はじめ
生成AIを使用する際によく目にする「トークン数」という概念について、イマイチピンとこなかった。
今までなんとなく知っていたこと:
- LLMへの入力前に、文書がtokenizerによりトークン単位に分割される
- トークンは単語とは異なる概念で、1単語が必ずしも1トークンではない
- 日本語や中国語の文字は英語よりもトークン数が多い傾向がある
- 課金計算時には入力トークン数と出力トークン数の合計が使用される
- LLMごとにトークン数の計算方法が異なる
主な疑問点:
- なぜわかりやすい単語ではなく、あえて「トークン」という概念を導入したのか?
- 文書はどのようにトークンに分割されるのか?
- なぜ日本語や中国語の文字は英語よりもトークン数が多くなるのか?
ネットで調べても、トークンの概念を詳しく説明している記事が少なかったため、その解明を目指して、記事をまとめてみます。
なぜわざわざトークンという概念を導入したのか?
生成AIにおけるトークンとは?
- トークンは言語の意味単位により近い概念です。以下の要素を1つのトークンとして扱うことができます。
- 単語
- 部分的な単語
- 複数の単語
- 記号
- LLMごとにトークン化の方法が異なるため、使用するLLMによってトークン数が異なることがあります。
- 多くのLLMプロバイダーは、トークン化のためのツールを提供しています。これらのツールを利用することで、簡単にトークン数を計算できます。入力テキストのトークン数を事前に確認することができ、コストの見積もりや入力制限の管理に役立ちます。
- OpenAI社のトークン化のサイト
- Anthropic社のトークン化のサイト
文書はどのようにトークンに分割されるのか?
トークンを意味のある単位として理解する際、以下のような特徴があります。
-
一つの英語の単語が複数のトークンに分割される場合:
-
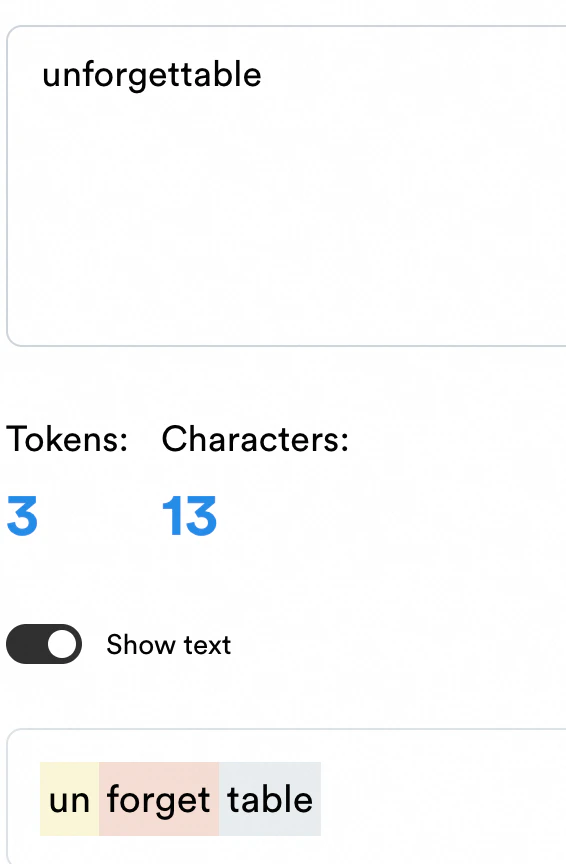
接頭辞や接尾辞を持っている単語は複数のトークンに分割されることがあります。
単語 ChatGPT token Claude token tokenization token+izationtoken+izationinternationalization international+izationinternational+izationunforgettable un+forgetableun+forget+able -
例:
unforgettable-
ChatGPTでのトークン化
-
Claudeでのトークン化
-
-
-
一つの日本語文字が複数のトークンに分割される場合:
-
ChatGPTでのトークン化
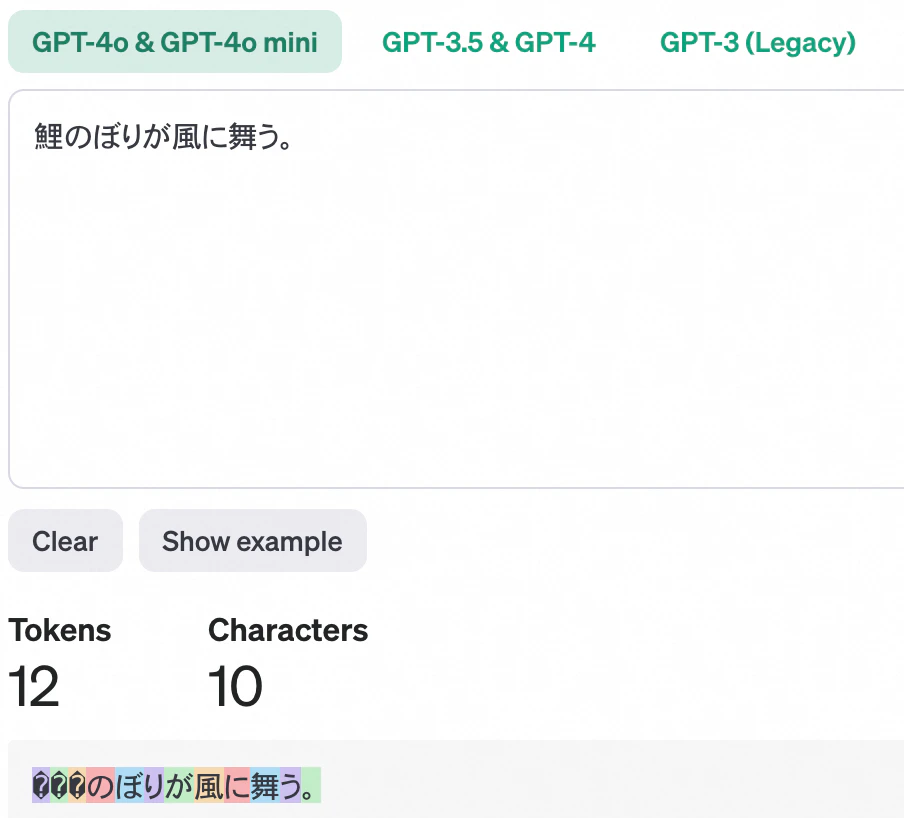
-
Claudeでのトークン化

文字 ChatGPTトークン数 Claudeトークン数 鯉 3 3 の 1 1 ぼ 1 2 り 1 1 が 1 1 風 1 2 に 1 1 舞 1 2 う 1 1 。 1 1 合計 12 15 -
-
複数の文字/単語を一つのトークンとする場合:特に頻繁に一緒に現れる単語や文字の組み合わせに対して行われます。
- 日本語の
東京:一つのトークン東京として扱われる場合がある - 縮約形(例:
don't):1つのトークンとして扱われる可能性が高い
文字 ChatGPTトークン数 Claudeトークン数 東京1 3 don't1 2 - 日本語の
-
同じ文字でも、異なる文脈ではトークン数が異なる場合がある:「東京は日本の東側に一致しています」という文

-
ChatGPTでのトークン化:
東京は、一つのトークンとして扱われています。東側は2つのトークンとして扱われています。 -
Claudeでのトークン化:
東京も、東側もそれぞれ2つのトークンとして扱われています。


トークン単位で分割することには、文字単位の分割と比較していくつかの重要な利点
-
意味のある単位での処理
- トークンは文字や単語よりも意味のある言語単位を表現できます。これにより、モデルは言語の構造をより効果的に理解し処理できるようになります。
-
多言語対応
- トークンベースのアプローチは、異なる言語間での処理の一貫性を提供します。例えば、英語では1単語が1トークンに近くなりますが、日本語では1文字が1〜3トークンになります。これにより、言語の特性に関わらず、同じモデルで多言語を扱えます。
-
データ圧縮と処理速度
- 頻出する単語やフレーズを1つのトークンとして扱うことで、データ量を削減し、処理速度を向上させることができます。
-
未知語や珍しい単語への対応
- サブワードトークン化を使用することで、モデルは未知の単語や珍しい単語をより小さな単位で理解できるようになります。
-
モデルの制御とリソース管理
- トークン数を基準にすることで、モデルの入出力量やコンテキストウィンドウのサイズを正確に制御できます。これは、計算リソースの管理や課金システムの設計に役立ちます。
-
多言語対応の向上:
- 日本語のような言語では、1文字が複数のトークンに分割されることがあります。これにより、漢字やひらがななど、文字の種類による意味の違いをモデルが認識しやすくなります。
これらの利点により、トークン単位の分割は現代の大規模言語モデルにおいて標準的なアプローチとなっています。文字単位の分割と比較して、言語処理の効率性、精度、そして柔軟性を大幅に向上させることができるのです。
同じ情報量を表現する場合でも、なぜ日本語や中国語は英語よりも多くのトークンを必要とするのか?
-
多くのLLMは主に英語のデータセットで訓練されています。そのため、英語のトークン化が最適化される一方、他の言語では非効率になる傾向があります。
-
多くのLLMは、
BPE(Byte Pair Encoding)などのサブワード分割アルゴリズムを使用します。これらのアルゴリズムは英語に最適化されていることが多く、CJK言語(中国語、日本語、韓国語)では効率が低下します。 -
トークン化アルゴリズムは一般的に出現頻度に基づいて単語やフレーズを分割します。英語のデータセットで学習されたモデルは、
CJK言語の頻出パターンを効率的に捉えられない可能性があります。 -
日本語では、文の意味を明確にするために多くの助詞や助動詞が使用されます。これらは追加のトークンとして数えられます。
文 ChatGPT token分割 token数 The cat is cute. The+cat+is+cute+.5 ねこはかわいいです。 ね+こ+は+かわ+いい+です+。7 猫は可愛いです。 猫+は+可+愛い+です+。6 Today is a nice day. Today+is+a+nice+day+.6 きょうはいいてんきです。 き+ょう+は+いい+て+ん+き+です+。9 今日は良い天気です。 今日は+良+い+天+気+です+。7 -
同じ情報量を表現する場合、トークン数は一般的に英語 < 漢字 < 仮名 の順で多くなります。
-
日本語(特に仮名)が英語よりも冗長な表現になりやすいこと、また漢字の使用が日本語のトークン数を削減する効果があることが言えそうです。
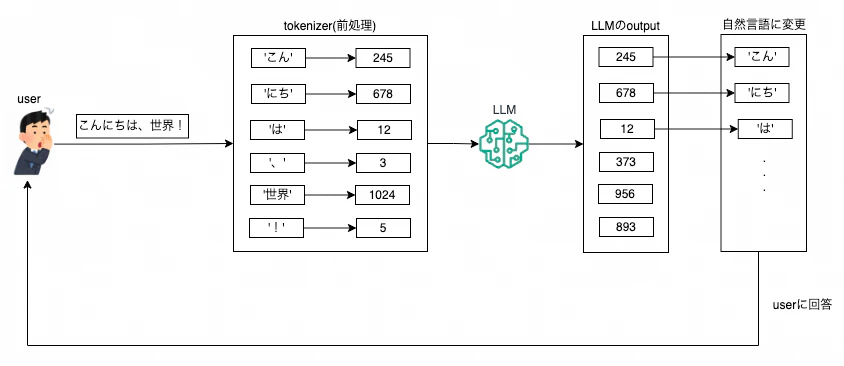
ChatGPTなどのLLMを利用する際の全体の流れ
-
ユーザー入力
- ユーザーが自然言語でテキストを入力します。例えば、「こんにちは、世界!」
-
tokenizerによるトークン化:この処理はユーザーには見えない形で行われます。
- 入力されたテキストが自動的にトークンに分割されます。例えば、['こん', 'にち', 'は', '、', '世界', '!']
- トークンID変換(エンコーディング、あるいはベクトル化):[245, 678, 12, 3, 1024, 5]
-
LLM入力
- トークン化された数値データ(ID)がLLMに入力されます。
-
LLM処理
- LLMが入力を処理し、応答のトークンIDを生成します。
-
デトークン化
- LLMの出力がトークンから自然言語テキストに変換されます。
-
ユーザー出力
- 変換されたテキストがユーザーに表示されます。
まとめ
- トークンは文字や単語よりも意味のある言語単位を表現できます。これにより、モデルは言語の構造をより効果的に理解し処理できるようになります。
- 単語、部分的な単語、複数の単語、記号などを1つのトークンとして扱うことができます。
- LLMごとにトークン化の方法が異なるため、同じ文章でもトークン数が異なる場合があります。
-
同じ情報量を表現する場合、トークン数は一般的に英語 < 漢字 < 仮名 の順で多くなります。例えば、英語の文章に対して日本語は約2.12倍、中国語(標準中国語)は約1.76倍のトークン数になるという調査結果もあります。
- 英語では1単語が1トークンに近くなりますが、日本語では1文字が1〜3トークンになります。
- 日本語や中国語は1文字に多くの意味が込められていることが多く、それを表現するために複数のトークンが必要になります。
- 日本語では、文の意味を明確にするために多くの助詞や助動詞が使用されます。これも日本語のトークン数が多いという原因の一つです。
- 漢字の使用が日本語のトークン数を削減する効果がありそうです。