自動化っていいですよね
ブラウザ操作を自動化してくれる「Selenium」。
テストやスクレイピングなどで使われている方も多いかと思います。
便利なんですが、エラーが起きた場合にその原因が分かりにくいな、Seleniumがどんな通信を行っているのか確認したいな、と思うことも。
この記事ではSeleniumの通信内容を簡易的に取得する方法を検証します。
この記事のゴール
- コンテナ形式のAWS LambdaにてSeleniumを動作させる
- Seleniumの通信ログ(HTTP/HTTPS)を確認する
前提および注意事項
- 開発環境としてAWS Cloud9を使用します
Cloud9の環境には予めDockerやAWS CLIなどがインストールされているため、それらのインストール手順は本記事では触れていません。
また、デフォルトのディスク容量だとすぐに不足するため、本記事の内容を検証した際は30GBに拡張しています。 - コンテナ形式のAWS Lambdaで動作確認を行っています
Lambdaは実行時間やメモリなどに応じて課金されますが、本記事の内容を実行する場合、比較的多くのメモリを割り当てる必要があるため(本記事では3000MB以上を指定しました)、ご注意ください。
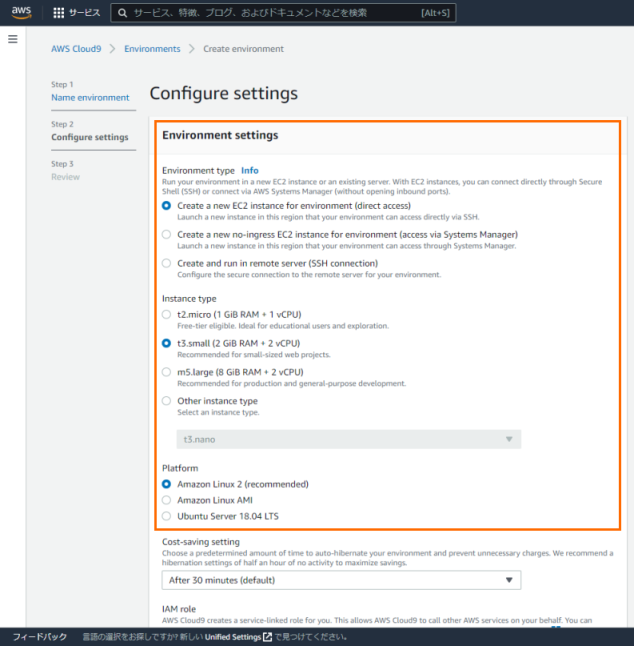
開発環境について
AWS Cloud9を使用しています。
設定は下図を参照ください。
ディレクトリ構成
コンテナイメージの定義や関数のコードを記述する前に、ディレクトリや空ファイルなどを準備します。
ディレクトリとファイルの概要
本記事の内容を進めると最終的な構成は次のとおりになります。
あわせて各要素の概要を示します。
├ lambda-selenium-wire/ ・・・作業用のプロジェクトディレクトリ。任意の名称でOKです。
│ ├ app.py ・・・Lambda関数(ハンドラ)を記述するPythonファイルです。
│ ├ Dockerfile ・・・コンテナイメージを作成するためのファイルです。
│ ├opt/ ・・・後述するサイトからダウンロードしたドライバなどを格納します。
│ ├ chromedriver
│ ├ headless-chromium
Cloud9のターミナルから以下のコマンドを実行することにより、同様の構成になります。
ディレクトリ名などは任意ですが、もし変更した場合、以降は適宜読み換えてください。
$ mkdir lambda-selenium-wire
$ cd lambda-selenium-wire
$ touch app.py
$ touch Dockerfile
$ mkdir opt
次に以下のそれぞれのサイトから、chromedriverとheadless-chromiumをダウンロードし、展開したものをoptディレクト配下に格納します。
なお、chromedriverとheadless-chromiumのバージョンを合わせる必要がある点だけご留意ください。
本記事の検証で使用したchromedriverとheadless-chromiumは次のコマンドでダウンロードできます。
$ cd lambda-selenium-wire/opt/
$ curl -SL https://github.com/adieuadieu/serverless-chrome/releases/download/v1.0.0-57/beta-headless-chromium-amazonlinux-2.zip > headless-chromium.zip
$ unzip headless-chromium.zip
$ rm headless-chromium.zip
$ curl -SL https://chromedriver.storage.googleapis.com/87.0.4280.20/chromedriver_linux64.zip > chromedriver.zip
$ unzip chromedriver.zip
$ rm chromedriver.zip
以上で準備は完了です。次からコード等を記述します。
Dockerfile
コンテナイメージの定義を行います。
ポイントしては、Seleniumを拡張した「Selenium Wire」をインストールしている箇所です。
FROM public.ecr.aws/lambda/python:3.9
# Selenium Wireをインストールします
RUN yum install -y https://dl.google.com/linux/direct/google-chrome-stable_current_x86_64.rpm
RUN yum install -y openssl
RUN pip install selenium-wire
# driverなどダウンロードしたものをコピー
COPY ./opt/headless-chromium /opt/
COPY ./opt/chromedriver /opt/
COPY app.py ./
ENV DISPLAY=:0.0
CMD [ "app.handler" ]
app.py
Lambda関数を定義します。
ポイントとしては次の2つです。
- Selenium Wire用のオプションである enable_har を有効化
enable_har の有効化により通信内容をHAR形式で取得することが可能となります。 - S3に保存
通信内容を記録したHARファイルはサイズが大きくなりがちです。
本記事ではS3に格納するため、以下に示すコードの BUCKET_NAME にバケット名を設定してください。
また、LambdaにS3へのアクセス権を付与する必要があります。
import os
import shutil
import time
from datetime import datetime
from seleniumwire import webdriver
from selenium.webdriver.chrome.options import Options
import boto3
s3 = boto3.resource('s3')
# HARファイルを格納するバケット名を設定します
BUCKET_NAME = "YOUR BUCKET NAME"
def handler(event, context):
url = event['target_url']
# /tmp/bin 配下にコピーする
move_bin("headless-chromium")
move_bin("chromedriver")
options = Options()
options.binary_location = '/tmp/bin/headless-chromium'
options.add_argument('--no-sandbox')
options.add_argument('--headless')
options.add_argument('--disable-gpu')
options.add_argument('--disable-extensions')
options.add_argument('--disable-dev-tools')
options.add_argument('--no-zygote')
options.add_argument('--single-process')
options.add_argument('--disable-dev-shm-usage')
options.add_argument('--window-size=1920x1080')
# HAR形式でのダンプを有効化
sw_options = {
'enable_har': True
}
driver = webdriver.Chrome(executable_path='/tmp/bin/chromedriver',
options=options,
seleniumwire_options=sw_options,
service_log_path='/tmp/chromedriver.log')
driver.get(url)
time.sleep(10)
# S3に格納
obj = s3.Object(BUCKET_NAME,"sw_" + datetime.now().strftime('%Y-%m-%d-%H-%M-%S') + ".har")
obj.put( Body=driver.har )
driver.close()
driver.quit()
del driver
return {"statusCode": 200, "body": {"url": url}}
def move_bin(fname, src_dir = "/opt", dest_dir = "/tmp/bin"):
if not os.path.exists(dest_dir):
os.makedirs(dest_dir)
dest_file = os.path.join(dest_dir, fname)
shutil.copy2(os.path.join(src_dir, fname), dest_file)
os.chmod(dest_file, 0o775)
ビルド&デプロイ
ビルドおよびデプロイはコンソール上から操作を進めると必要な手順などが示されます。
リポジトリ作成~リポジトリへのイメージのプッシュ
Amazon Elastic Container Registryへ遷移し、任意の名称でリポジトリを作成します。
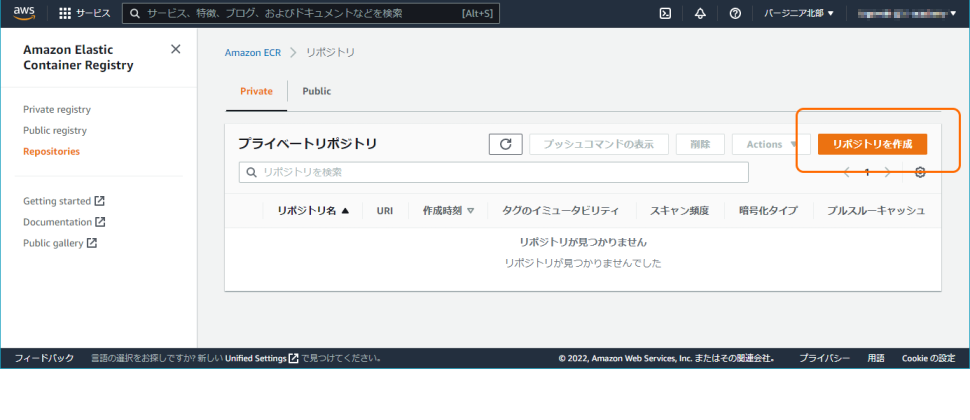
リポジトリの作成が完了すると、当該リポジトリへのプッシュコマンド等を示すボタンが表示されます。
ボタンを押下して表示されたコマンドを順次、実行してください。
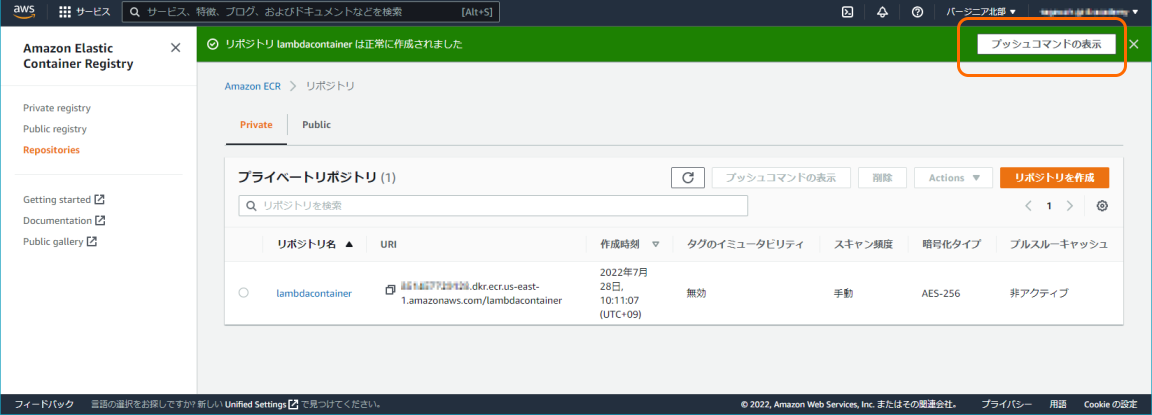
コマンドを全て実行すると、作成したリポジトリ内にイメージがプッシュされていることを確認できます。
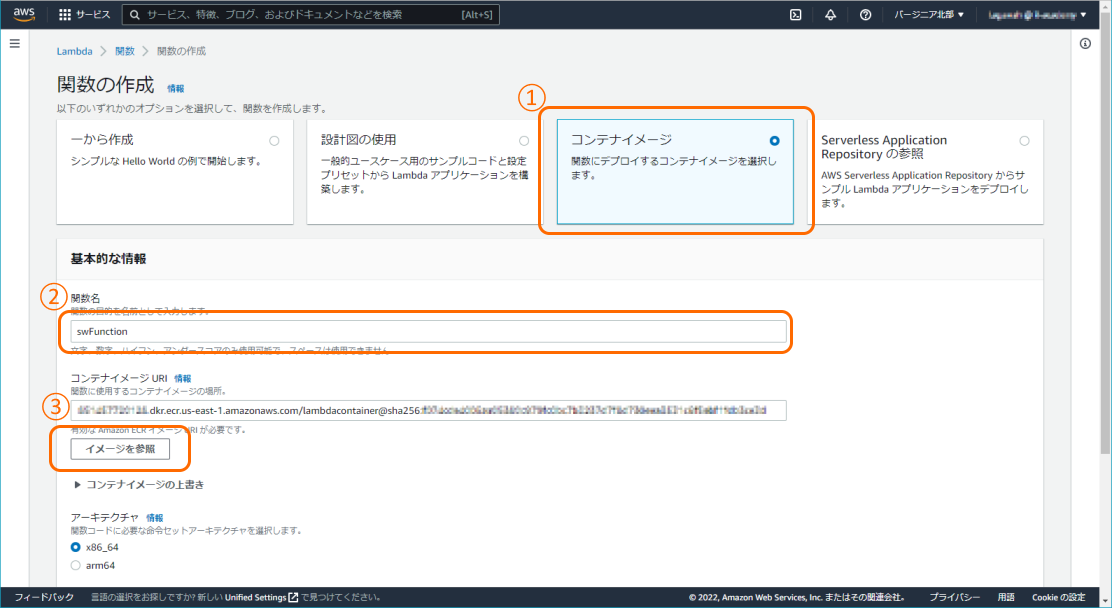
関数の作成
Lambdaへ遷移し、関数の作成を行います。
①:「コンテナイメージ」を指定します。
②:任意の関数名を指定します。
③:「イメージを参照」ボタンを押下し、先ほどプッシュしたイメージを選択します。
入力完了後、関数を作成します。
関数の作成完了後、以下の設定を行います。
- 関数の設定の変更
適切なメモリサイズなどは対象とするURLによりますが、本記事では次のように設定しました。
-メモリ:3000MB
-タイムアウト:20秒 - S3へのアクセス許可
IAMから当該関数のロールに対してS3へのアクセスを許可するポリシーをアタッチします。
設定完了後、テストを実施します。
テスト
Dockerイメージのビルド&デプロイが完了したらテストします。
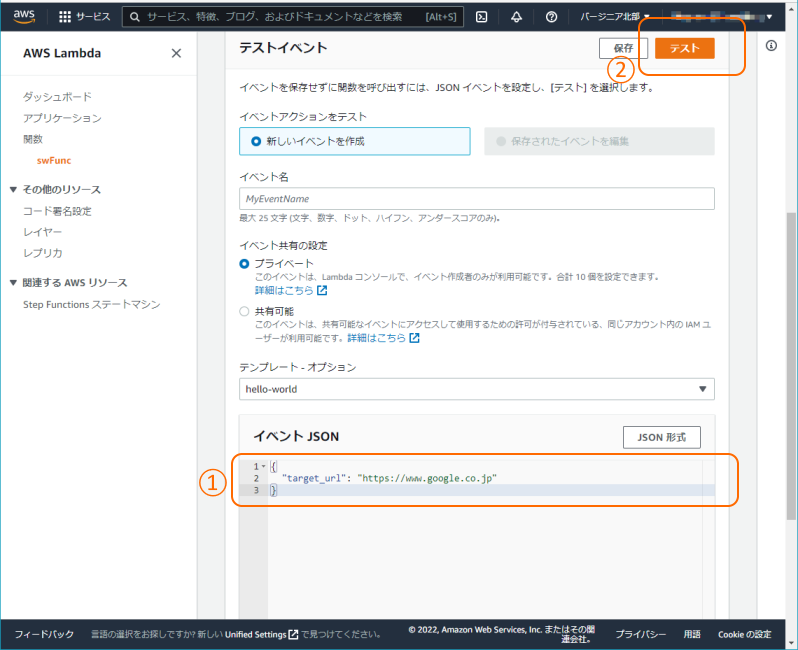
① Lambdaのテスト画面にて、イベントJSONを設定
{
"target_url": "https://www.google.co.jp"
}
② 「テスト」ボタンを押下
無事に成功したらS3のバケットにHARファイルが格納されます。
関数の実行結果である、S3に格納したHARファイルの抜粋を示します。
{
"log": {
"version": "1.2",
"creator": {
"name": "Selenium Wire HAR dump",
"version": "4.6.5",
"comment": "Selenium Wire version 4.6.5"
},
"entries": [
{
"startedDateTime": "2022-07-28T04:23:29.690681+00:00",
"time": 46,
"request": {
"method": "GET",
"url": "http://www.google.co.jp/",
"httpVersion": "HTTP/1.1",
"cookies": [],
"headers": [
{
"name": "Host",
"value": "www.google.co.jp"
},
{
"name": "Upgrade-Insecure-Requests",
"value": "1"
},
以上です。
さいごに
普段はHTTP(S)の通信ログを取得する場合はローカルプロキシを使用するのですが、プロキシの利用に制限のある環境で通信ログを取得したいことがあり、本記事で紹介させてもらいました「Selenium Wire」を検証してみました。
「Selenium Wire」の利用方法自体は簡単で、Seleniumを使ったことがある方であれば導入に特に問題はないかと思います。
今回使用したLambda環境での利用はおススメはしませんが(重いので…)、HAR形式に対応したビューアもいくつかあるためご興味ある方の参考になれば幸いです。
参考
本記事作成にあたり以下の記事を参考にさせてもらいました。
本記事では説明を割愛した部分も解説されているため、不明な点がある場合はこれらのサイトが参考になるかと思います。