1. MySQLの全体的なアーキテクチャ

大きく分けると、Server Layerとstorage engine layerという2つ層があります。
- Server layer(SQL Layer):
-
Connector:- クライアント接続、権限認証、セキュリティチェックなどを処理
- 様々な言語(Java, Python, PHPなど)向けのコネクタが存在し、それぞれのプロトコルに応じた通信をサポート
-
Query Cache:- MySQLにおいて実行されたSELECTクエリの結果をキャッシュし、同じクエリが再度実行された際にデータベースへのアクセスを避け、キャッシュされた結果を返すことでパフォーマンスを向上させるための機能
- 更新操作(INSERT、UPDATE、DELETE)の度にキャッシュされた結果を無効化する必要があり、キャッシュヒット率が低下し、結果としてシステム全体のパフォーマンスが悪化してしまうという課題があったため、MySQL 8.0から
Query Cacheが削除された - 代替手段として、他のキャッシングメカニズム(例:
MemcachedやRedis)を利用することで、より効率的かつ柔軟なキャッシング技術がおすすめです
-
Parser:- クライアントから送信されたSQLクエリを解析し、その構文が正しいかどうかをチェック。もしクエリ文に間違いがありましたら、エラーが返される。
elect * from t where ID=1; ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'elect * from t where ID=1' at line 1
- クライアントから送信されたSQLクエリを解析し、その構文が正しいかどうかをチェック。もしクエリ文に間違いがありましたら、エラーが返される。
-
Optimizer:- 解析されたSQLクエリに対して最適な実行計画を生成(クエリの実行順序や使用するインデックス、結合方法などを決定)し、最も効率的なクエリ実行方法が選択される
-
Executor:-
Optimizerによって生成された実行計画に基づいてSQLクエリを実行します。データベースからデータを取得し、必要な操作(挿入、更新、削除など)を行い、クライアントに結果を返す -
Executorは、ストレージエンジン提供しているAPIを呼び出して、データの読み書きを行う
-
-
- Storage Engine layer:
- データの読み書きやインデックスの管理、トランザクション処理などを行います
- InnoDB、MyISAM、Memory、CSVなど複数のストレージエンジンをサポートしており、それぞれ異なる特徴と用途があります
- ストレージエンジンはMySQLのpluginとして機能する。他のMySQLプラグインと同様にサーバーにロードされます。サーバー起動時にロードすることも、実行時に手動でロードすることも可能です。これにより、特定の用途に応じてストレージエンジンを追加・削除可能
- InnoDB:トランザクション処理、外部キー、クラッシュリカバリをサポートし、MySQL5.5.5以降のバージョンではデフォルトのストレージエンジンになっています。
-
テーブルごとにストレージエンジンを選択でき、用途に応じて最適なエンジンを使用することが可能
- つまり、ストレージエンジンはテーブル単位
- テーブル作成する時に明示的にストレージエンジンを指定しない場合はデフォルトのストレージエンジンInnoDBが利用される
- トランザクション機能はMySQLのServer層ではなく、ストレージエンジンが実装しております。MySQLでトランザクションをサポートしているストレージエンジンはInnoDBのみです
ストレージエンジンの詳細の種類は以下の記事をご参考ください。
2. MySQLでトランザクションの実行フロー
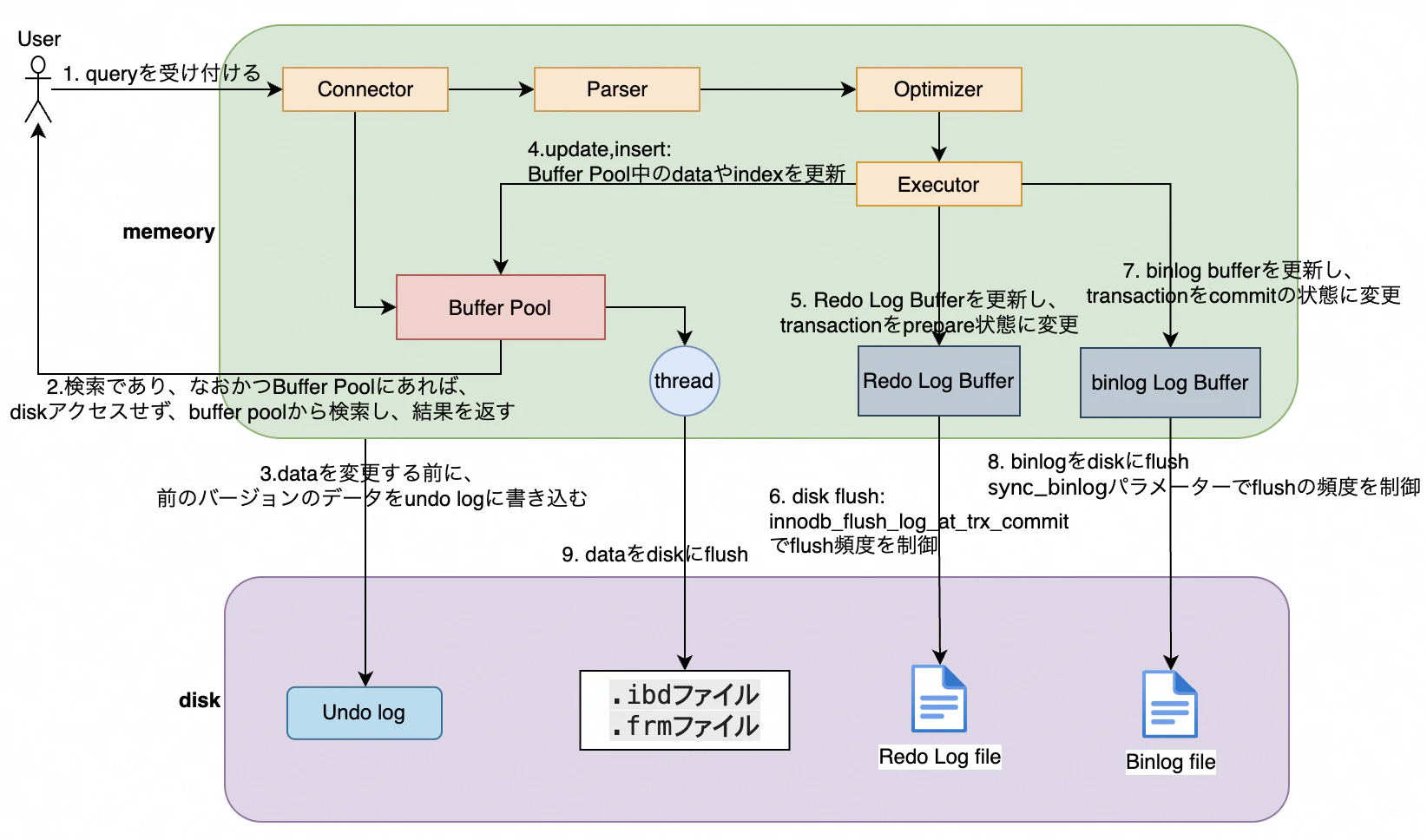
-
Buffer Pool-
Buffer Poolは、データベースのテーブルやインデックスページをキャッシュするためのメモリ領域です。頻繁にアクセスされるデータをpageという単位でメモリに保持することで、ディスクI/Oの負担を削減し、クエリのパフォーマンスを向上させます
-
-
Redo Log Buffer-
Redo Log Bufferは、トランザクションの変更内容を一時的に保持するメモリ領域です。トランザクションがコミットされると、Redo Log Bufferの内容がディスク上のRedo Logファイルに書き込まれます。これにより、システムクラッシュ時に未処理のトランザクションを復元(crash recovery/crash safe)可能です。
-
- Binlog Buffer
- Binlog Bufferは、バイナリログ(Binlog)イベントを一時的に保持するメモリ領域です。トランザクションがコミットされると、Binlog Bufferの内容がディスク上のバイナリログファイルに書き込まれます。これにより、レプリケーションや
PITR(ポイントインタイムリカバリ)が可能になります
- Binlog Bufferは、バイナリログ(Binlog)イベントを一時的に保持するメモリ領域です。トランザクションがコミットされると、Binlog Bufferの内容がディスク上のバイナリログファイルに書き込まれます。これにより、レプリケーションや
-
WAL(Write Ahead Log)の仕組み :- なぜデータの変更ごとにディスクに直接書き込まないのか?
- データの変更ごとにディスクに直接書き込むと、ランダムなディスクアクセスが増え、パフォーマンスが大幅に低下します。
- ディスクへの書き込みは時間がかかり、書き込んでいる途中でデータベースがクラッシュしてしまう場合、データが不完全な状態で残るため、クラッシュリカバリが難しくなります。つまり、トランザクションのACID特性の一つである一貫性(Consistency)が保証できなくなります。
- ということでMySQLではWALの仕組みを利用して上記の課題を解決しています。
簡単に言うと、データの変更をディスクに書き込む前には一旦ログに記録しましょう。
- なぜデータの変更ごとにディスクに直接書き込まないのか?
- ランダム書き込みって何?
データファイルへの変更は、テーブル内の行やインデックスの位置に依存します。これらの位置は物理的にディスク上の異なる場所に存在するため、更新操作が発生すると、ディスクのさまざまなセクタにアクセスして書き込みを行う必要があります。このため、データファイルの変更はランダムなディスク書き込みになり、非常に遅いです。 - ログも結局diskに記録されますが、なぜデータファイルの変更よりは早いのか?
ログの書き込みは連続(シーケンシャルな書き込み)的に行われます 。シーケンシャルな書き込みは連続的にデータを追加するため、ランダムな書き込みよりは遥かに早いです。
これによってデータベースがクラッシュした場合でも、ログを基にデータベースを復元できるため、データの整合性が保証されます。 - メモリへの書き込み、Diskへのランダムな書き込み、Diskへのシーケンシャルな書き込みの速度比較
- メモリへの書き込み
- 非常に高速、通常、数ナノ秒から数マイクロ秒で行われます。
- 速度: 数GB/sから数十GB/s
- Diskへのランダムな書き込み
- ランダムアクセスは、ディスクの異なる場所にランダムにデータを書き込むため、シーク時間が発生し、遅くなります。
- 速度(SSD): 数十MB/s
- Diskへのシーケンシャルな書き込み
- シーケンシャルアクセスは、ディスク上の連続した場所にデータを書き込むため、シーク時間が少なく、効率的です。
- 速度(SSD): 500MB/sから3GB/s
-
select文の実行流れ:
- 必要なデータがバッファプールに存在する場合、データベースエンジンはメモリから直接データを取得します。これにより、ディスクアクセスを避け、非常に高速な応答が可能になります
- 必要なデータがバッファプールに存在しない場合、データベースエンジンはディスクからデータを読み込んで、buffer poolに入れます。これにより、次回以降のアクセスが高速になります
-
update文の実行流れ:
- commit開始
- Buffer pool内のデータを更新(この時のデータページは
ダーティページと呼ばれる) - binlog, redolog, undo logを更新
- トランザクションをcommit
- 設定した更新ポリシーに従って定期的にディスクにフラッシュする、
ダーティページフラッシングという処理を行っている
dataはbuffer pool中のデータだけを更新すれば、trancationは完了とみなすのでしょうか。
トランザクションが完了したとみなされるのは、以下の条件が満たされたときです。
- Redo logに変更が記録され、必要に応じてディスクにフラッシュされている。
- Binlogに変更が記録され、sync_binlogパラメータに従ってディスクにフラッシュされている
- Buffer pool内のデータが更新されている
3.redo log
3.1 redo logとは
- redo Logは、データベースに対する変更を再実行するために使用されるログファイルです。クラッシュリカバリの際に重要な役割を果たします。
- redo logは、
InnoDBエンジンが出力するログです。つまり、InnoDB以外のストレージエンジンはそもそもredo logが存在していません。 - そもそもInnoDBは最初MySQLについていたものではありません。InnoDBはInnobase社(2005年10月にInnobase社がオラクルに買収)の製品であり、プラグインとしてMySQLに導入したもので、binlogだけではクラッシュセーフにならないため、InnoDBで別のログシステムであるredo logを使ってクラッシュセーフの機能を無理矢理に実現しました
3.2 redo log更新の流れ
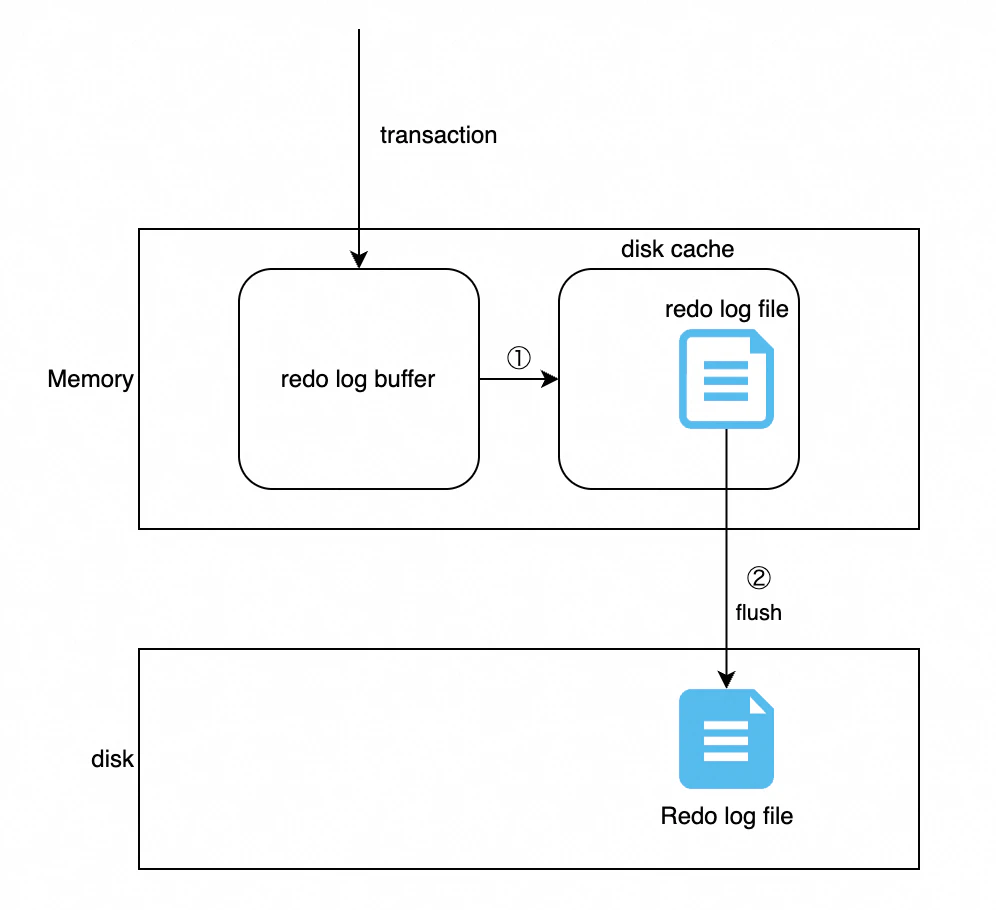
前提知識
-
disk cache(Page Cache):
- disk cacheは、ファイルシステムのCache(メモリ)に存在し、データが物理ディスクに書き込まれる前に一時的に保存されるメモリの一部です
- writeシステムコールの呼び出しでデータをPage Cacheに書き出します
このキャッシュは、ディスクへの書き込み操作を効率化し、パフォーマンスを向上させるために使用されます。 - キャッシュされたデータは、すぐに物理ディスクに書き込まれるわけではなく、一定の条件(例えば、キャッシュが満杯になったときや一定時間が経過したとき)でフラッシュされます。
-
flush:
flushとは、disk cacheに保存されたデータが物理ディスクに書き込まれる操作を指します。これにより、データはディスクに 永続化され、電源障害やシステムクラッシュ時にも失われないようになります。 -
disk cacheとflushの関係:
redo log bufferにデータが書き込まれると、まずdisk cacheに保存されます。この時点ではデータはまだ物理ディスクに永続化されていません。
disk cacheに保存されたデータが物理ディスクにflushされることで、初めてデータが永続化されます。
WALの具体的な流れ
- トランザクション開始:
トランザクションが開始されると、データベースの変更操作(INSERT、UPDATE、DELETE, createなどデータの読み込み以外の操作)がredo log bufferに書き込まれます。 - disk cacheにredo log fileを書き込む
redo log bufferの内容が一旦memoryにあるdisk cacheに書き込まれます - diskにredo log fileはdiskにflushされるを書き込む
ディスク上のredo logファイルに書き込まれます。これにより、変更内容が永続化されます。 - データファイルへの反映:
一定のタイミングで、ログファイルに書き込まれた変更内容が実際のデータファイルに適用されます。これをデータのチェックポイントと呼びます。 - クラッシュリカバリ:
システムクラッシュが発生した場合、起動時にredo logファイルを使用して、未適用の変更内容をデータファイルに反映し、一貫性を保ちます。
このWALの仕組みにより、MySQLは高いデータ一貫性と耐障害性を実現しています。
3.3 redo logの更新タイミングについて
innodb_flush_log_at_trx_commitはredo log bufferの内容をdisk上のredo logファイルに書き出すタイミングを制限するパラメーターです。以下の3つの値があります。
値0:
- トランザクションがコミットされてもredo log bufferは即座にmemory上のdisk cache)に書き込まず、1秒ごとに書き込むということ(つまり上記画像の①処理を1秒ごとに実行)
- 書き込む頻度が1秒ごとなので、もしインスタンスに障害がおき、複数のトランザクションがこのタイミングで失われる可能性がある
値1 (デフォルトの設定)
- トランザクションがコミットされるたびに、ログバッファがディスクにフラッシュされます
- 最も安全な設定で、トランザクションのデータ損失を最小限に抑えます。(書き込む頻度がtransactionごとなので、失うとしても1 transactionであり、非常に堅牢です。)
- ディスクI/Oの負荷が高くなり、パフォーマンスが低下する可能性があります
値2:
- トランザクションがコミットされるたびに、ログバッファがdisk cache上のログファイルに書き込まれます
- ログファイルに書き込まれたデータは、1秒ごとにディスクにflushされます
- トランザクションのデータ損失のリスクが設定値0よりも低くなります。パフォーマンスとデータの安全性のバランスが取れた設定です
- 1秒間のデータ損失のリスクは依然として存在しますが、設定値0よりは安全です
3.4 redo logの数とサイズについて
redo logファイルの個数とサイズが固定であり、ループで使用します。最後のファイルが一杯になったら、最初のファイルに戻って、再利用します。
redo logはデータpageへの変更を記録するため、Buffer Poolがデータページをディスクにフラッシュした場合、redo log中のdata pageが無効になり、新しいログは無効になったデータpage上書きすることになります。
MySQLでredo logファイルの個数やサイズを確認する方法:
# redo logファイルの個数の確認:
SHOW VARIABLES LIKE 'innodb_log_files_in_group';
+---------------------------+-------+
| Variable_name | Value |
+---------------------------+-------+
| innodb_log_files_in_group | 2 |
+---------------------------+-------+
# redo logファイルのサイズの確認:
SHOW VARIABLES LIKE 'innodb_log_file_size';
+----------------------+------------+
| Variable_name | Value |
+----------------------+------------+
| innodb_log_file_size | 1048576000 |
+----------------------+------------+
これらの設定は、my.cnf(またはmy.ini)設定ファイルにも記載されています。以下のように記述されています:
[mysqld]
innodb_log_file_size = 1000M
innodb_log_files_in_group = 2
3.5 redo logの用途→crash-safe
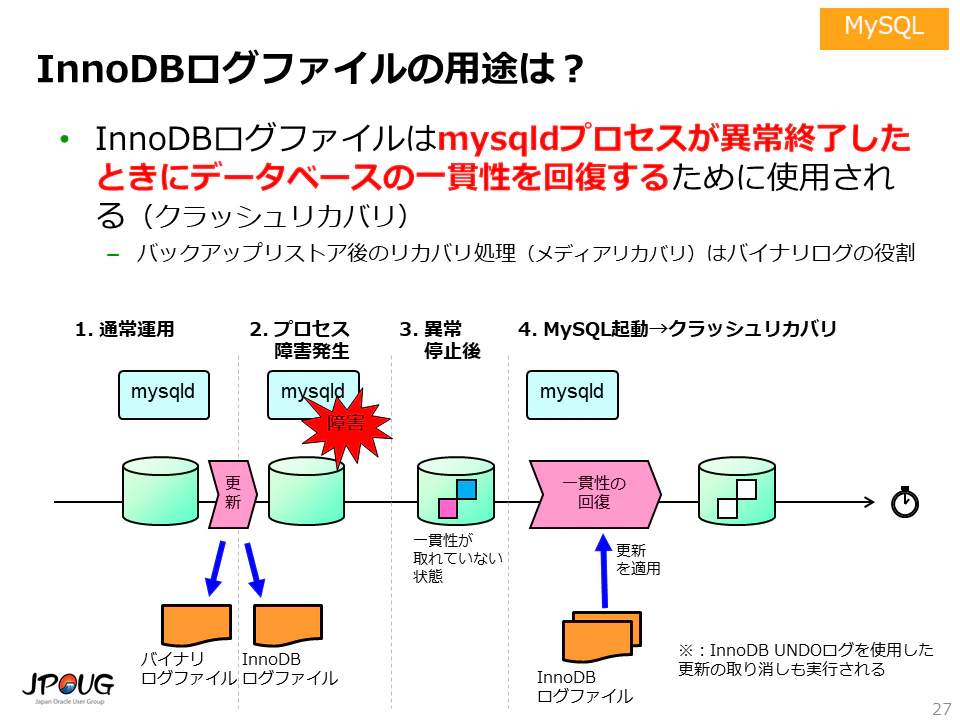
ダーティページフラッシングがまだ終了していないのに、何らかの理由でMySQLがcrashし(ダウンして再起動)した場合、Buffer Pool内の変更されたデータのディスクへのフラッシュが間に合わず、データが消えてしまい、トランザクションのACIDの永続性を保証できなくなります。
この問題を解決するために、redo logが導入されました。REDOログは、その名の通りdatabaseがcrashした時にやり直すことに焦点を当てたものです。 これは、特定の行や列がどのように変更されたかではなく、データベースの各データpageに加えられた変更を記録し、トランザクションコミット後にデータの物理ページを回復するために使用され、最後のコミット位置までしか回復できません。
MySQLがダウンして再起動してしまった時は、システムが自動的にredo logをチェックし、ディスクに書き込まれていないデータを redo logからMySQLにリストアすることによって、Innodb エンジンのcrash-safeを実現しています。
MySQL起動する時に、前回正常終了したか異常終了したかにかかわらず、起動時に必ずリカバリ操作を行います。
3.6 Redo Logの中身
以下に、redo logの中身をわかりやすく説明します。
- Redo Logの構造
Redo Logは、次のような情報を含むエントリで構成されています。- Log Sequence Number (LSN): 各エントリに割り当てられた一意の番号で、ログの順序を管理します
- Transaction ID: エントリが属するトランザクションのID
- Page ID: 変更が加えられたデータベースページのID
- Offset: ページ内の変更が行われた位置
- Before Image: 変更前のデータ
- After Image: 変更後のデータ
- 具体例
# 以下のようなテーブルがあるとします: CREATE TABLE employees ( id INT PRIMARY KEY, name VARCHAR(50), salary INT ); INSERT INTO employees (id, name, salary) VALUES (1, 'Alice', 5000), (2, 'Bob', 6000), (3, 'Charlie', 7000); # このテーブルの給料を更新するSQLステートメントを実行します: UPDATE employees SET salary = 7000 WHERE id = 1;
この場合、redo logの中身は次のようになります:
LSN: 10001
Transaction ID: 12345
Page ID: 200
Offset: 50
Before Image: (id: 1, salary: 5000)
After Image: (id: 1, salary: 7000)
- Redo Logの働き
クラッシュが発生した場合、redo logは次の手順で使用されます:- リカバリの開始: LSNを基にログエントリを順に処理します。
- Before Imageの確認: 各エントリの変更前のデータを確認します。
- After Imageの適用: 各エントリの変更後のデータを適用し、データベースの整合性を保ちます。
binlogのようにSQLクエリを再実行するのではなく、データベースのディスクページに直接変更を反映させるプロセスです。
具体的には、ログエントリに記録されたafter imageのデータを該当するデータページの指定されたオフセットに直接書き込みます。ですので、binlogの適用よりは遥かに早い。
4. binlog
4.1 binlogとは
- データベースに対するすべての変更はbinlogに記録されます。つまり、SELECTやSHOWなどデータベースを変更しない操作は記録されない。
binlogに記録される代表的なクエリ:- データ変更系DML:
insert,update,delete - DDL: tableやindexの作成、更新、削除など
-
create table,alter table,drop table -
create index,alter index,drop index
-
- トランザクション管理クエリ:
begin,commmit,rollback
- データ変更系DML:
- 用途:主にレプリケーションやポイントインタイムリカバリ(PITR)に使用
- データベースに対する変更を論理的に記録するため、論理ログと呼ばれます。これは、物理的なデータブロックの変更内容を直接記録する物理ログとは対照的です。
- binlogは、Server層が出力するログです。つまり、どんなストレージエンジンを使ったとしても、かならずbinlogログ利用できる ということです
- binlogはデフォルトで出力される設定ですが、不要な場合は出力させないことも可能
問題となるクエリーを特定するためには実行されたすべてのクエリ文が記録されるgeneral_logを使ってください。
4.2 binlogのフォーマット
MySQLのバイナリログ(binlog)のデータフォーマットには、以下の3種類の形式があります。
-
ステートメントベースロギング(Statement-Based Logging, SBR)
- 説明:
- データベースに対して変更を伴うSQLクエリ文そのものをログに記録します。MySQL 5.6とそれ以前のデフォルト値。
- そのクエリは何万行を更新あるいは削除したとしても、binlogにはクエリ文の一行しか記録しません
- 実質的にデータベースに変更を行わないUPDATE文やdelete文もbinlogに記録される。
- 利点:データ量が少なく、簡単な変更に対して効率的です。
- 欠点:一部の非決定的な関数(例:NOW())やストアドプロシージャの挙動が異なる可能性があります。
UPDATE employees SET salary = salary WHERE id = 1;
このUPDATE文は、salaryカラムの値を同じ値に更新しようとしています。実質的にデータベースの内容には変更がありませんが、このSQL文はbinlogに記録されます。なぜなら、statement-based binlogは実行されたSQL文そのものを記録するためです。
: - 説明:
-
ローベースロギング(Row-Based Logging, RBR)
- 説明:
- 変更前の行と変更後の行のデータそのものが記録される。
- 5.7からはデフォルト値になった。
- 非決定的な関数(例:NOW())であっても、実行した結果が記録されるため、一貫性が担保できる
- 実質的にデータベースに変更を行わないupdate文やdelete文はbinlogに記録されない
- DROP、TRUNCATE、ALTERなどのDDLはSTATEMENTの形式でbinlogに記録されます。これは、DDLステートメントがテーブル構造の変更を行うためであり、行ごとの変更ではないからです。
- 利点:すべてのデータ変更が確実に再現可能で、一貫性が保たれます。非決定的な操作(例:NOW()関数)による不一致を防ぎます。
- 欠点:行ごとのデータ変更をすべて記録するため、バイナリログのサイズが大きくなりやすいです
- 説明:
-
混合ベースロギング(Mixed-Based Logging, MBR)
- 説明:SBRとRBRを組み合わせた形式で、デフォルトではSBRを使用し、非決定的な関数(例:NOW()関数)などが含まれる場合はRBRに切り替えます
- 利点:両者の利点を組み合わせ、最適な形式を自動的に選択します。
- 欠点:一見これは一番よさそうな方法ですが、PITR(Point-In-Time Recovery)を使用してデータを復旧することができません。
3つのフォーマットの違いを例を用いて、わかりやすく説明してみます
初期データ:まず、以下のようなテーブル employees があるとします:
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50),
salary INT
);
INSERT INTO employees (id, name, salary) VALUES
(1, 'Alice', 5000),
(2, 'Bob', 6000),
(3, 'Charlie', 7000);
- データ変更
-- where指定せずに給料を7000に更新するSQLステートメントを実行
UPDATE employees SET salary = 10000;
-
ステートメントベースロギング(Statement-Based Logging, SBR)
バイナリログには、上記のSQLステートメントがそのまま記録されます。この形式は、SQL文が実行されたそのままの内容を再現するために使用されます。 -
ローベースロギング(Row-Based Logging, RBR)
この更新に対して、ローベースロギング(RBR)では変更前の行と変更後の行のデータそのものが以下のような形式で記録されます:
Table: employees
Event: Update
Row before:
id = 1, name = 'Alice', salary = 5000
id = 2, name = 'Bob', salary = 6000
id = 3, name = 'Charlie', salary = 7000
Row after:
id = 1, name = 'Alice', salary = 10000
id = 2, name = 'Bob', salary = 10000
id = 3, name = 'Charlie', salary = 10000
3. 混合ベースロギング(Mixed-Based Logging, MBR)
デフォルトでSBL形式を使用し、特定の状況でRBRに切り替えます。この場合、特に複雑なクエリや非決定的な関数が含まれる場合にRBRが使用されます。
UPDATE employees SET salary = 10000;
が基本的に記録されますが、必要に応じて行ごとの詳細な変更も記録されます。
4. MBRの場合は、なぜPITRが利用できないか?
-
UPDATE employees SET salary = 7000 WHERE name = 'Alice';が実行される場合は、binlogに該当のSQL文のみが記録され、更新前の具体的なデータ(更新前のsalaryの値)は記録されません。 - このため、PITR(Point-In-Time Recoverr)を使用してデータを復旧する際には、binlogに記録されたSQL文を再実行することになります。ここで問題となるのは、更新前の具体的なデータがわからないため、PITRによって完全なデータ復旧ができない場合があることです。
- 例えば、Aliceのsalaryが5000だった場合、
UPDATE employees SET salary = 7000 WHERE name = 'Alice';を再実行すると、Aliceのsalaryは確かに7000になりますが、5000という元の値を復旧することはできません。。
4.3 binlogの用途
1. データのレプリケーション
- primary instaceからstand-by instanceやread-only instanceへのデータレプリケーション

primary(マスター)側でBinlogを有効にしてstand-by、あるいはread-only側に送信し、そこでBinlogを再生(binlog中のクエリを再実行)することでデータのレプリケーションを実現しています。 - サードパーティのCDC(Change Data Capture)ツールを利用して、データをリアルタイムに他のシステムに同期する用途にも活用できます。
例えば、CDCツールでbinlogを解析して、データをリアルタイムにデータウェアハウスやElasticsearch、TableauなどのBIツール、Redisなどのキャッシュシステム、Apache Kafkaなどのメッセージングシステムに同期できます。

- よく利用されるCDCツール:
- AWS Database Migration Service (DMS)
- Apache Kafka
- CData Sync
- Google Cloud Datastream
- CDCの利点
- リアルタイムデータ同期: 変更が発生した瞬間にデータをキャプチャして、他のシステムに即時反映できます
- イベント駆動アーキテクチャ: データ変更イベントをトリガーとして、他のプロセスやサービスを動作させることができます
2. PITR(ポイントインタイムリカバリ)
誤って削除したデータを復元したり、特定のタイミングの状態に戻したいしたりする場合、binlogを利用します。
データベースのバックアップをベースに復元し、バックアップ時点から指定時点の間のbinlogを適用することで、指定時点のデータを復元できます。
5. redo logとbinlogの違い
| redo log | binlog | |
|---|---|---|
| 存在理由 | データファイルの更新は非常に遅いランダムな書き込みであり、早いシーケンシャルな書き込みできるredo logにデータを一時的に記録 | アーカイブ用(履歴データを記録) |
| 利用シーン | 1. crash-safe/crash recovery(transactionのACID特性の中の一貫性を保つために、データベース異常終了後、起動する時に必ずcrash recoreryを実施) :あくまでもMySQL内部用途 | 1. data replication ・master instanceからstand-by or read-only instanceへのデータ同期 ・third partyのtoolでbinlogを利用してデータをリアルタイムに同期(CDC) 2. バックアップからデータ復元:point-in-time recovery ※つまりMySQLの内部ではない外部ツールや人間が必要な時に利用 |
| 記録内容 | データベースの変更の物理的な記録(どのデータページが変更されたか,ページ内の変更が行われた位置,更新前のレコードの値,更新後のレコードの値など) | 1. Statement-Based Logging(SBR):更新系(insert,update,delete,createなど読み取り以外)クエリ文そのものが記録される 2. Row-Based Logging(RBR): 変更前の行の内容と変更後の行の内容そのものが記録される 3. Mixed-Based Logging(MBR)SBRとRBRを組み合わせた形式で、デフォルトではSBRを使用し、必要に応じてRBRに切り替える |
| ACID |
一貫性(Consistency)を実現 |
永続性 (Durability)を実現 |
| 物理/論理 | 物理ログ | 論理ログ(RBRの場合でも論理ログ※) |
| 実現のlayer | innodb storage engineのログ ※InnoDB以外のストレージエンジンはそもそもredo logがありません |
Server layerのログ ※どんなストレージエンジンを使ったとしてもかならずbinlogの仕組みがある(ログ自体の出力をoffにすることが可能) |
| 記録方式 | 1. ファイルの個数とサイズが固定 2. ラウンドロビン(ループ)方式で最後のファイルが一杯になったら、最初のファイルに戻って再利用(上書き方式) |
1. ファイルのmax size制限がありますが、ファイルの個数に制限がありません。 2. binlogの合計のサイズはある程度超えると古いファイルが自動的に削除される。 3. append方式、上書きしません |
| diskに書き込むタイミング | transaction開始する時 | transaction commitする時 |
-
ROW-based binlogが論理ログと呼ばれる理由
- 論理ログの定義:
論理ログは、データベースに対する操作や変更内容を論理的に記録します。これは、データベースがどのように変更されたかを示すものであり、SQL文や行の変更内容が含まれます。 - 物理ログの定義:
物理ログは、データベースの物理的なデータブロックの変更を直接記録します。これはデータの実際の物理的な配置や構造の変更を記録します。
例えば、InnoDBのredo logは物理ログであり、データページの物理的な変更を記録します。
ROW-based binlogでは、各行の変更内容が記録されます。これはデータの物理的な配置や構造の変更ではなく、行のデータがどのように変更されたかを記録するものです。
したがって、ROW-based binlogもデータベースの論理的な操作を記録するものであり、広義には論理ログとみなされます。 - 論理ログの定義: