はじめに
D言語で、各種文字コード(SJIS, EUC, JIS, EBCDIC, IBM漢字)への変換処理の実例を示したいと思います。
※記事で取り扱っていない文字コードについても、変換処理を実装する際の参考になればと思います。
環境
Shift_JIS(SJIS) <---> UTF8
toMBSz、fromMBSz使って、簡単に変換できます。Shift_JIS 文字コード表
string toSJIS(string s)
{ // UTF8 → SJIS
return ( s.toMBSz.to!string );
}
string fromSJIS(string s)
{ // SJIS → UTF8
return ( s.toStringz.fromMBSz );
}
EUC <---> UTF8
toMBSz、fromMBSzの引数にコードページを設定することで、変換できます。
コードページの対応表は、Code Page Identifiersにあります。20932はEUC-JPを意味しています。日本語EUC 文字コード表
string toEUC(string s)
{ // UTF8 → EUC(20932)
return ( s.toMBSz(20932).to!string );
}
string fromEUC(string s)
{ // EUC(20932) → UTF8
return ( s.toStringz.fromMBSz(20932) );
}
JIS <---> UTF8
JISからUTF8に変換する場合、EUCのようにfromMBSzを使うだけでは変換できません。
なぜかというと、fromMBSzでは文字コードが0x80以上の場合にのみ変換処理を行っています。
JISの漢字コードは0x80未満で構成されるため、変換対象になりません。JIS漢字コード表(JIS X 0208)
string fromMBSz(return scope immutable(char)* s, int codePage = 0)
{
const(char)* c;
for (c = s; *c != 0; c++)
{
if (*c >= 0x80)
{
wchar[] result;
int readLen;
result.length = MultiByteToWideChar(codePage, 0, s, -1, null, 0);
if (result.length)
{
readLen = MultiByteToWideChar(codePage, 0, s, -1, result.ptr,
to!int(result.length));
}
if (!readLen || readLen != result.length)
{
throw new Exception("Couldn't convert string: " ~
sysErrorString(GetLastError()));
}
return result[0 .. result.length-1].to!string; // omit trailing null
}
}
return s[0 .. c-s]; // string is ASCII, no conversion necessary
}
そのため、fromCodePageのような処理を実装する必要があります。
MultiByteToWideCharは、Windowsが提供しているAPIです。D言語は、Windows APIも簡単に呼び出せます。
string toJIS(string s)
{ // UTF8 → JIS(50220)
return ( s.toMBSz(50220).to!string );
}
string fromJIS(string s)
{ // JIS(50220) → UTF8
return ( s.fromCodePage(50220) );
}
string fromCodePage(string s, int codePage)
{ // (codePage) → UTF8
wstring ret;
int len = MultiByteToWideChar(codePage, 0, s.ptr, cast(int)s.length, null, 0);
if ( len > 0 ){
ret.length = len;
MultiByteToWideChar(codePage, 0, s.ptr, cast(int)s.length, cast(wchar*)ret.ptr, len);
}
return ( ret.to!string );
}
EBCDIC <---> UTF8
toMBSzでも文字コードが0x80以上かの判定があります。
このため、UTF8からEBCDICに変換する際は、toCodePageのような処理を実装する必要があります。
WideCharToMultiByteもWindows APIです。
EBCDICからUTF8に変換する際は、JISと同じくfromCodePageを使います。
20290はIBM290とも呼ばれ、CCSID 5026と同じ変換結果になりました。EBCDIC(CCSID 5026)コード表
string toEBCDIC(string s)
{ // UTF8 → EBCDIC(20290)
return ( s.toCodePage(20290) );
}
string fromEBCDIC(string s)
{ // EBCDIC(20290) → UTF8
return ( s.fromCodePage(20290) );
}
string toCodePage(string s, int codePage)
{ // UTF8 → (codePage)
char[] ret;
wstring sw = s.to!wstring;
int len = WideCharToMultiByte(codePage, 0, sw.ptr, cast(int)sw.length, null, 0, null, null);
if ( len > 0 ){
ret.length = len;
WideCharToMultiByte(codePage, 0, sw.ptr, cast(int)sw.length, ret.ptr, len, null, null);
}
return ( ret.to!string );
}
IBM漢字(CP930) <---> UTF8
IBM漢字(CP930)は、MultiByteToWideCharやWideCharToMultiByteが未対応のため、コード変換できませんでした。
このため、変換テーブルを作成してコード変換処理を行うよう実装しました。
変換テーブル(cp930.txt)は、こちらの情報を元に作成させていただきました。
static class CP930TBL {
static private wstring CP930toUTF8 = import("cp930.txt");
static private uint[wchar] UTF8toCP930;
static this() {
UTF8toCP930 = initConvTbl();
}
static private uint[wchar] initConvTbl()
{
uint[wchar] cp930tbl;
foreach ( hi, line; CP930toUTF8.split("\n") ){
foreach ( lo, c; line ){
cp930tbl[c] = cast(uint)((hi << 8) + lo + 0x4040);
}
}
cp930tbl[' '] = 0x4040;
return ( cp930tbl );
}
static string to(string s)
{ // UTF8 → CP930
char[] ret;
foreach ( cw ; s.to!wstring ){
auto c1 = UTF8toCP930[cw];
ret ~= [cast(char)(c1 >> 8), cast(char)(c1 & 0xff)];
}
return ( ret.to!string );
}
static string from(string s)
{ // CP930 → UTF8
wchar[] ret;
for ( int i = 0; i < s.length ; i += 2 ){
int hi = s[i ] - 0x40;
int lo = s[i+1] - 0x40;
ret ~= CP930toUTF8[hi * (0xff - 0x3F + 1) + lo];
}
return ( ret.to!string );
}
}
alias toCP930 = CP930TBL.to;
alias fromCP930 = CP930TBL.from;
ソースコード実装例
これまでの処理をまとめた実装例です。蛇足ですが、ソースコード自体の文字コードはUTF-8です。
import std.conv;
import std.stdio;
import std.string;
import std.windows.charset : fromMBSz, toMBSz;
import core.sys.windows.winnls : MultiByteToWideChar, WideCharToMultiByte;
string toSJIS(string s)
{ // UTF8 → SJIS
return ( s.toMBSz.to!string );
}
string fromSJIS(string s)
{ // SJIS → UTF8
return ( s.toStringz.fromMBSz );
}
string toCodePage(string s, int codePage)
{ // UTF8 → (codePage)
char[] ret;
wstring sw = s.to!wstring;
int len = WideCharToMultiByte(codePage, 0, sw.ptr, cast(int)sw.length, null, 0, null, null);
if ( len > 0 ){
ret.length = len;
WideCharToMultiByte(codePage, 0, sw.ptr, cast(int)sw.length, ret.ptr, len, null, null);
}
return ( ret.to!string );
}
string fromCodePage(string s, int codePage)
{ // (codePage) → UTF8
wstring ret;
int len = MultiByteToWideChar(codePage, 0, s.ptr, cast(int)s.length, null, 0);
if ( len > 0 ){
ret.length = len;
MultiByteToWideChar(codePage, 0, s.ptr, cast(int)s.length, cast(wchar*)ret.ptr, len);
}
return ( ret.to!string );
}
string toJIS(string s)
{ // UTF8 → JIS(50220)
return ( s.toMBSz(50220).to!string );
}
string fromJIS(string s)
{ // JIS(50220) → UTF8
return ( s.fromCodePage(50220) );
}
string toEUC(string s)
{ // UTF8 → EUC(20932)
return ( s.toMBSz(20932).to!string );
}
string fromEUC(string s)
{ // EUC(20932) → UTF8
return ( s.toStringz.fromMBSz(20932) );
}
string toEBCDIC(string s)
{ // UTF8 → EBCDIC(20290)
return ( s.toCodePage(20290) );
}
string fromEBCDIC(string s)
{ // EBCDIC(20290) → UTF8
return ( s.fromCodePage(20290) );
}
static class CP930TBL {
static private wstring CP930toUTF8 = import("cp930.txt");
static private uint[wchar] UTF8toCP930;
static this() {
UTF8toCP930 = initConvTbl();
}
static private uint[wchar] initConvTbl()
{
uint[wchar] cp930tbl;
foreach ( hi, line; CP930toUTF8.split("\n") ){
foreach ( lo, c; line ){
cp930tbl[c] = cast(uint)((hi << 8) + lo + 0x4040);
}
}
cp930tbl[' '] = 0x4040;
return ( cp930tbl );
}
static string to(string s)
{ // UTF8 → CP930
char[] ret;
foreach ( cw ; s.to!wstring ){
auto c1 = UTF8toCP930[cw];
ret ~= [cast(char)(c1 >> 8), cast(char)(c1 & 0xff)];
}
return ( ret.to!string );
}
static string from(string s)
{ // CP930 → UTF8
wchar[] ret;
for ( int i = 0; i < s.length ; i += 2 ){
int hi = s[i ] - 0x40;
int lo = s[i+1] - 0x40;
ret ~= CP930toUTF8[hi * (0xff - 0x3F + 1) + lo];
}
return ( ret.to!string );
}
}
alias toCP930 = CP930TBL.to;
alias fromCP930 = CP930TBL.from;
void writeHex(string s)
{ // 文字列の16進数表示
foreach ( c ; s ){
writef("%x ", c);
}
writeln();
}
void main()
{
string s = "あか青 AZaz ";
writeHex(s);
string s2 = s.toSJIS;
writeHex(s2);
writeHex(s2.fromSJIS);
s2 = s.toJIS;
writeHex(s2);
writeHex(s2.fromJIS);
s2 = s.toEUC;
writeHex(s2);
writeHex(s2.fromEUC);
s2 = "AZaz19アン<> ".toEBCDIC;
writeHex(s2);
writeHex(s2.fromEBCDIC);
s2 = "一9鸙煕 ".toCP930;
writeHex(s2);
writeHex(s2.fromCP930);
}
コンパイル手順
codeconv.dと同じフォルダにcp930.txtを配置してコンパイルします。
cp930.txtは、こちらに保存しています。
dmd -m64 -J=. codeconv.d
または
ldc2 -J=. codeconv.d
exeファイル実行例
変換前後のコードを16進数で出力する例となります。
D:\Dev> codeconv
e3 81 82 e3 81 8b e9 9d 92 e3 80 80 41 5a 61 7a 20
82 a0 82 a9 90 c2 81 40 41 5a 61 7a 20
e3 81 82 e3 81 8b e9 9d 92 e3 80 80 41 5a 61 7a 20
1b 24 42 24 22 24 2b 40 44 21 21 1b 28 42 41 5a 61 7a 20
e3 81 82 e3 81 8b e9 9d 92 e3 80 80 41 5a 61 7a 20
a4 a2 a4 ab c0 c4 a1 a1 41 5a 61 7a 20
e3 81 82 e3 81 8b e9 9d 92 e3 80 80 41 5a 61 7a 20
c1 e9 62 b9 f1 f9 81 bd 4c 6e 40
41 5a 61 7a 31 39 ef bd b1 ef be 9d 3c 3e 20
45 41 42 f9 67 fe 68 85 40 40
e4 b8 80 ef bc 99 e9 b8 99 e7 85 95 e3 80 80
応用例
fromXXXとtoXXXを組み合わせる
例えば、Shift_JISからJISに変換したい場合は、fromSJISとtoJISを組み合わせて実装できます。
ソースコード実装例のcodeconv.dから、main()を差し替えてください。
UFCSで書くと、すっきりしますね。
void main()
{
string s1 = [0x82, 0xA0, 0x82, 0xA8, 0x82, 0xE2, 0x82, 0xDC]; // Shift_JISで"あおやま"
string s2 = s1.fromSJIS.toJIS;
s2.writeHex; // 1b 24 42 24 22 24 2a 24 64 24 5e 1b 28 42
}
ファイル入出力の実装例
同じく、ソースコード実装例のcodeconv.dから、main()を差し替えてください。
void main()
{
auto fi = File("sjis.txt", "rt");
scope(exit) fi.close();
auto fo = File("jis.txt", "wt");
scope(exit) fo.close();
string line;
while ( (line = fi.readln()) !is null ){
fo.write(line.fromSJIS.toJIS);
}
}
Shift_JISからJISへの変換例として、Shift_JISで保存したインプットファイル(sjis.txt)を用意します。
あおやま
あかさか
実行結果をバイナリエディタで表示しました。
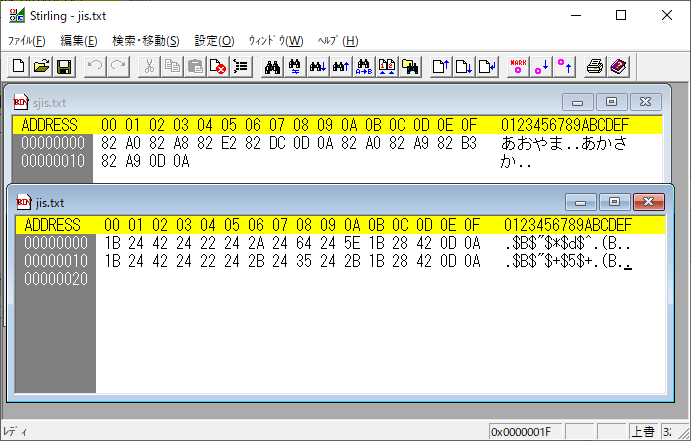
参考情報
D言語でShift-JISを入出力する
PowerShellで文字コード変換
IBM漢字コードからUTF8やSJISに変換する表を手に入れたい→手に入れた
Code Page Identifiers
D言語のUFCSが好きだ!
この記事のサンプルコード、変換テーブル
各種文字コード表
Shift_JIS 文字コード表
日本語EUC 文字コード表
JIS漢字コード表(JIS X 0208)
EBCDIC(IBM290, CCSID 5026)コード表
IBM漢字(CP930)コード表