【新人教育資料】時系列予測をprophet(Python)でやってみる第1章 〜インストールから簡単な予測編〜
あらすじ
最近は日本にいなかったり、インタビューや講演ばっかり受けてて、Qiitaサボリ気味でしたが、少しずつ再開しようと思ってます。
社内の技術イベントでLTしたものをかいつまんで記事をアップしたいと思います。
細かい事は特に気にせず、非エンジニアでもサクッと出来るレベルなので、やってみてください。
※後々、リクエストに応じて更新することが多いのでストックしておくことをおすすめします。
自分は某社でCTOをしていますが、頭でっかちに理論ばっかり学習するよりは、イメージがなんとなく掴めるように学習し、実践の中で知識を深めていく方が効率的に学習出来ると考えています。
未経験者の教育についてインタビューされた記事もあるので紹介しておきます。ご興味ある方は御覧ください。
エンジニアは「即戦力」より理念に共感した「未経験者」を育てるほうが費用対効果が高い。
教育スタイルとしては正しい事をきっちりかっちり教えるのではなく、未経験レベルの人がなんとなく掴めるように、資料を構成していきます。
以下のようなシリーズネタで進めます。
| No. | 記事 |
|---|---|
| 1 | 【新人教育資料】時系列予測をprophet(Python)でやってみる第1章 〜インストールから簡単な予測編〜 |
| 2 | 【新人教育資料】時系列予測をprophet(Python)でやってみる第2章 〜お天気編〜 |
| 3 | 【新人教育資料】時系列予測をprophet(Python)でやってみる第3章 〜実際にありそうなデータ編〜 |
では、今回もはじめていきましょう!
はじめに
今回は素直にprophetで用意しくれているCSVを読み込み、時系列予測をしてみます。
pandasとは
データ解析系の機能を提供するライブラリ。 特に、数表および時系列データを操作するためのデータ構造と演算を提供する。
一回使うと便利で病みつきです。
numpyとは
数値計算を効率的に行うためのライブラリ。行列計算やベクトルを扱う場合には必須といえる。
matolotlibとは
科学計算用グラフ描画ライブラリ。こいつのおかげで視覚的にすぐ確認が出来る。
fbprophet
Facebookが提供している時系列予測を簡単に出来るライブラリ。
2017.02.23に登場してから地味にアップデートして実用レベルにきている。
時系列予測をprophet(Python)でやってみよう
能書きもほどほどにやってみましょう。
事前準備
Python自体のインストールからデータ解析する時に必要なライブラリをインストールしましょう。
pyenvインストール
Pythonのバージョン等を使い分けたりする事が多いので
pyenvを使ってPythonの複数バージョンが同居出来るようにしましょう。
既にインストールしている方はスキップしてください。
$ mkdir {対象フォルダ}
$ cd {対象フォルダ}
$ git clone git://github.com/yyuu/pyenv.git ~/.pyenv
$ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile
$ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile
$ echo 'eval "$(pyenv init -)"' >> ~/.bash_profile
$ source ~/.bash_profile
※{対象フォルダ}は今回の作業をするフォルダを新規で作成しています。必要なければお好きなところでどうぞ。
pythonのインストール
pyenvを使ってPythonの3.5.xをインストールします。
$ pyenv install 3.5.2
$ pyenv rehash
$ pyenv shell 3.5.2
$ python —version
Python 3.5.2
$ pip -V
pip 9.0.1
pipでライブラリインストール
pipを利用し必要なライブラリをインストールします。
$ pip install pandas
$ pip install numpy
$ pip install fbprophet
$ pip install matplotlib
$ pip list | egrep "pandas|numpy|fbprophet|matplotlib"
fbprophet (0.2)
matplotlib (2.0.2)
numpy (1.13.1)
pandas (0.20.3)
描画テスト
pythonで描画で出来るか対話式でテストしてみましょう。
ターミナルで「python」と入力すると「>>>」と続けて表示されます。
$ python
pythonで対話モードに入ったら以下の内容を
入力し、別ウィンドウでグラフが表示されることを確認しましょう。
from numpy import *
import pylab as plt
x = linspace(-5, 5, 50)
y = x
plt.plot(x,y)
plt.show()
以下の画像のようになれば成功です。
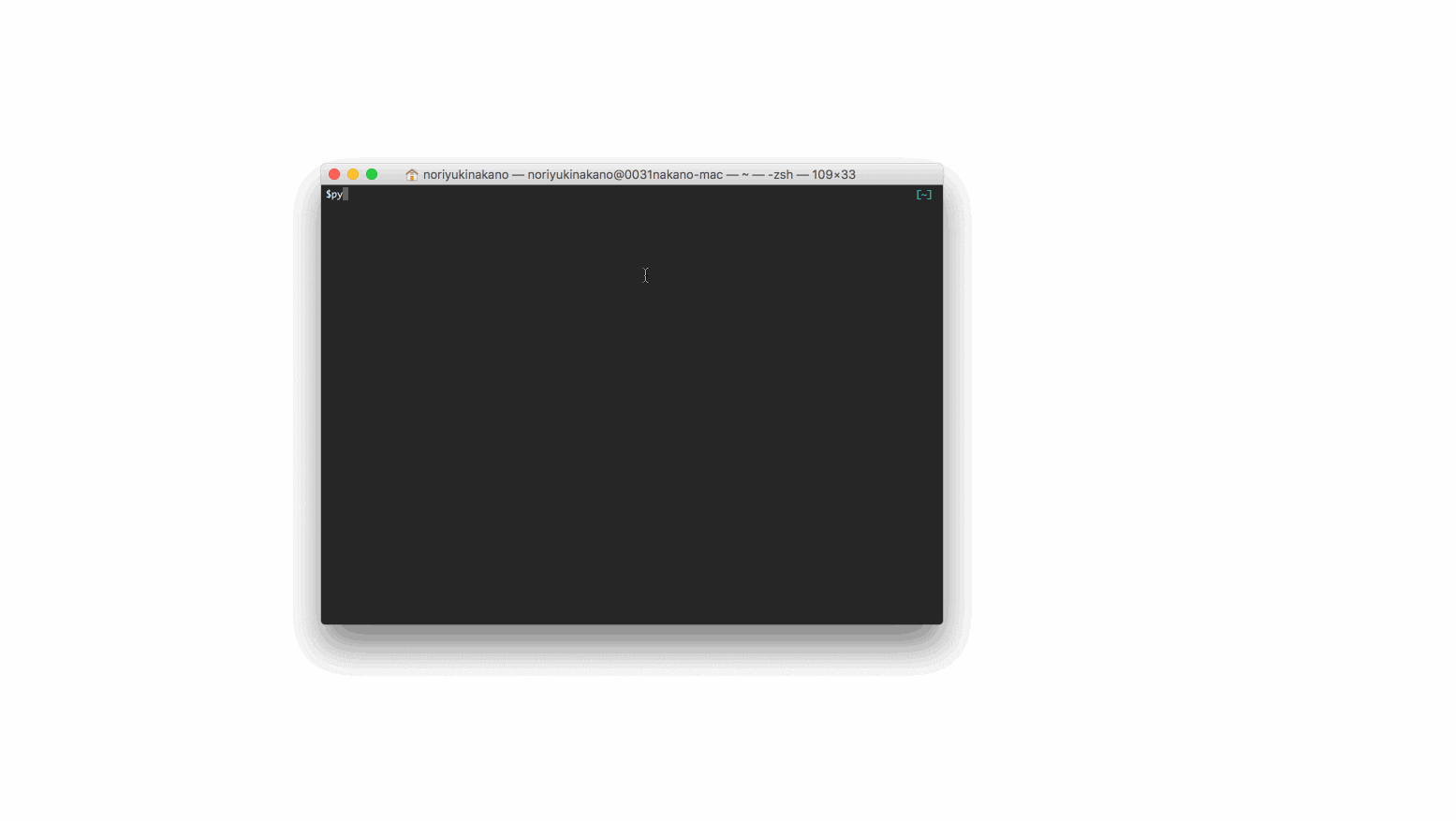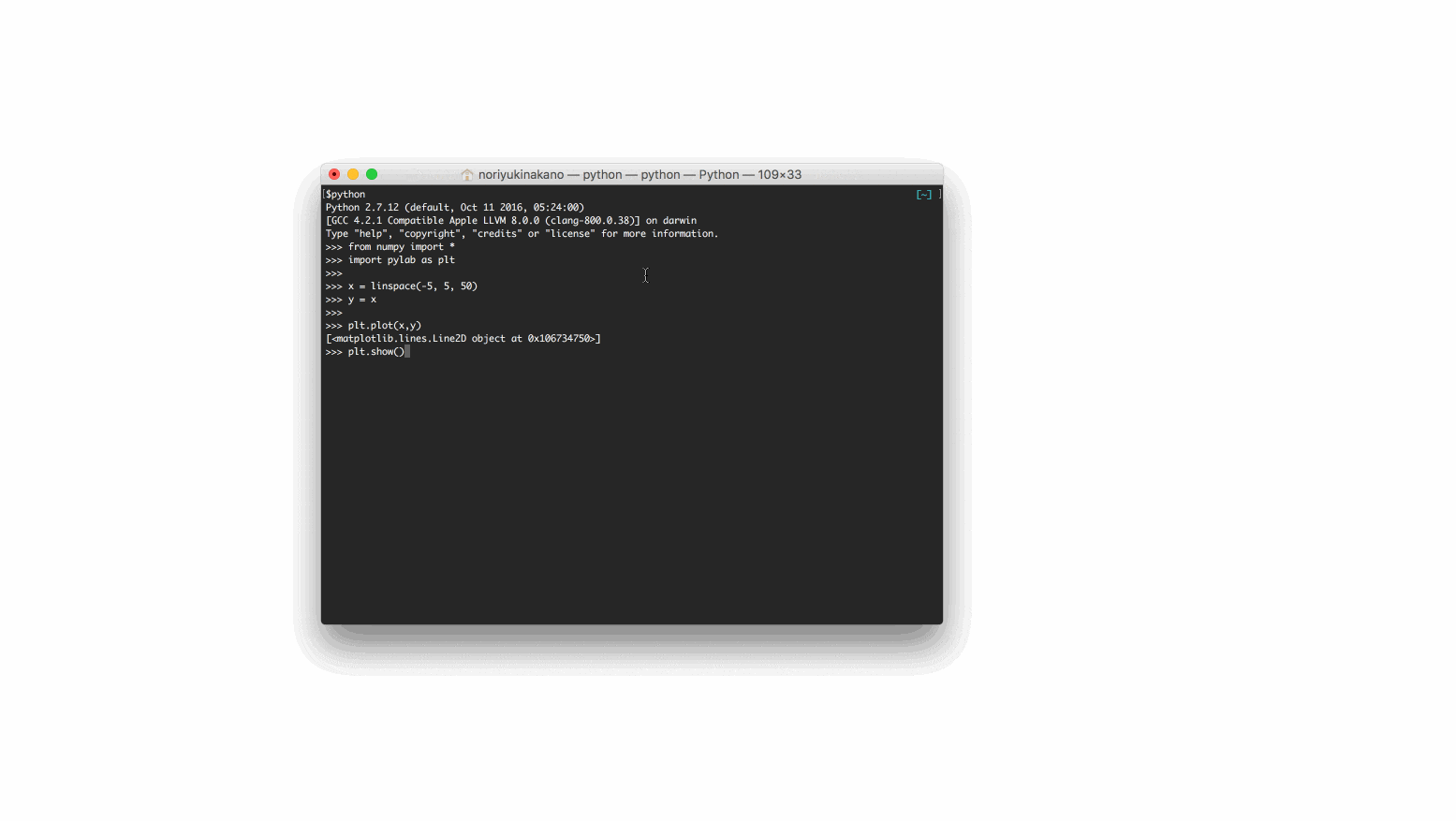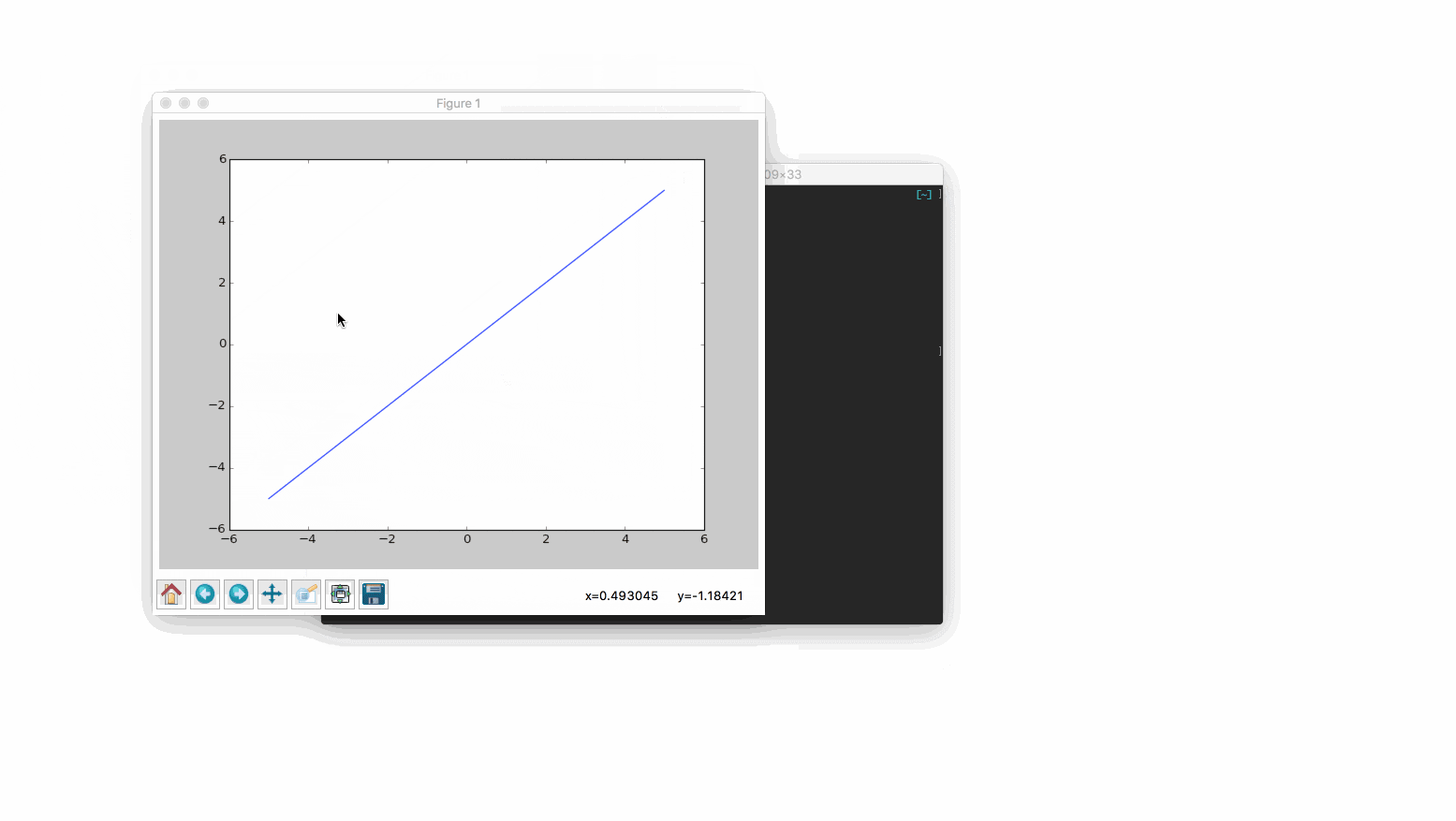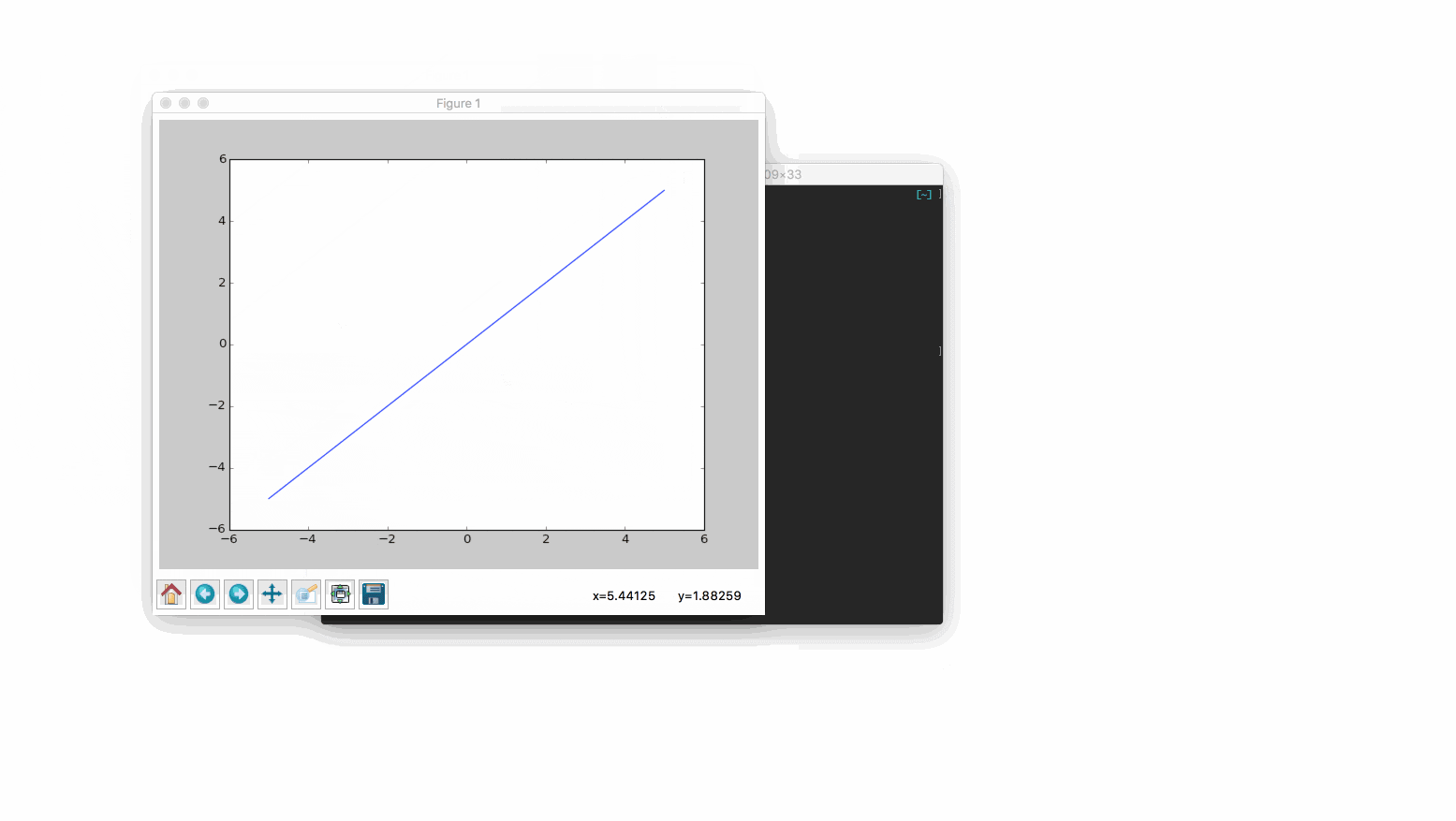
Prophetを対話式pythonで動作させる
サンプルCSVのダウンロード
$ cd {対象ディレクトリ}
$ wget https://raw.githubusercontent.com/facebook/prophet/master/examples/example_retail_sales.csv
$ ls
example_retail_sales.csv
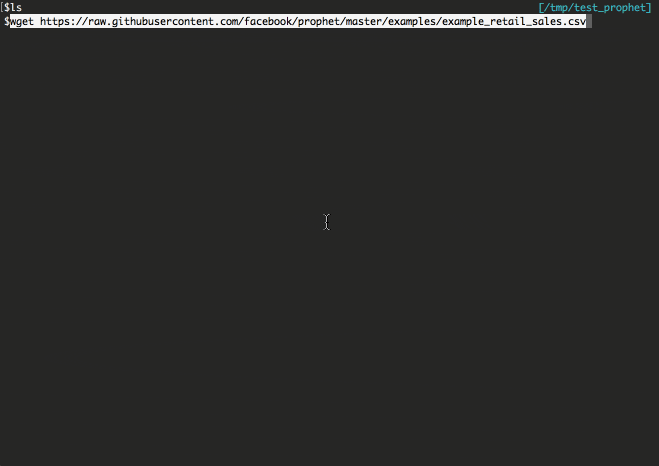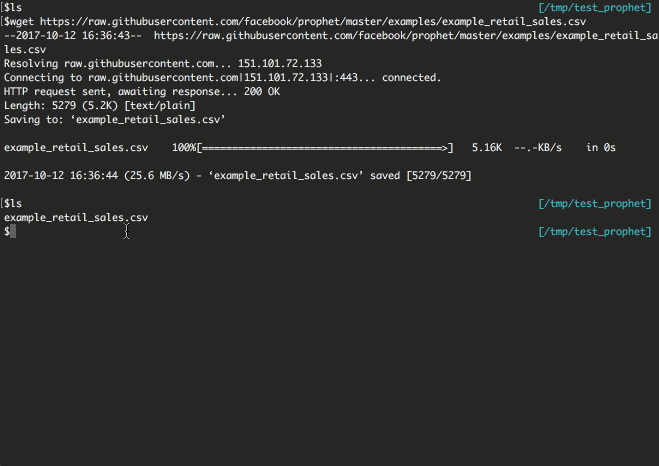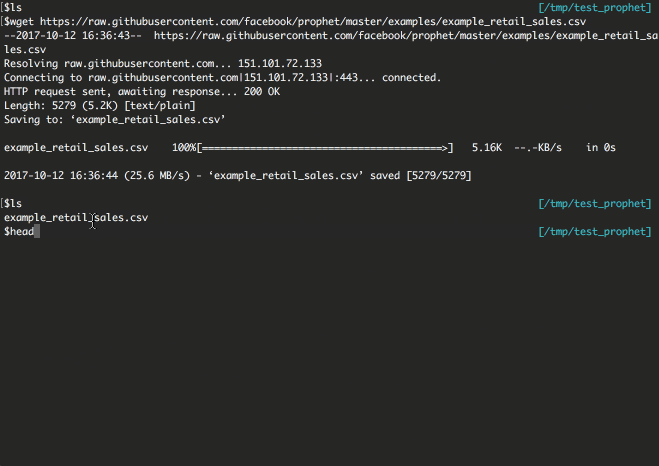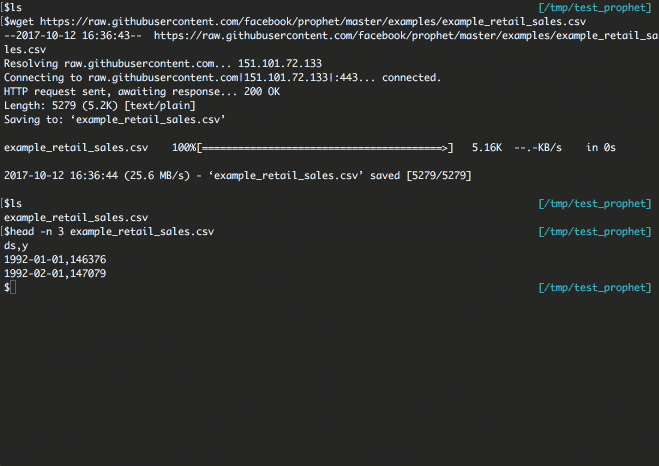
$ head -n 3 example_retail_sales.csv
ds,y
1992-01-01,146376
1992-02-01,147079
以下のように出力されればOKです。
実際に動かす
対話モード
$ python
>>>
対話モードに入ったら以下のコマンドを入力していきましょう。
pandasでCSVファイル読み込み
import pandas as pd
import numpy as np
from fbprophet import Prophet
import matplotlib.pyplot as plt
df1 = pd.read_csv('example_retail_sales.csv')
df1.info()

これで
csvを読み込み、pandasのデータフレームとして扱えるようになりました。
「df1.info()」でデータフレームの情報が確認できましたね。
今回のデータは293件あり、dataカラムとして2カラム存在することが確認できました。
pandasのデータフレームとして、IndexとDataという概念があるので覚えておいてください。
今回はread_csvメソッドを呼び出した際に特にオプションを指定していないため
元のCSVにあるカラムはdataカラムとして認識し、Indexとしてレコード番号が自動的に付与されている状態です。
次のコマンドで
データフレームの中身のデータを先頭からX行表示出来るので確認してみましょう。
pandasのデータフレームの中身を確認する
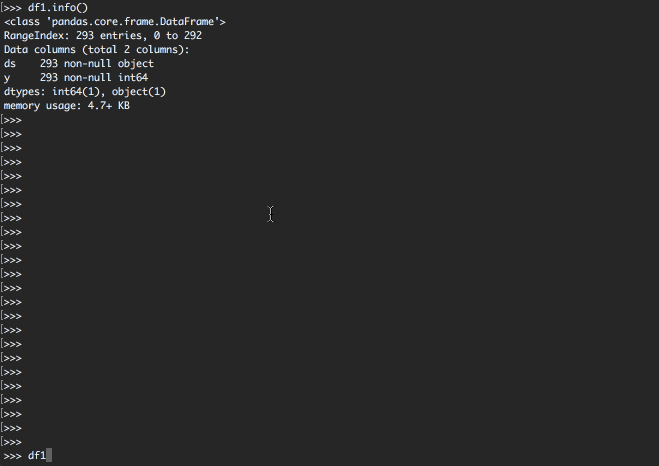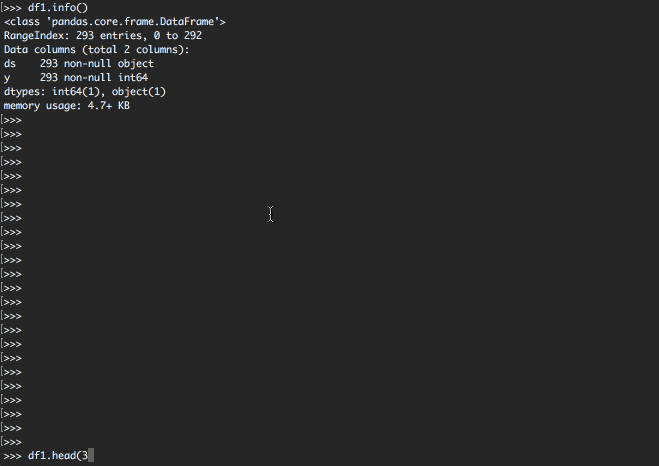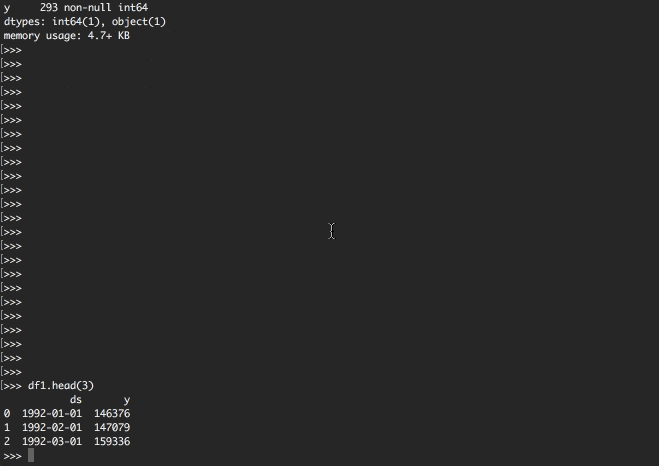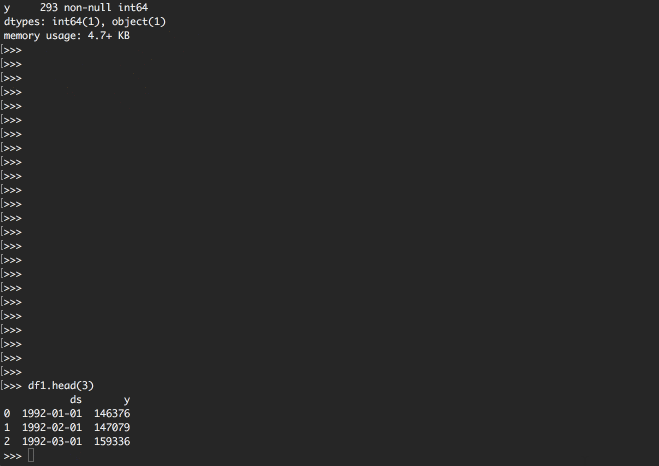
df.head(3)
以下のような構造が表示されましたね。
| ds | y | |
|---|---|---|
| 0 | 1992-01-01 | 146376 |
| 1 | 1992-02-01 | 147079 |
| 2 | 1992-03-01 | 159336 |
自然対数をとり、データフレームにカラム追加
データ解析において、突発的な異常値、外れ値などがあるとあるとそれに影響されてしまうので
自然対数をとったり、前処理をしてトレンドを綺麗だせるようにします。
今回は元々あった値を別のカラムとしてコピーし
自然対数を取った値を元のカラムに上書きしています。
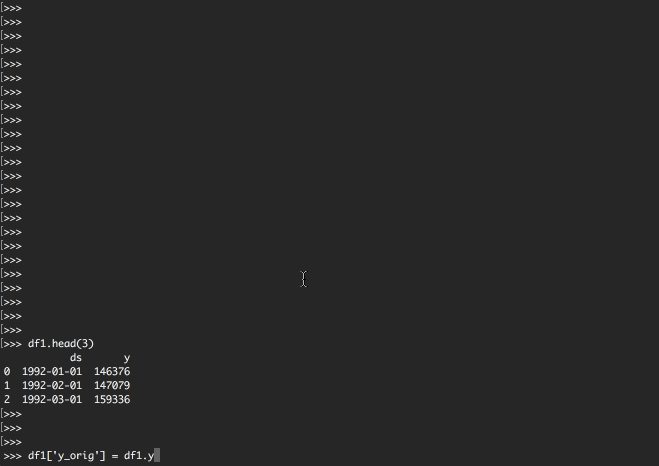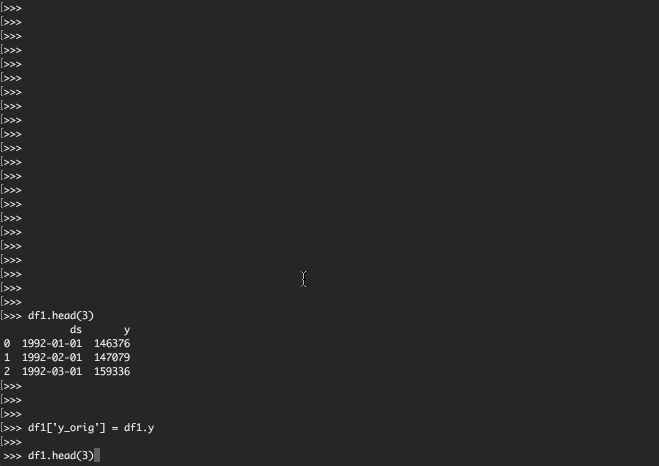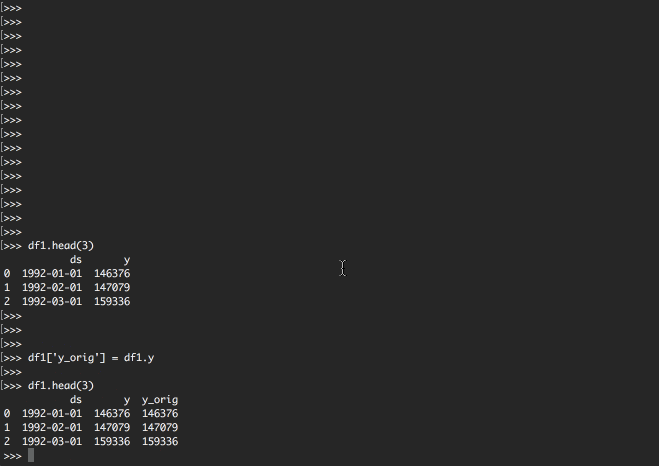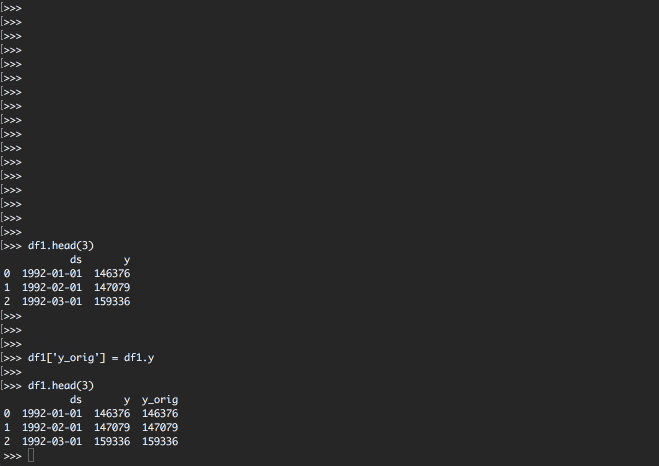
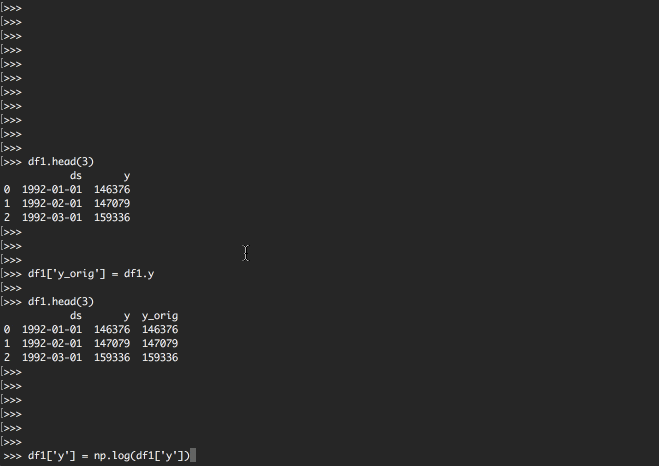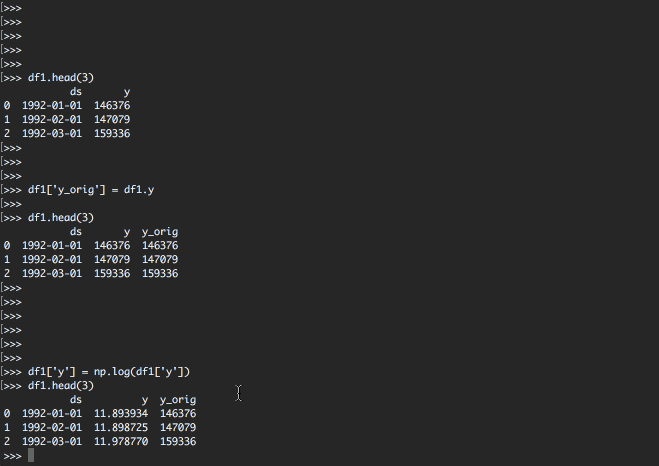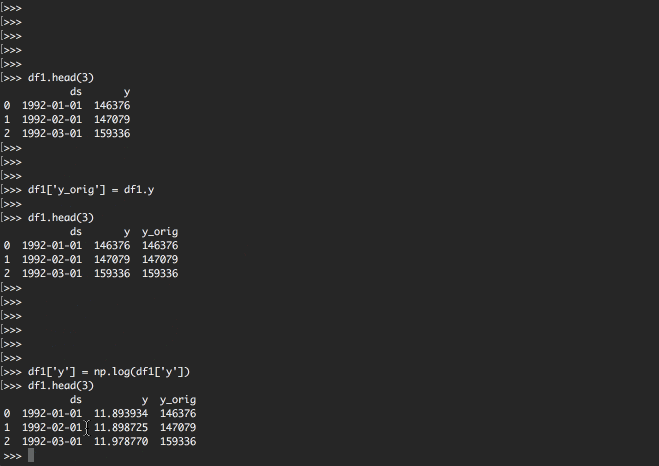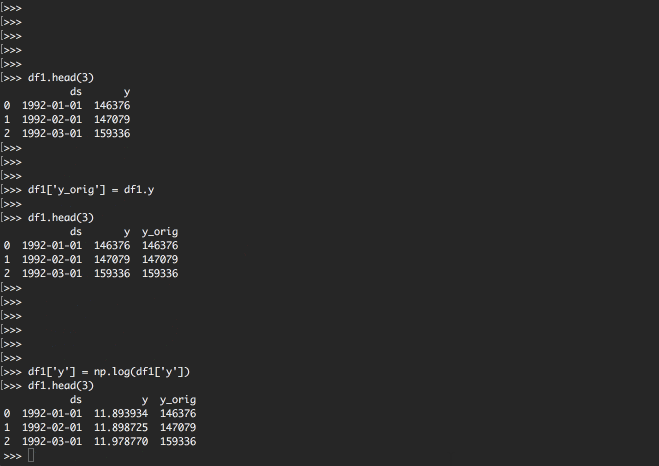
df1['y_orig'] = df1.y
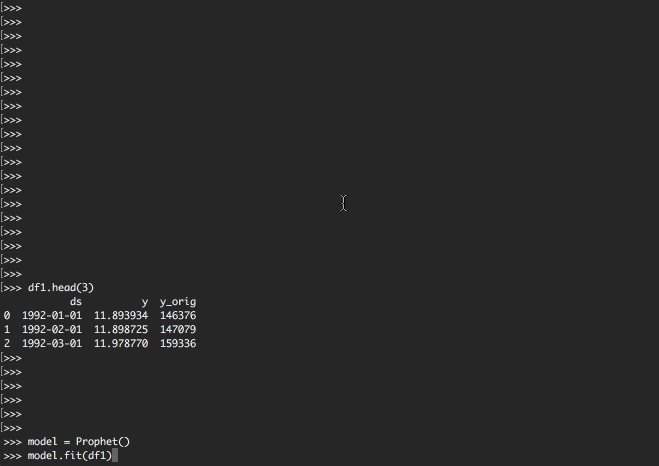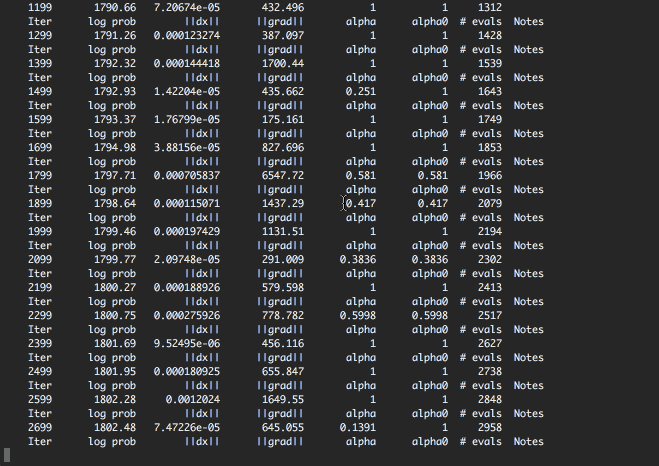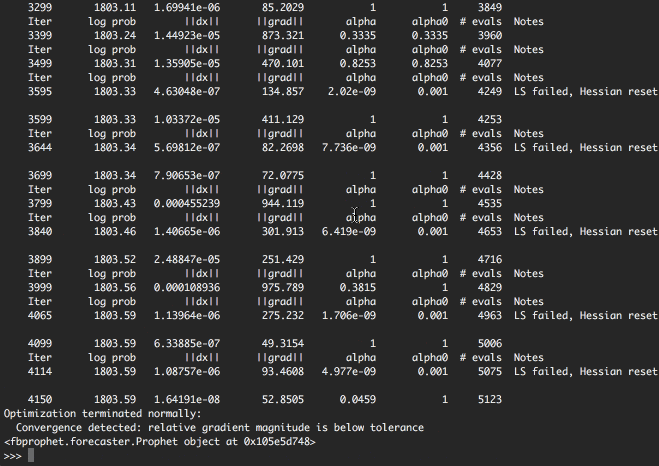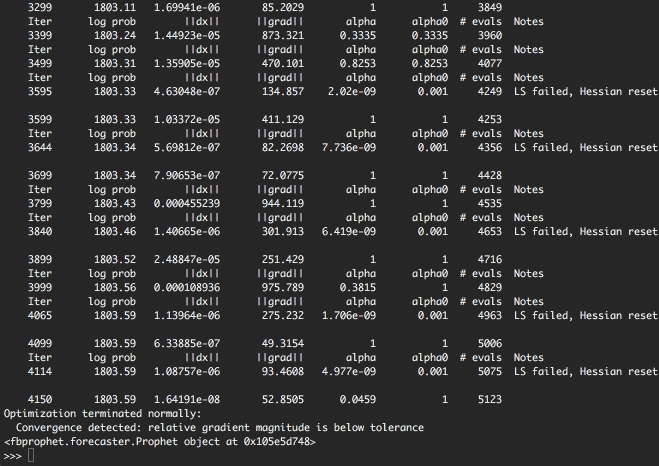
df1.head(3)
headで先頭行を見てみると
データフレームの構造が変わったのがわかると思います。
| ds | y | y_orig | |
|---|---|---|---|
| 0 | 1992-01-01 | 146376 | 146376 |
| 1 | 1992-02-01 | 147079 | 147079 |
| 2 | 1992-03-01 | 159336 | 159336 |
次に自然対数をとってみましょう。
これはnumpyのライブラリで用意されている便利な機能を利用します。
df1というデータフレームのyの値の自然対数をとり、df1のyカラムに格納しています。
df1['y'] = np.log(df1['y'])
df1.head(3)
| ds | y | y_orig | |
|---|---|---|---|
| 0 | 1992-01-01 | 11.893934 | 146376 |
| 1 | 1992-02-01 | 11.898725 | 147079 |
| 2 | 1992-03-01 | 11.978770 | 159336 |
prophetで予測モデルを作り学習させる
やっとここまできて、prophetのお話になってきます。
時系列予測をするために、まず最初にProphetで構成されるモデルを生成します。
その後に、実際のデータフレームを読み込み、学習させます。
本来であれば、モデルを宣言する際に様々なオプションが使えるのですが
ここでは説明を簡単にするために割愛します。
model = Prophet()
model.fit(df1)
prophetで未来の予測をする
次に、未来に対してどの程度の期間の予測するかを宣言し
実際に予測データを生成してみましょう。
「freq='m'」で月単位のデータを「periods=12」で12月分を予測してみます。
future_data = model.make_future_dataframe(periods=12, freq = 'm')
forecast_data = model.predict(future_data)
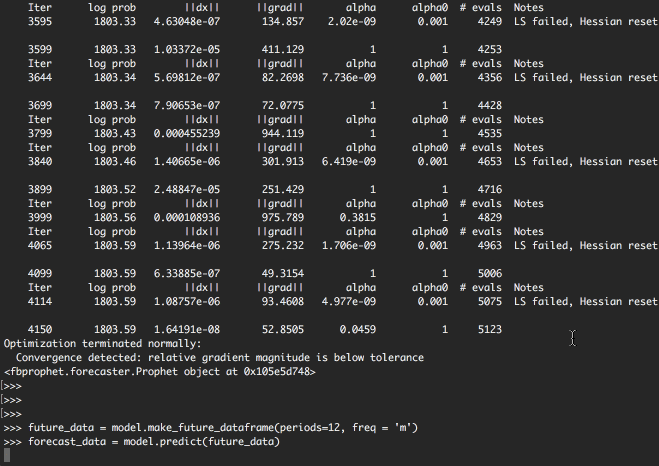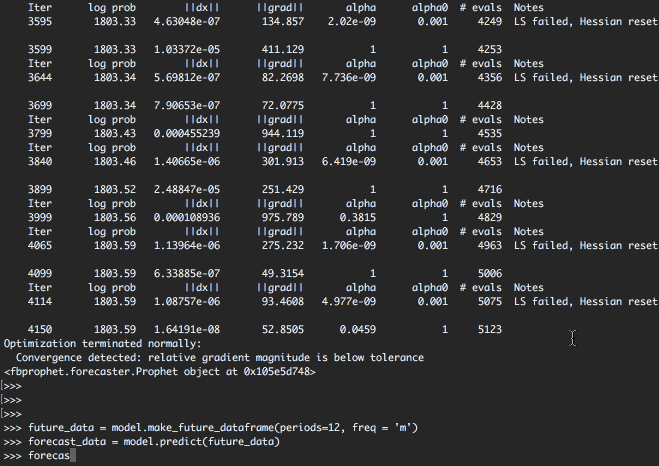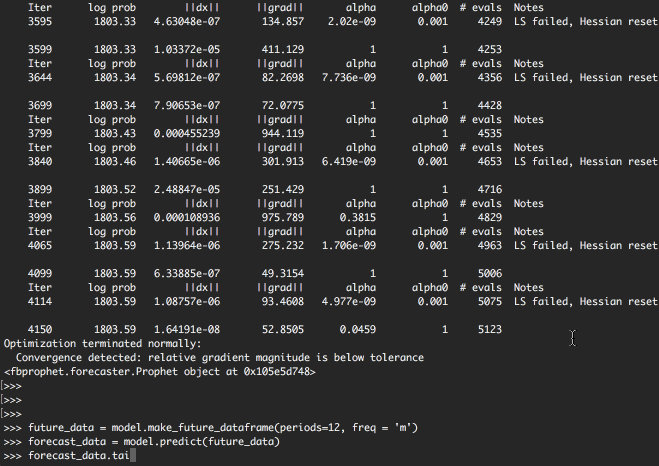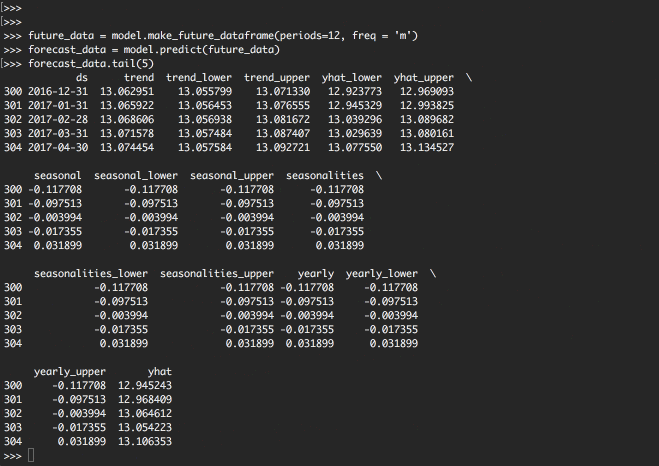
forecast_data.tail(5)
予測した結果データであるforecast_dataの中身は以下のような内容が保存されています。
簡単にふれると、傾向を示すトレンド、季節性、周期性、予測値とそれぞれ信頼区間として下限と上限と一緒に計算されているのが
わかると思います。
| ds | trend | trend_lower | trend_upper | yhat_lower | yhat_upper | seasonal | seasonal_lower | seasonal_upper | seasonalities | seasonalities_lower | seasonalities_upper | yearly | yearly_lower | yearly_upper | yhat | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 300 | 2016-12-31 | 13.062951 | 13.055799 | 13.07133 | 12.923773 | 12.969093 | -0.117708 | -0.117708 | -0.117708 | -0.117708 | -0.117708 | -0.117708 | -0.117708 | -0.117708 | -0.117708 | 12.945243 |
| 301 | 2017-01-31 | 13.065922 | 13.056453 | 13.076555 | 12.945329 | 12.993825 | -0.097513 | -0.097513 | -0.097513 | -0.097513 | -0.097513 | -0.097513 | -0.097513 | -0.097513 | -0.097513 | 12.968409 |
| 302 | 2017-02-28 | 13.068606 | 13.056938 | 13.081672 | 13.039296 | 13.089682 | -0.003994 | -0.003994 | -0.003994 | -0.003994 | -0.003994 | -0.003994 | -0.003994 | -0.003994 | -0.003994 | 13.064612 |
| 303 | 2017-03-31 | 13.071578 | 13.057484 | 13.087407 | 13.029639 | 13.080161 | -0.017355 | -0.017355 | -0.017355 | -0.017355 | -0.017355 | -0.017355 | -0.017355 | -0.017355 | -0.017355 | 13.054223 |
| 304 | 2017-04-30 | 13.074454 | 13.057584 | 13.092721 | 13.07755 | 13.134527 | 0.031899 | 0.031899 | 0.031899 | 0.031899 | 0.031899 | 0.031899 | 0.031899 | 0.031899 | 0.031899 | 13.106353 |
コンソール上では、データフレームのカラム数が多いので
改行されて表示されますので、びっくりしないでください。
予測した結果をグラフで確認する
予測した結果とそれを構成する成分情報をグラフで確認してみましょう。
model.plot(forecast_data)
model.plot_components(forecast_data)
plt.show()

無事に時系列データを用いて、予測が出来ましたね。
ここまでだと、自然対数を取っただけで傾向しか分からない状態なので
乗数をとって、もとの予測値に置き換えて表示する部分に関しては
のちほど更新しようと思います。
とりあえず動かしたい人向けの確認出来るソース全体
解説とかええから、とりあえず動かしてみたいねんって方は
以下を実行してみてください。
import pandas as pd
import numpy as np
from fbprophet import Prophet
import matplotlib.pyplot as plt
df1 = pd.read_csv('example_retail_sales.csv')
df1['y_orig'] = df1.y
df1['y'] = np.log(df1['y'])
model = Prophet()
model.fit(df1)
future_data = model.make_future_dataframe(periods=12, freq = 'm')
forecast_data = model.predict(future_data)
model.plot(forecast_data)
model.plot_components(forecast_data)
plt.show()
編集後記
今回の状態でも、雰囲気はつかめたかなと思います。この内容は会社でやっている技術LTイベントで急遽登壇してよという
無茶ぶりがあり、30分位で作ったネタです。データ解析や機械学習などのとっかかりにもちょうどいいのでシリーズ化し教育資料として
公開しちゃうことにしました。今後も更新していくので、フォローとストックをぜひおすすめします。
ps.会社で最近開発メンバも増えてきてUI/UX周りのコミュニケーションが大変になってきたのでこんなイベントを開催することになりました。興味あればぜひ、きてください。