1. はじめに
Qwen-Imageが凄いらしい。また、Comfyが正式対応して簡単に動作させられるというのをチラホラ見かけたため、ComfyUIを動作させるDockerイメージを作成し、さくっと試してみた。(というか公式のDockerイメージないんだね...)
なお、RTX5060ti 16GB、RTX3060 12GBで試行し、どちらでも動作させることができた。
2. 環境構築
DockerとNVIDIA Container Toolkitがインストール済みであることを前提としている。
2.1 Dockerfile作成
ComfyUIのgithubページとComfyUI Wikiを見ながらDockerfileを作成。
pytorchが必要と書いてあったため、pytorchの公式イメージをベースに作成した。
# 使用しているGPUドライバに対応するpytorchイメージを使用
FROM pytorch/pytorch:2.8.0-cuda12.9-cudnn9-runtime
# 作業ディレクトリ設定
WORKDIR /app
# 必要なモジュールをインストール
RUN apt-get update && apt-get install -y --no-install-recommends \
git \
&& rm -rf /var/lib/apt/lists/*
# comfyインストール
RUN git clone https://github.com/comfyanonymous/ComfyUI.git
WORKDIR /app/ComfyUI
RUN pip install --no-cache-dir -r requirements.txt
# ユーザー設定
RUN groupadd -g 1000 appuser && \
useradd -m -u 1000 -g 1000 appuser && \
chown -R appuser:appuser /app
USER appuser
EXPOSE 8188
# comfy起動
ENTRYPOINT ["python", "main.py", "--listen", "0.0.0.0"]
2.2 モデルファイルなど必要なものを取得&配置
HuggingFaceのComfyUIのページにあるモデルカードの内容を見ると、HuggingFaceからモデルを取得して配置しろとある。
Download qwen_image_fp8_e4m3fn.safetensors and put it in your ComfyUI/models/diffusion_models directory.
qwen_2.5_vl_7b_fp8_scaled.safetensors and put it in your ComfyUI/models/text_encoders directory.
qwen_image_vae.safetensors and put it in your ComfyUI/models/vae/ directory
以下のコマンドを実行してダウンロード&配置。
mkdir -p ./data/models
wget -P ./data/models/vae https://huggingface.co/Comfy-Org/Qwen-Image_ComfyUI/resolve/main/split_files/vae/qwen_image_vae.safetensors
wget -P ./data/models/diffusion_models https://huggingface.co/Comfy-Org/Qwen-Image_ComfyUI/resolve/main/split_files/diffusion_models/qwen_image_fp8_e4m3fn.safetensors
wget -P ./data/models/text_encoders hhttps://huggingface.co/Comfy-Org/Qwen-Image_ComfyUI/resolve/main/split_files/text_encoders/qwen_2.5_vl_7b_fp8_scaled.safetensors
2.3 docker-compose.yaml作成
私の環境はマルチGPU環境であるため、明示的に2番目ののGPUを使用するように指定している。
version: '3.8'
services:
comfyui:
build: .
container_name: comfyui
runtime: nvidia
environment:
# 筆者環境は5060tiが0, 3060が1。5060tiはLLMが常駐しているため、3060を使用するように明示的に設定
- CUDA_VISIBLE_DEVICES=1
volumes:
# ダウンロードしたモデルをマウント
- ./data/models:/app/ComfyUI/models
# 生成した画像の出力先
- ./data/output:/app/ComfyUI/output
# ワークフローの保存先
- ./data/workflows:/app/ComfyUI/user/default/workflows/
ports:
- "8188:8188"
2.4 その他マウントするディレクトリを掘っておく
生成した画像やワークフローをホスト側から直接参照できるようにするため、ディレクトリを掘って、それをコンテナにマウントしておきたい。このため、ディレクトリを予め掘っておく。
# 生成された画像を保存するディレクトリ
mkdir -p ./data/output
# 作成したワークフローを保存しておくディレクトリ
mkdir -p ./data/workflows
2.5 ディレクトリ・ファイル構成
最終的なディレクトリ・ファイル構成は以下のの通り。
$ tree
comfyui/
├── Dockerfile
├── data
│ ├── models
│ │ ├── diffusion_models
│ │ │ └── qwen_image_fp8_e4m3fn.safetensors
│ │ ├── text_encoders
│ │ │ └── qwen_2.5_vl_7b_fp8_scaled.safetensors
│ │ └── vae
│ │ └── qwen_image_vae.safetensors
│ ├── output
│ └── workflows
└──docker-compose.yaml
2.6 ビルド&起動
以下のコマンドでDockerイメージをビルドして、コンテナを起動する。
# ビルド
docker compose build
# 起動
docker compose up -d
コンテナ起動後、ブラウザでhttp://localhost:8188 にアクセスして、以下の画面が表示されれば構築完了。

3. 画像生成を試す
3.1 サンプルの画像生成を試す
ComfyUIのモデルカードのページにある画像を、ComfyUIの画面上にドラッグ&ドロップすると、ワークフローを読み込むことができる。

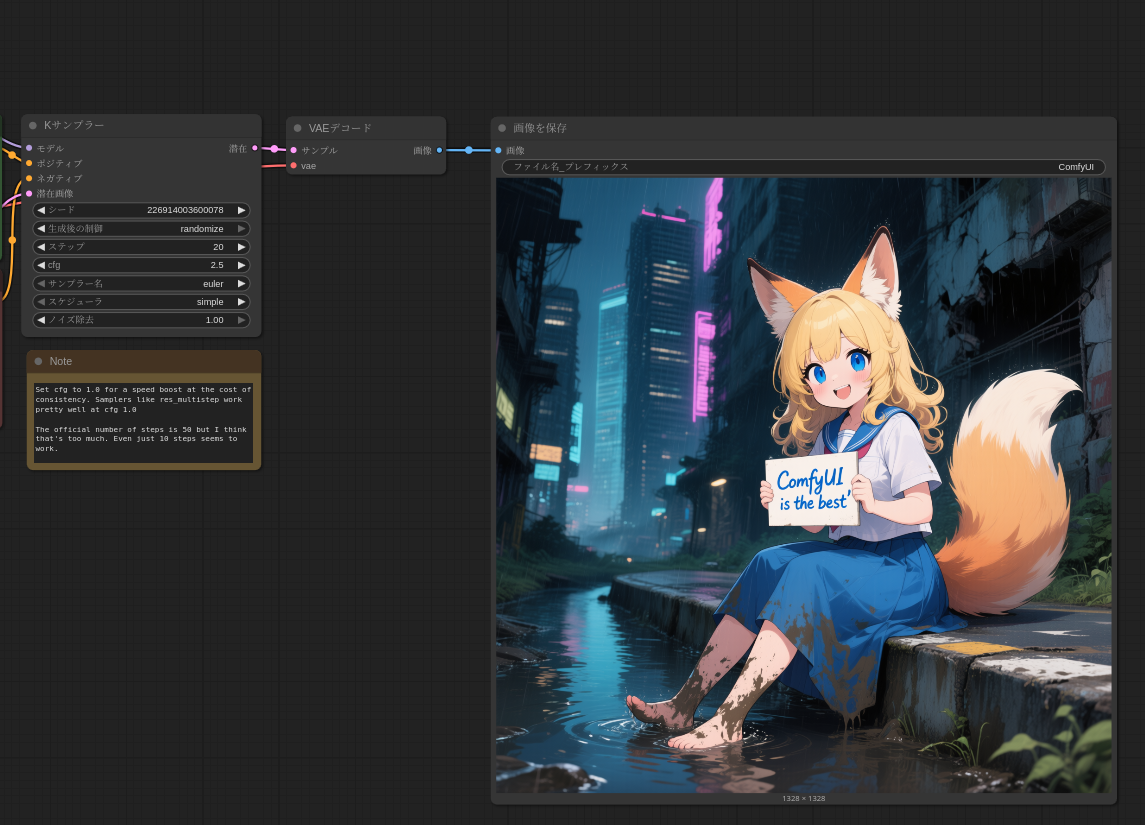
Positiveプロンプトには狐少女を作成するためのサンプルプロンプトが入力された状態になっている。

実行するとサンプルの画像とまったく同じ画像を生成することができた。なお、所要時間はRTX5060tiで190秒、RTX3060で387秒であった。
3.2 オリジナルの画像を生成してみる
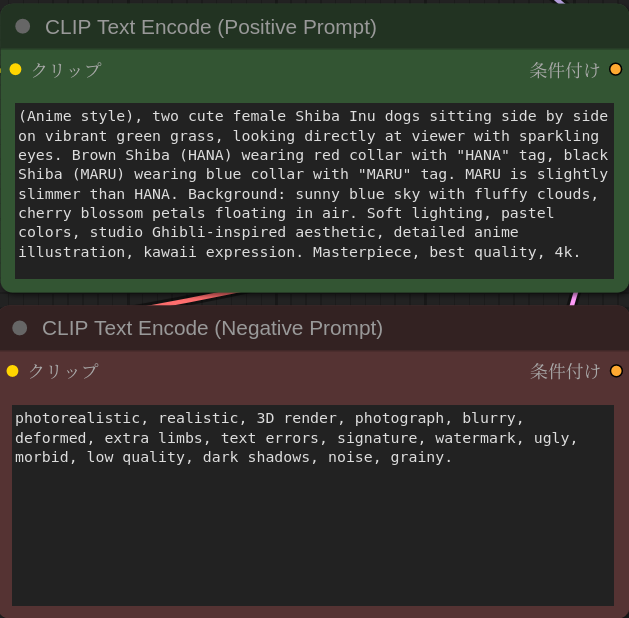
サンプルのワークフローのPoisitive Prompot, Negative Promptに独自のプロンプトを指定するだけで、好きな画像を生成させされる。
次のプロンプトを指定し、名札付きの首輪をつけた柴犬の画像を生成させてみた。
指示通りに名札付きの首輪をつけた柴犬の画像が生成された。きちんとプロンプトで指定した名前も出力されている。これは凄い。

4. まとめ
今回は、DockerでComfyUI環境を構築してQwen-Imageを試してみた。今回ComfyUIの構築と使用は初めてであったが、特にハマることもなくComfyUI+Qwen-Imageでの画像生成環境構築することができた。