・大量のデータを並列処理したい。
・せっかくCPUがコアがたくさんあるので有効活用したい。
・とりあえずスクリプトは書いてみたけど並列実行向けに書き直す余裕はない。
色々調べて、subprocess.Popen()を使う方法が簡単そうだったので実験してみた。
参考記事
https://qiita.com/HidKamiya/items/e192a55371a2961ca8a4
実行環境と負荷試験用サンプルコード
Windows 10 (64bit)
Python 3.7.6
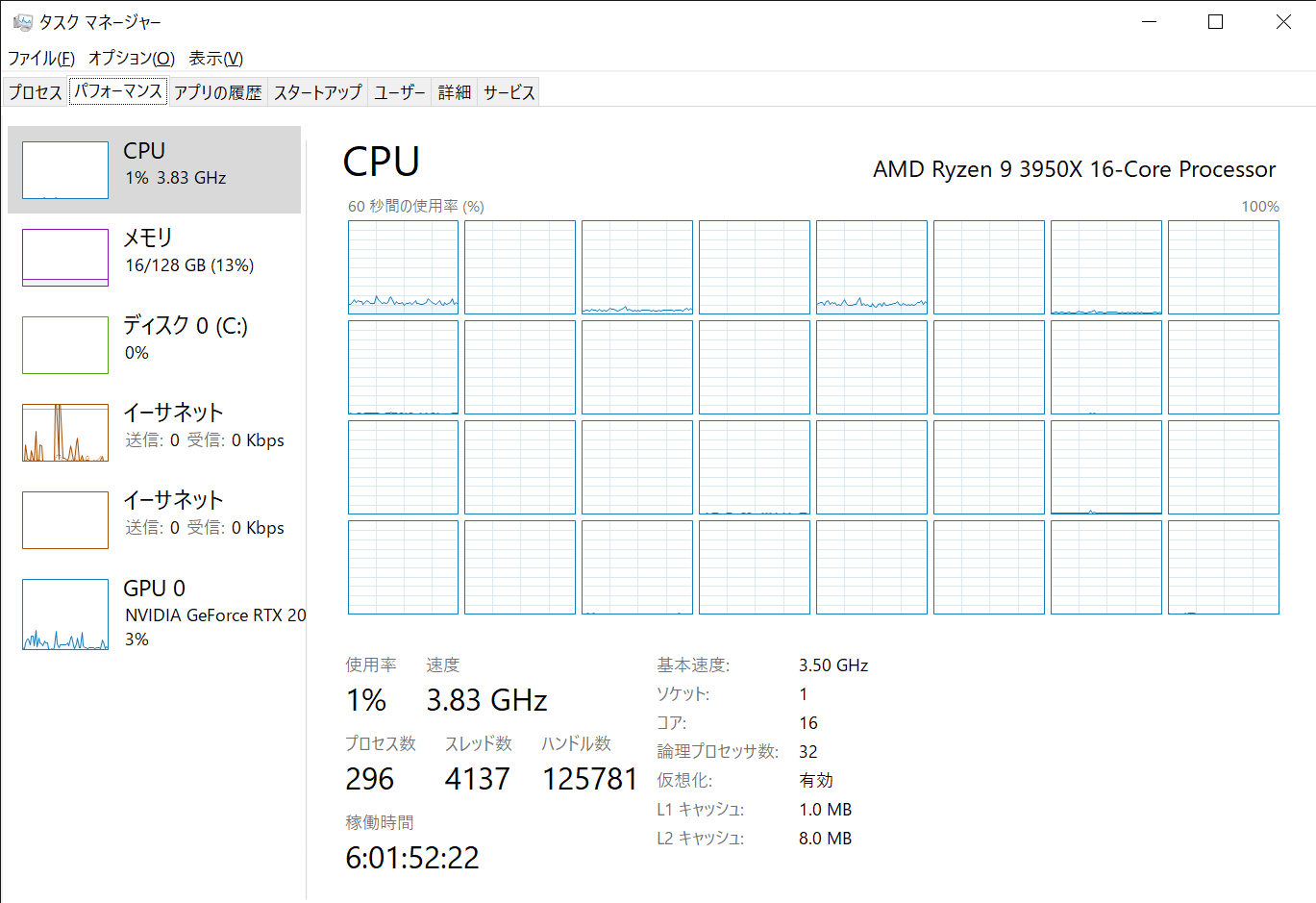
CPUはRyzen 9 3950Xでこういう環境。
以下のコードで実験します。
(コマンドライン引数で指定したフィボナッチ数列の下2桁を表示するだけ。)
import sys
def fib(n):
a, b = 0, 1
for i in range(n):
a, b = b, a + b
return a
if __name__ == "__main__":
num = int(sys.argv[1])
result = fib(num)
print("n = {0}, result % 100 = {1}".format(num, result % 100))
例えばpython fib_sample.py 10000と実行すれば、n = 10000, result % 100 = 75と表示して終了します。
シーケンシャルに実行
まずsubprocess.run()でシーケンシャルに実行してみる。
subprocess.run(['python', r".\fib_sample.py", str(500000 + i)])で引数を与えてpythonを実行する。コマンドライン引数を500000から500063まで変えて、64回実行すると、
from time import time
import subprocess
start=time()
loop_num = 64
for i in range(loop_num):
subprocess.run(['python', r".\fib_sample.py", str(500000 + i)])
end=time()
print("%f sec" %(end-start))
> python .\batch_sequential.py
n = 500000, result % 100 = 25
n = 500001, result % 100 = 26
n = 500002, result % 100 = 51
(中略)
n = 500061, result % 100 = 86
n = 500062, result % 100 = 31
n = 500063, result % 100 = 17
130.562213 sec
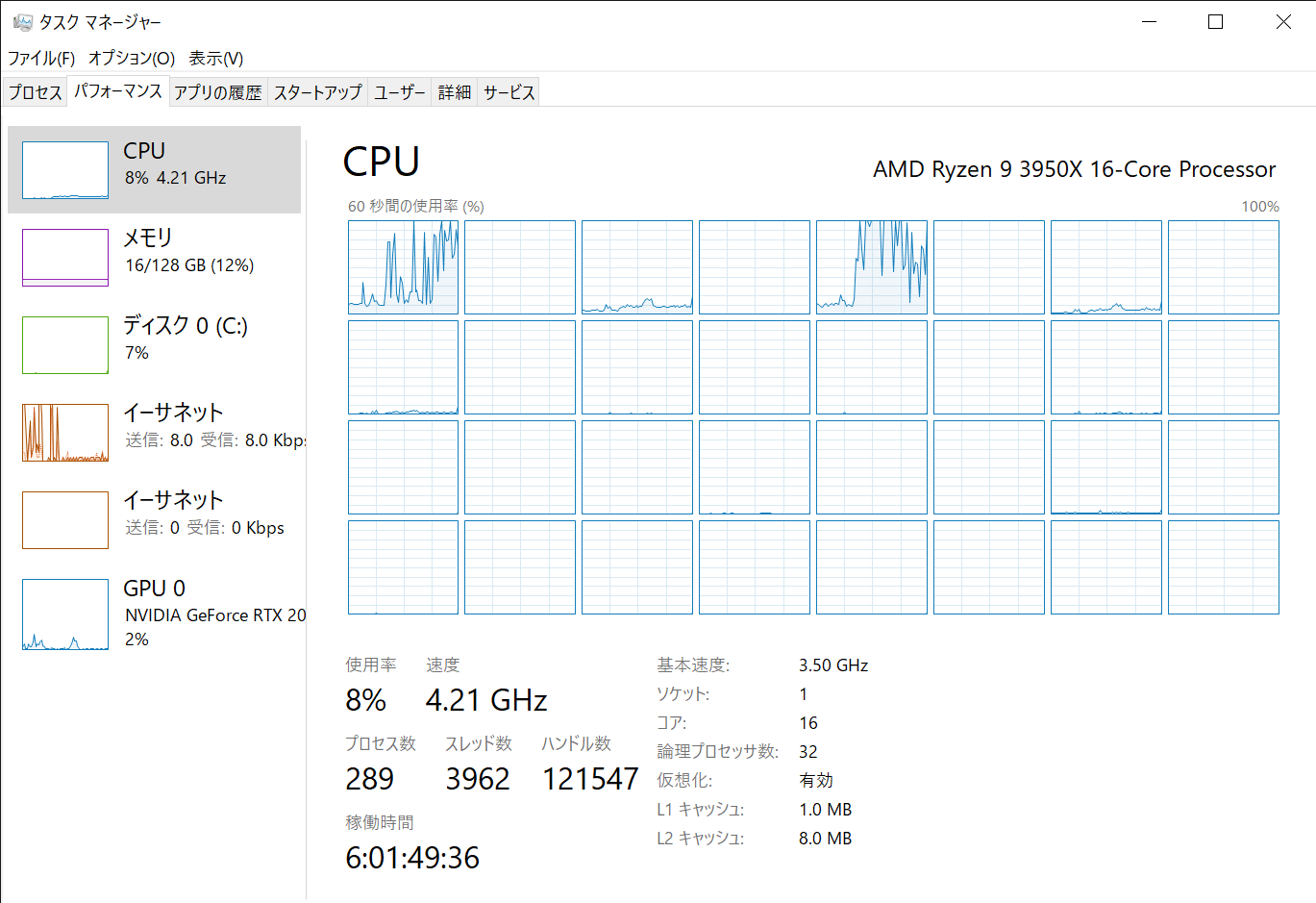
2分強かかった。
当たり前だがCPUコアもぜんぜん使われていない。
並列実行
同じ処理をsubprocess.Popen()で並列実行してみる。subprocess.Popen()はsubprocess.run()と違って生成したプロセスの終了を待たない。
以下のコードは、max_processで指定した数だけプロセス実行→それらがすべて終了するのを待つ→次のプロセス実行→...を繰り返している。
from time import time
import subprocess
start=time()
# 並列プロセス実行数の最大値
max_process = 16
proc_list = []
loop_num = 64
for i in range(loop_num):
proc = subprocess.Popen(['python', r".\fib_sample.py", str(500000 + i)])
proc_list.append(proc)
if (i + 1) % max_process == 0 or (i + 1) == loop_num:
#max_process毎に、全プロセスの終了を待つ
for subproc in proc_list:
subproc.wait()
proc_list = []
end=time()
print("%f sec" %(end-start))
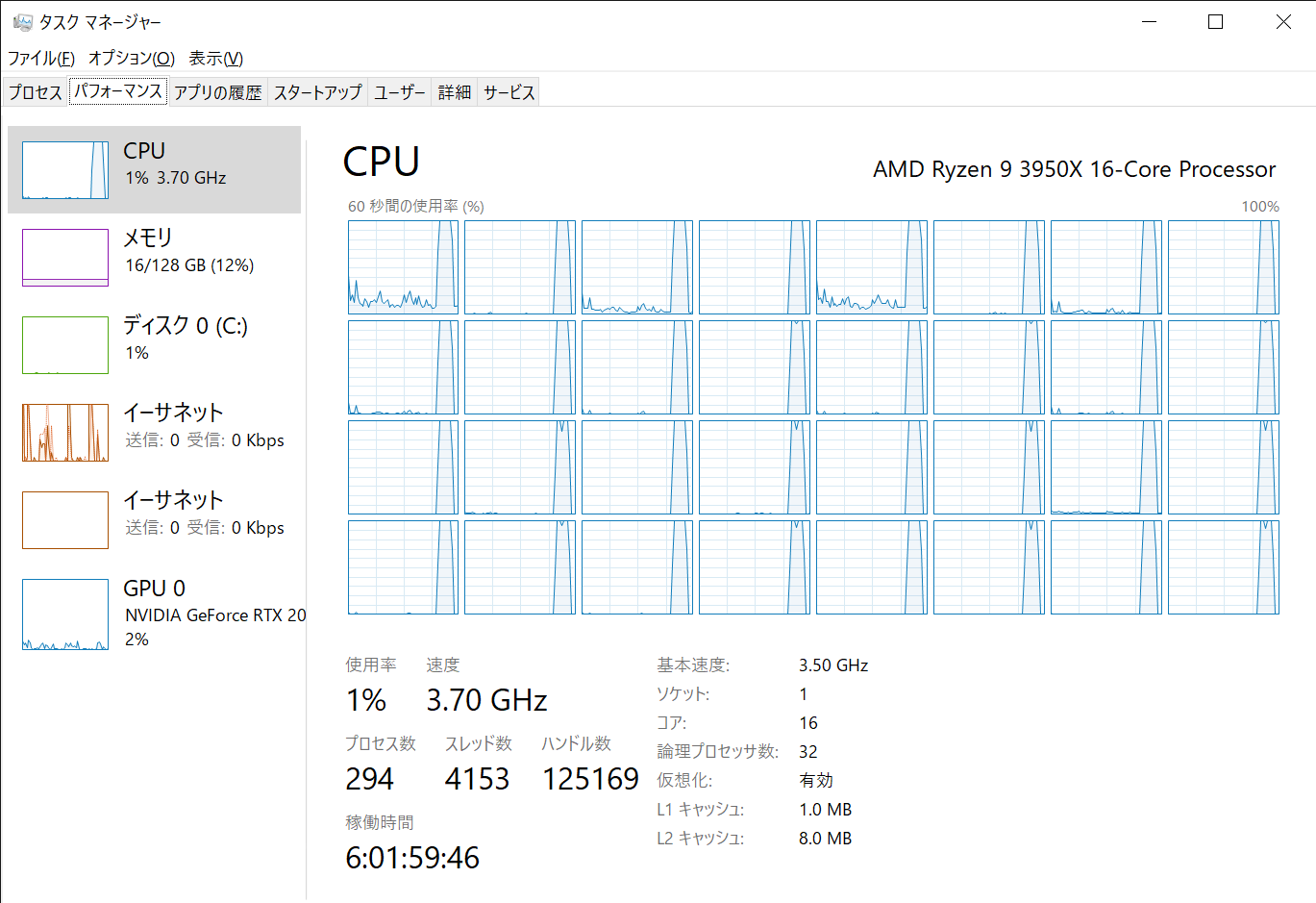
Ryzen 3950Xの物理コア数に合わせて16並列で実行した結果。
> python .\batch_parallel.py
n = 500002, result % 100 = 51
n = 500004, result % 100 = 28
n = 500001, result % 100 = 26
(中略)
n = 500049, result % 100 = 74
n = 500063, result % 100 = 17
n = 500062, result % 100 = 31
8.165289 sec
並列実行しているので処理が終わる順番がばらばらになっている。
130.562秒→8.165秒でほぼ16倍高速化された。
すべてのコアが使われて、正しく並列実行できていることがわかる。
ちなみに物理コア数ではなく論理コア数に合わせて32並列で実行しても早くはならない。むしろ時々遅くなる。
並列実行数を変えて3回ずつ実行したときの、平均実行時間は下のグラフのようになった。
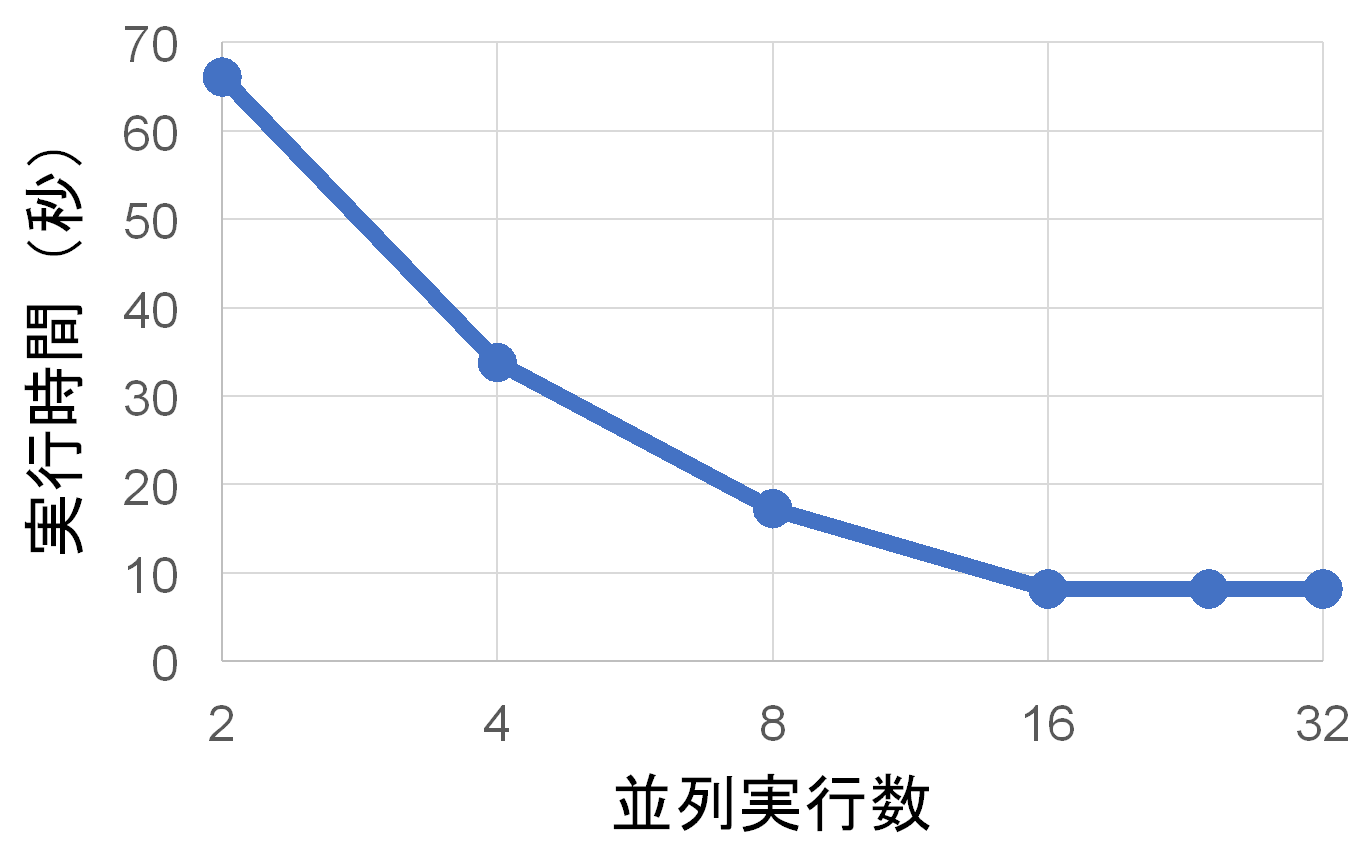
バックグラウンドで色々アプリケーションを走らせていたのであまり正確ではないが、傾向は正しいと思う。
まとめ
まあまあお手軽に高速化できた。
上記のコードだと、並列実行を始めたあとその中で一番処理の長いプロセスの終了を待つので、たまたま処理時間の長いプロセスがいるとそいつの終了を待つオーバーヘッドが大きくなってしまう。本来は各プロセスの実行が終わったらすぐに次のプロセスを立ち上げて常時並列数が一定になるようなコードにするべきだと思う。
もっとも、実際は同じ長さの大量のデータファイルを同じ信号処理にかけるというような用途での高速化が目的だったので、実行時間はまあ大体同じだろうという見込みがあり目をつむった。とりあえず手軽に高速化という目的は果たせたので満足。