はじめに
皆さん、負債解消してますか!私のチームでも、システム開発に関わる様々な負債の解消に日々勤しんでいます。
ただ、この負債解消について、コード以外の観点での事例って割と技術記事投稿サイトでは見かけないかなーと思ったので、私たちが取り組んだ事例を出来る範囲で書いてみました。へー、こんなことしてるんだーと参考になることがあれば幸いです。
ついでに、テックカンパニーではない開発チームでも、割と面白いことに取り組んでいたりするんだなーと思っていただければ嬉しいです。
この記事で紹介する負債の事例は、アーキテクチャの技術的負債、組織体制上の負債となります。
また、記事公開にあたり、私たちの事例内容を一部抽象化・一般化している部分やもありますが、ご了承ください。
事例紹介の前に: システム開発の負債は何故出来るのか?
システムを運用すればするほど溜まるもの、それは技術的負債。このテトリスの例えはわかりやすいですよね。素早く技術負債を解消して、足場を整えないとこうなります。
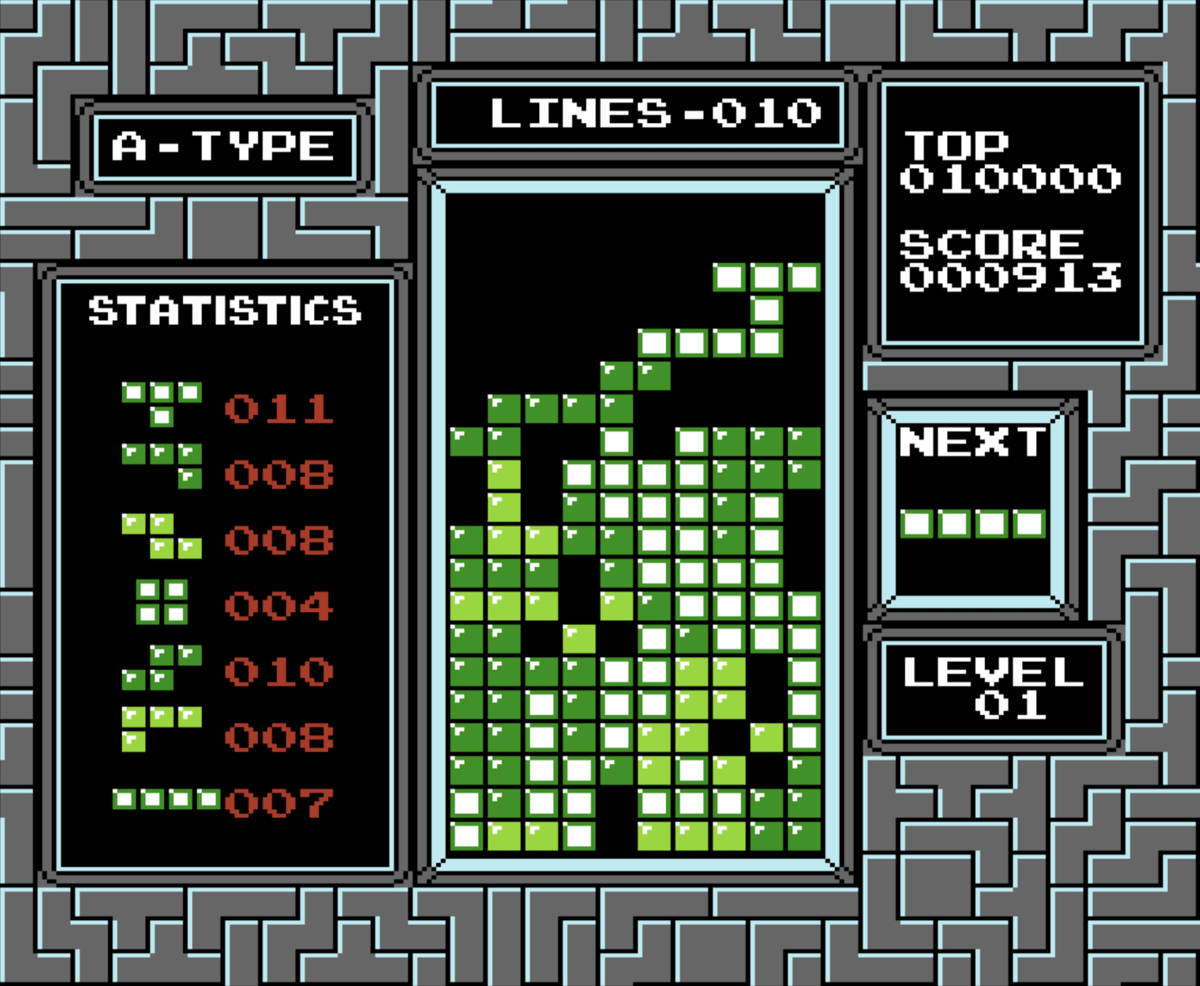
引用: https://gigazine.net/news/20190322-technical-debt-tetris/
コードの負債であれば、どうやって発生していくのかイメージが付きやすいと思います。誰もが最初から負債にならないように検討を進めてはいるはずなのに、想定よりもやるべきことが多くなって開発期間が無くなり、雑な作りになってしまった。あるいは想定外の機能追加が発生し、それに対応する為にいびつな拡張を行ってしまった。このように、ソフトウェア開発の不確実で思い通りにいかない性質が、負債が出来る原因の一つになっています。
そんな不確実性を話すときに必ず取り上げられる、不確実性のコーンという図があります。

引用:https://xtech.nikkei.com/it/article/COLUMN/20131001/508039/
この図は、最初は不確実性が大きい状態で、開発が進むほどそれが減っていくことを示しています。そう考えると、初期段階のより不確実な状態で決められたアーキテクチャや組織にも、負債が溜まっていくというのは想像できます。
実際、最初はベストだったと思っていたアーキテクチャや組織構成が、ニーズの変化についていくのにかみ合わなくなったなんてことはざらにあります。特に変化の激しいIT業界であればなおさらです。
コードに限らずアーキテクチャでも組織でも、どんなに頑張ってもシステム開発における負債はたまるものと認識し、課題を正しくとらえ、解消に取り組んでいくことが重要です。
私たちが取り組んだシステム開発の負債解消
というわけで、ここからは私たちの話を書いていきます。まずはやっていることの紹介から。
弊社ではデータセンター事業を展開しており、私たち開発チームは、そのデータセンターを利用するお客様・運用者向けのポータルサイトを作っています。
どんなポータルサイトかと言いますと、
お客様「いついつ入館したいで!」
運用者「あああのお客様か。承認しましたー」
お客様「サーバーをいついつ送るで!」
運用者「りょーかいです。準備しておきますねー」
お客様「おう、毎回申請めんどいから入館証用意してくれや!」
運用者「承知しました、手配してお送りますねー」
みたいな、データセンターに関わる申請等を受け付けるためのものになります。
このデータセンターのポータルサイト開発を進めるにあたり、出てきた負債とその解消について紹介していきます。
「うわっ…私のリリース、遅すぎ…?」モノリシックからマイクロサービスへ
私たちのデータセンターサービス事業は世界展開しているのですが、実は利用いただくポータルサイトは国によってバラバラでした。これはお客様にとって嬉しくないことだったので、ポータルサイトを統一する必要がありました。
一方で、サービス向上のため、他事業社と比較して足りない機能の追加開発もしていました。その追加開発はどこに力を入けばいいのか?それはお客様がよく使う機能でした。
特に、私たちのサービスでは、お客様がよく使う機能というのはある程度決まっていました。例えば入館申請。お客様は入館しないとデータセンターを利用出来ないため、必ず使われる機能となります。
そんなよく使う機能のアップデートを素早くリリースしたいのですが、当時はモノリシックなシステムアーキテクチャを採用していたため、一部の開発でもシステム全体の差し替え、試験し直しが必要となり、その分リリース速度が落ちていました。
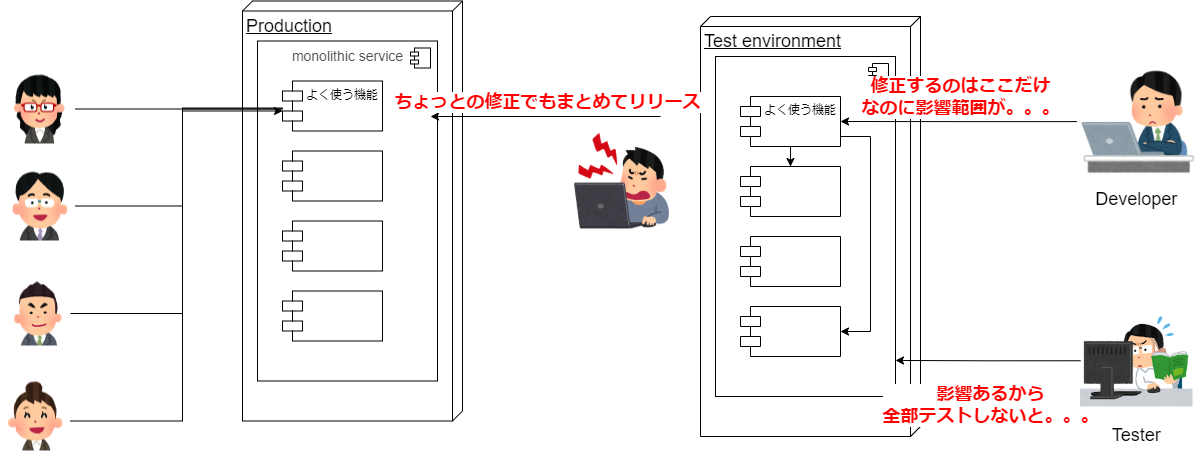
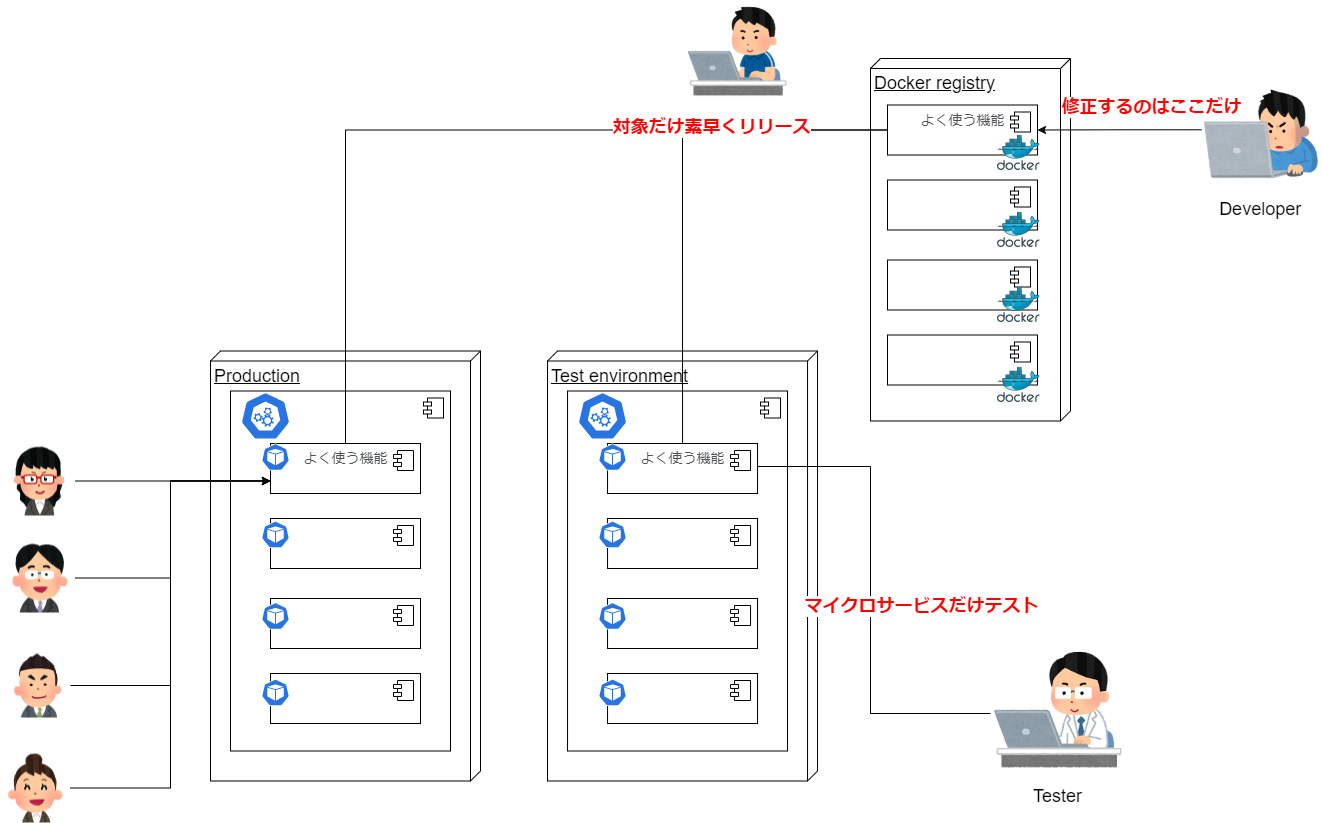
このリリース速度を上げるために、システムのアーキテクチャをマイクロサービス化して刷新。機能単位でマイクロサービスを作り、DBもマイクロサービスに分けてREST APIでのデータのやりとりをする形に変えることで、一部の機能だけをリリースすることが可能な状態にしました。
また、技術要素としてはマイクロサービスをコンテナ化し、kubernetesを使った管理を行うようにしました。これは、kubernetesの可用性・拡張性に期待する以外にも、コンテナ化することによりプラットフォームの移し替えにも柔軟に対応できるようにするという目的もありました。
- まとめ
- 負債: よく使う機能のリリース速度が遅い
- 原因: モノリシックなシステムであるため、開発の影響度及びテスト範囲が広かった
- 対処: マイクロサービス化により、一部機能のみがリリース可能な状態にした
「うわっ…私の要件検討、遅すぎ…?」日本の開発チーム構築へ
アーキテクチャを新しく、もう安心。とそう簡単にはいきません。
マイクロサービス化の目的はリリース速度を上げる点にあったのですが、実際進めていくと今度は開発プロセスの問題が浮き彫りになってきました。
弊社のビジネス拠点は日本にあるのですが、当時の開発拠点は海外にあり、システムアーキテクチャを考えるのも海外のメンバーでした。オフショア開発のように日本で基本設計→人件費の安い国で開発という構図ではなく、要望は日本で受け、ビジネス的な要件検討は日本、技術的な検討は海外でやっていた構図になります。
ビジネスでやりたい要望をどう実現するかを検討する際、ビジネスと技術それぞれの観点は完全に切り離されているわけではなく、実現性を見ながらビジネスとしてベターな解を模索するといったアプローチは必ず必要となってきます。その中で、日本だけでは技術的な実現性を詰めることが出来ない体制は、検討速度の遅さを生み出すことになります。それ以外にも、国が異なることによるコミュニケーション、時差、文化の違い、様々な要素が検討の遅さに繋がり、求めていたリリース速度向上への足枷になっていきました。
また、本来は私たちのシステムに関する負債は自分たちで分析し、検討・解消を進めていきたいのですが、技術的な議論をするなら海外となるため、それも難しい状況を生んでいました。
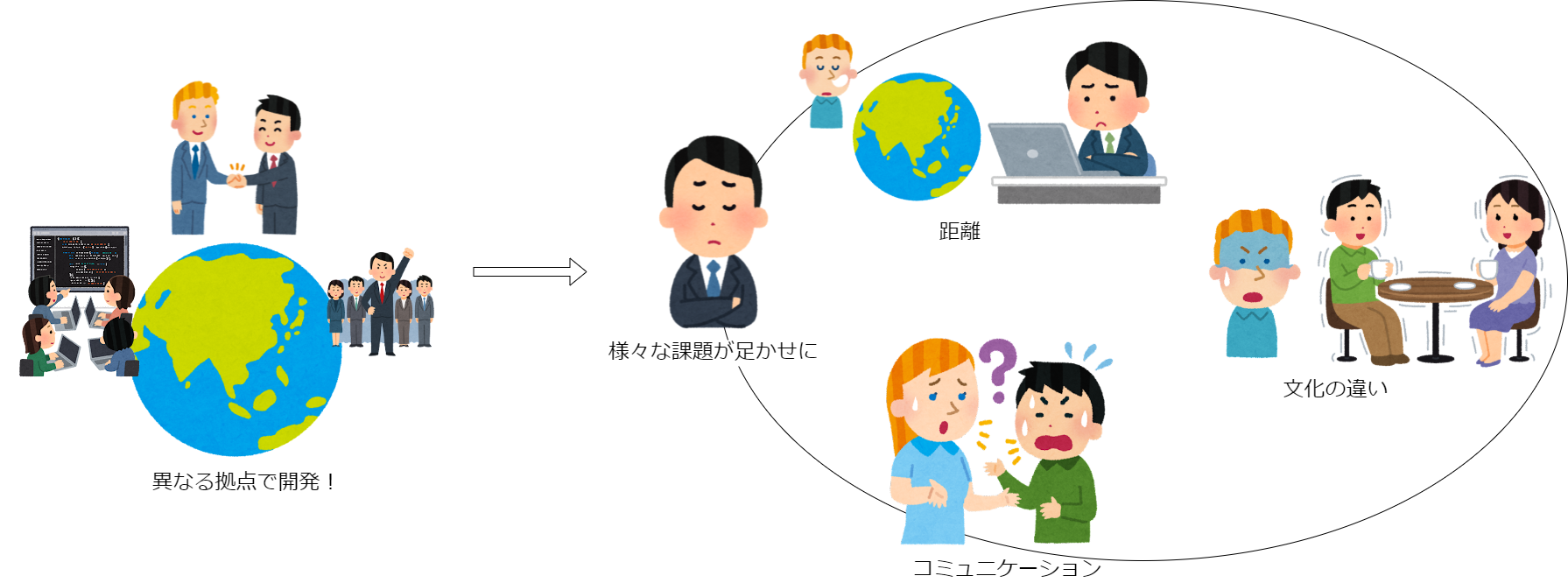
そういった課題を解決するため、開発拠点を日本に移動。日本に技術要素が分かる人員を立て、ビジネスロジックをはじめとするインフラ以外すべての要素を日本チームで開発するという体制を作ることに成功しました。
この体制により、日本で技術的な要素も含めた検討をスムーズに進めることが出来るようになり、リリース速度に対する足かせを外すことができました。また、技術的検討の中心が私たち自身になることで、技術的負債解消にも取り組めるようになりました。

ちなみに、この日本チームを立ち上げていく中で、チームビルディングの観点で色々な苦労や取り組みがありました。そういう苦労話も面白いんじゃないかなと思いますので、その話はこちらで別途記事にしました。
- まとめ
- 負債: 要件の検討速度が遅い
- 原因: ビジネス拠点は日本、開発拠点は海外にあり、スムーズな技術的検討が出来なかったため
- 対策: 開発拠点が日本になるよう開発チームを立ち上げ、スムーズな技術的検討が出来るようにした
- 副産物: 自分たちで技術的負債解消が出来るようになった
「うわっ…私のオンプレ、(やること)多すぎ…?」オンプレからの脱却
日本チームも立ち上げ、無事リリース速度は改善。そのまま利用拠点も拡大し、新しいシステムの運用が徐々に本格化していきました。
ただ、実際に運用がはじまると新たな課題が見えてきます。自前で安定運用を進めていくには、やることが.. やることが多い..!!(金田一の犯人並感)
果たしてどんなことをやらなければいけなかったのか?ここでは、以下の観点で書いていきます。
- 故障率を下げる
- どう設計するか?
- どう品質をあげるか?
- 稼働率を上げる
- どう故障を検知するか?
- どう素早く復旧するか?
拡張性の話等もあるのですが、上記が出来ないとそのステージにも立てないのでここでは省略します。
故障率を下げるための設計: ボスケテ!
故障率を減らすためには、主に以下の観点があるかなと思います。
- 止まらないようにする
- 止まりそうな箇所を減らす
前者は、要は冗長化しましょうってやつですね。例えば2台同じデータベースを持っていて、1台が死んでももう1台が使えるようになっていれば、システム全体は止まらないよね?みたいな話です。
後者は、例えば1つの機能を実現するために2か所からデータを取ってこなければいけない場合、そのうちの1つが故障していると機能が使えなくなります。これが3か所、4か所と増えていくと、機能が使えなくなるケースが増えていき、その分故障リスクにつながります。だから無駄なやり取りは消していこう!といった感じの話です。出来るだけシンプルに作ろうぜ!みたいな。やり取りを減らす、影響範囲を分散させる等、様々なアプローチがあると思います。
私たちのシステムでは、冗長化の為にkubernetesを取り入れ、加えてkubernetes外管理のデータベース等にも独自に冗長・切り替えの仕組みを取り入れていました。そうして冗長化された構成を組んでいくと、今度はシステム全体の規模が大きく、複雑さが増していきます。その複雑さが今度は故障点を増やすことに。
実際、あまりビジネスロジックと関係のないちょっとしたデータを取るだけなのに、アクセスしないといけない場所が色々なところ存在する構成になっており、その構成要素の1か所が故障して障害が発生ということがありました。解決するには、冗長化は保ちつつ、故障点も減るようなシンプルな構成に変えなければいけませんでした。うーん頭が痛い
この相反しそうなことを同時にこなしていく構造、なんかすごいよ!!マサルさんで出てきたボスケテみたいだな。ボス決して落とさず急いで冗長化して そして早くシステムをシンプルにして!
クラウドサービスだと、こういった冗長構成が機能として提供されていて、利用者としては意識せずに恩恵を得られる状態になっていることが多いと思います。これだけでも考えるべきことがいくらか軽減されますよね。
故障率を下げるためのテスト: 可能性の沼へようこそ
試験の観点ではどうでしょう?構成が大きくなると、その分コストがかかってきます。本番とは違い検証環境となると、出来るだけコストを抑えるため、構成を妥協したくなります。するとどうなるか?
検証環境と本番環境を異なる構成にすると、本番でしか起きない故障発生!という、思わぬ事態を引き起こすことがあります。
そうならない為にも、出来る限り「本番と全く同じ」環境でテストすることが大事です。
…同じってどこまでやるのよ?って思いますよね。色々度外視して理想論だけで語ると、ネットワークから冗長構成からマシンスペックから、全く同じ状態にするのが理想だとは思います。
しかし現実問題としては人、もの、金、どれも限りがあります。なのでどこまで同じ構成をテスト用に構築すると効果が高そうか?について頭を悩ませて設計する必要があります。
しかも同じ構成を組めればOK!というわけではなく、今度は起きうる事象、ユースケース、諸々を想定して、一部故障や不安定な状態のテストをする必要があります。
設計上いくら完璧であったとしても、テストをせずに問題なく動作するシステムなんて *ただし摩擦はないものとする みたいな理想の話です。
ただこちらも必要性としてはわかるんだけど、実際に故障のケースを洗い出していくのって中々ハードですよね。例えばインフラ故障だけでも、
- 一部サーバーダウン
- ネットワーク不通
- DBアクセス異常
etc、色々なケースがありますし、じゃあそのサーバーダウンを取っても
- サーバー自体が落ちている
- サーバー上の一部主要アプリケーションだけ落ちている
- 起動はしているけど応答がない
etc
いくらでも状況が出てきます。沼です。なのでテスト観点としてもどれをやるのが効果的かを設計していく必要があります。
これらのテスト設計と実行は必要ですし、やらない限りは品質は上がらず故障は防げません。
まあこのくらいは平気だろうと妥協したところに限って故障が!なんて経験、皆さんもあるのではないでしょうか?
人・もの・金・時間に限りがある中、その制限の中でよりベターなテストを追求していく必要があります。
こちらもクラウドサービスだと、クラウド側が提供しているサービスについては彼らが品質を保っているため、いくらかテストに関する負担も軽減されます。
稼働率を上げるための故障検知: テスト沼の横には監視沼が
今度は稼働率について考えていきます。稼働率改善のためには、故障率に加え、故障からの復旧時間も改善する必要があります。
え、まだあるの!?故障率を下げたんでしょ!テストもしっかりしたしもう故障なんて起こらないよ!!と摩擦はないものとしたくなるかもしれませんが、現実を受け止めて故障した後のことも考えましょう。
まずは故障をいち早く発見できるようにする必要があります。監視の導入です。
監視は想定される故障のケースに対して入れることになると思いますが、ひとつ前のテストのところでも書いたように、故障のケースって沢山あります。また、監視の種類も沢山あります。入門監視で書かれている監視のタイトルを上げていくだけでも、フロントエンド監視、アプリケーション監視、サーバー監視、ネットワーク監視、セキュリティ監視と様々。
故障率の沼を抜けたら今度は監視の沼で取り囲まれました。
もちろん導入できる監視は全部導入したいところですが、ここでもどこからやるか、どこまで出来るかの検討が必要です。どこを監視すると効果的なの?ネットワーク?サーバー?
この辺りの監視対象をきめ、監視を導入していく必要があります。当然アラートを上げる仕組みも必要です。
ここを妥協すれば発見が遅れ、ユーザー影響が増えていく。やるべきことをやらなければ。
クラウドサービスを利用すると、自分たちで管理する部分とクラウドサービス内で管理される部分に分かれるので、監視についても自分たちのものに意識を向ければいいですよね。クラウドのリソースに対する監視機能もあるし。
また、クラウドサービス側の故障についても、発生時にわかるようRSS等が用意されていると思います。仕組みがある分監視も比較的容易でしょう。
稼働率を上げるための復旧対応: 自動復旧とくらし安心クラシアン
さあ、監視が動き出しました!早速故障が検知されています!今度は復旧です!現実は非情です!
当然自動復旧の仕組みが導入できるなら、どんどん入れた方がいいです。例えばkubernetesを使うと落ちたコンテナの再起動をしてくれますし、復旧手段が決まっているものなら、監視アラートトリガーで復旧手段を実行するような仕組みも導入できると思います。
ただ、サービス運用の段階次第では、まだ自動復旧の仕組みが導入しきれていないこともあるでしょうし、導入済みでも不測の事態を考える必要があります。もしサービスが1分1秒も止められないようなものであれば、くらし安心クラシアンのような24時間365日体制で誰かが故障を直す必要が出てきます。
故障?もちろん俺らは抵抗するで?人手で
さあ果たして素早く復旧作業が出来るクラシアン部隊を持つことが出来るのか?中々ハードルの高い話だと思います。かといって体制を妥協して、人が割けない時間に故障が起きれば、被害が広がりサポートへの連絡も増える一方。そして故障対応による忙しさに負けて他の必要なことに力が割けなくなり、更なる故障が起きて、と悪循環が続くなんてことも。。。
クラウドサービスであれば、クラウド側の故障に関してはクラウドサービス内で復旧が行われたりと、一部のクラシアン人員を肩代わりしてくれる利点はありますよね。
やること軽減のためにクラウドネイティブへ。どう進めていくかは今の資産次第
そんなこんなでやることの多い運用。人も金も湯水のようにあるわけではないので、すべてを理想通りに実現することは出来ません。何かを変えるしかない。
というわけで、オンプレ構成をクラウドプラットフォームに乗せ換えていき、コストの削減を狙う方向に。
ただ、アーキテクチャを改めて検討するにあたり、効果の予想・測定は大事です。単純にモダンな開発がしたい!が目的であれば、「全部サーバーレス化だ!クラウドネイティブだ!」となるかもしれません。しかし、私たちの達成したいことは違います。なので、何が一番ネックになって解決したいことなのか?やろうとしていることが本当に課題解決に効果があるのか?ということを考える必要があります。
例えば、私たちの既存マイクロサービスに対する検討としては、サーバーレス化するか、コンテナだけ利用してクラウド上にkubernetesクラスタを立てるか、等の選択肢からアーキテクチャを決める必要がありました。
その中で以下について試算。
- 既にあるマイクロサービスたちをサーバーレス化する開発コストの追加
- サーバーレス化によるメンテナンスコストの変動
- サーバーレス化による運用コストの変動
結果を比較すると、意外と既存サービスに関してはサーバーレス化することで大きなメリットを得ることが出来ず、逆に開発コストだけかかることが分かりました。故障率の面で見ても、別段サーバーレス化したからといって大きくビジネスロジックの構成が変わるわけではないため、大差ないという結果に。
であれば頑張って全部サーバーレスにする必要もないかー。例えば新規開発とか、機能から見直したいマイクロサービスが出てきたら、サーバーレスの利用を考えるか―という方針に落ち着きました。
それよりもメリットがあったのが、インフラ周りの置き換えでした。インフラをクラウドネイティブな機能で置き換えていくと、人件費、運用費、様々な観点で効果が得られそうでした。実際先ほど説明していたどの観点でもメリットがあります。そのため、まずはVMの乗せ換えでいいから一度基盤をクラウド上で動く状態にし、その後インフラ部分をクラウドネイティブな機能に置き換えていく方針で進めることとなりました。
というわけで、私たちのクラウド化方針をまとめると以下となります。
- 既存マイクロサービスはコンテナをそのまま活用
- 新規機能はサーバーレスで
- インフラ環境はクラウドネイティブを狙う
この方針は、あくまで私たちの取り巻く環境を考えた場合にこれがベターだったという話になります。
例えばこれがマイクロサービス化してコンテナ利用する前であれば、コンテナ vs サーバーレスどちらも開発コストがかかるため評価も変わってくると思います。
また、例えば私たちが歴戦のシステム運用チームを持っていた場合、上記で書いた運用面の課題はクリアした状態だと思いますので、クラウド化による学習・再設計コストやランニングコストを加味してやっぱりオンプレのままいこう!という結論に至った可能性もあります。
このように、単純に「クラウド化だ!」と言っても、その組織が持っている技術的資産や人的資産、取り巻く環境などによってアプローチの仕方や目的は変わっていくものなのかなと思います。
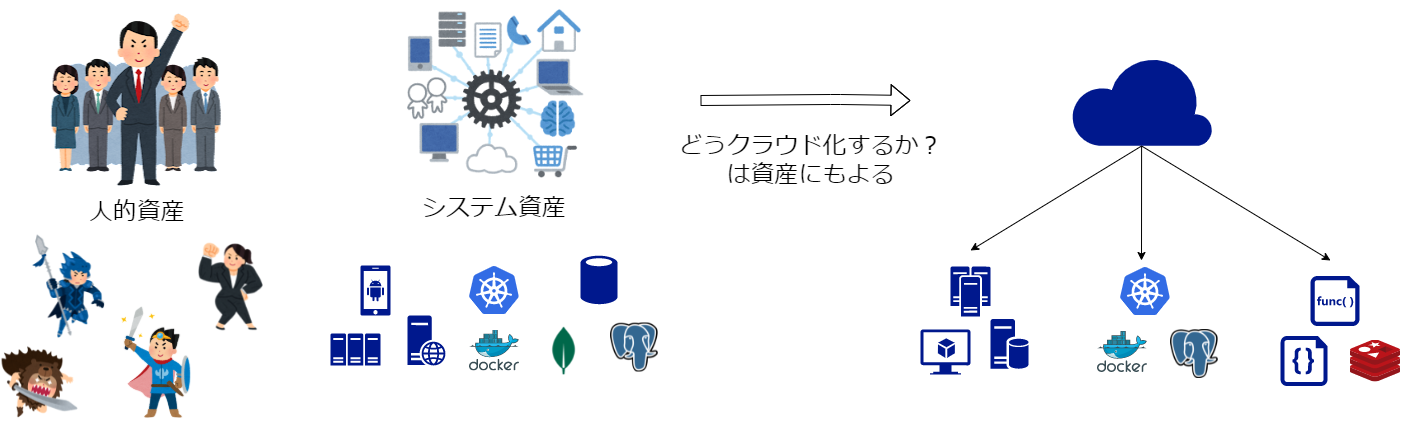
- まとめ
- 負債: 安定運用の為に私たちがやるべきことに対して、実行が追い付かない
- 原因: やるべきことが大量にあり、実行量を超えていた
- 対策: クラウド化により、自分たちでやるべきことを減らす
「うわっ…私の負債、多すぎ…?」改善は続くよどこまでも
ここまで負債解消の話をしてきましたが、これで負債が無くなったかというとそんなことはありません。最初に書いたように負債はたまっていくものですし、まだまだやるべきことは盛りだくさんです。
例えば
- 自動テスト, CI/CDの強化
- 性能面に目を向け、速度面の改善
- クラウド運用について効果測定・分析 && 改善
- 新規サービス拡張に伴うアーキテクチャのゆがみを分析 && 改善
etcetc
改善は続くよどこまでも
最後に
ここまで私たちの取り組んだ、システム開発の負債解消についてまとめました。
改めてやってきたことをざっくり書くと、
モノリシック
→ よく使う機能を素早くリリースするため、マイクロサービス化
→ スムーズに要件を詰めるため、日本に開発チームを立ち上げ
→ 自分たちでやることを減らすため、クラウド化
という流れ。やろうとしていることはそう珍しくないことだと思います。
ただ、その裏では色々な出来事や課題があり、それに対してどう立ち向かってきたかの背景がなんとなく伝わったのではないでしょうか?
純粋に「いいものを作るために改善していきたい!」と言っても、ゲームの世界のように全部壊してすぐ作り直し!とはいかないです。改善を進めるための泥臭くやるべきことを捉え、実行していく必要があります。そのために、色々な組織が日々頭を悩ませながら改善に取り組んでいるわけです。
普段皆さんがこのサービスイケてないなと思うようなシステムがあったとしても、実は「ああ、裏で色々なことがあるんだろうなー」と思いながらHRTを忘れずに見てみると、新たな気付きがあるかもしれませんね。
参考
記事
「技術的負債とはどういうものなのか?」をテトリスに例えるとこうなる
プロジェクトの本質とはなにか (不確実性のコーンを引用)
書籍
入門監視 初版 (監視の話で少しだけ登場)