ナレッジベースとは
Amazon Bedrock のナレッジベースでは、データソースを情報のリポジトリにまとめることができます。ナレッジベースを使用すると、検索拡張生成 (RAG) を活用したアプリケーションを簡単に構築できます。RAG は、データソースから情報を取得することでモデルレスポンスの生成を強化する手法です。設定後、ナレッジベースは次のように活用できます。
・RetrieveAndGenerate API を使用してナレッジベースをクエリし、取得した情報からレスポンスを生成するように RAG アプリケーションを設定します。
・ナレッジベースをエージェントに関連付けて (詳細については、「Agents for Amazon Bedrock」を参照) エージェントに RAG 機能を追加し、エージェントがエンドユーザーを支援するための手順を推論できるように支援する。
・Retrieve API を使用してアプリケーション内にカスタムオーケストレーションフローを作成し、ナレッジベースから直接情報を取得する。
ナレッジベースは、ユーザーのクエリに答えるだけでなく、プロンプトにコンテキストを提供することで基盤モデルに提供されるプロンプトを強化するためにも使用できます。ナレッジベースのレスポンスには引用も付いているため、ユーザーはレスポンスの基になっているテキストを正確に調べることで詳細な情報を見つけたり、そのレスポンスが意味のあるもので事実に基づく正確なものかどうかを確認したりできます。
う~ん。RAGを簡単に構築できそうなサービス?くらいしか分からない・・・
Bedrock+Kendraと何が違うんだろう・・・
ちゃんと調べてみよう。
いきなりまとめ
ポイントはこちら!
1.前処理の自動化
データソースを埋め込み基盤モデルでベクトル変換してベクトルデータベースへ格納してくれる
2.RAG検索の精度向上
質問内容を埋め込み基盤モデルでベクトル変換してベクトルデータベースを検索してくれる
詳細を解説します。
「1.前処理の自動化」
以下の図は、ベクトルデータベース用のデータの前処理を表しています。
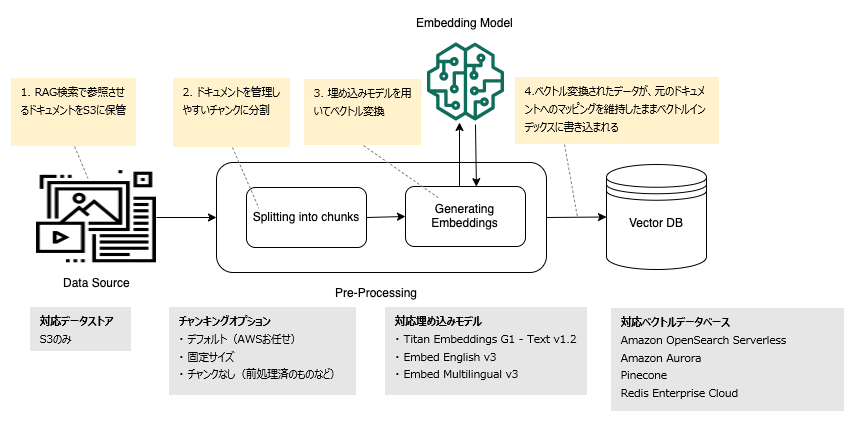
※記載内容は2024/3/21時点のものです。
ナレッジベースが、データソースをチャンキングして埋め込み基盤モデルでベクトル変換してベクトルデータベースへ格納してくれます。
対応ドキュメントの形式は以下の通り。
| 拡張子 |
|---|
| .txt |
| .md |
| .html |
| .doc/.docx |
| .csv |
| .xls/.xlsx |
「2.RAG検索の精度向上」
以下の図は、RAG が実行時にどのように動作してユーザークエリへのレスポンスを補強するかを示しています。
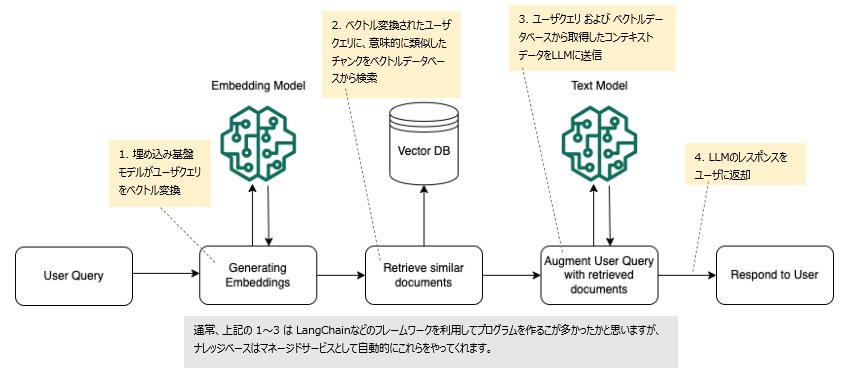
※記載内容は2024/3/21時点のものです。
なお、ベクトルデータベースを検索する際の検索オプションがあります。
・デフォルト – Amazon Bedrock が検索戦略を決定します。
・Hybrid – ベクトル埋め込みの検索 (セマンティック検索) と raw テキストの検索を組み合わせることができます。現在、ハイブリッド検索は、フィルター可能なテキストフィールドを含む Amazon OpenSearch Serverless ベクトルストアでのみサポートされています。別のベクトルストアを使用するか、Amazon OpenSearch Serverless ベクトルストアにフィルター可能なテキストフィールドが含まれていない場合、クエリはセマンティック検索を使用します。
・セマンティック - ベクトル埋め込みのみを検索します。
最後に
Kendraのように、多種多様なデータソースとのコネクタは無いにしても、
簡単かつ高速にRAGアプリを構築するためには非常に有用なサービスだと認識しました。
次回?はナレッジベースを実際に利用してみようと思います。
※間違いなどあれば、ご指摘いただけると助かります。