はじめに
ディープラーニングがどんなものか学ぶためにpytorchを使って分類を実施してみた。
あとはGPUでちゃんと回せるかも確認。
環境
windows 10
python 3.8.10
torch 1.9.0+cu111
使うデータセット
下記のサイトから。DryBeanの品種について。
種類としてはSEAKR、BARBUNYA、BOMBAY、CALI、HOROZ、SIRA、DERMASONの7種類だそう(読み方がよくわからないけど)。
ラベルの変換はエクセルで実施済。
内容
データセットの準備
import pandas as pd
import numpy as np
import torch
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from torch.utils.data import random_split
from torchvision import transforms
from tqdm import tqdm
import matplotlib.pyplot as plt
# ファイルの読み込み
df = pd.read_csv('Dry_Bean_Dataset.csv')
# データを説明変数と目的変数にわける
data = df.drop('Class',axis=1)
target = df.iloc[:,-1]
# データ数の確認
df.shape
データ数は、(13611, 17)となった。全体は13611個のデータで、要素数が17(ラベル除くと16)となっている。
# tensor形式へ変換
data = torch.tensor(data.values, dtype=torch.float32)
target = torch.tensor(target.values, dtype=torch.int64)
# 目的変数と入力変数をまとめてdatasetに変換
dataset = torch.utils.data.TensorDataset(data,target)
# 各データセットのサンプル数を決定
# train : val : test = 60% : 20% : 20%
n_train = int(len(dataset) * 0.6)
n_val = int((len(dataset) - n_train) * 0.5)
n_test = len(dataset) - n_train - n_val
# データセットの分割
torch.manual_seed(0) #乱数を与えて固定
train, val, test = torch.utils.data.random_split(dataset, [n_train, n_val,n_test])
# バッチサイズ
batch_size = 32
# 乱数のシードを固定して再現性を確保
torch.manual_seed(0)
# shuffle はデフォルトで False のため、学習データのみ True に指定
train_loader = torch.utils.data.DataLoader(train, batch_size, shuffle=True)
val_loader = torch.utils.data.DataLoader(val, batch_size)
test_loader = torch.utils.data.DataLoader(test, batch_size)
# 辞書型変数にまとめる(trainとvalをまとめて出す)
dataloaders_dict = {"train": train_loader, "val": val_loader}
ネットワークの定義と学習
class Net(nn.Module):
# 使用するオブジェクトを定義
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(16, 16)
self.fc2 = nn.Linear(16, 7)
# 順伝播
def forward(self, x):
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
return x
# インスタンス化
net = Net()
# 損失関数の設定
criterion = nn.CrossEntropyLoss()
# 最適化手法の選択
optimizer = torch.optim.SGD(net.parameters(), lr=0.1)
入力変数が16、クラスが7のため結合層を上記のように設定した。今回は単純化のため、層は増やさずシンプルに。
def train_model(net, dataloader_dict, criterion, optimizer, num_epoch):
#入れ子を用意(各lossとaccuracyを入れていく)
l= []
a =[]
# ベストなネットワークの重みを保持する変数
best_acc = 0.0
# GPUが使えるのであればGPUを有効化する
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net = net.to(device)
# (エポック)回分のループ
for epoch in range(num_epoch):
print('Epoch {}/{}'.format(epoch + 1, num_epoch))
print('-'*20)
for phase in ['train', 'val']:
if phase == 'train':
# 学習モード
net.train()
else:
# 推論モード
net.eval()
epoch_loss = 0.0
epoch_corrects = 0
# 第1回で作成したDataLoaderを使ってデータを読み込む
for inputs, labels in tqdm(dataloaders_dict[phase]):
inputs = inputs.to(device)
labels = labels.to(device)
# 勾配を初期化する
optimizer.zero_grad()
# 学習モードの場合のみ勾配の計算を可能にする
with torch.set_grad_enabled(phase == 'train'):
outputs = net(inputs)
_, preds = torch.max(outputs, 1)
# 損失関数を使って損失を計算する
loss = criterion(outputs, labels)
if phase == 'train':
# 誤差を逆伝搬する
loss.backward()
# パラメータを更新する
optimizer.step()
epoch_loss += loss.item() * inputs.size(0)
epoch_corrects += torch.sum(preds == labels.data)
# 1エポックでの損失を計算
epoch_loss = epoch_loss / len(dataloaders_dict[phase].dataset)
# 1エポックでの正解率を計算
epoch_acc = epoch_corrects.double() / len(dataloaders_dict[phase].dataset)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
#lossとaccをデータで保存する
a_loss = np.array(epoch_loss)
a_acc = np.array(epoch_acc.cpu()) #GPU⇒CPUに変換してnumpy変換
a.append(a_acc)
l.append(a_loss)
# 一番良い精度の時にモデルデータを保存
if phase == 'val' and epoch_acc > best_acc:
print('save model epoch:{:.0f} loss:{:.4f} acc:{:.4f}'.format(epoch,epoch_loss,epoch_acc))
torch.save(net, 'best_model.pth')
#testとvalのlossとaccを抜き出してデータフレーム化
a_train = a[::2]
l_train = l[::2]
a_train = pd.DataFrame({'train_acc':a_train})
l_train = pd.DataFrame({'train_loss':l_train})
a_val = a[1::2]
l_val = l[1::2]
a_val = pd.DataFrame({'val_acc':a_val})
l_val = pd.DataFrame({'val_loss':l_val})
df_acc = pd.concat((a_train,a_val),axis=1)
df_loss = pd.concat((l_train,l_val),axis=1)
#ループ終了後にdfを保存
df_acc.to_csv('acc.csv', encoding='shift_jis')
df_loss.to_csv('loss.csv', encoding='shift_jis')
# 学習と検証
num_epoch = 30
net = train_model(net, dataloaders_dict, criterion, optimizer, num_epoch)
各イタレーションでのlossとaccuracyをデータとして保存したかったので、リストで入れ込んでいる。
tensorのままだとNGとか、GPU上ではnumpyがうまく使えないなど、意外と面倒なことが判明。
テストデータでの実施
# 最適なモデルを呼び出す
best_model = torch.load('best_model.pth')
# 正解率の計算
def test_model(test_loader):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
with torch.no_grad():
accs = [] # 各バッチごとの結果格納用
for batch in test_loader:
x, t = batch
x = x.to(device)
t = t.to(device)
y = best_model(x)
y_label = torch.argmax(y, dim=1)
acc = torch.sum(y_label == t) * 1.0 / len(t)
accs.append(acc)
# 全体の平均を算出
avg_acc = torch.tensor(accs).mean()
std_acc = torch.tensor(accs).std()
print('Accuracy: {:.1f}%'.format(avg_acc * 100))
print('Std: {:.4f}'.format(std_acc))
# テストデータで結果確認
test_model(test_loader)
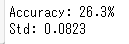
かなり正解率が低い。Std見る限りバッチ間での差はないので、全体的に悪い様子。
(得られたcsvファイル見ても、trainやvalの段階でそもそもよくないのだが…)
本当はモデル調整が必要だが、とりあえず実施できたということで終わりにした。
まとめ
精度はともかく手法はある程度把握できたと思う。
かなりコードが長くなってごり押し感はちょっとあるけど、GPUもちゃんと設定できたしまあいいや。
https://github.com/dem-kk/File/tree/main/DryBean
余談ですが今回利用・作成したcsvファイルをgithubに上げました。
※8/13 コード等一部修正(見直すと意外とスペルミスがあることに気づく)
参考
https://blog.bassbone.tokyo/archives/317
https://tetsumag.com/2021/01/11/ml7/
上記以外からもたくさん参考にしているが、特に使わせてもらったHP。