で、システム(OS、アプリケーション)外のハードウェア(サーバー、ネットワーク)などは、今回の話の対象外としておきます。
監視
システムのダウンタイムをなくす上で、運用上最も重要なのは監視システムです。運用上と書いたのは、本番環境にデプロイした後の話と限定するためで、もちろんデプロイする前のテストなどはさらに重要です。ここでは、運用担当の立場でどうやってダウンタイムを減らすかを考えていきたいと思います。
監視システムを採用しても、何を監視するか、どのような状況でアラートを出すかなど細かな考察・テスト・変更が必要で、最初に設定した内容で変更なくシステムの監視をできることはほぼないのではないでしょうか。
監視項目
ここでは従来のシステム、VMなどを監視る場合を考えます。先ず、何を監視する必要があるか。これはシステムによって様々ですが、OSレベルでは以下のような感じです。
- CPU、メモリーの使用状況。これは、最もわかりやすいところでどどちらもオーバーロードすると、大概のアプリケーションは何らかの問題を発生しだします。
- ストーレジ(ボリュームやシェア等)の使用状況、I/O、スペースの空き状況やInodesの使用状況など。ディスクのレイテンシなども、アプリケーションに重大な問題を起こす原因となるので、重要項目です。
- NICの使用状況。全体のネットワークは専門の担当部署が監視しているとしても、システムのNIC自体の監視はシステム運用者の責任です。ストーレジ同様ネットワークのレイテンシ、パケットの再送信などかなり地味なところですが、NIC周りの問題は重大な障害を及ぼす可能性があります。その割にトラブルシューティングをしているときにCPUやメモリーはまず最初に目をつけやすいところですが、なかなかパケット送信状況などをチェックするところまでたどり着くには時間のかかる時があります。
アプリケーションの監視となると、アプリケーションの目的や重要度、使用してるテクノロジー、開発言語などによって全く異なるので一概には言えませんがこのような感じです。
- 監視用URLの作成。わかりやすいところで、監視用のURL(監視専用のURLでもいいですし、監視専用のページなんかでもいいと思います)を作成してそれに定期的にアクセスして、レスポンスタイムなどを図ることができます。重要なのはこの監視用のページが何を行うかで、ある程度ユーザが本来アクセスするページと同じアプリケーションの動作を行うと、それによってシステムの状況を知ることができます。
- 例えば、データベースと連動している場合は、監視用のページもデータベースにアクセスしてダミーデータを取り出すように設定します。これによって、データベースやデータベースへの接続に問題があると、監視用のページでもエラーが出たりレスポンスが悪くなったりします。監視用のページだけで何が問題なのかはわかりませんが、システムに問題があってアラートを出すことはできます。
- 関連システムの監視。どのようなシステムでも、ApacheなどのWebシステムだけで静的なコンテンツだけを発信していることはあまりないと思います。多くの場合、データベース、別のマイクロサービス、基幹システムなど何らかの関連システムと連動して運用されていることと思います。それらのシステムの監視はその運用担当者責任の範囲で行われますが、自分のシステムと関連システムの連携、例えばマイクロサービスへの接続状況、APIのレスポンスなど自分のシステムに重大な障害を及ぼす可能性のある項目はある程度監視を行っていた方が、問題解決への道のりも短くなります。
- データベースを運用している場合は、トランザクションの数やスピード、ボトルネックになっているSQLステートメントなどを監視することで、データベースの状況を把握することができます。
クラウド
クラウド上でシステムを運用すると、以前のようにハードウェアを購入する必要がないのでサイジングや監視も以前のように突き詰める必要がないのではと考えています。足らなくなったCPUやメモリー、ディスクは追加すればいいので以前よりも対処は楽になりました。
クラウド以前は、そう簡単にそれらのリソースを追加できないので、監視を細かく行って問題発生前に、問題が起こりそうなところを洗い出しアプリケーションの改善や、ハードウェアの追加を行う必要がありました。
クラウド上で運用すると、それら必要なリソースはいつでも追加できますし、また使用後は削除できます。
完璧な監視を行うために多くの時間や人的リソースを費やすより、その時間を問題が発生した時に自動的に復旧できるシステムを構築する方に費やせば、ある意味合理的にシステムの運用ができます。
確かにリソースの無駄が出る可能性もありますが、全体的にみると結果的に運用効率は上がると思われます。
これは運用担当者のストレスをかなり軽減できるはずです。以前は、CPUやメモリーの問題が発生すると何とか復旧するまでトラブルシューティングを行わなければいけませんでしたが、クラウドだととりあえずCPUやメモリーを追加してその場をしのぐこともできます。
Kubernetes監視
Kubernetesは複数のノード上で複数のワークロードを運用するので、ノードそれぞれの状態とクラスター全体を監視する必要があります。基本的には従来のシステムと同様の監視が必要ですが、それ以外にKubernetesに特化した監視も必要です。
- CPU、メモリーの使用状況。従来のシステム同様、Kubernetesでも基本的なリソースの監視は必要です。ノードごとの使用状況も重要ですが、クラスター全体でどれくらいCPUやメモリーが使用されているかを監視し十分な余裕を持った状態にしておかないと、オートスケーリングなどを行えなくなります。
- PodのCPU、メモリー使用状況。PodごとにRequestとLimitで管理されている場合でも、Podごとに実際どれくらいCPUやメモリーを使用しているか、ピーク時の使用状況などを把握しておくとクラスター全体のリソースを計画するときに有効です。
- CPU、メモリーを多く必要とするPodがどれくらいあって、クラスター全体にどのような影響を与えるか。ノードのプールを決める際に、どのようなPodをどのプールを指定して運用するかなど決める必要があります。
- Podの状態。Podが正常に起動しているか、起動に失敗しているかなど提供するサービスに直結する問題を発生させかねません。
監視ツール
監視ツールにはいろいろあります。それぞれ良しあしがあるので、どれが良いと言うのは運用しているシステム、他のシステムとの兼ね合いなどいろいろと考慮する必要があります。とはいえ監視ツールは、システムの安定運用するためには最重要なツールで最低限これくらいの要件は満たしてほしいというものがあります。
- 高可用性システムで安定していること。監視ツールがダウンすると、それで監視をしているシステムすべてにリスクが伴います。監視ツールとしては絶対条件です。
- 導入が簡単である。ここでいう導入は、対象システムの監視を始めるのが簡単に行えるという意味です。監視ツール自体の構築は他のシステム同様、ある程度の工程を必要とされますが、対象システムを監視対象とするのは簡潔な方法で行える必要があります。特にクラウドでシステムを運用すると、サーバの入れ替えなど頻繁に行うので、そのたびに監視ツール用のエージェントなどをインストールする必要があり、それはできるだけ簡潔に行える必要があります。
- 導入の自動化をできる。先ほど同様、クラウドで運用などする場合エージェントの実装や、監視ツールとの統合などはすべて自動化できる必要があります。
自分が担当しているプロジェクトではDynatraceという監視ツールを使用しています。上にあげた監視項目は殆ど、特別な設定もなく監視対象とされていて、非常に使いやすいツールだと感じております。Kubernetesの監視には若干の設定や、いくつかKubernetes上で実装が必要なこともありますが、それも複雑でなくすぐにできるものです。こちらの記事でその例を紹介されているようですので、ご参考にしてください。
トラブルシューティング
システムのトラブルシューティングは多岐にわたり、使われているテクノロジー、言語などによって全くアプローチの仕方が異なったりするので、一概にこれと言った方法があるわけではありません。それぞれのシステムの特性に合わせて経験則を元に最適の方法を見つけ出していかなければなりません。
ですが、基本的な初歩段階のことは大体以下のような感じでしょうか。
- エラーメッセージの分析。システムで問題が発生すると、大抵の場合は何かエラーメッセージが出るはずです。例外も当然あり得ますが、まずはこのエラーメッセージを良く分析して、何が問題かを把握する必要があります。大規模な障害でない場合、エラーメッセージだけでRCA(根本原因分析)までたどりこともできます。
- 問題の切り分け。大規模障害になってくると、エラーメッセージが色々なところから出てきます。例えば、データベースがオーバーロード気味でレスポンスが悪くなった場合、それを呼び込むアプリケーションではタイムアウトなどのエクセプションのエラーが出るでしょうし、ユーザーがアクセスするページでは404、50*系のエラーが出たりします。また、オバーロード気味でダウンしているわけではないので、リクエストが成功している場合もあります。この場合、何種類かのエラーが同時に発生してどれがRCAにつながるエラーで、どれがエラーによって引き起こされた副作用的なエラーか見分ける必要があります。この問題の切り分けができないと、RCAをできずに根本的な問題解決にはつながりません。
- 問題の再現。地味な作業ですが、本当の根本的解決にたどり着くには問題を再現できる必要があります。それを行うためにも、普段からテスト・QA環境を整備している必要があります。本番環境へのデプロイの前にテストを行うQA環境(ここでは仮にQA環境とします)は、できるだけ本番環境と同じでないといけません。100%というの無理ですが、近ければ近いほど何か問題が発生した時にQA環境を使って問題の再現、トラブルシューティング、解決方法のテストを行うことができます。データベースがオーバーロード気味の場合、QA環境でどうやったらデータベースをオバーロード気味に再現できるかなど、本番環境ではできないテストも行えます。QA環境で問題の再現ができない場合、本番環境との環境の違いが原因として考えられたりするので(例えば本番環境とQA環境では違うネットワークを使っている)、再現ができなくても切り分けはできるかもしれません。
- 問題の切り分けや再現をするには、そのシステムの運用経験とシステムの弱点などを把握しておく必要があります。どのシステムでもどこか弱点のようなものはあります。特に運用開始初期段階では、弱点だらけのことも大いにあり得ます。先ほどの例で行くと、データベースに負荷のかかりやすいシステム構造だということを理解していると、エラー発生時に内容に関係なく、まずデータベースの状態を確認するというのも一つの方法として考えられます。
問題の再現や切り分けが難しい例
以前あった障害でたとえですが、RCAに至るまで紆余曲折しそうな問題です。
まず結果から言うと、原因はネットワークの状態があまり良くなかった、たとえばルーターやスイッチ等で障害があってパケットの再送が時々にあるような状態ですが完全にダウンしているわけではありません。この場合、起こりそうなエラーとしてはわかりやすところから
- アプリケーションのエラー。トランザクションの失敗やタイムアウト、さらにエクセプションなどが出やすくなります。この段階では、アプリケーションのエラーだけが出てきたりするのでその分析から始めたりします。エラーを分析して何が原因か、アプリケーションにバグはないかなど探ったりします。開発担当者にエラーを見て分析してもらうことも必要です。
- 次に目につきやすそうなのが、CPUやメモリーの使用状況が悪くなること。アプリケーション側でこのような状況の場合どう対処するか考えられていて、適度な待ち時間の後にタイムアウトでエラーを出せばまだいいですが、中には全くタイムアウトを設定していないコードもあります。その場合、最悪の場合はスレッド数がどんどん上昇してメモリーを使いきったりします。
- 例えばJavaの場合はガベージ・コレクション(GC)が動いて余計なものを掃除してくれたりしますが、タイムアウトがちゃんと設定されてないアプリケーションだとスレッドがアクティブのままになったりしてGCでは掃除しきれなくなりだします。GCの数も増えてCPUの使用量も増えていきます。
- ここまでくると最終的にはOut Of Memoryなんかでアプリケーション自体がダウンしたりします。
原因がわからない状態で、この一連の障害が発生すると、なかなかネットワークが原因と断定するのは難しい状況です。先ず、アプリケーションでタイムアウトを設定できてないので、本来出るはずのタイムアウトエラーがそれほど見られないこと。また、ネットワークは不安定なだけでダウンしているわけではないので、問題を再現するためにテストした時には成功する可能性があること。初期段階のエラーを見つければまだいいですが、OOMを出すようになってからでは多くのエラーが出ているので、その中で副作用的なエラーを排除しなくてはいけないこと。
さらに、ネットワークを疑いだしてもTCPダンプを取ってパケットの分析などをするか、パケットの再送を監視できる監視システムを導入している必要があったりします。
パケットの再送が普段より上昇していることに気付けば、おそらくネットワーク側に問題があってアプリケーションもしくはシステム自体の障害ではないというとこまでたどり着けるのではないでしょうか。
自動復旧
すべてのシステムに使えるわけではありませんが、あまり構造が複雑でないシステムの場合は監視システムを利用して自動復旧を構築することもできます。Kubernetesの場合はPodなど基本的に自動復旧ができるように設計されているので、ここではKubernetes外のことを書いていきたい思います。
あまり複雑でないシステムの場合、サービスの内容にもよりますが何かアプリケーションで障害があった場合、アプリケーションの再起動をすれば単純に解決することも多くあります。本番環境の場合サービスのダウンタイムは避けなければならないので、原因究明よりもサービスの復旧が優先度は上に来るべきです。
このような場合、監視システムで障害時のアクションを、例えばWeb Hookを通してJenkinsのパイプラインを起動するように設定しておきます。
Jenkins側ではGeneric Webhook Triggerプラグインを使います。
Jenkinsのパイプライン側では、Tokenなどを以下のように設定します。監視システムからはTokenのほかにパイプラインに渡したい情報を変数で送ることもできます。
triggers {
GenericTrigger(
genericVariables: [
[key: 'State', value: '$.State'], //<- 監視システムからPostされる変数です
[key: 'Impact', value: '$.Impact'] //<- 監視システムからPostされる変数です
],
causeString: 'Cause: $Impact',
token: 'abcdef-1234-5678-9abc-000000000',
printContributedVariables: true,
printPostContent: true,
silentResponse: true
)
}
監視システムからは
https://jenkins_url.name.company/generic-webhook-trigger/invokeに必要な情報とTokenをAuthorization: Bearer TOKEN_HEREとして渡せば監視システムからJenkinsのパイプラインを起動できます。
先ほど例に挙げたDynatraceだと、英語ですが以下の記事を参考にすればDynatraceからJenkinsのパイプラインを起動することもできます。
パイプラインではサービスの復旧に最も重要なアプリケーションにできるだけ絞って、状態を確認し必要であれば再起動などを行うようにパイプラインを作ります。システムは冗長化されているはずなので、複数のサーバーなどの状態を同時に確認する必要があります。その場合、以前ご紹介したRundeckを使うと一気に複数のサーバーに同じプログラムを実行できるので非常に便利です。
これによって、それぞれのサーバーでアプリケーションが正常に起動しているか、もししていない場合は再起動をし正常に起動したことを確認するようにRundeckのJobなどを作ることもできます。
Rundeckを使うと基本的に対象システムで任意のスクリプトを実行することができます。ここでは、自動復旧のためにアプリケーションの再起動をしていますが、それができないようなシステムでも自動でスクリプトを実行しデバッグログを取ったりもできます。そのほか普段問題があった時に行う作業をできるだけスクリプトで実行できるようにすると原因究明が早く行えます。
JenkinsからはSlackに通知もできたりするので、パイプラインの開始時と終了時、自動復旧が成功したかどうかなどを通知してやると運用担当者は自動復旧が失敗した時だけ、本当に調査を始める必要があり自動復旧が成功した時は休日や夜中にまでわざわざ確認を必要はなくなります。これだけでも少しは残業を減らしたり睡眠時間の確保になるのではないでしょうか。
例えばシステムの再起動が失敗した場合や、再起動しても正常に動いていないときなどパイプラインのステージを失敗として、以下のようにSlackに通知できます。
post {
unsuccessful {
slackSend channel: '#jenkins_notifications',
color: 'danger',
message: "ERROR:<${env.BUILD_URL}|${currentBuild.fullDisplayName}> : ${currentBuild.currentResult}"
}
}
監視と復旧の優先度
監視ツールを導入すると今まで知らなかったような多くの問題に気づきます。だからと言ってすべての障害、エラーを分析、修復する必要があるかと言うとそういうわけでもありません。特にクラウドの場合は、サーバの再構築など簡単に行えますので、一過性の可能性のある問題に多くの時間を割くより、再構築して復旧する方が効率が良いこともあります。
また、アプリケーションも再起動で解決できることもあります。再起動で復旧できる場合は、そちらの方が時間的に効率の良い場合も多くあります。
問題の重要性を見極め、再発するような障害は時間をかけてでも原因究明を行う必要がありますが、そうでない場合はすべての障害に時間を割くといくら人と時間があっても足りません。
監視項目や詳細などや、監視ツールの設定の完成度やアラートが出た時にどのように対応するかなどは以下のことを考慮する必要があります。
- システムが提供するサービスの重要性、優先順位。
- 扱っているデータの重要性。
- 高可用性システムであるかどうか。例えば高可用性システムの場合クラスターのうちの1つのサーバーがダウンしていても、サービス自身は正常に動いている場合、複数の障害がある時はこのサーバーの復旧や原因究明は最重要課題ではなくなるかもしれません。
ダウンタイム
運用担当者として最も重要なゴールの一つがダウンタイムをなくすことです。システムにもよりますが、ダウンタイムはシステムや会社の信用を下げ、直接業績に影響を及ぼしかねません。例えば、監視ツールを販売している会社のサイトがダウンしていたら、自社のサイトも監視できないその監視ツールを導入するのは躊躇すると思います。
できれば計画的なメンテナンスも含めてダウンタイムはできるだけなくしたいものです。
そのためには高可用性システムであることは最低条件です。本番システムへのデプロイメントも、高可用性システムであることを利用して、複数のノードの中から一部をサービスからオフラインにしてデプロイし、またサービスに戻すといったことを自動的に行えるようなパイプラインを作る必要があります。いわゆるブルーグリーンデプロイメントのようなことをして、全く同じセットのサーバーを2つ以上用意し仮本番のシステムにデプロイメントをすべて行い、終了したらエンドポイントを切り替えるといったやり方もあります。
計画的なメンテナンスも同様の方法で行うことによって、ダウンタイムを限りなくなくす方向で計画できるはずです。
DR対策とデータロス
ダウンタイムも運用担当者としては避けたいですが、それは復旧すれば業績への影響などはありますがサービスがしばらく使えなかったぐらいで済むかもしれません。ところが大規模な災害が発生した場合DR(ディザスタリカバリ)対策をしていないと、本当に最悪の状況になり復旧ができなくなるかもしれません。
こちらのニュースを目にした方も多いと思います。クラウドを使っていても1つのリジョンだけで運用すると、このような災害が起こると長時間のダウンタイムのうえに、データを失う可能性があります。実際こちらのニュースでもデータのリカバリーができないこともあると書いてあります。
これを避けるためには、バックアップを物理的に異なる場所で保管することやDR対策として2か所以上のリジョンで運用することなどが必要です。以前書いた記事でCDNとGTMを利用して2か国のリジョンで運用する方法を書いてみました。
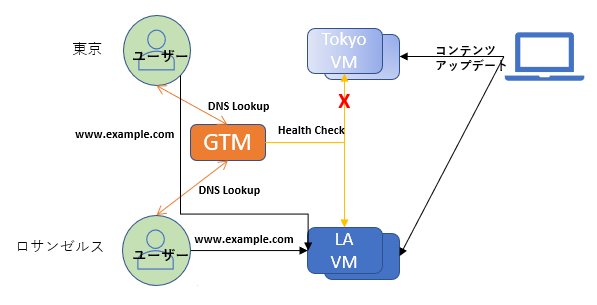
この記事ではバックアップのことは触れていませんが、東京のリジョンで重大な災害が発生した場合、自動的にエンドポイントを別のリジョンに切り替えることによってサービスを引き続き提供することができます。例では、2か国で行っていますが、国内で東京と大阪と利用するだけでも十分です。また、バックアップも2か所でとっておけば、災害時でもデータロスをなくす、もしくは極力少なくできます。
DR対策は予算が必要です。2つのリジョンで運用するには単純に倍の予算が必要で、これを必要経費ととらえるかどうかは経営判断によるかと思います。会社にとって重要なシステムを任されたときは、少なくてもDR対策を提案した上で、会社としてどれほど予算を割くべきシステムかを検討する必要があります。
最後に
システムをダウンタイムやデータロスなく、24時間365日途切れずに運用するためには、監視、アラート、自動復旧から高可用性システムやDR対策まで幅広く多くの状況に対応できる体制が必要です。
当然これをすべて行うには人的なリソースも必要ですが、予算も継続的に確保する必要があります。監視項目にしてもどこまで細かく監視するか、またDR対策などすべては対象システムの重要性、予算などによります。
会社にとって重要なシステムなのに、予算もつけずにサービスを保証するのは不可能ですし、予算があってもDR対策をしていないと、もしもの時に重大な問題となり得ます。
色々とシステム運用担当者の方の負担ができるだけ削減できる方法を書いてみました。
何か参考になれば幸いです。