リバースエンジニアリングへの道
出田 守です。
最近、情報セキュリティに興味を持ち、『リバースエンジニアリング-Pythonによるバイナリ解析技法』という本(以降、「教科書」と呼びます)を読みました。
「こんな世界があるのか!かっこいい!」と感動し、私も触れてみたいということでド素人からリバースエンジニアリングができるまでを書いていきたいと思います。
ちなみに、教科書ではPython言語が使用されているので私もPython言語を使用しています。
ここを見ていただいた諸先輩方からの意見をお待ちしております。
軌跡
環境
OS: Windows10 64bit Home (日本語)
CPU: Intel® Core™ i3-6006U CPU @ 2.00GHz × 1
メモリ: 2048MB
Python: 3.6.5
私の環境は、普段Ubuntu16.04を使っていますが、ここではWindows10 64bitを仮想マシン上で立ち上げております。
ちなみに教科書では、Windowsの32bitで紹介されています。
Intel Deveroper's Manual [1] Chapter9 - Chapter10
現在CPU周りの知識をつけるために『Intel Software Developer's Manual(IDMと呼びます)』をさっくりまとめています。
前回はIDMのChapter8までをまとめました。なお、画像は全てIDMより掲載しています。
今回はChapter9 - Chapter10までをまとめます。
CHAPTER 9 PROGRAMMING WITH INTEL® MMXTM TECHNOLOGY
Intel MMXテクノロジはPentium ⅡプロセッサとMMXテクノロジをサポートするPentiumプロセッサのIA-32アーキテクチャに導入されました。MMXテクノロジが導入された拡張機能は単一命令、高度なメディアとアプリケーション通信のパフォーマンスを向上するために設計されたマルチデータ(SIMD)実行モデルをサポートします。
9.1 OVERVIEW OF MMX TECHNOLOGY
MMXテクノロジはシンプルで柔軟なパックされた64bit整数データを扱うためのSIMD拡張モデルを定義します。このモデルは、すべてのIA-32アプリケーションおよびオペレーティングシステムコードとの下位互換性を維持しながら、IA-32アーキテクチャーに以下の機能を追加します。
- MMXレジスタと呼ばれる8つの新しい64bitデータレジスタ
- 3つの新しいパックされたデータ型:
- 64bitのパックされたByte整数(符号付きおよび符号なし)
- 64bitのパックされたWord整数(符号付きおよび符号なし)
- 64bitのパックされたDword整数(符号付きおよび符号なし)
- 新しいデータ型をサポートし、MMX状態管理を処理するための命令
- CPUID命令の拡張
MMXテクノロジは全てのIA-32アーキテクチャ実行モード(protectedモード、real-addressモード、virtual 8086モード)で利用可能です。アーキテクチャに新しいモードを追加しません。
9.2 THE MMX TECHNOLOGY PROGRAMMING ENVIRONMENT
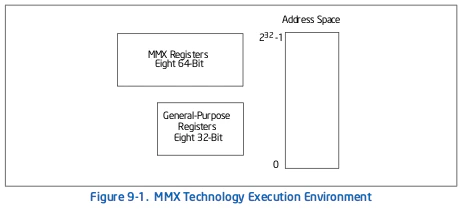
図9-1はMMXテクノロジの実行環境を表しています。全てのMMX命令はMMXレジスタ、汎用レジスタ、と/またはメモリを操作します。
- MMXレジスタ
これらの8つのレジスタは64bitのパックされた整数データを操作するために使用されます。 - 汎用レジスタ
8つの汎用レジスタ(図3-5参照)は、既存のIA-32アドレッシングモードで使用され、メモリ内のオペランドをアドレス指定します(MMXレジスタはメモリのアドレス指定に使用できません)。汎用レジスタは一部のMMX命令操作のオペランドを保持するためにも使用されます。
9.2.1 MMX Technology in 64-Bit Mode and Compatibility Mode
互換モードと64bitモードではMMX命令は保護モードのように機能します。メモリ操作はSection3.7.5で説明したModR/M, SIBを使って指定されます。
9.2.2 MMX Registers
MMXレジスタは8つの64bitレジスタを構成し(図9-2参照)、MMXパックされた整数データ型に対して計算を実行します。MMXレジスタの値はメモリの64bitと同じ形式をもちます。
MMXレジスタには64bitアクセスモードと32bitアクセスモードという2つのデータアクセスモードがあります。
64bitモードは次の目的で使用されます。
- 64bitのメモリアクセス
- 64bitのMMXレジスタ間転送
- 全てのパック命令、論理命令、算術命令
- いくつかのアンパック命令
32bitモードは次の目的で使用されます。
- 32bitのメモリアクセス
- 32bitの汎用レジスタとMMXレジスタ間転送
- いくつかのアンパック命令

MMXレジスタはIA-32アーキテクチャでは別々のレジスタとして定義されていますが、FPUデータレジスタスタック(R0〜R7)のレジスタにエイリアスされています。
9.2.3 MMX Data Types
MMXテクノロジはIA-32アーキテクチャの64bitデータ型として以下を導入しています。
- 64bitのパックされたByte整数-8のパックされたByte
- 64bitのパックされたWord整数-4のパックされたWord
- 64bitのパックされたDword整数-2のパックされたDword
MMX命令は64bitデータ型(パックされたByte, パックされたWord, パックされたDword)あるいはQwordデータ型を、MMXレジスタとメモリ間または64bitブロックのMMXレジスタ間で移動します。しかし、パックされたデータ型に対して算術演算または論理演算を行うとき、MMX命令はMMXレジスタに含まれる個別のByte, Word, Dwordを並列に実行します(Section 9.2.5参照)。

9.2.4 Memory Data Formats
メモリに格納するとき、パックされたデータ型(Byte, WOrd, Dword)は連続的なアドレスに格納されます。最下位Byte, Word, Dwordは最下位アドレスに格納され、最上位Byte, Word, Dwordは上位アドレスに格納されます。メモリ内のByte, Word, Dwordの順序は、常にリトルエンディアンです。
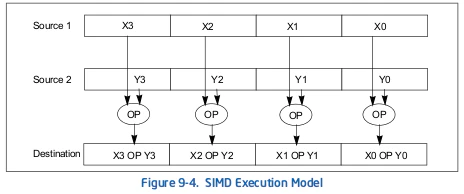
9.2.5 Single Instruction, Multiple Data (SIMD) Execution Model
MMXテクノロジは、MMXレジスタにパックされたByte, Word, Dwordの算術演算と論理演算を実行するための単一命令、複数データ(SIMD)技術を使用します(図9-4参照)。たとえば、PADDSW命令は、1つのソースオペランドからの4つの符号付きWord整数を第2のソースオペランドの4つの符号付きWord整数に加算し、4 Wordの整数結果を宛先オペランドに格納します。このSIMD技術は、複数のデータ要素に対して同じ操作を並行して実行できるようにすることで、ソフトウェアのパフォーマンスを向上させます。 MMXテクノロジは、MMXレジスタに格納されている場合、Byte, Word, Dwordのデータ要素に対する並列処理をサポートします。
MMXテクノロジでサポートされているSIMD実行モデルは、多数の小さなデータ型(Byte, Word, Dword)で同じ操作を実行する高度なアルゴリズムを頻繁に使用する最新のメディア、通信、グラフィックスアプリケーションのニーズに直接対応します。例えば、ほとんどのオーディオデータは16ビット(Word)量で表されます。MMX命令は、1命令で4ワード同時に動作することができます。ビデオおよびグラフィックス情報は、一般にパレタイズされた8ビット(Byte)の量として表されます。図9-4では、1つのMMX命令が同時に8バイトで動作します。
9.3 SATURATION AND WRAPAROUND MODES
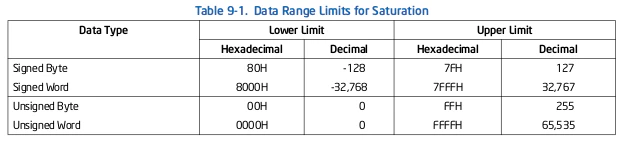
整数演算を実行すると、演算結果が範囲外の状態になることがあります。真の結果は宛先フォーマットで表現できません。たとえば、符号付きWord整数に対して算術演算を実行する場合、真の符号付き結果が16ビットより大きい場合に、正のオーバーフローが発生する可能性があります。
MMXテクノロジは、範囲外の条件を処理する3つの方法を提供します。
- Wraparound arithmetic
ラップアラウンド演算では、真の範囲外結果が切り捨てられます(つまり、キャリーbitまたはオーバーフローbitは無視され、結果の最下位bitのみが宛先に返されます)。ラップアラウンド演算は、範囲外の結果を防ぐためにオペランドの範囲を制御するアプリケーションに適しています。ただし、オペランドの範囲が制御されない場合、ラップアラウンド演算は大きなエラーにつながります。たとえば、2つの大きな符号付き数値を加算すると、正のオーバーフローが発生し、負の結果が生成されます。 - Signed saturation arithmetic
符号付き飽和演算では、範囲外の結果は、操作されている整数サイズの符号付き整数の表現可能な範囲に制限されます(表9-1を参照)。たとえば、符号付きWord整数で動作するときに正のオーバーフローが発生した場合、結果は16bitで表現できる最大の正の整数である7FFFHまで "飽和"します。負のオーバーフローが発生すると、結果は8000Hに飽和します。 - Unsigned saturation arithmetic
符号なし飽和演算では、範囲外の結果は、整数サイズの符号なし整数の表現可能な範囲に制限されます。したがって、符号なしバイト整数で操作するときの正のオーバーフローの結果、FFHが返され、負のオーバーフローが発生すると00Hが返されます。
飽和演算は、多くのオーバーフローに対する答えを提供します。たとえば、色の計算では、飽和は反転を許さずに純粋な黒または純粋な白色のままにします。また、使用されないソースオペランドの範囲チェック時にラップアラウンドアーティファクトが計算に入るのを防ぎます。
MMX命令は、EFLAGSレジスタに例外またはフラグを生成することによって、オーバーフローまたはアンダーフローの発生を示しません。
9.4 MMX INSTRUCTIONS
MMX命令は47命令で構成され、以下に示すカテゴリに分けられます。
- データ転送
- 算術演算
- 比較
- 変換
- アンパック
- 論理演算
- シフト
- 空のMMX状態命令(EMMS)
テーブル9-2はMMX命令セットの概要を示します。
この章で説明するMMX命令は、CPUID.01H:EDX.MMX[bit 23] = 1のときIA-32プロセッサで利用可能です。

9.4.1 Data Transfer Instructions
MOVD命令はメモリからMMXレジスタあるいはその逆または、汎用レジスタからMMXレジスタあるいはその逆にパックされたデータの32bitを転送します。
MOVQ命令はメモリからMMXレジスタあるいはその逆または、MMXレジスタ間でパックされたデータの64bitを転送します。
9.4.2 Arithmetic Instructions
算術演算命令は加算、減算、乗算、乗算して加算をパックされたデータ型に対して実行します。
PADDB/PADDW/PADDD命令とPSUBB/PSUBW/PSUBD命令はwraparoundモードのソースまたは宛先オペランドの符号付きまたは符号なしデータ要素に対応した加算または減算を行います。
PADDSB/PADDSW命令とPSUBSB/PSUBSW命令は、ソースオペランドおよび宛先オペランドの対応した符号付きデータ要素を加算または減算し、その結果を符号付きデータ型範囲の制限に飽和させます。これらの命令は、パックされたByteとWordのデータ型で動作します。
PADDUSB/PADDUSW命令とPSUBUSB/PSUBUSW命令はソースオペランドおよび宛先オペランドの対応した符号なしデータ要素を加算または減算し、その結果を符号なしデータ型範囲の制限に飽和させます。これらの命令は、パックされたByteとWordのデータ型で動作します。
PMULHW命令とPMULLW命令はソースと宛先オペランドの対応するWordの符号付き乗算を実行し、上位または下位16bitのそれぞれの結果のbitをそれぞれ宛先オペランドに転送します。
PMADDWD命令は、ソースと宛先オペランドの対応する符号付きWordの積を計算します。4つの中間32bitDword積は、ペア(高次のペアと低位のペア)で合計され、2つの32bitのDword結果を生成します。
9.4.3 Comparison Instructions
PCMPEQB/PCMPEQW/PCMPEQD命令とPCMPGTB/PCMPGTW/PCMPGTD命令はソースまたは宛先オペランドの符号付きデータ要素(Byte, Word, Dword)に対応したそれぞれ等しいまたはそれ以上の比較を行います。
これらの命令は、宛先オペランドに書き込まれる1または0のマスクを生成します。論理演算では、マスクを使用してパックされた要素を選択できます。これは、分岐または分岐命令のセットなしで、パックされた条件付き移動操作を実装するために使用できます。EFLAGSレジスタのフラグは影響を受けません。
9.4.4 Conversion Instructions
PACKSSWB命令とPACKSSDW命令は符号付きWordを符号付きDwordに符号付きDwordを符号付き飽和を使って符号付きWordにそれぞれ変換します。
PACKUSWB命令は符号付きWordを符号なし飽和を使って符号なしByteに変換します。
9.4.5 Unpack Instructions
PUNPCKHBW/PUNPCKHWD/PUNPCKHDQ命令とPUNPCKLBW/PUNPCKLWD/PUNPCKLDQ命令は、Byte、Word、Dwordを上位または下位のデータ要素からアンパックします。ソースオペランドと宛先オペランドに挿入し、それらを宛先オペランドにインターリーブします。すべての0をソースオペランドに配置することにより、これらの命令を使用して、Byte整数をWord整数、Word整数からDword整数、Dword整数からQword整数に変換することができます。
9.4.6 Logical Instructions
PAND命令、PANDN命令、POR命令、PXOR命令はソースと宛先オペランドに対してbit毎の論理演算を実行します。
9.4.7 Shift Instructions
論理左シフト命令、論理右シフト命令、算術左シフト命令、算術右シフト命令は指定されたbit位置の数の分だけ各要素をシフトします。
PSLLW/PSLLD/PSLLQ命令とPSRLW/PSRLD/PSRLQ命令はデータ要素の論理左シフトまたは論理右シフトを実行し、空の上位または下位のbitをゼロで埋めます。これらの命令はパックされたWord, Dword, Qwordに対して操作します。
PSRAW/PSRAD命令は算術右シフトを実行し、各データ要素の符号bitを各データ要素の上端の空bit位置にコピーします。この命令はパックされたWordとDwordに対して操作します。
9.4.8 EMMS Instruction
EMMS命令は、x87 FPUタグワード内のタグを11Bに設定することによってMMX状態を空にし、空のレジスタを示します。この命令は、浮動小数点命令を実行できる他のルーチンを呼び出す前に、MMXルーチンの最後に実行する必要があります。この命令の使用方法の詳細は、Section 9.6.3を参照してください。
9.5 COMPATIBILITY WITH X87 FPU ARCHITECTURE
MMX状態はx87 FPU状態にエイリアスされます。MMXテクノロジをサポートするために、IA-32アーキテクチャに新しい状態やモードが追加されていません。x87 FPU状態を保存および復元する同じ浮動小数点命令もMMX状態を処理します(たとえば、コンテキスト切り替え中)。
9.5.1 MMX Instructions and the x87 FPU Tag Word
各MMX命令の後、x87 FPUタグワード全体が有効(00B)に設定されます。EMMS命令(空のMMX状態)は、x87 FPUタグワード全体を空にします(11B)。
9.6 WRITING APPLICATIONS WITH MMX CODE
以下の節からはMMXテクノロジを使ってアプリケーションコードを書くためのガイドラインを紹介します。
9.6.1 Checking for MMX Technology Support
MMXテクノロジを使う前に現在のプロセッサが対応しているかチェックすべきです。チェックは以下のステップで出来ます。
- プロセッサがCPUID命令を実行し、CPUID命令をサポートしていることを確認してください。プロセッサがCPUID命令をサポートしていない場合、無効オペコード例外(#UD)が生成されます。
- プロセッサがMMXテクノロジをサポートしていることを確認します(CPUID.01H:EDX.MMX [ビット23] = 1の場合)。
- x87 FPUのエミュレーションが無効になっていることを確認します(CR0.EM [bit2] = 0の場合)。
プロセッサがサポートされていないMMX命令を実行しようとした場合、またはCR0.EM [ビット2]がセットされたMMX命令を実行しようとすると、無効オペコード例外(#UD)が生成されます。
例9-1はCPUID命令を使用してMMXテクノロジを検出する方法です。この例は、CPUIDシーケンス全体を表すのではなく、MMXテクノロジの検出に使用される部分を示しています。
Example 9-1. Partial Routine for Detecting MMX Technology with the CPUID Instruction
... ; identify existence of CPUID instruction
... ; identify Intel processor
mov EAX, 1 ; request for feature flags
CPUID ; 0FH, 0A2H CPUID instruction
test EDX, 00800000H ; Is IA MMX technology bit (Bit 23 of EDX) set?
jnz ; MMX_Technology_Found
9.6.2 Transitions Between x87 FPU and MMX Code
アプリケーションはX87 FPU浮動小数点とMMX命令両方を含めることが出来ます。しかし、MMXレジスタはx87FPU レジスタスタックにエイリアスされているため、予期しないincoherentまたは結果を防ぐため、x87 FPU命令とMMX命令の間で遷移を行うときは注意が必要です。
(EMMS命令以外の)MMX命令が実行されたときプロセッサはx87 FPU状態を以下のように変更します。
- x87 FPU状態のTOS(スタックの先頭)値を0にセット
- 完全なx87 FPUタグワードを無効な状態(全てのタグ領域を00b)へセット
- MMX命令がMMXレジスタに書き込むとき、対応する浮動小数点レジスタの指数部(bit 64-79)に1を書き込みます(11B)。
これらの動作の最終的な結果は、MMX命令の実行前のx87 FPU状態が本質的に失われることです。
x87 FPU命令が実行されると、プロセッサはx87 FPUレジスタスタックおよび制御レジスタの現在の状態が有効であるとみなし、x87 FPU状態の予備修正なしに命令を実行します。
アプリケーションにx87 FPU浮動小数点命令とMMX命令の両方が含まれている場合は、次のガイドラインを推奨します。
- x87 FPUとMMXコードの間で移行する場合、将来の使用のために保存する必要のあるx87 FPUデータまたは制御レジスタの状態を保存します。FSAVEおよびFXSAVE命令は、x87 FPUの状態全体を保存します。
- MMXとx87 FPUコード間を移行するときは、次の操作を行います。
- 将来の使用のために保存する必要のあるデータをMMXレジスタに保存します。FSAVEとFXSAVEはMMXレジスタの状態も保存します。
- EMMS命令を実行して、x87データおよび制御レジスタからMMX状態をクリアします。
次のセクションでは、EMMS命令の使用法について説明し、x87 FPUとMMXコードを混在させるための追加ガイドラインを示します。
9.6.3 Using the EMMS Instruction
Section 9.6.2で説明したように、MMX命令が実行されると、x87 FPUタグワードは有効(00B)とマークされます。この状態では、x87 FPUレジスタスタックに有効なデータが含まれているように見えるため、後続のx87 FPU命令を実行すると、予期しないx87 FPU浮動小数点例外や誤った結果が生じる可能性があります。x87 FPUタグワードを空とマークすることにより、この問題を防ぐためにEMMS命令が提供されています。
EMMS命令は、次の場合に使用する必要があります。
- x87 FPU命令を使用するアプリケーションがMMXテクノロジライブラリ/DLL(MMX命令の最後にEMMS命令を使用)を呼び出す場合
- MMX命令を使用するアプリケーションがx87 FPU浮動小数点ライブラリ/DLL(x87 FPUコード命令を呼び出す前にEMMS命令を使用)
- x87 FPUコードよりも前に実行されるMMX命令が確実に存在しない限り、タスクまたはスレッド内のMMXコードと協調オペレーティングシステム内の他のタスクまたはスレッドとの間で切り替えが行われます。
9.6.4 Mixing MMX and x87 FPU Instructions
アプリケーションには、x87 FPU浮動小数点命令とMMX命令の両方を含めることができます。ただし、MMX命令とx87 FPU命令の間の頻繁な移行は、一部のプロセッサ実装ではパフォーマンスが低下する可能性があるため、お勧めできません。MMXコードとx87 FPUコードを混在させる場合は、次のガイドラインに従ってください。
- コードを別々のモジュール、プロシージャ、またはルーチンに保管してください。
- x87 FPUとMMXコードモジュールの間のトランジションでレジスタの内容に依存しないでください。
- MMXコードとx87 FPUコード間で移行するとき、(もし将来的に必要なら)MMXレジスタ状態を保存し、MMX状態を空にするためにEMMS命令を実行します。
- x87 FPUコードとMMXコード間で移行するとき、(もし将来的に必要なら)x87 FPU状態を保存します。
9.6.5 Interfacing with MMX Code
MMXテクノロジはMMXレジスタに直接アクセスできます。これは、プロセッサの汎用レジスタ(EAX、EBXなど)の使用に適用されるすべての既存のインタフェース規約が、MMXレジスタの使用にも適用されることを意味します。
MMXルーチンへの効率的なインタフェースは、MMXレジスタを介して、または(スタックを介した)メモリ位置とMMXレジスタの組み合わせによって、パラメータと戻り値を渡すことがあります。MMXレジスタを使用してパラメータを渡す場合は、EMMS命令を使用しないでください、またはMMXとx87 FPUコードを混在させないでください。
MMXデータ型を直接サポートしない高水準言語が使用されている場合、MMXデータ型は、パックされたデータ型を含む64ビット構造体として定義できます。
高水準言語でMMX命令を実装する場合は、次のような方法があります。
- スタックを介して構造体にポインタを渡すことによって、MMXルーチンにパラメータを渡す。
- 構造体へのポインタを返すことによって関数から値を返す。
9.6.6 Using MMX Code in a Multitasking Operating System Environment
アプリケーションは、そのアプリケーションが動作するマルチタスキングオペレーティングシステムの性質を識別する必要があります。各タスクは、タスクスイッチが発生したときに保存する必要がある独自の状態を保持します。プロセッサの状態(コンテキスト)は、汎用レジスタと浮動小数点およびMMXレジスタで構成されます。
オペレーティングシステムは、2つのタイプに分類することができます。
- 協調マルチタスクオペレーティングシステム
- プリエンプティブマルチタスクオペレーティングシステム
協調マルチタスキングオペレーティングシステムは、コンテキストスイッチを実行するときにFPUまたはMMX状態を保存しません。
したがって、アプリケーションは、オペレーティングシステムへの直接的または間接的な制御を放棄する前に、関連する状態を保存する必要があります。
プリエンプティブマルチタスキングオペレーティングシステムは、コンテキスト切り替えを実行するときにFPUおよびMMX状態の保存と復元を行います。したがって、アプリケーションはFPUおよびMMX状態を保存または復元する必要はありません。
9.6.7 Exception Handling in MMX Code
MMX命令は、他のIA-32命令(page fault, segment not present, and limit violations)と同じタイプのメモリアクセス例外を生成します。既存の例外ハンドラは、MMXコードのこれらのタイプの例外を処理するために変更する必要はありません。
保留中の浮動小数点例外がない限り、MMX命令は数値例外を生成しません。したがって、既存の例外ハンドラを変更するか、数値例外を処理するために新しい例外ハンドラを追加する必要はありません。
浮動小数点例外が保留中の場合、後続のMMX命令は数値エラー例外(割り込み16および/またはFERR#ピンのアサーション)を生成します。MMX命令は、例外ハンドラからの復帰時に実行を再開します。
9.6.8 Register Mapping
MMXレジスタとこれらのタグは浮動小数点レジスタとタグの物理位置へマップされます。
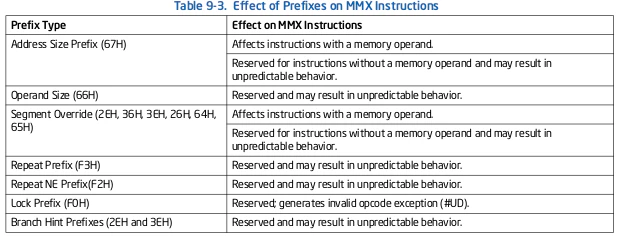
9.6.9 Effect of Instruction Prefixes on MMX Instructions
テーブル9-3はMMX命令で命令プレフィクスの影響を説明しています。予測不可能な動作は、ある世代のIA-32プロセッサ上で予約されたオペレーションとして処理されることから、別の世代のプロセッサ上で無効なオペコード例外を生成することまであります。
Chapter9まとめ
- 9章はMMXテクノロジの概要を説明
- MMXレジスタ、MMX命令、MMX命令で操作するデータ型が用意されている
- MMX命令とx87 FPU命令を同時に使う際は注意が必要
CHAPTER 10 PROGRAMMING WITH INTEL STREAMING SIMD EXTENSIONS(INTEL SSE)
Streaming SIMD extensions(SSE)はPentium ⅢプロセッサファミリのIA-32アーキテクチャに導入されました。これらの拡張は高度な2-D画像と3-D画像、モーションビデオ、画像処理、音声認識、音声合成、テレフォニー、ビデオ会議においてIA-32プロセッサのパフォーマンスを強化します。
10.1 OVERVIEW OF SSE EXTENSIONS
MMXテクノロジは、64bit MMXレジスタ、64bitのパックされた整数データ型、パックされた整数でSIMD演算を実行できる命令を備えたIA-32アーキテクチャにSIMD(single-instruction multiple-data)機能を導入しました。SSE拡張は、128bitレジスタに含まれるパックされたスカラー単精度浮動小数点値を処理するための機能を追加することによって、SIMD実行モデルを拡張します。
CPUID.01H:EDX.SSE [bit 25] = 1の場合、SSE拡張が存在します。
SSE拡張は全ての既存のIA-32プロセッサ、アプリケーション、OSの後方互換性を維持しつつ、IA-32アーキテクチャへ次の機能を追加します。
- 非64bitモードで8つの128bitデータレジスタ(XMMレジスタと呼ばれます)、64bitモードでは16の128bitデータレジスタ
- XMMレジスタで実行される操作の制御bitとステータスbitを提供する32bit MXCSRレジスタ
- 単精度浮動小数点に対してSIMD操作を実行する命令と、整数に対して実行できる拡張SIMD操作
- MMXレジスタでデータ位置を操作するための128bitのパックされた命令、あるいは単精度浮動小数点命令
- MMXレジスタでパックされた整数オペランドの位置に対して追加操作をサポートする64bit SIMD整数命令
- MXCSRレジスタの状態を保存あるいは復元する命令
- 明示的なデータのプリフェッチ、データのキャッシュ制御、ストア操作の順序の制御をサポートする命令
- CPUID命令の拡張
これらの機能は4つの重要な方法でIA-32アーキテクチャのSIMDプログラミングモデルを拡張します。
- 4つのパックされた単精度浮動小数点値でSIMD演算を実行する能力により、計算量の多いアルゴリズムを使用して単純なネイティブデータ要素の大規模な配列に対して繰り返し演算を実行する高度なメディアおよび通信アプリケーション向けのIA-32プロセッサのパフォーマンスが向上します。
- MMXレジスタのSIMD単精度浮動小数点演算をXMMレジスタおよびSIMD整数演算で実行できるため、大規模な浮動小数点および整数データ配列で動作するアプリケーションを実行する際の柔軟性とスループットが向上します。
- キャッシュ制御命令は、キャッシュを汚染することなく、また実際に使用される前に選択されたキャッシュレベルにデータをプリフェッチする機能を持たずに、XMMレジスタにデータを入出力する機能を提供します。大量のデータへの定期的なアクセスを必要とするアプリケーションでは、これらのプリフェッチおよびストリーミングストア機能が役立ちます。
- SFENCE命令は、weakly-orderedされたメモリタイプを使用するときのストア操作の順序をより詳細に制御します。
SSE拡張は、IA-32プロセッサ用に書かれたすべてのソフトウェアと完全に互換性があります。SSE拡張機能を搭載したプロセッサでは、既存のソフトウェアはすべて修正せずに正しく動作し続けます。CPUIDの拡張により、SSE拡張の検出が可能になりました。SSE拡張は、protectedモード、real-addressモード、virtual-8086モードのすべてのIA-32実行モードからアクセスできます。
10.2 SSE PROGRAMMING ENVIRONMENT
図10-1に、SSE拡張の実行環境を示します。すべてのSSE命令は、次のようにXMMレジスタ、MMXレジスタ、またはメモリ上で動作します。
- XMMレジスタ
8つのレジスタ(図10-2とSection 10.2.2参照)はパックされた単精度浮動小数点データまたはスカラ単精度浮動小数点データに対して操作するために使用されます。スカラ操作はXMMレジスタの下位Dwordに格納された個々の(アンパック)単精度浮動小数点に対して操作を実行します。XMMレジスタはXMM0-7で参照されます。 - MXCSRレジスタ
32bitレジスタ(図10-3とSection 10.2.3を参照)はSIMD浮動小数点操作で使用されるステータスbit、制御bitを提供します。 - MMXレジスタ
8つのレジスタ(図9-2参照)は、64bitのパックされた整数データに対して演算を実行するために使用されます。MMXレジスタとXMMレジスタ間で実行されるオペレーションのオペランドを保持するためにも使用されます。MMXレジスタはMM0-7で参照されます。 - 汎用レジスタ
8つの汎用レジスタ(図3-5参照)はメモリのオペランドをアドレス指定するための既存のIA-32アドレッシングモードと一緒に使用されます(MMXレジスタとXMMレジスタはメモリのアドレス指定で使用することが出来ません)。汎用レジスタはまたいくつかのSSE命令のためのオペランドを保持するために使用され、EAX, EBX, ECX, EDX, EBP, ESI, EDI, ESPとして参照されます。 - EFLAGSレジスタ
この32bitレジスタ(図3-8参照)はいくつかの比較操作の結果を記録するために使用されます。

10.2.1 SSE in 64-Bit Mode and Compatibility Mode
互換モードでは、SSE拡張はprotectedモードと同様に機能します。64bitモードでは、8つの追加XMMレジスタを利用できます。レジスタXMM8-XMM15はREXプレフィクスを使ってアクセスされます。メモリオペランドはSection 3.7.5で説明したModR/M, SIBエンコードを使用して指定されます。
いくつかのSSE命令は汎用レジスタに対して操作するために使用されるかもしれません。REXプレフィクスが意味を持たないときに使用される場合、プレフィクスは無視されることに注意してください。
10.2.2 XMM Registers
8つの128bit XMMデータレジスタはSSE拡張とIA-32アーキテクチャに導入されました(図10-2参照)。これらのレジスタはXMM0-7という名前を使って直接アクセスでき、x87 FPU、MMXレジスタ、汎用レジスタとは独立してアクセスできます(つまり、他のレジスタへエイリアスされていません)。
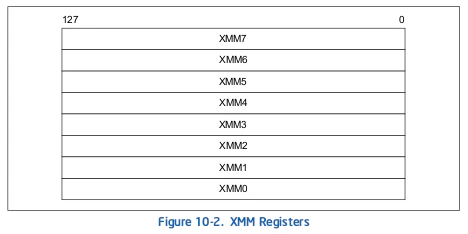
SSE命令はパックされた単精度浮動小数点オペランドに対して操作するためだけにXMMレジスタを使います。SSE2拡張はパックされた倍精度浮動小数点またはスカラ倍精度浮動小数点とパックされた整数オペランドに対してXMMレジスタの機能を拡張します(Section 11.2とSection 12.1参照)。
XMMレジスタはデータに対して計算を実行するためだけに使用されます。ただし、メモリをアドレス指定するためには使用できません。
データはXMMレジスタに読み込むことができ、32bit, 64bit, 128bit単位でレジスタからメモリへ書き込むことができます。XMMレジスタの全内容を(128bit格納)メモリに格納するとき、データは連続的に16Byteに格納され、レジスタの下位Byteはメモリの最初のByteに格納されます。
10.2.3 MXCSR Control and Status Register
2ビットMXCSRレジスタ(図10-3参照)には、SSE、SSE2、およびSSE3 SIMD浮動小数点演算の制御およびステータス情報が含まれています。このレジスタには、
- SIMD浮動小数点例外のフラグとマスクbit
- SIMD浮動小数点演算の丸め制御フィールド
- SIMD浮動小数点演算でアンダーフロー条件を制御する手段を提供するflush-to-zeroフラグ
- SIMD浮動小数点命令がどのようにデノーマルソースオペランドを処理するかを制御するdenormals-are-zeroフラグ
このレジスタの内容は、LDMXCSRおよびFXRSTOR命令を使用してメモリから読み込み、STMXCSRおよびFXSAVEを使用してメモリに格納することができます。
MXCSRレジスタのbit16-31は予約されており、プロセッサのパワーアップまたはリセット時にクリアされます。FXRSTOR命令またはLDMXCSR命令のいずれかを使用してこれらのbitに0以外の値を書き込もうとすると、一般保護例外(#GP)が生成されます。

10.2.3.1 SIMD Floating-Point Mask and Flag Bits
MXCSRレジスタのbit 0-5は、SIMD浮動小数点例外が検出されたかどうかを示します。それらは「sticky」フラグです。すなわち、フラグがセットされた後、フラグは明示的にクリアされるまでセットされたままです。これらのフラグをクリアするには、LDMXCSRまたはFXRSTOR命令を使用してゼロを書き込みます。
bit 7-12は、SIMD浮動小数点例外に対する個々のマスクbitを提供します。例外タイプは、対応するマスクbitが設定されている場合はマスクされ、bitがクリアの場合はマスクされません。これらのマスクbitは、パワーアップまたはリセット時に設定されます。これにより、すべてのSIMD浮動小数点例外が最初にマスクされます。
LDMXCSRまたはFXRSTORがマスクbitをクリアして対応する例外フラグbitをセットすると、この変更の結果としてSIMD浮動小数点例外は生成されません。マスクされていない例外は、マスクされていない例外条件を検出する次のSSE/SSE2/SSE3命令の実行時にのみ生成されます。
10.2.3.2 SIMD Floating-Point Rounding Control Field
MXCSRレジスタのbit 13-14(丸め制御[RC]フィールド)は、SIMD浮動小数点命令の結果がどのように丸められるかを制御します。Section 4.8.4参照。
10.2.3.3 Flush-To-Zero
MXCSRレジスタのbit 15(FTZ)は、SIMD浮動小数点アンダーフロー条件に対するマスクされた応答を制御するflush-to-zeroモードを有効にします。アンダーフロー例外がマスクされ、flush-to-zeroモードが使用可能になると、プロセッサは浮動小数点アンダーフロー条件を検出すると、次の操作を実行します。
- 真の結果の符号付きゼロ結果を返します。
- 精度フラグとアンダーフロー例外フラグを設定します。
アンダーフロー例外がマスクされていない場合、flush-to-zeroビットは無視されます。
flush-to-zeroモードは、IEEE Standard 754と互換性がありません。アンダーフローに対するIEEEが要求するマスクされた応答は、非正規化された結果を提供することです(Section 4.8.3.2参照)。
主に性能上の理由からflush-to-zeroモードが提供されています。わずかな精度の損失を犠牲にして、アンダーフローが共通でアンダーフローの結果がゼロに丸められるアプリケーションでは、より高速な実行を実現できます。プロセッサのパワーアップまたはリセット時にflush-to-zeroビットがクリアされ、flush-to-zeroモードを無効にします。
10.2.3.4 Denormals-Are-Zeros
MXCSRレジスタのbit 6(DAZ)は、SIMD浮動小数点デノーマルオペランド条件に対するプロセッサの応答を制御するdenormals-are-zerosモードを有効にします。denormals-are-zeroフラグがセットされると、プロセッサはソースオペランドの符号を用いて全てのデノーマルソースオペランドをゼロに変換してから計算を実行する。プロセッサは、デノーマルオペランド例外マスク(DM)の設定にかかわらず、デノーマルオペランド例外フラグ(DE)をセットしない。例外がマスクされていない場合は、デノーマルオペランド例外は生成されません。
denormals-are-zeroモードはIEEE Standard 754と互換性がありません(Section 4.8.3.2参照)。denormals-are-zeroモードは、ストリーミングメディア処理のようなアプリケーションのプロセッサ性能を向上させるために提供されます。デノーマルオペランドをゼロに丸めることは、処理されるデータの品質に大きな影響を与えません。
denormals-are-zeroフラグは、電源投入またはリセット時にクリアされ、denormals-are-zeroモードは無効になります。
denormals-are-zeroモードは、SSE2拡張機能を備えたPentium 4およびIntel Xeonプロセッサに導入されました。ただし、SSE SIMD浮動小数点命令と完全に互換性があります(つまり、denormals-are-zeroフラグはSSE SIMD浮動小数点命令の動作に影響します)。以前のIA-32プロセッサとPentium 4プロセッサの一部のモデルでは、このフラグ(bit 6)は予約されています。この機能の可用性を検出する手順については、Section 11.6.3項を参照してください。
DAZフラグをサポートしないプロセッサでMXCSRレジスタのbit 6を設定しようとすると、一般保護例外(#GP)が発生します。FXSAVE命令で返されたMXCSR_MASK値を使用して、このような一般保護例外を防止する手順については、Section 11.6.6項を参照してください。
10.2.4 Compatibility of SSE Extensions with SSE2/SSE3/MMX and the x87 FPU
SSE拡張を含むIA-32実行環境に導入された状態(XMMレジスタおよびMXCSRレジスタ)は、SSE2およびSSE3拡張と共有されます。SSE/SSE2/SSE3命令は完全に互換性があります。命令セットの切り替え時に状態を保存する必要がなく、同じ命令ストリームで一緒に実行することができます。
XMMレジスタはx87 FPUおよびMMXレジスタとは独立しているため、XMMレジスタで実行されるSSE/SSE2/SSE3演算は、x87 FPUレジスタおよびMMXレジスタの演算と並行して実行できます(Section 11.6.7項参照)。
FXSAVEおよびFXRSTOR命令は、SSE/SSE2/SSE3の状態をx87 FPUおよびMMXの状態とともに保存および復元します。
10.3 SSE DATA TYPES
SSE拡張では、128bitのパックされた単精度浮動小数点データ型の1つのデータ型がIA-32アーキテクチャに導入されました(図10-4参照)。このデータ型は、Dqwordにパックされた4つのIEEE 32bit単精度浮動小数点値で構成されています。(単精度浮動小数点値のレイアウトについては、図4-3を参照してください;単精度浮動小数点形式の詳細については、Section 4.2.2を参照してください)。

この128bitのパックされた単精度浮動小数点データ型は、XMMレジスタまたはメモリで動作します。2つのパックされた単精度浮動小数点値を2つのパックされたDword整数またはスカラー単精度浮動小数点値をDword整数に変換するための変換命令が用意されています(図11-8を参照)。
SSE拡張は、XMMレジスタとMMXレジスタ間、XMMレジスタと汎用bitレジスタ間の変換命令を提供します。図11-8を参照してください。
128bitのパックされたメモリオペランドのアドレスは、次の場合を除いて16Byteの境界に揃えなければなりません。
- MOVUPS命令は、境界整列されていないアクセスをサポートしています。
- 配置要件の対象とならない4Byteのメモリオペランドを使用するスカラ命令。
図4-2に、メモリ内の128bit(Dqword)データ型のByte順を示します。
10.4 SSE INSTRUCTION SET
SSE命令は4つの機能グループに別れます。
- パックされた単精度浮動小数点命令、あるいはスカラ単精度浮動小数点命令
- 64bit SIMD整数命令
- 状態管理命令
- キャッシュ制御、プリフェッチ、メモリ順序命令
10.4.1 SSE Packed and Scalar Floating-Point Instructions
パックされた単精度浮動小数点命令あるいはスカラ単精度浮動小数点命令は、次のサブグループに分かれています。
- データ転送命令
- 算術命令
- 論理命令
- 比較命令
- シャッフル命令
- 変換命令
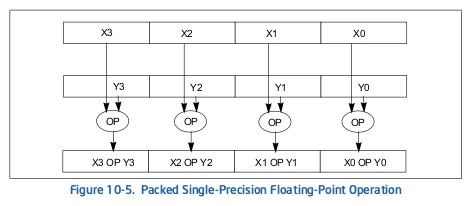
パックされた浮動小数点命令はパックされた浮動小数点オペランドに対してSIMD操作を実行します(図10-5参照)。各ソースオペランドには4つの単精度浮動小数点値が含まれ、宛先オペランドには各オペランドの値(X0とY0, X1とY1, X2とY2, X3とY3)に応じて並列で操作(OP)を実行した結果が含まれます。
スカラ単精度浮動小数点命令は、2つのソースオペランド(X0およびY0)の下位(最下位)のDwordで動作します。図10-6を参照してください。最初のソースオペランドの3つの最も重要なDword(X1、X2、X3)が宛先に渡されます。スカラ演算は、x87 FPUデータレジスタで実行される浮動小数点演算と同様であり、x87スタック演算が15bitを使用する点を除いて、x87 FPU制御ワードの単精度(24bitの有効桁数)SSE演算は8bitの指数範囲を使用します。

10.4.1.1 SSE Data Movement Instructions
SSEデータ移動命令は、XMMレジスタ間およびXMMレジスタとメモリ間で単精度浮動小数点データを移動します。
MOVAPS命令は、4つのパックされた単精度浮動小数点値を含むDqwordオペランドをメモリからXMMレジスタに、またはその逆、またはXMMレジスタ間で転送します。メモリアドレスは16Byteの境界に揃えなければなりません。それ以外の場合は、一般保護例外(#GP)が生成されます。
MOVUPS命令は、メモリアドレスの16Byte整列が必要でないことを除いて、MOVAPS命令と同じ操作を実行します。
MOVSS命令は、32bit単精度浮動小数点オペランドをメモリからXMMレジスタの下位Dwordに、またはその逆、またはXMMレジスタ間で転送します。
MOVLPS命令は、2つのパックされた単精度浮動小数点値をメモリからXMMレジスタの下位Qwordに、またはその逆に移動します。レジスタの上位Qwordは変更されません。
MOVHPS命令は、2つのパックされた単精度浮動小数点値をメモリからXMMレジスタの上位Qwordに、またはその逆に移動します。レジスタの下位Qwordは変更されません。
MOVLHPS命令は、2つのパックされた単精度浮動小数点値をソースXMMレジスタの下位Qwordから宛先XMMレジスタの上位Qwordに移動します。宛先レジスタの下位Qwordは変更されません。
MOVHLPS命令は、2つのパックされた単精度浮動小数点値をソースXMMレジスタの上位4Wordから、宛先XMMレジスタの下位4Wordに移動します。宛先レジスタの上位Qwordは変更されません。
MOVMSKPS命令は、XMMレジスタの4つのパックされた単精度浮動小数点数の最上位bitを汎用レジスタに転送します。この4bitの値は、分岐を行うための条件として使用します。
10.4.1.2 SSE Arithmetic Instructions
SSE算術命令は、パックされた単精度浮動小数点値、またはスカラ単精度浮動小数点値の加算、減算、乗除算、逆数、平方根、平方根の逆数、最大/最小演算を実行します。
ADDPSおよびSUBPS命令は、パックされた2つの単精度浮動小数点オペランドをそれぞれ加算および減算します。
ADDSSおよびSUBSS命令は、2つのオペランドの下位単精度浮動小数点値をそれぞれ加算および減算し、その結果を宛先オペランドの下位Dwordに格納します。
MULPS命令は、パックされた2つの単精度浮動小数点オペランドを乗算します。
MULSS命令は、2つのオペランドの下位倍精度浮動小数点値を乗算し、その結果を宛先オペランドの下位Dwordに格納します。
DIVPS命令は、2つのパックされた単精度浮動小数点オペランドを除算します。
DIVSS命令は、2つのオペランドの下位単精度浮動小数点値を除算し、その結果を宛先オペランドの下位Dwordに格納します。
RCPPS命令は、パックされた単精度浮動小数点オペランドの値のおおよその逆数を計算します。
RCPSS命令は、ソースオペランド内の下位単精度浮動小数点値の近似逆数を計算し、その結果を宛先オペランドの下位Dwordに格納します。
SQRTPS命令は、パックされた単精度浮動小数点オペランドの値の平方根を計算します。
SQRTSS命令は、ソースオペランド内の下位単精度浮動小数点値の平方根を計算し、結果を宛先オペランドの下位Dwordに格納します。
RSQRTPS命令は、パックされた単精度浮動小数点オペランドの値の平方根の近似逆数を計算します。
RSQRTSS命令は、ソースオペランド内の下位単精度浮動小数点値の平方根の近似逆数を計算し、その結果を宛先オペランドの下位Dwordに格納します。。
MAXPS命令は、パックされた2つの単精度浮動小数点オペランドの対応する値を比較し、各比較から宛先オペランドに数値的に大きな値を格納します。
MAXSS命令は、パックされた2つの下位単精度浮動小数点オペランドの値を比較し、その比較から数値の大きい値を宛先オペランドの下位Dwordに格納します。
MINPS命令は、パックされた2つの単精度浮動小数点オペランドからの対応する値を比較し、各比較から宛先オペランドに数値的に小さい値を格納します。
MINSS命令は、パックされた2つの下位単精度浮動小数点オペランドの値を比較し、その比較から数値の小さい値を宛先オペランドの下位Dwordに格納します。
10.4.2 SSE Logical Instructions
SSE論理命令は、パックされた単精度浮動小数点値に対してAND、NOT、OR、およびXOR演算を実行します。
ANDPS命令は、パックされた2つの単精度浮動小数点オペランドのANDを返します。
ANDNPS命令は、2つのパックされた単精度浮動小数点オペランドのAND NOTを返します。
ORPS命令は、パックされた2つの単精度浮動小数点オペランドのORを返します。
XORPS命令は、パックされた2つの単精度浮動小数点オペランドのXORを返します。
10.4.2.1 SSE Comparison Instructions
比較命令は、パックされた単精度浮動小数点値あるいはスカラ単精度浮動小数点値を比較し、比較結果を宛先オペランドまたはEFLAGSレジスタに返します。
CMPPS命令は、2つのパックされた単精度浮動小数点オペランドの対応する値を、即値オペランドを使用して比較し、比較毎のすべて1またはすべて0の32ビットマスク結果を宛先オペランドに返します。即値オペランドの値により、等しい、より小さい、等しいまたはより小さい、順序付けられていない、等しくない、より小さくない、より小さくないまたは等しくない、順序付けされたの8つの比較条件のいずれかを選択できます。
CMPSS命令は、2つのパックされた単精度浮動小数点オペランドの下位値を、即値オペランドを使用して比較し、すべて1またはすべて0の32ビットのマスク結果を宛先オペランドの下位Dwordに返します。即値オペランドは、CMPPS命令と同様に比較条件を選択します。
COMISSおよびUCOMISS命令は、2つのパックされた単精度浮動小数点オペランドの下位値を比較し、 EFLAGSレジスタのZF、PF、CFフラグを使用して、結果を表示します(より大きい、より小さい、等しい、順不同)。これら2つの命令は、次のように異なります。COMISS命令は、ソースオペランドがQNaNまたはSNaNの場合は浮動小数点無効操作例外(#I)例外を通知します。UCOMISS命令は、ソースオペランドがSNaNである場合にのみ無効操作例外を通知します。
10.4.2.2 SSE Shuffle and Unpack Instructions
SSEシャッフルおよびアンパック命令は、2つのパックされた単精度浮動小数点値の内容をシャッフルまたはインターリーブし、その結果を宛先オペランドに格納します。
SHUFPS命令は、宛先オペランドの4つのパックされた単精度浮動小数点値のうちの2つを宛先オペランドの2つの下位Dwordに配置し、 ソースオペランドからの4つのパックされた単精度浮動小数点値を宛先オペランドの2つの上位Dwordに格納します(図10-7参照)。
SHUFPS命令は、ソースと宛先のオペランドに同じレジスタを使用することにより、4つの単精度浮動小数点値を任意の順序でシャッフルできます。

UNPCKHPS命令は、ソースオペランドと宛先オペランドからの上位単精度浮動小数点値のインターリーブされたアンパックを実行し、その結果を宛先オペランドに格納します(図10-8参照)。
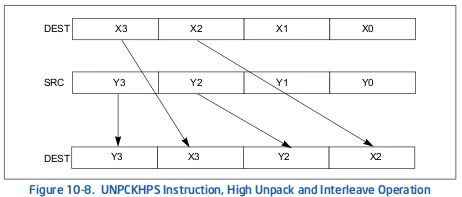
UNPCKLPS命令は、ソースオペランドと宛先オペランドからの下位単精度浮動小数点値のインターリーブとアンパックを実行し、その結果を宛先オペランドに格納します(図10-9参照)。

10.4.3 SSE Conversion Instructions
SSE変換命令(図11-8参照)は、単精度浮動小数点とDword整数間のパックされた変換とスカラ変換をサポートします。
CVTPI2PS命令は、2つのパックされた符号付きDword整数を2つのパックされた単精度浮動小数点値に変換します。変換が不正確な場合、結果はMXCSRレジスタで選択された丸めモードに従って丸められます。
CVTSI2SS命令は、符号付きDword整数を単精度浮動小数点値に変換します。変換が不正確な場合、結果はMXCSRレジスタで選択された丸めモードに従って丸められます。
CVTPS2PI命令は、2つのパックされた単精度浮動小数点値を2つのパックされた符号付きDword整数に変換します。変換が不正確な場合、結果はMXCSRレジスタで選択された丸めモードに従って丸められます。
CVTTPS2PI命令は、切り捨てがソース値を整数値に丸めるために使用されることを除いて、CVTPS2PI命令と似ています(Section 4.8.4.2を参照)。
CVTSS2SI命令は、単精度浮動小数点値を符号付きのDword整数に変換します。変換が不正確な場合、結果はMXCSRレジスタで選択された丸めモードに従って丸められます。
CVTSTSS2SI命令は、切り捨てを使用してソース値を整数値に丸めることを除いて、CVTSS2SI命令と似ています(Section 4.8.4.2項を参照)。
10.4.4 SSE 64-Bit SIMD Integer Instructions
SSE拡張は、以下の64bitのパックされた整数命令をIA-32アーキテクチャに追加します。これらの命令は、MMXレジスタと64bitのメモリ位置のデータで動作します。
SSE2拡張がIA-32プロセッサに存在する場合、これらの命令は、XMMレジスタおよび128bitメモリ位置の128bitオペランドで動作するように拡張されています。
PAVGBおよびPAVGW命令は、それぞれ2つのパックされた符号なしByteまたはWord整数オペランドのSIMD平均を計算します。パックされたソースオペランド内の対応するデータ要素のそれぞれの対について、要素が一緒に加算され、1が一時的な合計に加算され、その結果が右の1ビット位置にシフトされます。
PEXTRW命令は、MMXレジスタから選択されたWordを汎用レジスタにコピーします。
PINSRW命令は、汎用レジスタまたはメモリからMMXレジスタの選択されたWord位置にWOrdをコピーします。
PMAXUB命令は、パックされた2つのオペランドの対応する符号なしByte整数を比較し、各比較結果の大きい方を宛先オペランドに返します。
PMINUB命令は、パックされた2つのオペランドの対応する符号なしByte整数を比較し、各比較のうち小さい方を宛先オペランドに返します。
PMAXSW命令は、2つのパックされたオペランドの対応する符号付きWord整数を比較し、各比較のうち大きな方を宛先オペランドに返します。
PMINSW命令は、パックされた2つのオペランドの対応する符号付きWord整数を比較し、各比較のうち小さい方を宛先オペランドに返します。
PMOVMSKB命令は、パックされたByte整数からMMXレジスタ内の8bitマスクを作成し、その結果を汎用レジスタの下位Byteに格納します。マスクには、MMXレジスタの各Byteの最上位bitが含まれています。(128bitオペランドで動作する場合、16bitマスクが作成されます。)
PMULHUW命令は、2つのソースオペランドのWordのSIMD符号なし乗算を実行し、各結果の上位WordをMMXレジスタに返します。
PSADBW命令は、2つのソースオペランド内の対応する符号なしByte整数のSIMD絶対差を計算し、その差を合計し、宛先オペランドの下位Wordに格納します。
PSHUFW命令は、8bitの即値オペランドで指定された順序に従ってソースオペランドのWordをシャッフルし、その結果を宛先オペランドに返します。
10.4.5 MXCSR State Management Instructions
MXCSR状態管理命令(LDMXCSRおよびSTMXCSR)は、MXCSRレジスタの状態をそれぞれ読み込み、保存します。LDMXCSR命令はメモリからMXCSRレジスタを読み込み、STMXCSR命令はレジスタの内容をメモリに格納します。
10.4.6 Cacheability Control, Prefetch, and Memory Ordering Instructions
SSEの拡張機能では、プログラムにデータのキャッシングをより詳細に制御するためのいくつかの新しい命令が導入されています。また、指定されたキャッシュレベルにデータをプリフェッチする機能を提供するPREFETCHh命令と、格納においてプログラム順序を強制するSFENCE命令も導入されています。
10.4.6.1 Cacheability Control Instructions
以下の3つの命令は、non-temporal hintを使用してMMXおよびXMMレジスタからのデータをメモリに格納することを可能にします。non-temporal hintは、プロセッサに、データをキャッシュ階層に書き込まずにメモリに格納するように指示します。non-temporal なstoreとhintについては、Section 10.4.6.2を参照してください。
MOVNTQ命令は、non-temporal hintを使用して、MMXレジスタからメモリにパックされた整数データを格納します。
MOVNTPS命令は、non-temporal hintを使用して、XMMレジスタからメモリにパックされた浮動小数点データを格納します。
MASKMOVQ命令は、バイトマスクを使用して個々のバイトを選択的に書き込むことによって、MMXレジスタから選択されたバイト整数をメモリに格納します。この命令は、non-temporal hintも使用します。
10.4.6.2 Caching of Temporal vs. Non-Temporal Data
プログラムによって参照されるデータは、temporal(データは再び使用される)またはnon-temporal(データは一度参照され、すぐに再使用されない)とすることができます。例えば、プログラムコードは一般的にtemporalですが、3Dグラフィックスアプリケーションのディスプレイリストなどのマルチメディアデータは、non-temporalであることが多いです。プロセッサのキャッシュを効率的に使用するためには、temporalデータをキャッシュし、non-temporalデータをキャッシュしないことが一般的に望ましいです。SSEとSSE2のキャッシュ制御命令は、プログラムがキャッシュの汚染を最小限に抑えるようにnon-temporalなデータをメモリに書き込むことを可能にします。
これらのSSEおよびSSE2 non-temporal store命令は、アクセスされるメモリをWrite combining(WC)型として処理することによってキャッシュ汚染を最小限にします。プログラムがこれらの命令の1つでnon-temporal storeを指定し、宛先領域のメモリタイプがWrite back(WB)、Write through(WT)またはWrite combining(WC)の場合、プロセッサは次の処理を行います。
- 書き込まれるメモリ位置がキャッシュ階層内に存在する場合、キャッシュ内のデータは追い出される。(いくつかの古いCPU実装(例えば、Pentium M)は、メモリタイプがWCでなく、ラインが既にキャッシュ内にある場合、非一時ストア命令で書かれたアドレスをインプレースで更新することを可能にした。)
- non-temporalデータはWC セマンティクスを用いて書き込まれる。
Volume 3AのChapter11を参照。
WCセマンティクスを使用すると、storeトランザクションは弱く順序付けられます。つまり、データがプログラム順にメモリに書き込まれず、storeが割り当てを書き込まない(つまり、ストアを実行する前にプロセッサは対応するキャッシュラインをキャッシュにフェッチしません)また、異なるプロセッサ実装は、これらのstoreを崩壊させ、組み合わせることを選択することができる。
non-temporal storeに指定されたメモリアドレスがキャッシュ不可能なメモリにある場合、書き込まれる領域のメモリタイプはnon-temporal hintをオーバーライドできます。Uncacheableとは、ここに書き込まれる領域が、キャッシュ不可能(UC)または書き込み保護(WP)メモリタイプのいずれかでマップされていることを意味します。
一般に、WCセマンティクスは、他のプロセッサおよび他のシステムエージェント(例えば、グラフィックスカード)に関して、一貫性を保証するソフトウェアを必要とします。プロデューサ/コンシューマの使用モデルでは、同期とフェンシングを適切に使用する必要があります。フェンシングは、すべてのシステムエージェントが格納されたデータのグローバルな可視性を持つことを保証します。例えば、フェンスに失敗すると、書かれたキャッシュラインがプロセッサ内に留まり、他のエージェントには見えなくなることがあります。
メモリタイプエイリアシングが存在する場合にバス上に見えるメモリタイプは実装固有のものです。1つの例として、バスに書き込まれるメモリタイプは、プログラム順序で見られるように、このラインへの第1の記憶装置のメモリタイプを反映することができます。また他の選択肢も可能です。この動作は予約されているとみなされ、特定の実装の動作に依存すると将来の非互換性が生じる可能性があります。
10.4.6.3 PREFETCHh Instructions
PREFETCHh命令は、プログラムが必要なときにプロセッサの読み込みおよびストアユニットにデータを近づけるように、プログラムが推奨キャッシュレベルでプロセッサにデータを読み込みできるようにします。これらの命令は、temporal locality hint(表10-1参照)によって指定されたキャッシュ階層内の位置に、アドレス指定されたByteを含む32Byte(実装によってはそれ以上)をフェッチします。この表では、第1レベルのキャッシュはプロセッサに最も近く、第2レベルのキャッシュは第1レベルのキャッシュよりもプロセッサから離れています。hintは、temporalまたはnon-temporalデータのプリフェッチを指定します(Section 10.4.6.2参照)。
その後のtemporalなデータへのアクセスは通常のアクセスと同様に処理されますが、non-temporalなデータへのアクセスはキャッシュの汚染を最小限に抑え続けます。データがすでにプロセッサに近いキャッシュ階層のレベルに存在する場合、PREFETCHh命令はデータ移動を起こしません。PREFETCHh命令は、プログラムの機能的動作に影響を与えません。
PREFETCHh命令の詳細については、Section 11.6.13を参照してください。


10.4.6.4 SFENCE Instruction
SFENCE(Store Fence)命令は、メモリストア操作のフェンスを作成することによって、書き込み順序を制御します。この命令は、プログラム順序でストアフェンスに先行するすべてのストア命令の結果が、フェンスに続くストア命令の前に全体的に見えることを保証します。SFENCE命令は、弱く順序付けされたデータを生成するプロシージャと、そのデータを使用するプロシージャとの間の順序付けを保証する効率的な方法を提供します。
10.5 FXSAVE AND FXRSTOR INSTRUCTIONS
FXSAVE命令およびFXRSTOR命令は、Pentium IIプロセッサー・ファミリーのIA-32アーキテクチャーに導入されました(SSE拡張の導入前)。これらの命令の元のバージョンは、それぞれx87実行環境(x87状態)の高速保存とリストアを実行しました。(x87 FPUデータレジスタの状態を保存することにより、FXSAVE命令とFXRSTOR命令は暗黙的にMMXレジスタの状態を保存して復元します)。SSE拡張機能は、これらの命令の範囲を拡張して、x87状態のもとでXMMレジスタの状態とMXCSRレジスタ(SSE状態)を保存および復元します。
FXSAVE命令とFXRSTOR命令は、FSAVE/FNSAVE命令とFRSTOR命令の代わりに使用できます。ただし、FXSAVE命令およびFXRSTOR命令の動作は、FSAVE/FNSAVEおよびFRSTORの動作と同じではありません。
FXSAVE命令およびFXRSTOR命令は、SSE命令グループの一部とはみなされません。それらは存在するかどうかを示すために別個のCPUID機能bitを持っています(CPUID.01H:EDX.FXSR [bit 24] = 1の場合)。
SSE拡張機能のCPUID機能ビットは、FXSAVEおよびFXRSTORの存在を示していません。
FXSAVE命令とFXRSTOR命令は、FXSAVE領域と呼ばれるメモリ領域にx87状態とSSE状態を整理します。Section 10.5.1に、FXSAVEエリアとそのフォーマットの詳細を示します。Section 10.5.2はFXSAVEの動作を説明し、10.5.3項はFXRSTORの動作を説明します。
10.5.1 FXSAVE Area
FXSAVE命令とFXRSTOR命令は、FXSAVE領域と呼ばれるメモリ領域にx87状態とSSE状態を整理します。各々の命令は、それが動作するFXSAVE領域の16Byte整列ベースアドレスを指定するメモリオペランドをとります。
すべてのFXSAVE領域は、領域のベースアドレスから始まる512Byteで構成されます。表10-2に、FXSAVE領域のレガシー領域の最初の416Byteのフォーマットを示します。

x87状態コンポーネントは、Byte23:0およびByte159:32を含みます。SSE状態コンポーネントは、Byte31:24およびByte415:160を含みます。 FXSAVEとFXRSTORはByte511:416を使用しません。Byte463:416は予約されています。
10.5.1.1 x87 State
FXSAVEとFXRSTORがx87状態とSSE状態を構成する方法を表10-2に示します。FXSAVEおよびFXRSTORとの相互作用の詳細とともに、x87の状態を以下に示します。
- x87 FPU制御Word(FCW)、x87 FPUステータスWord(FSW)、x87 FPUオペコード(FOP)には、Byte1:0, 3:2, 7:6がそれぞれ使用されます。
- Byte4は、x87 FPUタグワード(FTW)の短縮版に使用されます。その使用方法は次のとおりです。
- 各jについて、0≦j≦7の場合、FXSAVEは、x87 FPUデータレジスタSTjに空のタグがある場合、Byte4のbitjに0を保存します。それ以外の場合、FXSAVEは1をByte4のbitjに保存します。
- 各jについて、0≦j≦7、FXRSTORはx87 FPUデータレジスタSTjのタグ値を次のように設定します。Byte4のbitjが0であれば、そのデータレジスタのタグレジスタ内のSTjのタグは空(11B)とマークされます。それ以外の場合、x87 FPUはそのレジスタに読み込まれている値に基づいてSTjのタグを設定します(以下を参照)。
- Byte15:8は次のように使用されます。
- 命令にREXプレフィクスがない場合、またはREX.W = 0の場合:
- Byte11:8はx87 FPU命令ポインタオフセット(FIP)のbit31:0に使用されます。
- CPUID(EAX = 07H、ECX = 0H)の場合:EBX [bit13] = 0、Byte13:12がx87 FPU命令ポインタセレクタ(FPU CS)に使用されます。それ以外の場合、プロセッサはFPUのCS値を非推奨にします。FXSAVEは0000Hとして保存します。
- Byte15:14は使用されません。
- 命令にREX.W = 1のREXプレフィックスが付いている場合、FIPの全64bitにByte15:8が使用されます。
- 命令にREXプレフィクスがない場合、またはREX.W = 0の場合:
- Byte23:16は次のように使用されます。
- 命令にREXプレフィクスがない場合、またはREX.W = 0の場合:
- Byte19:16は、x87 FPUデータポインタオフセット(FDP)のbit31:0に使用されます。
- CPUID(EAX = 07H、ECX = 0H)の場合:EBX [bit13] = 0、x87 FPUデータポインタセレクタ(FPU DS)にByte21:20が使用されます。それ以外の場合、プロセッサはFPU DS値を非推奨にします。FXSAVEは0000Hとして保存します。
- Byte23:22は使用されません。
- 命令にREX.W = 1のREXプレフィックスがある場合、FDPの64bitすべてに対してByte23:16が使用されます。
- 命令にREXプレフィクスがない場合、またはREX.W = 0の場合:
- Byte31:24はSSE状態に使用されます(Section 10.5.1.2参照)。
- レジスタST0-7(MM0-7)には、Byte159:32が使用されます。8つのレジスタのそれぞれに128bitの領域が割り当てられ、レジスタに使用される下位80bitと未使用の上位48bitが使用されます。
10.5.1.2 SSE State
FXSAVEとFXRSTORがx87状態とSSE状態を構成する方法を表10-2に示します。FXSAVEおよびFXRSTORとの相互作用の詳細とともに、SSE状態を以下に示します。
- Byte23:0がx87状態に使用されます(Section 10.5.1.1を参照)。
- MXCSR_MASK値には、バイト31:28が使用されます。FXRSTORはこのフィールドを無視します。
Byte27:24は、MXCSRレジスタに使用されます。FXRSTORは、MXCSRレジスタの予約bitのいずれかを設定しようとすると、汎用保護違反(#GP)を生成します。 - Byte159:32はx87状態で使用されます。
- Byte287:160は、レジスタXMM0-7に使用されます。
- Byte415:288は、レジスタXMM8-15に使用されます。これらのフィールドは、64bitモードでのみ使用されます。64bitモード以外でFXSAVEを実行しても、これらのByteには書き込まれません。64bitモード以外のFXRSTORの実行はこれらのByteを読み取らず、XMM8-15を更新しません。
CR4.OSFXSR = 0の場合、FXSAVEおよびFXRSTORはSSE状態で動作する場合と動作しない場合があります。この動作は実装に依存します。さらに、CR4.OSFXSR = 1以外の場合、SSE命令は使用できません。
10.5.2 Operation of FXSAVE
FXSAVE命令は、単一のメモリオペランドをとります。これはFXSAVE領域です。命令はx87状態とSSE状態をFXSAVE領域に格納します。命令プリフィックスによって決まるモード固有の操作と操作に関する詳細は、Section 10.5.1.1とSection 10.5.1.2を参照してください。
10.5.3 Operation of FXRSTOR
FXRSTOR命令は、単一のメモリオペランドをとります。これはFXSAVE領域です。FXSAVE領域のByte27:24の値がMXCSRレジスタのための正当な値でない場合(例えば、その値は予約bitを設定する)。 それ以外の場合、命令はFXSAVE領域からx87状態とSSE状態を読み込みます。命令プリフィックスによって決まるモード固有の操作と操作に関する詳細は、Section 10.5.1.1とSection 10.5.1.2を参照してください。
10.6 HANDLING SSE INSTRUCTION EXCEPTIONS
(省略)
10.7 WRITING APPLICATIONS WITH THE SSE EXTENSIONS
(省略)
Chapter10まとめ
- Chapter10ではSSE拡張について説明
- CPUID.01H:EDX.SSE [bit 25] = 1の場合、SSE拡張が存在
- SSE拡張にはXMMレジスタやMXCSRレジスタなどを使用