はじめに
筆者はふと思った。
「お寿司が食べたい🍣!」
別の日、こうも思った。
「何かpythonでやれたらいいな~![]() 何かいいネタないかな」
何かいいネタないかな」
…よし、この2つをくっつけてお寿司のデータセットを作ったらいいじゃないか?と思ったのがきっかけ。
お寿司だしちょうどネタ被りでいいんじゃね?って感じで
そんな短絡的なことではなく、ちゃんと分かりやすくて勉強になると思ってもちろんやってますよ。…はい。
画像集め
ペイント機能を使ってひたすら書いていきました。
沢山作るのはしんどいので、「鮪・鯛・蛸・鯵・鮭」の5種類で実施(計500枚)。
ペイントでひたすら書き書き。

これをずっと見ていると頭が混乱してきそう。
何とか500枚作成したので、次はデータセットの作成に移る。
データセットの作成
# zipファイルの解凍(colab上のため)
!unzip 500.zip
# モジュールインポート
from natsort import natsorted
import matplotlib.pyplot as plt
import cv2
import glob
import numpy as np
train_set = []
# 画像を読み込んでリスト化
files = glob.glob('/content/*.png')
for i in natsorted(files):
img_array = cv2.imread(i,cv2.IMREAD_GRAYSCALE)
img_array = cv2.resize(img_array, (28,28))
train_set.append(img_array)
# numpy配列に変換
train = np.array(train_set)
# バイナリファイルで保存
np.save('/content/oshusi_xtrain', train)
多次元配列になるためcsvでは保存できない。そのためバイナリ形式(.npy)で保存することにした。
作成したファイルを読み込んで、正しく画像が保管されているか確認する。
# npyファイルの読み込み
img = np.load('/content/oshusi_xtrain.npy')
# 画像を表示
from PIL import Image
pil_img = Image.fromarray(img[0]) #最初のだけ確認
plt.imshow(pil_img,cmap='gray') #グレースケールで表示
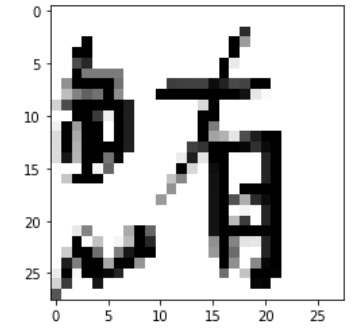
ちゃんと画像を呼び出せたので、データセットはできていそう。
まとめ
やりきったので何かすがすがしい気分。
実際に作ったデータセットで何かできたらいいなあ。
どこかでGitにもアップできればと思う。
(2021年11月15日)
下記にデータセット(画像とラベル)をアップしました。
ファイル作ってから気づいたけど「oshusi」になってた。違っていたけど何かかわいいからこのままにしておく。
https://github.com/dem-kk/File/tree/main/oshusi
参考
https://intellectual-curiosity.tokyo/2019/07/02/%E3%82%AA%E3%83%AA%E3%82%B8%E3%83%8A%E3%83%AB%E3%81%AE%E7%94%BB%E5%83%8F%E3%81%8B%E3%82%89%E3%83%87%E3%83%BC%E3%82%BF%E3%82%BB%E3%83%83%E3%83%88%E3%82%92%E4%BD%9C%E6%88%90%E3%81%99%E3%82%8B%E6%96%B9/
https://office54.net/python/module/sort-file-natsorted
https://numpy.org/doc/stable/reference/generated/numpy.load.html