この記事は、DjangoCongress 2018で発表した内容を再編したものです。使用した資料は以下にあります。
しかし口頭での説明に頼った部分が多いため、スライドだけでは分かりづらい部分もあるのでmakemigrationsやmigrateのソースを追っかけている部分について補足付きでまとめていきます。資料でいうところのP16-P66までを再編する予定です。
前提
この資料はDjango 2.0系のソースコードをもとに、以下のModelでのBook.authorを追加した際の流れを見ていきました。
from django.db import models
class Book(models.Model):
name = models.CharField(max_length=200)
author = models.ForeignKey('Author', on_delete=models.CASCADE, default=None, null=True)
class Author(models.Model):
name = models.CharField(max_length=200)
DBへの反映コマンド
この記事を読んでいる方にはいまさらですが、DjangoでModelを変更した場合は以下の2つのコマンドを実行します。
# 変更内容を含んだマイグレーションファイルを生成
$ python manage.py makemigrations
# マイグレーションファイルを実際のDBにSQLを発行して反映
$ python manage.py migrate
さて、makemigrationsやmigrateといったmanage.pyのサブコマンドはいずれかのAppのmanagement.commandsパッケージの中に同名のファイルを配置することで自動的に登録されます。もちろん自身で作成したAppでmanagement.commandsにファイルを作成することで独自のサブコマンドを定義することもできます。
makemigrationsやmigrateは以下に実体のモジュールが存在します。
django/core/management/commands/makemigrations.pydjango/core/management/commands/migrate.py
今回はこれらのソースを追っかけていくことにします。
makemigrations
makemigrationsでは現在のソースの状態と適用済のマイグレーションから計算して、DBの状態を更新するために必要なマイグレーションファイルを生成します。
0. 大まかな流れ
大まかな流れを先にまとめておきます。
-
app_labelsといった追加の引数の妥当性チェック - 既存のマイグレーションファイルからProjectStateを生成
- 適用済マイグレーションと生成されているマイグレーションファイルの妥当性チェック
- 既存のマイグレーションファイルの末端が収束しているかのチェック
- ProjectStateを比較し、生成すべきマイグレーションの特定
- マイグレーションファイルの書き出し
一応makemigrationsでも3. の時点で適用済マイグレーションを確認するためDBへ接続を行っていますが、マイグレーションファイルの生成は本質的にはバックエンドは不要です。
それでは順次見ていきます。
1. app_labelsといった追加の引数の妥当性チェック
makemigrations はオプションを省略した場合はsettingsのINSTALLED_APPSに指定したすべてのアプリケーションについて、マイグレーション対象の有無をチェックします。しかしmanage.py makemigrations myappのようにチェック対象のアプリケーションを絞ることができます。
makemigrationsの最初の段階では指定されたアプリケーション名が妥当であるかをチェックしています。
# django.core.management.commands.makemigrations.Command#add_arguments
def add_arguments(self, parser):
parser.add_argument(
'args', metavar='app_label', nargs='*',
help='Specify the app label(s) to create migrations for.',
)
makemigrationsのあとに指定した文字列はapp_labelsに格納されます。そして実際の処理が書かれているhandleの先頭部分で事前チェックが行われます。
# django.core.management.commands.makemigrations.Command#handle
# @@ makemigrationsに指定されたappがある場合はそれが存在するかのチェック
app_labels = set(app_labels)
bad_app_labels = set()
for app_label in app_labels:
try:
apps.get_app_config(app_label)
except LookupError:
bad_app_labels.add(app_label)
if bad_app_labels:
for app_label in bad_app_labels:
self.stderr.write("App '%s' could not be found. Is it in INSTALLED_APPS?" % app_label)
sys.exit(2)
apps.get_app_config(app_label)で指定されたアプリケーションの設定が取得できるかをチェックし、一つでもLookupErrorが発生したものがあればその旨を示しここで処理は異常終了します。
2. 既存のマイグレーションファイルからProjectStateを生成
事前チェックの後は実際の処理に入っていきます。まず、これまでに生成されたマイグレーションファイルをすべて読み込み、ProjectStateと呼ばれるものを組み立てていきます。
ProjectStateとは、現在のプロジェクトにどのようなアプリケーションが登録されていて、それぞれのアプリケーションにどのようなモデルが存在するかといった情報を表現するものです。
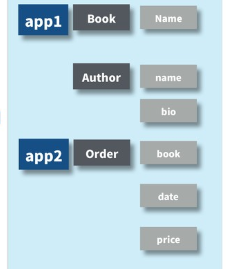
ProjectStateはmakemigrationsでいくつかの方法で生成されていますが、まずはMigrationLoaderクラスを使用して作成されています。
# django.core.management.commands.makemigrations.Command#handle
loader = MigrationLoader(None, ignore_no_migrations=True)
第一引数でNoneが渡っています。ここはDBとの接続connectionオブジェクトを渡すことができますが、ここでは渡していません。渡した場合はバックエンドDB内のマイグレーション適用状況も考慮していきますが、makemigrations時点ではその処理は行われません。(※migrateでは実行しています。)
MigrationLoaderのコンストラクタはこんな感じです。
# django.db.migrations.loader.MigrationLoader
class MigrationLoader:
:
def __init__(self, connection, load=True, ignore_no_migrations=False):
self.connection = connection
self.disk_migrations = None
self.applied_migrations = None
self.ignore_no_migrations = ignore_no_migrations
if load:
self.build_graph()
load引数は渡していないのでデフォルトのTrueです。そのためself.build_graph()が実行されます。
# django.db.migrations.loader.MigrationLoader
def build_graph(self):
:
# Load disk data
self.load_disk()
# Load database data
if self.connection is None:
self.applied_migrations = set()
else:
recorder = MigrationRecorder(self.connection)
self.applied_migrations = recorder.applied_migrations()
self.connectionはNoneなのでself.applied_migrationsは空になります。もし渡していればMigrationRecorderを経由して適用済マイグレーションの情報を取得しますが、ここは後から同じ処理が出てくるので説明を省略します。
メインの処理はself.load_disk()です。ここではローカルにすでに生成されているマイグレーションファイルを読み込んで、self.disk_migrationsに追加していきます。最終的には以下のように(app_name, migrate_name)のタプルをキーとして、MigrationインスタンスをバリューとするDictが構成されます。
{('admin', '0001_initial'): <Migration admin.0001_initial>,
('admin', '0002_logentry_remove_auto_add'): <Migration admin.0002_logentry_remove_auto_add>,
('auth', '0001_initial'): <Migration auth.0001_initial>,
('auth', '0002_alter_permission_name_max_length'): <Migration auth.0002_alter_permission_name_max_length>,
('auth', '0003_alter_user_email_max_length'): <Migration auth.0003_alter_user_email_max_length>,
('auth', '0004_alter_user_username_opts'): <Migration auth.0004_alter_user_username_opts>,
('auth', '0005_alter_user_last_login_null'): <Migration auth.0005_alter_user_last_login_null>,
('auth', '0006_require_contenttypes_0002'): <Migration auth.0006_require_contenttypes_0002>,
('auth', '0007_alter_validators_add_error_messages'): <Migration auth.0007_alter_validators_add_error_messages>,
('auth', '0008_alter_user_username_max_length'): <Migration auth.0008_alter_user_username_max_length>,
('auth', '0009_alter_user_last_name_max_length'): <Migration auth.0009_alter_user_last_name_max_length>,
('contenttypes', '0001_initial'): <Migration contenttypes.0001_initial>,
('contenttypes', '0002_remove_content_type_name'): <Migration contenttypes.0002_remove_content_type_name>,
('sessions', '0001_initial'): <Migration sessions.0001_initial>}
ちなみにMigrationインスタンスは何かというと、ローカルにすでに生成されているであろうこういうやつです。
from django.db import migrations, models
class Migration(migrations.Migration):
initial = True
dependencies = [
]
operations = [
migrations.CreateModel(
name='Author',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('name', models.CharField(max_length=200)),
],
)
]
ローカルにある既存のマイグレーションファイルを読み込んでインスタンス化したものを保持しているわけです。
3. 適用済マイグレーションと生成されているマイグレーションファイルの妥当性チェック
さて、続いてマイグレーションの状況などの事前チェックが行われます。
# django.core.management.commands.makemigrations.Command#handle
connection = connections[alias]
:
# loaderはMigrationLoaderのインスタンス
loader.check_consistent_history(connection)
おもむろにconnectionというDBへの接続っぽいものを取り出しています。これはdjango.db.backends.base.base.BaseDatabaseWrapperを継承した各DBエンジンに対応するクラスのインスタンスです。まぁとりあえずはDBへの接続をラップしたクラスだと思っておけばよいです。
check_consistent_historyでは適用済のマイグレーションと出力さてているマイグレーションファイルの一貫性が取れているかをチェックしています。
# django.db.migrations.loader.MigrationLoader#check_consistent_history
def check_consistent_history(self, connection):
"""
Raise InconsistentMigrationHistory if any applied migrations have
unapplied dependencies.
"""
recorder = MigrationRecorder(connection)
applied = recorder.applied_migrations()
for migration in applied:
:
for parent in self.graph.node_map[migration].parents:
if parent not in applied:
:
raise InconsistentMigrationHistory(
"Migration {}.{} is applied before its dependency "
"{}.{} on database '{}'.".format(
migration[0], migration[1], parent[0], parent[1],
connection.alias,
)
)
さっき省略したMigrationRecorderが出てきました。これは使用しているDB内に存在するdjango_migrationsというテーブルとの中継をするクラスです。recorder.applied_migrations()により適用済として登録されているマイグレーションを取得します。取得したマイグレーションについて一つづつ確認していきます。
self.graphは現在のディスク上のマイグレーションから構成されたグラフデータです。self.graph.node_map[migration].parentsではそのマイグレーションの親のマイグレーションを取得しています。ある適用済マイグレーションがあったとき、現在のディスク上の構成においてあるマイグレーションより前に適用されているべきマイグレーションがここで戻っていますが、それがDB内で適用済になっていない場合は一貫性が取れていませんのでInconsistentMigrationHistoryが送出されます。
発生ケースとしてはmigrateを実行した後でマイグレーションファイルの削除や書き換えを行ったケースなどでです。
なお、省略したMigrationRecorderの中身に少し触れておきます。
# django.db.migrations.recorder.MigrationRecorder
class MigrationRecorder:
:
class Migration(models.Model):
app = models.CharField(max_length=255)
name = models.CharField(max_length=255)
applied = models.DateTimeField(default=now)
class Meta:
apps = Apps()
app_label = "migrations"
db_table = "django_migrations"
def __str__(self):
return "Migration %s for %s" % (self.name, self.app)
Migrationというモデルが定義されており、このモデルで作られるテーブルがdjango_migrationsです。このテーブルは適用されたアプリケーション名とマイグレーション名が記録されます。あくまで名前だけですので同名のファイルの中身を書き換えたりしても期待した動作にはならないので注意しましょう。
4. 既存のマイグレーションファイルの末端が収束しているかのチェック
続いて生成されているマイグレーションファイルが収束しているかがチェックされています。
# django.core.management.commands.makemigrations.Command#handle
conflicts = loader.detect_conflicts()
:
if conflicts and not self.merge:
name_str = "; ".join(
"%s in %s" % (", ".join(names), app)
for app, names in conflicts.items()
)
raise CommandError(
"Conflicting migrations detected; multiple leaf nodes in the "
"migration graph: (%s).\nTo fix them run "
"'python manage.py makemigrations --merge'" % name_str
)
なんらかのconflictsが見つかれば--mergeの実行を促す例外が発生します。
# django.db.migrations.loader.MigrationLoader#detect_conflicts
def detect_conflicts(self):
"""
Look through the loaded graph and detect any conflicts - apps
with more than one leaf migration. Return a dict of the app labels
that conflict with the migration names that conflict.
"""
seen_apps = {}
conflicting_apps = set()
for app_label, migration_name in self.graph.leaf_nodes():
if app_label in seen_apps:
conflicting_apps.add(app_label)
seen_apps.setdefault(app_label, set()).add(migration_name)
return {app_label: seen_apps[app_label] for app_label in conflicting_apps}
やっていることは単純で、self.graph.leaf_nodes()で取得されるマイグレーションファイルのグラフの末端の一覧を取得します。それぞれは(app_label, migration_name)という形で保持されています。同一のapp_labelが2回以上発生した場合はそれをconflicting_appsに登録しています。conflicting_appsが空でない限りコンフリクトが発生したとみなされます。つまり、同じAppにおいては末端のマイグレーションファイルは必ず1つであることが期待されています。
少しわかりにくいですが、図示すると以下のようになります。
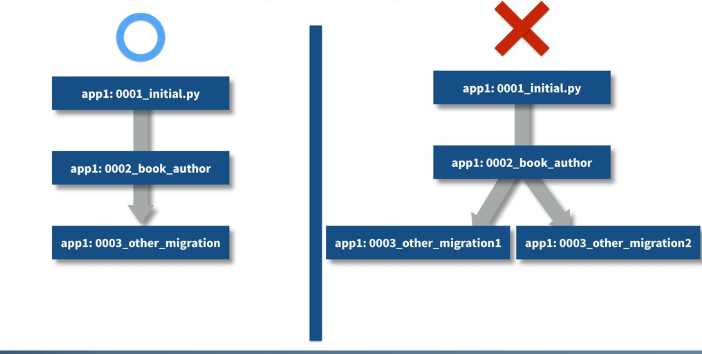
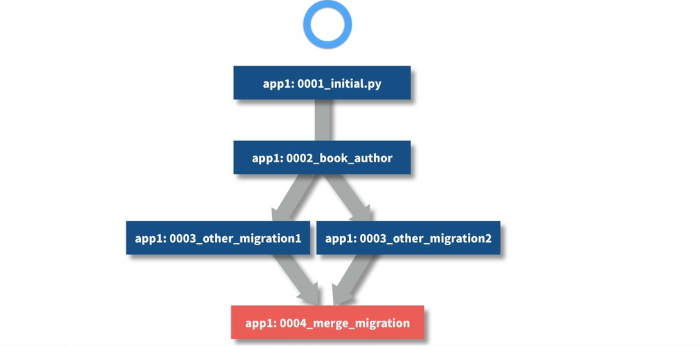
5. ProjectStateを比較し、生成すべきマイグレーションの特定
# @@ マイグレーション計算の肝であるDetectorを生成
# loader.project_state -> Migrationファイルから計算したState
# ProjectState.from_apps(apps) -> 現在のプロジェクトの状態から求めたState
# MigrationAutodetectorは両者の差分を元にマイグレーションファイルを生成する機能をもつ
# MigrationAutodetectorをここで初期化する
autodetector = MigrationAutodetector(
loader.project_state(),
ProjectState.from_apps(apps),
questioner,
)
:
# @@ migrationの計算
# {'app1': [<Migration app1.0002_book_author>]}
changes = autodetector.changes(
graph=loader.graph,
trim_to_apps=app_labels or None,
convert_apps=app_labels or None,
migration_name=self.migration_name,
)
MigrationAutodetectorのコンストラクタは引数を3つ取っていますが、最後の1つは対話処理のためのヘルパーなので直接処理内容には関係ありません。前2つの引数(from_state, to_state)がポイントです。
| code | mean |
|---|---|
loader.project_state() |
Diskから読み込んだマイグレーションファイルで構成したProjectState |
ProjectState.from_apps(apps) |
現在のソースコードから構成したProjectState |
例えば今回であれば、前者のProjectStateはBookモデルにはAuthorは存在せず、後者にはAuthorが存在しています。両者を比較することで、差分を特定しその差分を埋めるマイグレーションファイルを生成することができます。
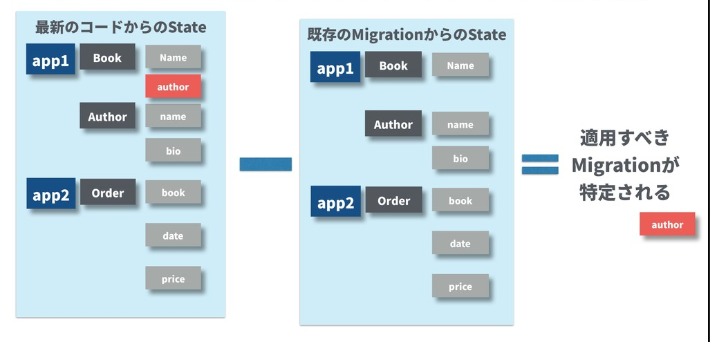
MigrationAutodetector.changesで実際の差分の計算が行われています。
# django.db.migrations.autodetector.MigrationAutodetector#changes
def changes(self, graph, trim_to_apps=None, convert_apps=None, migration_name=None):
"""
Main entry point to produce a list of applicable changes.
Take a graph to base names on and an optional set of apps
to try and restrict to (restriction is not guaranteed)
"""
changes = self._detect_changes(convert_apps, graph)
# @@ マイグレーションファイル名の調整等
changes = self.arrange_for_graph(changes, graph, migration_name)
# @@ app_labelが指定されている場合はそれ以外のChangeを捨てる
if trim_to_apps:
changes = self._trim_to_apps(changes, trim_to_apps)
return changes
何段階か処理がわかれていますが、メインはself._detect_changesです。なかなか長いメソッドですので分けてみていきます。
# django.db.migrations.autodetector.MigrationAutodetector#_detect_changes
def _detect_changes(self, convert_apps=None, graph=None):
:
self.generated_operations = {}
self.altered_indexes = {}
# Prepare some old/new state and model lists, separating
# proxy models and ignoring unmigrated apps.
self.old_apps = self.from_state.concrete_apps
self.new_apps = self.to_state.apps
self.old_model_keys = set()
self.old_proxy_keys = set()
self.old_unmanaged_keys = set()
self.new_model_keys = set()
self.new_proxy_keys = set()
self.new_unmanaged_keys = set()
for al, mn in self.from_state.models:
model = self.old_apps.get_model(al, mn)
if not model._meta.managed:
self.old_unmanaged_keys.add((al, mn))
elif al not in self.from_state.real_apps:
if model._meta.proxy:
self.old_proxy_keys.add((al, mn))
else:
self.old_model_keys.add((al, mn))
for al, mn in self.to_state.models:
model = self.new_apps.get_model(al, mn)
if not model._meta.managed:
self.new_unmanaged_keys.add((al, mn))
elif (
al not in self.from_state.real_apps or
(convert_apps and al in convert_apps)
):
if model._meta.proxy:
self.new_proxy_keys.add((al, mn))
else:
self.new_model_keys.add((al, mn))
self.old_appsとself.new_appsにProjectStateから取得されたアプリケーションの状態を格納します。
その後、それぞれについて登録されているModelの一覧を確保しておきます。
# django.db.migrations.autodetector.MigrationAutodetector#_detect_changes
# @@ マイグレーションの検知処理
# Renames have to come first
self.generate_renamed_models()
# Prepare lists of fields and generate through model map
self._prepare_field_lists()
self._generate_through_model_map()
# Generate non-rename model operations
self.generate_deleted_models()
self.generate_created_models()
self.generate_deleted_proxies()
self.generate_created_proxies()
self.generate_altered_options()
self.generate_altered_managers()
# Create the altered indexes and store them in self.altered_indexes.
# This avoids the same computation in generate_removed_indexes()
# and generate_added_indexes().
self.create_altered_indexes()
# Generate index removal operations before field is removed
self.generate_removed_indexes()
# Generate field operations
self.generate_renamed_fields()
self.generate_removed_fields()
self.generate_added_fields()
self.generate_altered_fields()
self.generate_altered_unique_together()
self.generate_altered_index_together()
self.generate_added_indexes()
self.generate_altered_db_table()
self.generate_altered_order_with_respect_to()
self._sort_migrations()
self._build_migration_list(graph)
self._optimize_migrations()
return self.migrations
その後、モデル名の変更検知や列追加・削除など変更内容ごとにメソッド化されており順番にチェックが行われています。今回は列追加ですのでself.generate_added_fieldsで変更内容が検知されます。
# django.db.migrations.autodetector.MigrationAutodetector#generate_added_fields
def generate_added_fields(self):
"""Make AddField operations."""
# @@ 既存のフィールドとの差分を取って列追加を検知する
# ('app1', 'book', 'author') のような形式
for app_label, model_name, field_name in sorted(self.new_field_keys - self.old_field_keys):
self._generate_added_field(app_label, model_name, field_name)
追加された列の検知方法は、from/toのそれぞれの状態で各モデルのfieldをまとめたself.new_field_keysとself.old_field_keysについて差分を取ることで、追加された列を検知することができます。なお、列情報はself._prepare_field_lists()の中で収集されており('app1', 'book', 'author')のように(app_name, model_name, field_name)の3値のtupleのsetとして構成されているので豪快に差分を取るだけでいいのです。
# django.db.migrations.autodetector.MigrationAutodetector#_generate_added_field
def _generate_added_field(self, app_label, model_name, field_name):
field = self.new_apps.get_model(app_label, model_name)._meta.get_field(field_name)
# Fields that are foreignkeys/m2ms depend on stuff
dependencies = []
if field.remote_field and field.remote_field.model:
dependencies.extend(self._get_dependencies_for_foreign_key(field))
# You can't just add NOT NULL fields with no default or fields
# which don't allow empty strings as default.
time_fields = (models.DateField, models.DateTimeField, models.TimeField)
preserve_default = (
field.null or field.has_default() or field.many_to_many or
(field.blank and field.empty_strings_allowed) or
(isinstance(field, time_fields) and field.auto_now)
)
if not preserve_default:
field = field.clone()
if isinstance(field, time_fields) and field.auto_now_add:
field.default = self.questioner.ask_auto_now_add_addition(field_name, model_name)
else:
field.default = self.questioner.ask_not_null_addition(field_name, model_name)
self.add_operation(
app_label,
operations.AddField(
model_name=model_name,
name=field_name,
field=field,
preserve_default=preserve_default,
),
dependencies=dependencies,
)
最終的にはself.add_operationにoperations.AddFieldを追加します。AddFieldはOperationクラスを実装しており(正確にはFieldOperationをですが)、ある単独の処理を表現します。また、Operationも処理内容ごとにクラスがわかれています。ここでまとめられたOperationは最終的にAppごとに作られたMigrationのoperationsに組み込まれます。
# django.db.migrations.migration.Migration
class Migration:
operations = [] # ここに登録される
dependencies = []
run_before = []
replaces = []
initial = None
atomic = True
def __init__(self, name, app_label):
self.name = name
self.app_label = app_label
# Copy dependencies & other attrs as we might mutate them at runtime
self.operations = list(self.__class__.operations)
self.dependencies = list(self.__class__.dependencies)
self.run_before = list(self.__class__.run_before)
self.replaces = list(self.__class__.replaces)
最終的にMigrationAutodetector.changesの戻り値として以下のようなApp名をキーとしてMigrationをバリューとするDictが戻ります。
{'app1': [<Migration app1.0002_book_author>]}
6. マイグレーションファイルの書き出し
さて、いよいよ大詰めです。
# django.core.management.commands.makemigrations.Command#handle
if not changes:
# No changes? Tell them.
if self.verbosity >= 1:
if app_labels:
if len(app_labels) == 1:
self.stdout.write("No changes detected in app '%s'" % app_labels.pop())
else:
self.stdout.write("No changes detected in apps '%s'" % ("', '".join(app_labels)))
else:
self.stdout.write("No changes detected")
else:
# @@ マイグレーションファイルの作成
self.write_migration_files(changes)
if check_changes:
sys.exit(1)
作成されたMigrationを書き出しますが、変更がなかったときはそのまま終了です。変更があった(changesが空でない)場合はself.write_migration_files(changes)に流れていきます。
# django.core.management.commands.makemigrations.Command#write_migration_files
def write_migration_files(self, changes):
"""
Take a changes dict and write them out as migration files.
"""
directory_created = {}
for app_label, app_migrations in changes.items():
# @@ app1 [<Migration app1.0002_book_author>]
if self.verbosity >= 1:
self.stdout.write(self.style.MIGRATE_HEADING("Migrations for '%s':" % app_label) + "\n")
for migration in app_migrations:
# Describe the migration
# @@ Migrationから書き出し用のMigrationWriterを取得する
writer = MigrationWriter(migration)
# @@ migration_stringを使いまわしてるのは少し気持ち悪い・・
if self.verbosity >= 1:
:
if not self.dry_run:
:
migration_string = writer.as_string()
# @@ 実際にマイグレーションファイルを書き出す
with open(writer.path, "w", encoding='utf-8') as fh:
fh.write(migration_string)
各MigrationについてMigrationWriterをインスタンス化しています。そしてwriter.as_string()より、マイグレーションファイルの内容を文字列として取得し、ファイルとして書き出しています。
# django.db.migrations.writer.MigrationWriter#as_string
def as_string(self):
"""Return a string of the file contents."""
items = {
"replaces_str": "",
"initial_str": "",
}
imports = set()
# Deconstruct operations
operations = []
for operation in self.migration.operations:
# @@ Operation単位でコマンドに変換
operation_string, operation_imports = OperationWriter(operation).serialize()
# @@ importsは一回やればいいからsetになっている
imports.update(operation_imports)
operations.append(operation_string)
items["operations"] = "\n".join(operations) + "\n" if operations else ""
# Format dependencies and write out swappable dependencies right
dependencies = []
for dependency in self.migration.dependencies:
if dependency[0] == "__setting__":
dependencies.append(" migrations.swappable_dependency(settings.%s)," % dependency[1])
imports.add("from django.conf import settings")
else:
dependencies.append(" %s," % self.serialize(dependency)[0])
items["dependencies"] = "\n".join(dependencies) + "\n" if dependencies else ""
:
return MIGRATION_TEMPLATE % items
:
OperationWriter(operation).serialize()とあるように、実際の内容はさらにOperationWriter経由で取得されています。OperationWriterでは渡されたOperationのdeconstructを呼び出して、同じインスタンスが生成できるのに必要な情報を取得しています。
# django.db.migrations.writer.OperationWriter
class OperationWriter:
:
def serialize(self):
:
imports = set()
name, args, kwargs = self.operation.deconstruct()
operation_args = get_func_args(self.operation.__init__)
:
self.operationは今回であればAddFieldです。
class AddField(FieldOperation):
"""Add a field to a model."""
def __init__(self, model_name, name, field, preserve_default=True):
self.field = field
self.preserve_default = preserve_default
super().__init__(model_name, name)
def deconstruct(self):
kwargs = {
'model_name': self.model_name,
'name': self.name,
'field': self.field,
}
if self.preserve_default is not True:
kwargs['preserve_default'] = self.preserve_default
return (
self.__class__.__name__,
[],
kwargs
)
deconstructは名前の通り、__init__で受け取った内容を再度戻り値として戻すものです。これがあれば、再度同じAddFieldインスタンスを生成できるので、ファイルに正しく書き出されれば同じインスタンスを生成するスクリプトになるわけです。
ちなみに、django.db.migrations.writer.MigrationWriter#as_stringではMIGRATION_TEMPLATEという文字列にデータを当て込んで最終的な文字列を取得していました。該当のテンプレートは以下のようなものです。
MIGRATION_TEMPLATE = """\
# Generated by Django %(version)s on %(timestamp)s
%(imports)s
class Migration(migrations.Migration):
%(replaces_str)s%(initial_str)s
dependencies = [
%(dependencies)s\
]
operations = [
%(operations)s\
]
"""
最終的に生成されたマイグレーションファイルと見比べると、このテンプレートから生成されていることがよくわかりますね。
from django.db import migrations, models
import django.db.models.deletion
class Migration(migrations.Migration):
dependencies = [
('app1', '0001_initial'),
]
operations = [
migrations.AddField(
model_name='book',
name='author',
field=models.ForeignKey(default=None, null=True, on_delete=django.db.models.deletion.CASCADE, to='app1.Author'),
),
]
まとめ
makemigrationsによってどのようにマイグレーションファイルが生成されていくか、ソースを追ってみました。無事にマイグレーションファイルが作成されるところまで追えましたので、次回はこのマイグレーションファイルがどのように適用されていくかをまとめていきます。