ナレッジベースとは
Amazon Bedrock のナレッジベースについてはこちらにまとめているので、良かったら見てください。
今回やること
コンソールからナレッジベースを作成してテスト実行してみます。
※次の記事でAPIを利用してテストしてみようと思います
ナレッジベースをコンソールから使ってみる
さっそくコンソールからナレッジベースを作成してみます。
事前準備(RAG用のデータソース準備)
以下の図は、ベクトルデータベース用のデータの前処理を表しています。
赤枠の部分にあたる、RAG用のデータソースをS3に配置します。
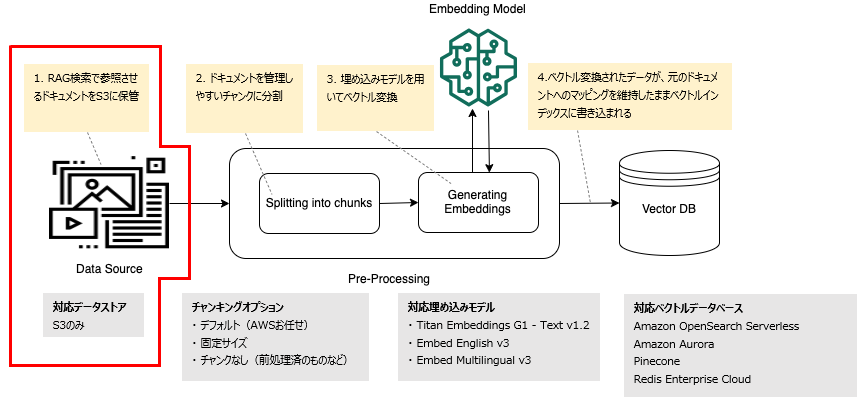
今回は Bedrcok のAPIリファレンス(PDF)を配置して検証してみます。
・Bedrcok APIリファレンス

ステップ0.Bedrock のナレッジベースを作成
2024/03/22時点で 利用可能なリージョン は以下の2つです。今回はUS Eastを利用します。

Bedrockの左ペイン[ナレッジベース]を選択した後、画面中央の右側にある「ナレッジベース作成」をクリック。

ステップ1.ナレッジベース詳細入力
名称やIAM許可等、適切に指定してあげてください。
今回はデフォルトのままで「次へ」をクリック。

ステップ2.データソースを設定
名称は適切に指定してあげてください。
S3 URIに事前準備で用意したS3バケットを指定します。
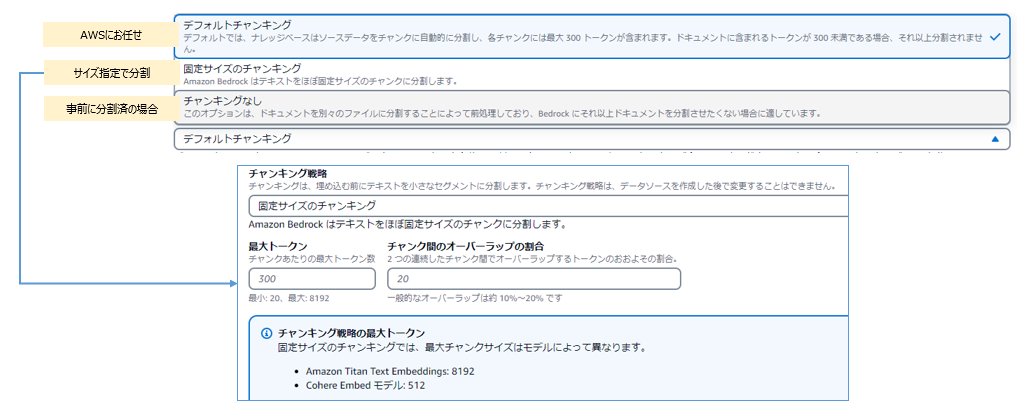
「▼詳細設定-オプション」を開くと、KMSキーとチャンキング戦略のオプションを指定できます。
今回はデフォルトのままで「次へ」をクリック。

※参考(チャンキング戦略で指定可能なオプション)
以下図の赤枠の部分にあたります。
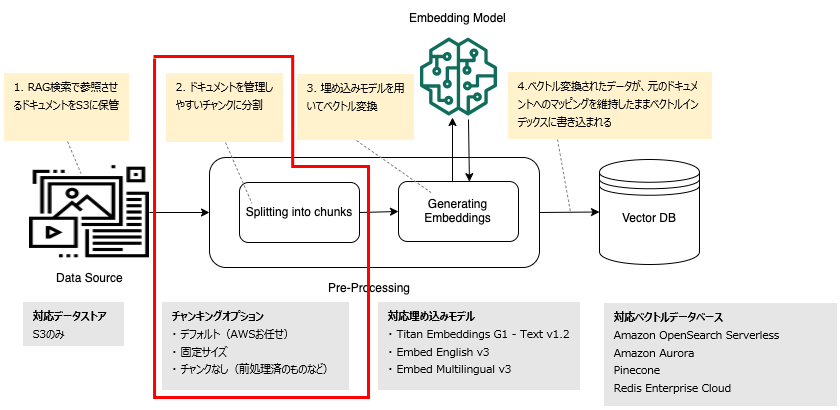
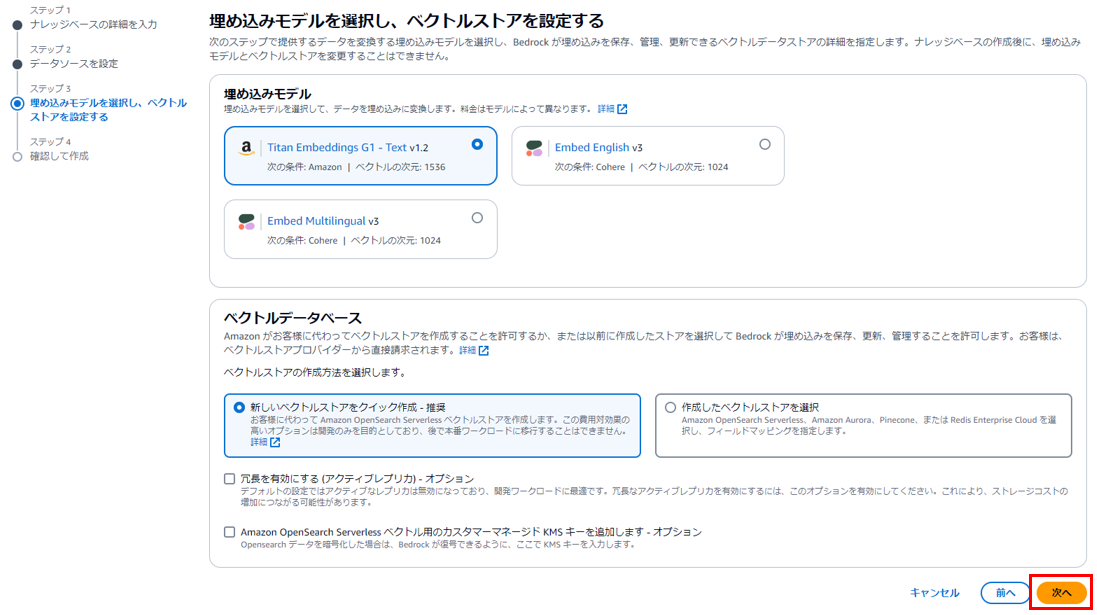
ステップ3.埋め込みモデルを選択し、ベクトルストアを設定する
以下図の赤枠部分にあたります。
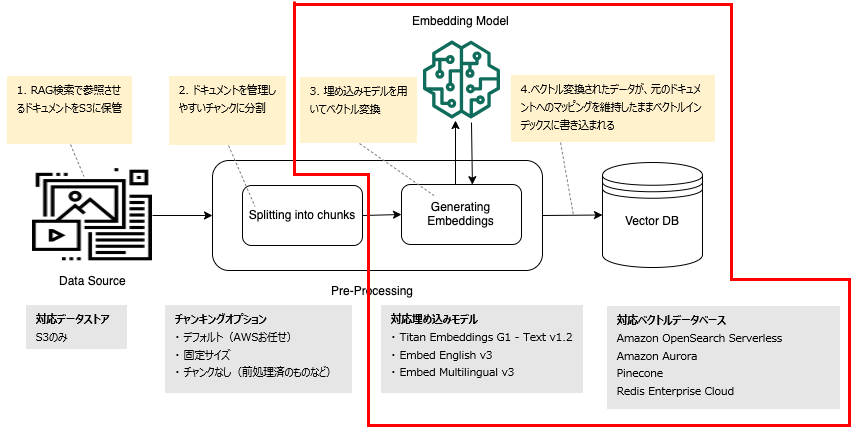
埋め込みモデルは以下3つから選択できます。
・Amazon Titan Embeddings G1 - Text v1.2
・Cohere Embed English v3 (英語テキストのみを対象)
・Cohere Embed Multilingual v3(多言語対応)
ベクトルデータベースは新規作成or作成済のものを選択することができます。
今回はデフォルトのままで「次へ」をクリック。
※補足
「新しいベクトルストアをクイック作成 - 推奨」を選択した場合は、Amazon OpenSearch Serverless 用ベクトルエンジンが使用されます。AuroraやPinecone、Redis Enterprise Cloudを利用する場合は事前にベクトルデータベースを作成しておく必要があります。

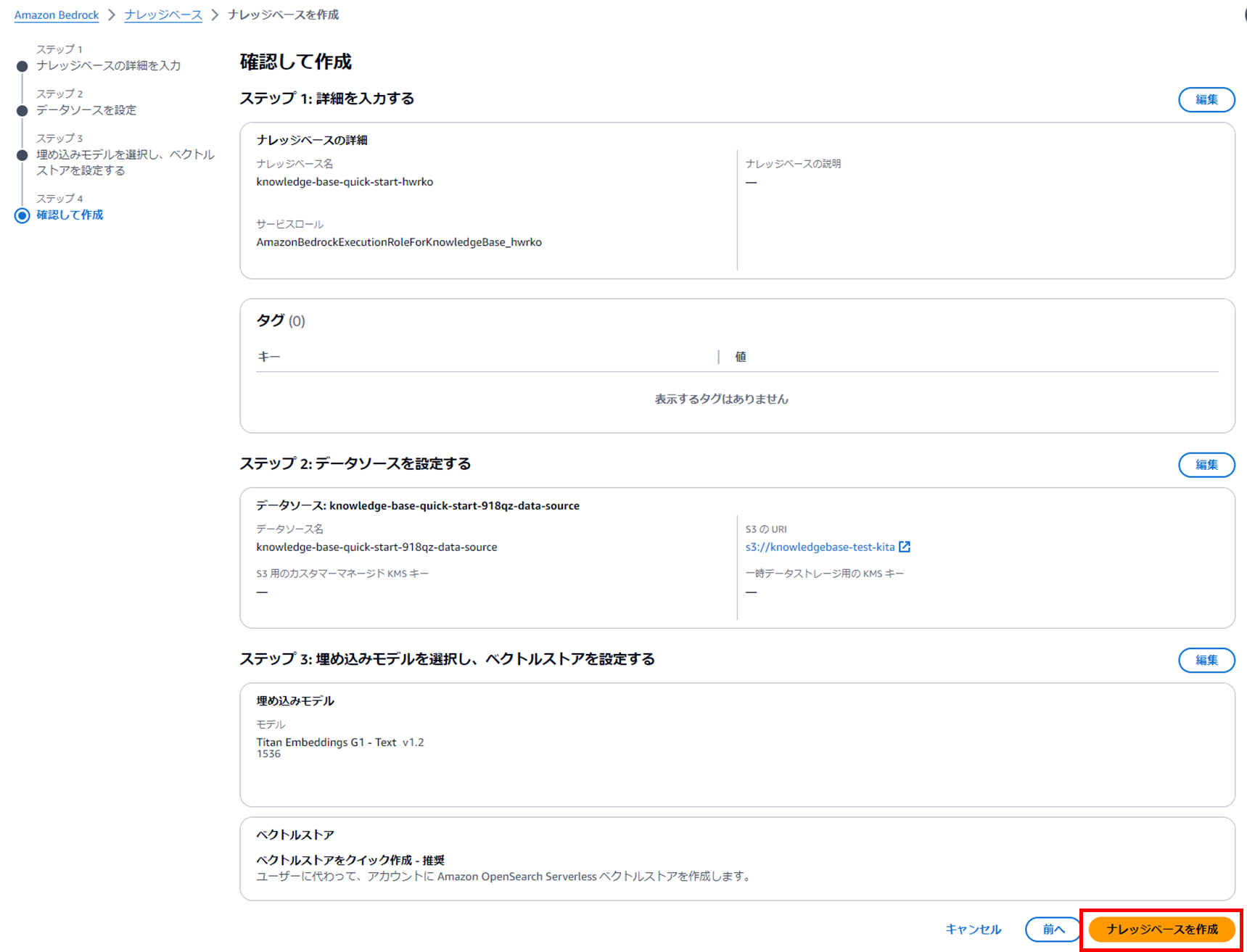
ステップ4.確認
確認して「ナレッジベースを作成」をクリック。
1分程度で作成が完了します。
完了したら、「データソースを同期」をクリックします。
今回は同期に5分程度かかりました。
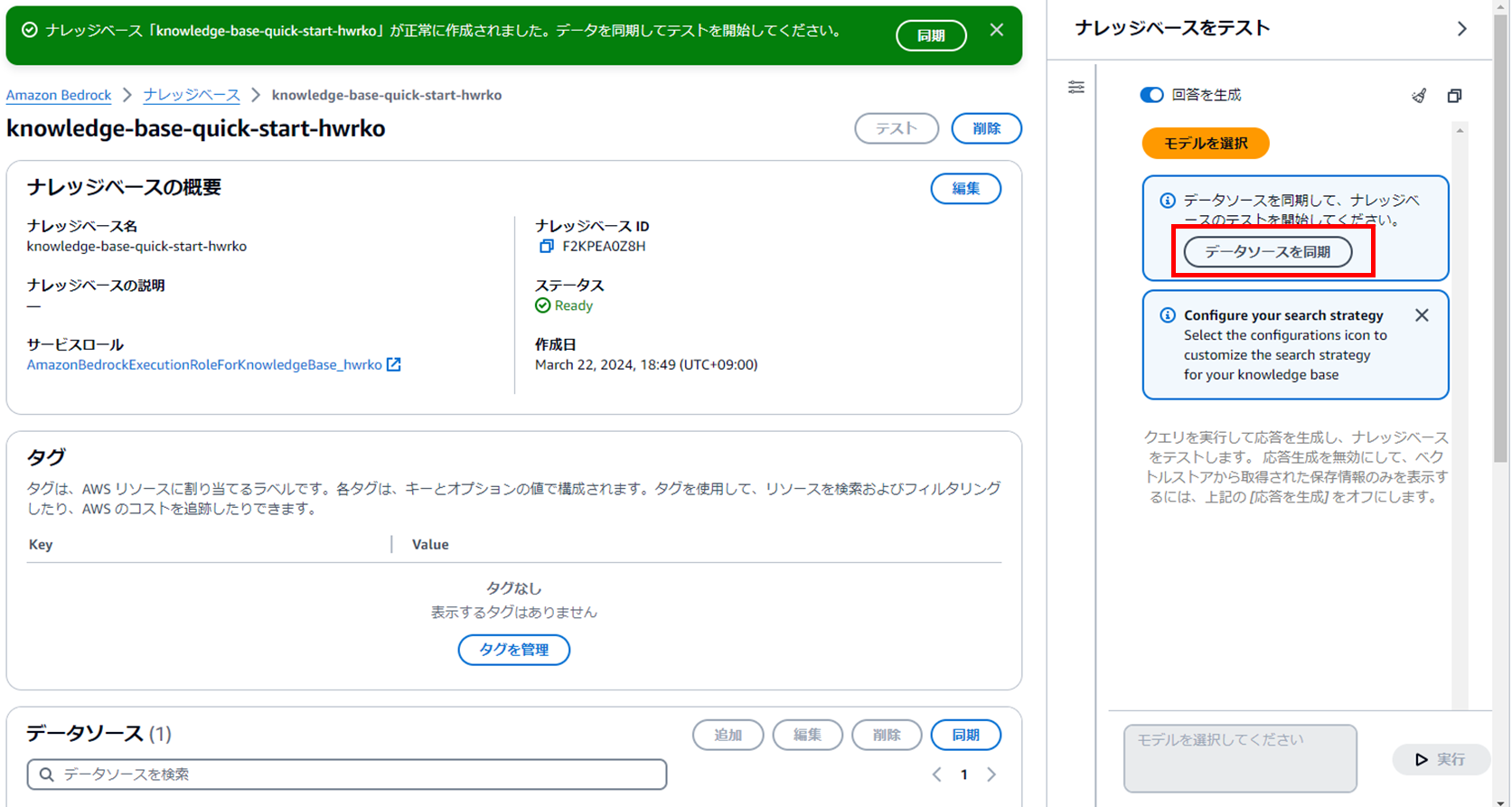
ナレッジベースをテストしてみる
画面右側でテストができます。
が、小さくて使いづらいので赤枠で囲んだ部分をクリックすると大きくなります。

テストをする時に検索タイプと基盤モデルを選択します。
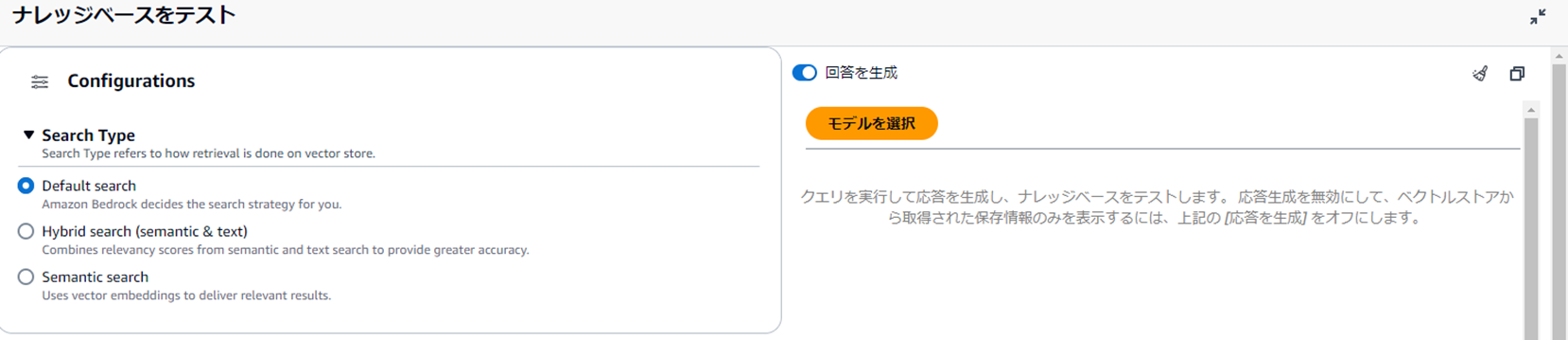
検索タイプ
・デフォルト : Amazon Bedrock が検索戦略を決定
・ハイブリット : ベクトル埋め込みの検索 (セマンティック検索) と raw テキストの検索を組み合わせることが可能(Amazon OpenSearch Serverless ベクトルストアでのみサポート)
・セマンティック : ベクトル埋め込みのみを検索
コンソール上で利用可能な基盤モデルは以下の通りです。
※利用可能なモデルが少ないので、今後のアップデートに期待ですね。
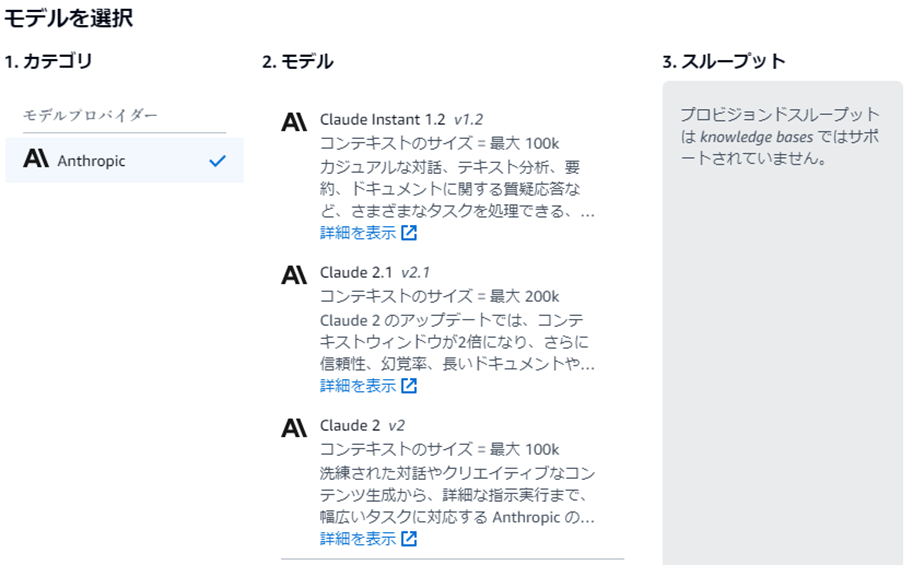
あれ?!最初に基盤モデルって選択した気がしたけど・・・
と思った方もいるのではないでしょうか?(私がそうですw)
最初に指定したのは、ベクトルデータベースとのやり取りを担うものです。
今回指定する基盤モデルは以下図の赤枠の部分で、ユーザクエリ+ナレッジベース取得結果に基づいて応答を生成するためのものです。

Claude Instantを利用してやってみました。
BedrockのAPIリファレンスを参照して正しい回答を出してくれました。

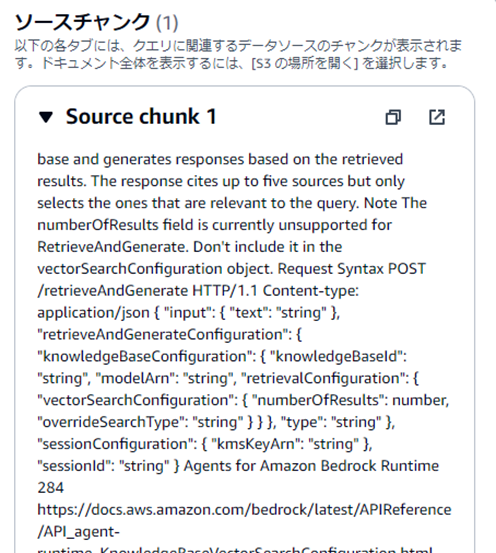
「結果の詳細を表示」をクリックすると、関連するデータソースのチャンクを表示してくれます。(最大5件表示されるようです)
注意点
ナレッジベースを削除しても、ベクトルデータベースは自動的に削除されません。
検証目的で作られた方は、忘れずにベクトルデータベースを手動で削除するようにしましょう。(結構料金掛かります)
最後に
さすがAWSといった感じで、簡単にRAGアプリが作れそうですね。
早く東京リージョンに来てほしいと願うばかりです。
次回はAPIからテストしてみます。
※間違いなどあれば、ご指摘いただけると助かります。