本シリーズの目的
近年、Retrieval-Augmented Generation (RAG) に関する情報は急速に増加し、多くの技術イベントでも頻繁に取り上げられています。しかし、現状のネット上の情報には以下のような課題があります。
- 情報の断片化:多くの記事が特定の側面にのみ焦点を当てており、全体像を把握しづらい
- 包括性の不足:RAGの概念から実装まで、全体を網羅した内容が少ない
- 初心者への配慮:技術的な前提知識を要求する記事が多く、新規参入者にとって理解が困難
これらの課題に対応するため、本シリーズでは以下を目指します:
- RAGに関する情報を体系的に整理し、全体像を提示する
- 基礎概念から実装まで、段階的に理解を深められる構成を提供する
- 初心者にも理解しやすい説明と、実践的な例を交えて解説する
私自身の学習と理解を深める過程も兼ねて、このシリーズを通じてRAGに関する包括的な情報を提供します。読者の皆様のRAG理解の一助となれば幸いです。
1. はじめに:企業での生成AI利用の現状
生成AIモデルは急速に進化を続けており、GPT-4やClaude 3.5などの最新モデルはより高度な理解力と生成能力を示しています。個人利用では文章の自動生成、翻訳、チャットボットなどで広く活用されていますが、企業での利用には依然として多くの課題が存在します。
-
情報の最新性
- 学習データの制限(例:GPT 3.5は2021年9月まで、GPT 4は2023年4月まで)
- 最新の出来事や情報の反映が困難
-
知識の限界
- 汎用的知識は豊富だが、特定分野や業界の専門知識が不足
- 企業固有の内部情報を活用できない
-
コンテキスト理解の制限
- 「コンテキスト・ウィンドウ」による文脈保持の限界
- 短期記憶はあるが、長期的な文脈維持が困難
-
説明可能性の低さ
- 予測や回答の背後にある理由がブラックボックス化
- 意思決定プロセスの透明性が低い
-
セキュリティとプライバシーの懸念
- 企業データのLLMへの漏洩リスク
- ユーザーの役職や役割に基づくアクセス制御の複雑さ
-
回答の信頼性
- 「ハルシネーション」問題:学習していない質問に対してあたかも本当のように事実と異なることを言ってしまう。
- 古い情報や一般的すぎる情報の提示
- 権限のないソースからの回答生成
-
用語の一貫性
- 異なる学習ソースによる同じ用語の異なる解釈
生成AIモデルは、熱心で自信に満ちた新入社員に例えることができます。常に自信を持って、迅速に応答しますが、経験不足や限られた情報源のため、時に不正確な回答をすることがあります。
-
ハルシネーションとは、AIが「嘘をつく」または「でたらめを言う」現象
- 具体的な特徴:
- 事実ではない情報を本当のことのように話す
- 存在しない情報を自信満々に作り出す
- 質問に答えられないときでも、適当な回答をでっち上げる
- これは人間で例えると、次のような状況に似ています。
- 知識がない分野の質問をされても、適当に答えてしまう新入社員
- 記憶があいまいなのに、自信たっぷりに話をする人
- 夢と現実の区別がつかなくなっている状態
- 具体的な特徴:
-
なぜAIが知らないことは知らないと言わずにでたらめを言うか?
- 「知らない」という概念の欠如: AIモデルは人間のように「知らない」という概念を持っていません。常に学習データに基づいて最も適切と判断した回答を生成しようとします。
- AIモデルは自身の回答の正確性を適切に評価できないことがあり、不確実な情報でも確信を持って提示してしまいます。
- 学習データとモデルの限界: AIモデルは膨大なデータで学習していますが、すべての情報を完全に理解しているわけではありません。データの不完全さや偏りが、誤った回答を生成する原因となります
-
ハルシネーションは完全に解決できますか?
ハルシネーション問題の影響を最小限に抑えることがき期待できますが、問題の完全な解決は不可能です。実は人間、ソフトウェア、そしてAIにはいくつか共通点があります。
-
完璧を求めることの難しさ
- 人間であれば、誰もが間違いを犯します。完璧な人間というのは存在しません。これは人間の本質的な特徴です。
- ソフトウェアテストの基本原則の一つに、「バグゼロのソフトウェアは存在しない」というものがあります。どんなに丁寧に作られたソフトウェアでも、何らかの不具合が潜んでいる可能性があります。
- AIも同様に、完璧ではありません。特に「ハルシネーション」と呼ばれる、事実と異なる情報を生成してしまう問題は、完全になくすことが極めて困難です。
-
なぜ完璧を求めるのは難しいのか
- 複雑さ:人間の思考、ソフトウェアのコード、AIのアルゴリズムはとても複雑です。複雑なものには必ず予期せぬ動作が生じる可能性があります。
- 変化する環境:世界は常に変化しています。完璧だと思われたものも、環境の変化によって不完全になることがあります。
- 未知の要素:どんなに準備しても、予測できない状況や問題が発生することがあります。
-
現実的なアプローチ:完璧を求めるのではなく、以下のような現実的なアプローチが重要です。
- 継続的な改善:人間もソフトウェアもAIも、常に学習し、改善し続けることが大切です。
- リスク管理:完全になくすことはできなくても、問題が起こるリスクを最小限に抑える努力をすることが重要です。
- 適切な利用:それぞれの長所と短所を理解し、適切な場面で適切に活用することが求められます。
-
結論として、人間、ソフトウェア、AIのいずれも完璧ではありませんが、それぞれの特性を理解し、上手に活用することで、より良い結果を得ることができます。
次章では、これらの課題を解決するための手法として、ファインチューニングとRAG(Retrieval-Augmented Generation)について詳しく説明します。
2. LLMの単体利用における課題を解決するアプローチ
2.1 LLM利用アプローチの全体
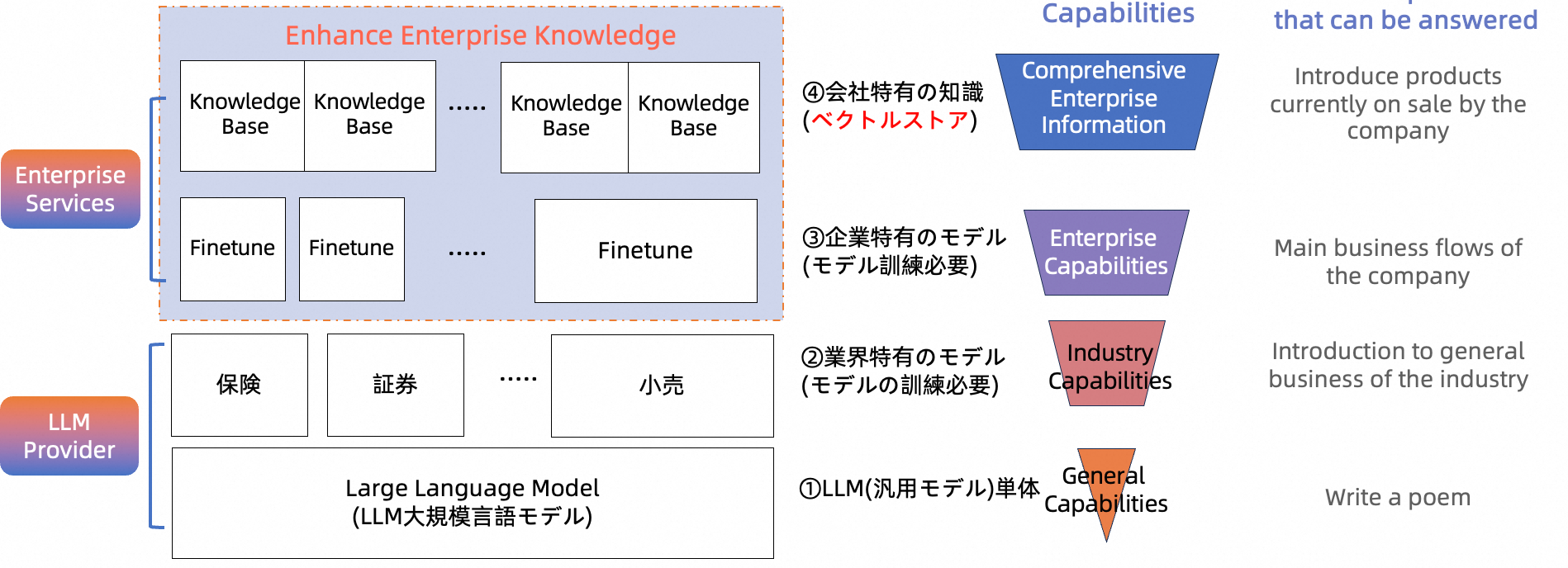
LLMの単体利用における欠点を補うために、主に以下の3つのアプローチが考えられます。
- 業界特有のモデル構築
- 企業独自のモデル構築(ファインチューニング)
- 企業特有の知識の利用(
RAG)
2.2 各アプローチの難易度と実現可能性
1. LLMと業界特有のモデル構築
こちらのアプローチは非常に高度で、主にトップレベルの企業や研究機関が実施可能です。
- 要件:
- 新規データセットによる業界独自のLLMモデルの訓練
- 高度なAI人材の確保
- 大規模なGPUリソース
- 包括的なMLOps体制の構築
2. 企業独自のモデル(ファインチューニング)
既存のLLMを基に、企業独自のデータで調整するアプローチです。
- 特徴:
- 既存モデルをベースとするため、1よりも実現しやすい
- 企業固有のニーズに合わせたカスタマイズが可能
3. 企業特有の知識の利用(RAG)
Retrieval-Augmented Generation (RAG) は、ファインチューニングよりもやりやすくて、多くの企業で実現可能なアプローチです。
- 特徴:
- ベクトルストアを利用して企業固有の知識を活用
- 既存のLLMと組み合わせて使用可能
- 他のアプローチと併用可能
4. RAGシステムの一般的な構成パターン
上記ののアプローチは相互排他的ではなく、組み合わせて使用することで、より効果的なAIシステムを構築できます。企業のニーズ、リソース、技術力に応じて適切なアプローチを選択または組み合わせることが重要です。
- ベクトルストア + LLM(汎用モデル)
- ベクトルストア + 業界特有のモデル
- ベクトルストア + 企業独自のモデル(ファインチューニング済み)
2.3 ファインチューニング
1. 定義
ファインチューニングとは、既存の大規模言語モデル(LLM)を特定のタスクやドメインに適応させるプロセスです。このプロセスでは、学習データをモデルのパラメータに組み込み、新しい特化型モデルを作成します。
2. 仕組み
- 事前学習済みのLLMに対して、ラベル付きデータ(入力と出力のペア)を用意して追加学習させて、特定のタスクの精度を高める
- モデル自体のパラメータを調整し、特定のドメインや用途に最適化
3. 特徴
- 特定のタスクやドメインに深く特化したシナリオに適している
- 特定の形式や文脈に対応したタスクに高い効果を発揮
4. 利点
-
データの効率的な圧縮と学習
- 大量のデータを効率的にモデルに組み込む
- 広範囲のデータから抽出された知識や特徴を効率的に表現
-
全体的な文脈理解
- 学習データ全体の傾向や特徴を捉える能力
- 特定のドメインや文脈に関する深い理解と一貫性のある出力が可能
5. 適用例
-
企業戦略アドバイザー
- 企業の戦略フレームワークや過去の意思決定パターンを学習
- 企業の戦略的思考や意思決定プロセスに沿った分析と提案が可能
- 例:過去の事例を踏まえた新規市場参入戦略の提案
-
イノベーションアシスタント
- 企業の技術力や製品哲学を理解
- 企業の強みや技術的制約を考慮した実現可能性の高いアイデア生成
- 例:既存技術と市場ニーズを組み合わせた新製品コンセプトの提案
-
業務プロセスアシスタント
- 企業特有の業務プロセスや専門用語を理解
- 社内の暗黙知や文化的背景を含めた回答が可能
- 複雑な業務フローの理解と説明に適している
- 例:新入社員向けの企業特有の略語や業務フロー説明ガイダンスの生成
2.4 RAG
1. 定義
RAGは、LLMを変更せずに外部の知識ベースから質問と関連の情報を取得し、LLMと組み合わせることで、最新かつ正確な情報を提供するAIシステムの回答質向上技術です。
2. 仕組み
- 独自データをベクトルデータベースに格納
- ユーザーからの質問に関連する情報を外部データベースから検索
- 検索結果をLLMに入力し、回答を生成
3. 特徴
- 外部知識ベースの活用による最新かつ正確な情報提供
- 大規模データベースからの幅広い事実への対応
- データベース更新による常に最新の情報提供
- 特定の質問に対する正確で具体的な回答生成
4. 適用例
- カスタマーサポート
- 製品マニュアル、FAQs、過去のサポート履歴を活用
- 例:新製品の特定機能に関する質問への回答
- 社内ナレッジ管理
- 社内文書、報告書、プロジェクト履歴の活用
- 例:部門の予算使用状況の確認
- 市場分析と競合情報
- 最新の市場レポート、ニュース、競合情報の活用
- 例:競合他社の最新製品戦略の分析
- 法律・規制関連の質問対応
- 歴史的事実や統計データの提供
5. RAGの限界
- 全体的な情報把握よりも局所的な情報利用に適している
- 創造的タスクや複雑な推論には制限がある可能性
6. 社内に蓄積されたすべてのファイルをLLMに送信する方法はなぜだめでしょうか?
ChatGPTなどの商用LLMを利用する際、参考情報のファイルをアップロードしてから会話する方法はみなさはお馴染みですよね。これはもRAGと言えるのか?
企業の機密情報保護の観点から、社内に蓄積されたすべてのファイルを商用LLMに送信することはリスクがあります。そこで、商用LLMの代わりにオープンソースのLLMを自社のクラウド環境で運用することが考えられます。この場合、すべての社内ファイルをLLMに一括でアップロードする方法は適切でしょうか。
それとも、やはりRAGシステムを構築する必要があるのでしょうか。RAGシステムが必要だとすれば、その理由は何でしょうか。
-
ChatGPTの参考情報アップロード機能とRAGの関係:
ChatGPTに参考情報をアップロードして会話する方法は、RAGの簡易的な形態と見なすことができます。ただし、完全なRAGシステムほど洗練されてはいません。 -
オープンソースLLMの自社クラウド運用と全ファイルアップロード:
- この方法は確かにデータセキュリティの観点からは商用LLMを利用するよりも安全です。しかし、すべての社内ファイルを全部LLMにアップロードする手法には、以下の問題があります。
- 効率性の低下:大量のデータを常に処理する必要があり、レスポンス時間が遅くなる可能性があります。
- 更新の困難さ:新しい情報を反映するたびに全データを再アップロードする必要があります。
- コンテキストの制限:LLMのコンテキストウィンドウには制限があり、全情報を一度に処理できない可能性があります。
- 関連性の低い情報の混入:質問に関係のない情報も含まれ、回答の質が低下する可能性があります。
- この方法は確かにデータセキュリティの観点からは商用LLMを利用するよりも安全です。しかし、すべての社内ファイルを全部LLMにアップロードする手法には、以下の問題があります。
-
なぜRAGシステムが必要か:
- 効率的な情報検索:質問に関連する情報のみを抽出し、LLMに提供します。
- 最新情報の反映:データベースの更新が容易で、常に最新の情報を提供できます。
- スケーラビリティ:大規模なデータセットでも効率的に処理できます。
- コンテキストの最適化:質問に最も関連する情報のみを提供し、より正確な回答を生成します。
- カスタマイズ性:検索アルゴリズムやランキング方法を細かく調整できます。
- セキュリティの強化:必要な情報のみをLLMに送信するため、情報漏洩のリスクを最小限に抑えられます。
結論として、オープンソースLLMを自社クラウドで運用することでセキュリティを向上させつつ、RAGシステムを構築することで効率性、正確性、スケーラビリティを確保することができます。これにより、企業の機密情報を保護しながら、AIの能力を最大限に活用することが可能になります。
2.5 企業でのAIGC利用におけるファインチューニングとRAGの比較と選定
1. ビジネス観点
| 特性 | ファインチューニング | RAG |
|---|---|---|
| 特徴 | • 与えられた全体的な知識を学習し内部化 • 広範囲のコンテキスト理解と複雑な関連性把握 |
• 質問に関連する特定情報を即時取得・利用 • 最新情報を柔軟に取り入れ可能 |
| 長所 | • 会社全体の戦略や方針を考慮した提案 • 部門間相互作用や長期的影響の考慮 |
• 常に最新の情報に基づく回答 • 特定質問への詳細で正確な回答 |
| 短所 | • 新情報反映には再学習が必要 • 大量のデータと計算リソースが必要 |
• 広範囲のコンテキスト把握が限定的 • 複雑な戦略的提案には追加処理が必要 |
| 実際の応用 | 戦略的意思決定:会社全体の状況を考慮した長期的提案 | 日常的な問い合わせ対応、最新情報に基づく正確な回答 |
| 例え話 | 経験豊富な顧問や長年勤務のCEO:会社の歴史、文化、戦略を深く理解し、広範な視点から助言 | ヘルプデスクや総務のベテラン社員:最新の社内文書にアクセスでき、特定質問に迅速・正確に回答するが、会社全体的文脈解釈は限定的 |
2. 技術観点
| 特性 | ファインチューニング | RAG |
|---|---|---|
| 技術手法 | LLMに独自データを追加学習させ、新たな知識を蓄えたモデルを作成 | 外部知識ベースの情報をプロンプトに加え、LLMに問い合わせ |
| 初期コスト | 高い: • 学習データ準備 • GPU訓練コスト • MLOps構築 |
比較的低い: • データベース構築 • 情報検索システム組み込み • モデル訓練不要 • クラウド知識で構築可能 |
| クエリ時のトークン費用 * | 低い:入力プロンプトと生成回答のトークンのみ | 比較的高い:関連文書やコンテキスト情報も含むため総トークン数増加 |
| 柔軟性 | 低い:新情報反映に再学習必要 | 高い:外部データソース更新で最新情報反映可能 |
| 開発者のコントロール | 限定的:モデル全体の挙動変更に再学習必要 | 高い: • 情報ソースの制御・変更が容易 • 権限レベルに応じたアクセス制御可能 • 誤情報参照のトラブルシューティング可能 |
| モデル訓練の有無 | ・あり ・新しい強い汎用モデルが登場する時に、そのモデルをベースに再度学習する必要性も考慮 |
なし |
| モデルサイズ | 大きい(学習データを内包) | 小さい(外部データを参照) |
| レイテンシ | 低い(学習済みモデルから直接生成) | やや高い(データ検索と処理が必要) |
| 難易度 * | 高い | 中程度 |
- クラウドでオープンソースLLMを自前運営する場合、直接的なトークン費用は発生しないが、代わりに計算リソース費用や運用コスト、セキュリティ対策費用などが発生。
3. なぜよく 「ファインチューニングは最終手段だ!ファインチューニングをやる前にはまずRAGを検討しよう」 と言われるか?
- たしかに、従来のニューラルネットワークのファインチューニングではtensorflowやkeras、pytorchといったライブラリを駆使してコードを書く必要もあったし、ニューラルネットワークの中間層の情報を確認しながらどの層からファインチューニングを行うかなどを決めて学習実行、出来上がったモデルの精度確認という作業を繰り返すことになりかなり大変な作業でした。
- しかし、現在ではLLMプロバイダーのサービスではそんなことをする必要はなく、比較的簡単に実行できるようになっていました。
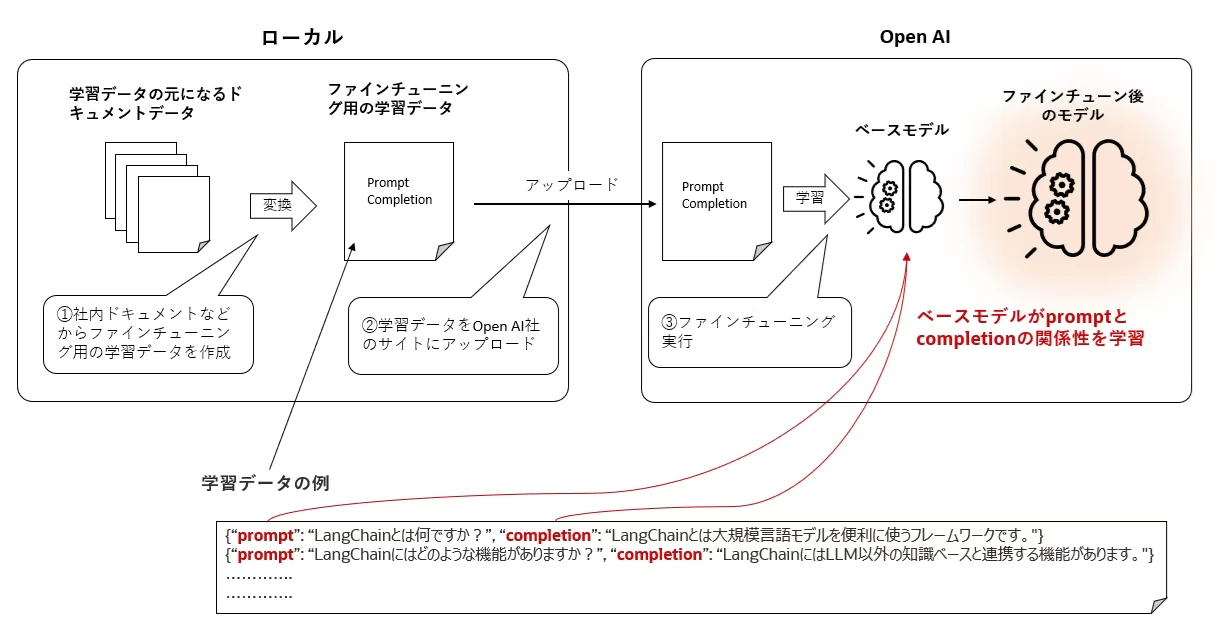
- GPTでのファインチューニングの作業フロー:
- ファインチューニング用の学習データを作成
- 作成した学習データをOpen AIのサイトにアップロードする
- アップロードした学習データを使ってベースモデルの学習を実行
- AWS Beddrockでもwebコンソール上から結構簡単にファインチューニングできるようになった。
- ラベル付きデータの作成もClaudeやGPT-4oなどのLLMを利用して簡単に自動生成することもできるようになった。
- ファインチューニングの効果は?
- ファインチューニングでは、既にある程度最適化されている数千億、数兆程度のパラメターをもつLLMの一部のパラメータが新たなデータの学習処理によって更新されることにより、新たな知識を得たことになります。文字通り、パラメータをチューニングするような処理になりますのでファインチューニングという名前が付いています。
- 数百件のデータセットはこのような大規模な言語モデルに与える影響って無視できるほど小さいであることが想像できるでしょう。
- 別の言い方にすると、効果的なファインチューニングには大量の高品質なデータが必須です。
- LLMを使って高品質なデータ作成ってわりと簡単になったのでは?
上記の記事にもありますが、LLMを使ってデータセットを生成することは技術的には比較的容易になってきています。しかし、ファインチューニングに効果的なデータセットを作成するには、まだいくつかの重要な課題があります。- データの質と多様性:
LLMが生成するデータは、元のデータセットやLLMの訓練データに偏りがある可能性があります。高品質で多様なデータセットを作成するには、単純な生成だけでなく、適切な戦略が必要です。 - タスク特有の要件:
特定のタスクや領域に特化したデータセットを作成する場合、LLMが必要な専門知識や文脈を正確に反映できるとは限りません。 - ハルシネーションの問題:
LLMは時として事実と異なる情報を生成することがあります。これは特に事実に基づく正確さが重要なタスクでは大きな問題となります。 - 場合によって、LLMが生成したデータセットを人間の目でチェックする必要もあります。
- データの質と多様性:
これらの理由から、LLMを使ってデータセットを生成することは技術的には可能ですが、効果的なファインチューニングのためのデータセット作成には、単純な生成以上の工夫と労力が必要です。
そのため、多くの場合、まずはRAGのようなアプローチを試すことが推奨されています。RAGは既存のデータを効果的に活用でき、ファインチューニングほどの大規模なデータセットを必要としないため、多くの組織にとってより実現可能な選択肢となっています。
4. チューニング済みモデルの他クラウドでの運用可能性
- オープンソースのLLMだけでなく、商用の大規模言語モデルもファインチューニングできる。 企業は特定の業界や用途に合わせてモデルをカスタマイズしたいというニーズがあります。商用LLMプロバイダーはこの需要に応えるためにファインチューニング機能を提供しています。
- 多くの商用LLMプロバイダーは、ファインチューニングされたモデルの使用に関して厳格な条件を設けています。例えば:
- プラットフォーム限定の使用:
Amazon Bedrockで fine-tuning されたClaude 3 Haikuは、Amazon Bedrock環境内でのみ使用することが想定されています。モデルをdownloadして、他のクラウド上で運用することができない。- 商用LLMのファインチューニングサービスには、通常、厳格なライセンスと利用規約が適用されます。これらの規約により、チューニング済みモデルの外部への持ち出しや他のプラットフォームでの使用が制限される
- 競合制限:
- LandingAIの利用規約では、ファインチューニングされたモデルを使用して競合する製品やサービスを開発することを禁止しています。
4. 組み合わせの可能性
RAGは最新かつ正確な情報提供が必要な場面、特に変化の激しい情報や広範なデータからの特定事実抽出に効果的です。一方、ファインチューニングは企業特有の文脈理解や一貫したコミュニケーションスタイル、複雑な業務プロセス理解や企業文化に根ざした創造的タスクに適しています。
実際の応用では、これらの手法を組み合わせることでより効果的なAIシステムを構築できる可能性があります。例えば、RAGで最新の詳細情報を取得し、ファインチューニングされたモデルでそれを広範なコンテキストで解釈することで、両アプローチの利点を活かせます。
3. RAGの汎用的な実装パターン
RAGの汎用的な実装パターンについて、基本的な構成から高度な手法まで詳細に説明します。
3.1 基本的なRAGパターン
1. RAGの基本構成
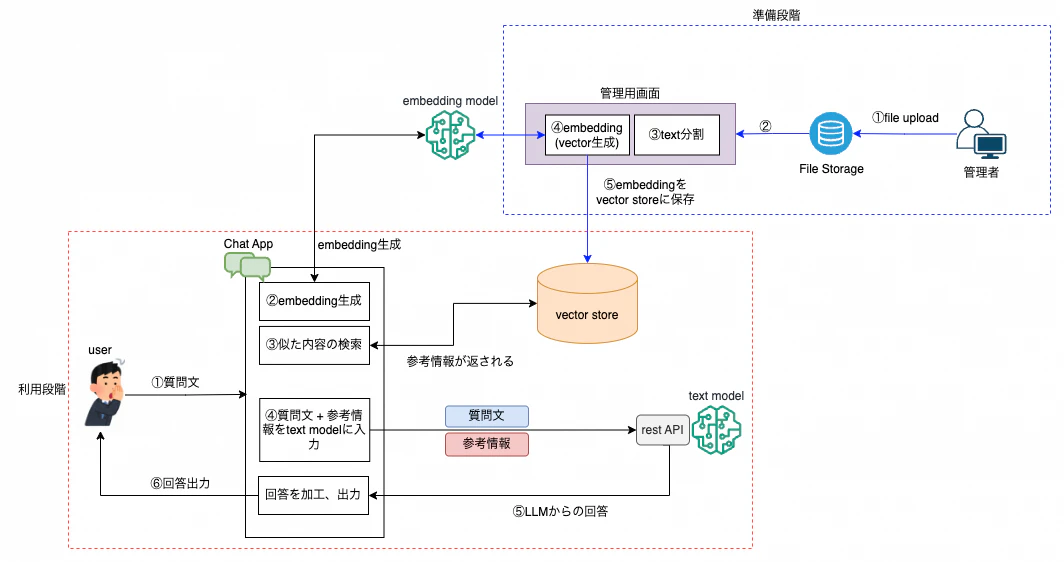
基本的なRAGパターンは、準備段階と利用段階の2つのフェーズで構成されます。
2. 基本ステップ
準備段階
-
構成コンポーネント:
- ファイルストレージ
- 管理用画面
- 埋め込み(
Embedding)モデル - ベクトルストア
-
ステップ:
- ファイル取り込み
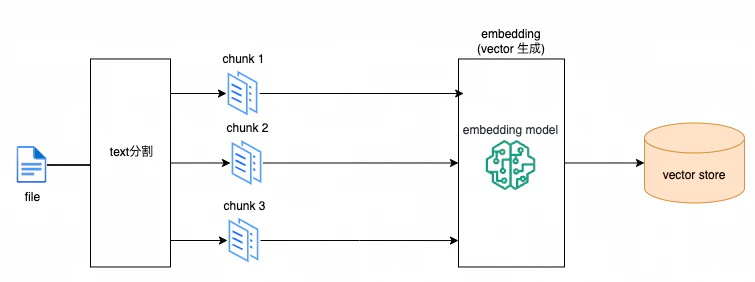
- text分割:長い文書を適切な長さのチャンクに分割
- 埋め込み生成(ベクトル化):embedding modelを利用してテキストデータをベクトル表現に変換
- ベクトルの保存(チャンク単位:原文 + ベクトルデータ + メタデータ)
- インデックス作成(オプション)
利用段階
-
構成コンポーネント:
- チャットアプリケーション
- 埋め込みモデル
- ベクトルストア
- LLMモデル
-
ステップ:
- ユーザーがチャットアプリで質問を入力
- 質問文を埋め込みモデルでベクトル化
- ベクトル化された質問文を使用してベクトルデータベースから関連テキストチャンク(関連性の高いテキストのみ抽出)を検索し、取得(ベクトルデータベースではベクトルだけではなく、チャンクの原文も持っている。実際に返されるのはチャンクの原文です)
- 参考情報(複数のチャンク)と質問文をLLMに入力
- LLMが回答を生成
- ユーザーに回答を出力
この基本的なパターンは、多くのRAGシステムの基礎となっています。LangChainやLlamaIndexなどのフレームワークを使用することで、このパターンを簡単に実装できます。
今回はここまでとします。今後のシリーズでは、より詳細な実装方法や応用例について解説していきます。