はじめに
何か面白そうだったので、記載練習がてらに触ってみました。
データ取り出しまで
ほぼこの記事そのままです。
# delikaのclientとPandas他、必要なパッケージ
!pip install --extra-index-url=https://docs.delika.io/python/ delika[DataFrame]
import delika
#JWTの取得
token = delika.new_token(host= "https://api.delika.io/v1", open_browser = "true")
token.save()
client = delika.load_client()
# データフレームで取得
import delika.pandas
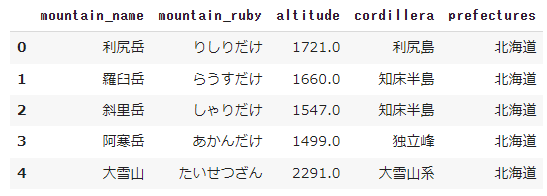
df1 = delika.pandas.read_delika_data(account_name="bpk_t", dataset_name="mountain", data_name="日本100名山.csv", client= client)
df1.head()
普通のimport pandasではエラーになっていた(import delika.pandasが必要)。delika用のpandasモジュールと思えばいいのだろうか?
データで何するか
難しいことはする気力がなかったので、単純に条件に当てはまる標高の山を探してみます。
日本100名山の中に、1000m以上1500m以下の山がどれだけあるのでしょうか?
df1[(df1['altitude'] >= 1000) & (df1['altitude'] <= 1500)]
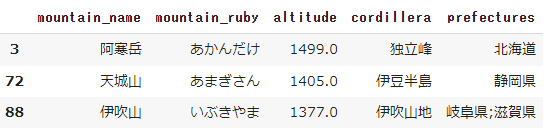
答えは3つでした。名山なだけあってもっと高い山が多いようです(ちなみに1000未満は2つでした)。
まとめ
高度なことはしてないけど、ちゃんとデータをとりだして使ってみることはできたのでないでしょうか。自分のデータセットも登録できるので、機会があればやってみたいです。