はじめに
Excelで下記のようなことをしたいなと思った。

Excelでそのままやってもいいけど、せっかくだからpythonで自動化できないかトライしてみた(このデータ数なら、自分で1つずつやった方が早いような...)。
環境(Colabratory)
windows 10
Python 3.7.10
pandas 1.1.5
内容
# colabratory上でのファイルアップロード
import pandas as pd
from google.colab import files
files.upload()
# データ表示(SHIFT-JISで日本語対応)
df = pd.read_csv('/content/data.csv',encoding='SHIFT-JIS')
df

データは90個あることがわかる。今回は値の列だけ取り出して実施する。
90÷5=18なので、最後に18個のデータがcsvに保存されていたら成功。
# 値の列だけを切り取り
df1 = df.iloc[:,1]
# 5個ずつ値の平均を取り、リストに入れ込む
x=0
mean_number = []
while x+5<=len(df1):
number = round(df1[x:x+5].mean(),2) #小数点2桁で表示
mean_number.append(number)
x+=5
# リストの数字をcsvに保存
df_mean = pd.DataFrame(mean_number, columns = ['平均値'])
df_mean.to_csv('/content/data2.csv',encoding='SHIFT-JIS')
csvファイルが保存されたので、本当にできているか確認してみよう。
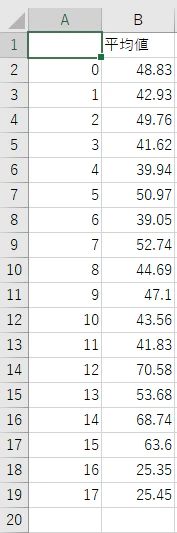
ちゃんと18個数字があるので、成功したようだ。多分正しくできてるはず。
まとめ
やりたいことはできたので満足(時間はちょっとかかったけど)。
やってて画像だけでなく、作成したファイルもアップしたいなと思った。GitHubも勉強しなければ…![]()