お題
前回に引き続き、「小説家になろう」のAPIから取得したデータで、しょうもないことを調べてみます。
猫も杓子も異世界転生の昨今ですが、実のところ、異世界転生ってどれくらいの割合なんでしょう?
APIのパラメータについて
さっそくなろう小説APIを見てみましょう。
すると、即座に回答が見つかります。
- istensei 1を指定した場合、登録必須キーワードに「異世界転生」が含まれている小説のみを抽出します。
- istenni 1を指定した場合、登録必須キーワードに「異世界転移」が含まれている小説のみを抽出します。
- istt 1を指定した場合、登録必須キーワードに「異世界転生」または「異世界転移」が含まれている小説のみを抽出します。
すごい……親切です……!
一番面倒な「どうやって異世界転生か判断するの?」というフェーズがすっ飛びましたね。
さっそくAPIからデータを取得しましょう!……って、あれ……?ん……?
小説が異世界転生/転移モノか判別する、isttフラグですが、よくよく読むとこれ、データ属性ではありません。
あくまで、API問い合わせ時に「異世界転生/転移モノを除外したい!」という時に使うパラメータのようです。
でもご安心下さい。転生か判断するistenseiと転移か判断するistenniはデータ属性に入ってます。
isttについては、自分で計算することにしましょう。
補足・指標について
今回は、異世界転生も異世界転移もごっちゃにして、異世界転生/転移と一括りに扱います。
もちろん、公式がAPIで切り分けているだけあって、この二つは別ジャンルです。
が、うーん、一読者としては……転生モノと転移モノの違いって、プロローグで主人公を殺すかどうかってだけだし、そんなに気にしてないんですよね…(※個人の感想です
本稿では、全体における「異世界転生/転移の割合」を「異世界転生率」と呼ぶことにします。キャッチーでわかりやすいですし!
データの取得と加工
いつものようにデータを取得します。
今後のことを考えて、面白そうなのは全部パラメータに突っ込みました。
import pandas as pd
import requests
import json
import numpy as np
import seaborn as sns
from scipy import stats
import matplotlib.pyplot as plt
%matplotlib inline
url = "http://api.syosetu.com/novelapi/api/"
st = 1
lim = 500
data = []
while st < 2000:
payload = {'of': 't-g-l-gp-n-ga-ka-nt-gf-gl-its-iti', 'order': 'hyoka',
'out':'json','lim':lim,'st':st}
r = requests.get(url,params=payload)
x = r.json()
data.extend(x[1:])
st = st + lim
df = pd.DataFrame(data)
出て来るデータはこんな感じです。
| general_all_no | general_firstup | general_lastup | genre | global_point | istenni | istensei | kaiwaritu | length | ncode | noveltype | title |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 286 | 2012/11/22 17:00 | 2015/4/3 23:00 | 201 | 411735 | 0 | 1 | 22 | 2835125 | N9669BK | 1 | 無職転生 - 異世界行ったら本気だす - |
| 285 | 2013/11/7 15:49 | 2017/10/28 18:00 | 201 | 331740 | 1 | 0 | 40 | 3030120 | N8611BV | 1 | ありふれた職業で世界最強 |
| 299 | 2013/7/21 7:55 | 2017/10/20 18:39 | 102 | 325071 | 0 | 1 | 45 | 1092487 | N4029BS | 1 | 謙虚、堅実をモットーに生きております! |
| 303 | 2013/2/20 0:36 | 2016/1/1 0:00 | 201 | 319740 | 0 | 1 | 14 | 2091226 | N6316BN | 1 | 転生したらスライムだった件 |
| 205 | 2013/6/1 20:37 | 2017/3/25 10:00 | 201 | 307574 | 0 | 1 | 41 | 2763313 | N8802BQ | 1 | 八男って、それはないでしょう! |
さて、異世界転生と異世界転移から自分で異世界転生/転移フラグを作らないとダメですね。
istenni + istensei > 0なら1を返す、単純なステップ関数を使うのが早そうです。
APIの設計上、マイナス値が来ないことは確かですので、こんなのでいいでしょう。
def step(x):
if x == 0:
return 0
else:
return 1
また、初投稿日のgeneral_firstupと最終投稿日のgeneral_lastupがobject型になってます。日付型に変更しないといけませんね。
面倒なので、データフレームを修正する関数を作りましょう。
def modify_df(df):
def step(x):
if x == 0:
return 0
else:
return 1
df['general_firstup'] = pd.to_datetime(df['general_firstup'])
df['general_lastup'] = pd.to_datetime(df['general_lastup'])
df['series_period'] = df['general_lastup'] - df['general_firstup']
df['series_period'] = [t.days for t in df['series_period']]
df['per_episode'] = df['length'] / df['general_all_no']
df['istt'] = df['istenni'] + df['istensei']
df['istt'] = df['istt'].apply(step)
df['title_len'] = df['title'].apply(len)
df['year'] = df['general_firstup'].apply(lambda x:x.year)
return df
ちなみに、この関数は元のデータフレームも上書きします。
元のデータフレームを維持したい場合は、あらかじめdf.copy()でコピーを用意しておきましょう。
異世界転生どうでしょう
さっそく、異世界転生・転移ものと、それ以外の件数を比べてみましょう!
by_istt = df.groupby('istt')['title'].count().reset_index()
sns.barplot(x='istt',y='title',data=by_istt)
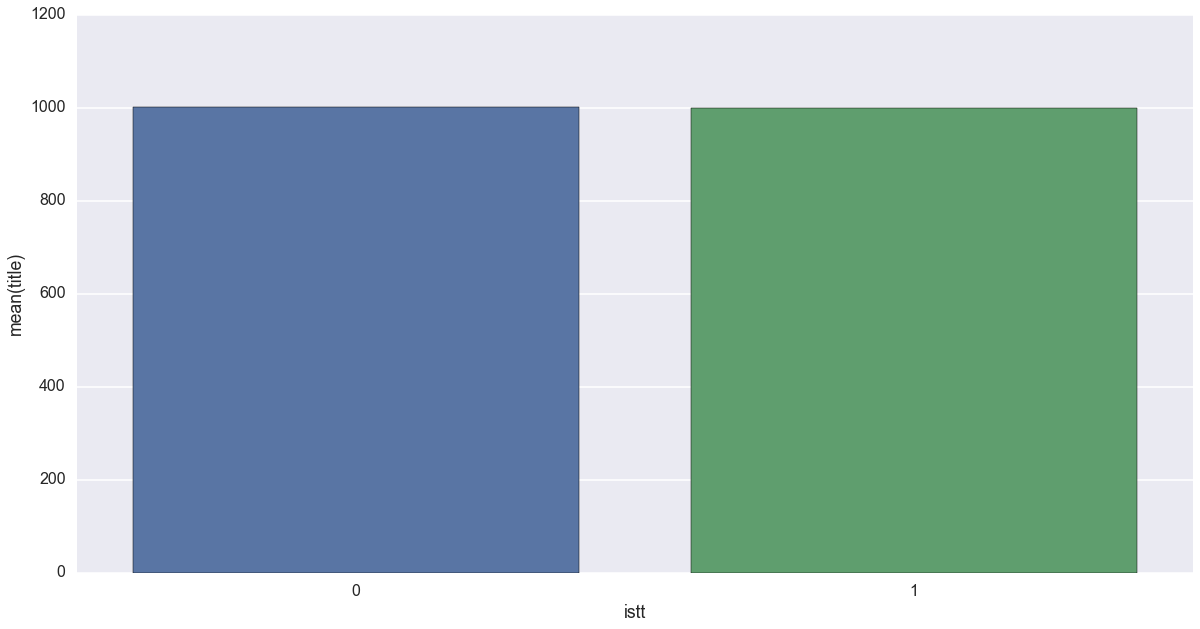
えーと、1が異世界転生/転移もので、0がそれ以外ですが……あれ、思ったより拮抗してますね…
異世界転生率、50%くらいでしょうか。
色んな切り口でデータを見る
不思議な感じがするので、データをもっとよく見ていきます。
幸い、pandasのgroupbyメソッドはSQLのGROUP BY構文とほぼ同じです。色々な切り口で集計が出来るので、試していきます。
年別データ
年別データです。先程はX軸に転生の有無、Y軸にタイトル数を指定しました。
今度はX軸に年を、Y軸はタイトル数、そしてhueに異世界転生フラグを入れます。
こうすることで、カテゴリ別の棒グラフが描けるのですね。
by_year_ten = df.groupby(['year','istt'])['title'].count().reset_index()
sns.barplot(x='year',y='title',hue='istt',data=by_year_ten)
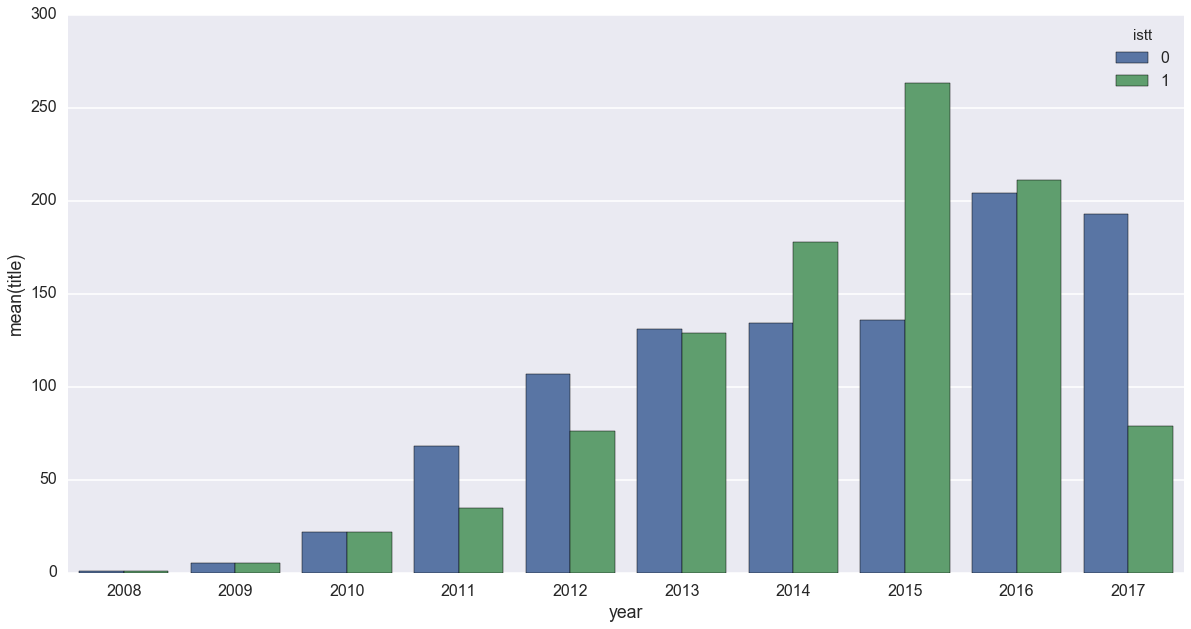
おっと、これは面白いデータですよ。
緑が異世界転生/転移小説の件数です。見ての通り、2015年にピークを迎えた後、2016年に落ち着いて、2017年にはドラマティックに減少してます。
どうやら、もう時は大転生時代ではなくなったようですね。私は転生モノ大好きなんで残念です。
ジャンル別データ
次はジャンル別に見てみましょう。コードは殆ど同じです。
by_genre = df.groupby(['genre','istt'])['title'].count().reset_index()
sns.barplot(x='genre',y='title',hue='istt', data=by_genre)
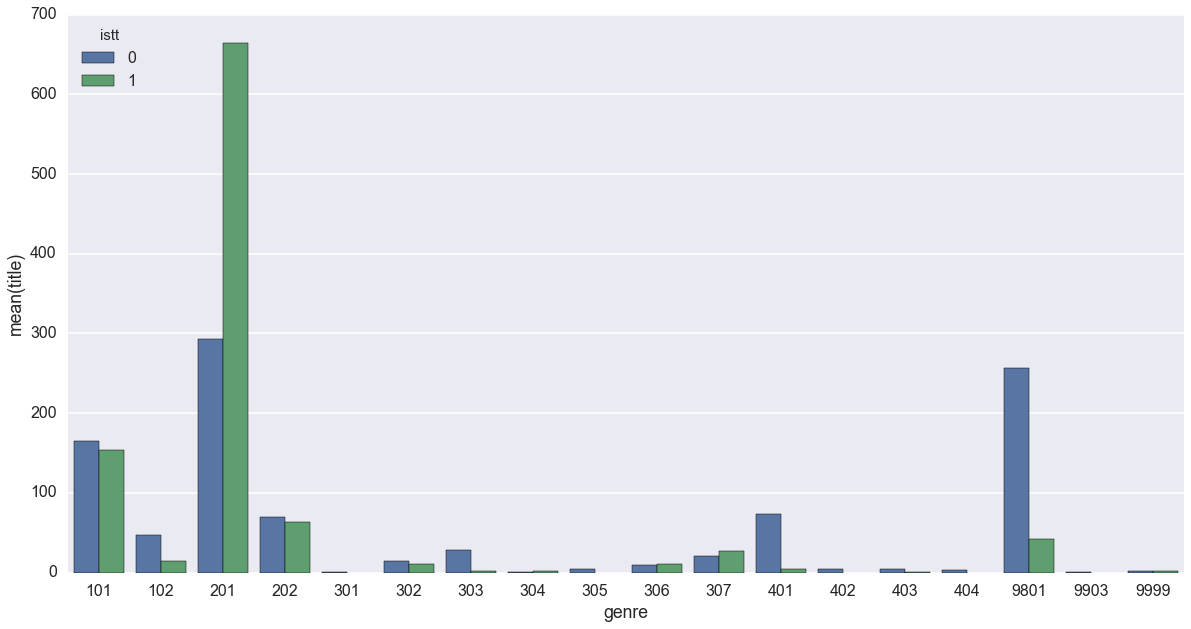
ジャンルが数字で、ぱっと見ではよく分かりませんね。
APIマニュアルから引用すると、
101: 異世界〔恋愛〕
102: 現実世界〔恋愛〕
201: ハイファンタジー〔ファンタジー〕
202: ローファンタジー〔ファンタジー〕
301: 純文学〔文芸〕
302: ヒューマンドラマ〔文芸〕
303: 歴史〔文芸〕
304: 推理〔文芸〕
305: ホラー〔文芸〕
306: アクション〔文芸〕
307: コメディー〔文芸〕
401: VRゲーム〔SF〕
402: 宇宙〔SF〕
403: 空想科学〔SF〕
404: パニック〔SF〕
9901: 童話〔その他〕
9902: 詩〔その他〕
9903: エッセイ〔その他〕
9904: リプレイ〔その他〕
9999: その他〔その他〕
9801: ノンジャンル〔ノンジャンル〕
とのことです。
異世界[恋愛]と現実世界[恋愛]の圧倒的な格差に、思うところは色々ありますが……まあ、みんな、恋愛は異世界でしたいってことでしょうか(遠い目
201 ハイファンタジーは抜きん出て件数が多く、異世界転生とそれ以外の比率も2:1くらいに見えます。
2017年に何があったかは、このジャンルに注目するといいのかも知れません。
あと、9801のノンジャンルには、異世界転生以外の小説が集中しているのも分かります。
年別にジャンルを見てみる
ここまで来ると、殆ど流れ作業です。
まず年別にデータフレームを指定する、マスクを作ってあげましょう。
あとはマスクを被せて、プロットするだけです。
mask15 = by_year_genre['year'] == 2015
sns.barplot(x='genre',y='title',hue='istt', data=by_year_genre[mask15])
2016年、2017年も作りました。繰り返しなのでコードは省略し、結果を見ましょう。
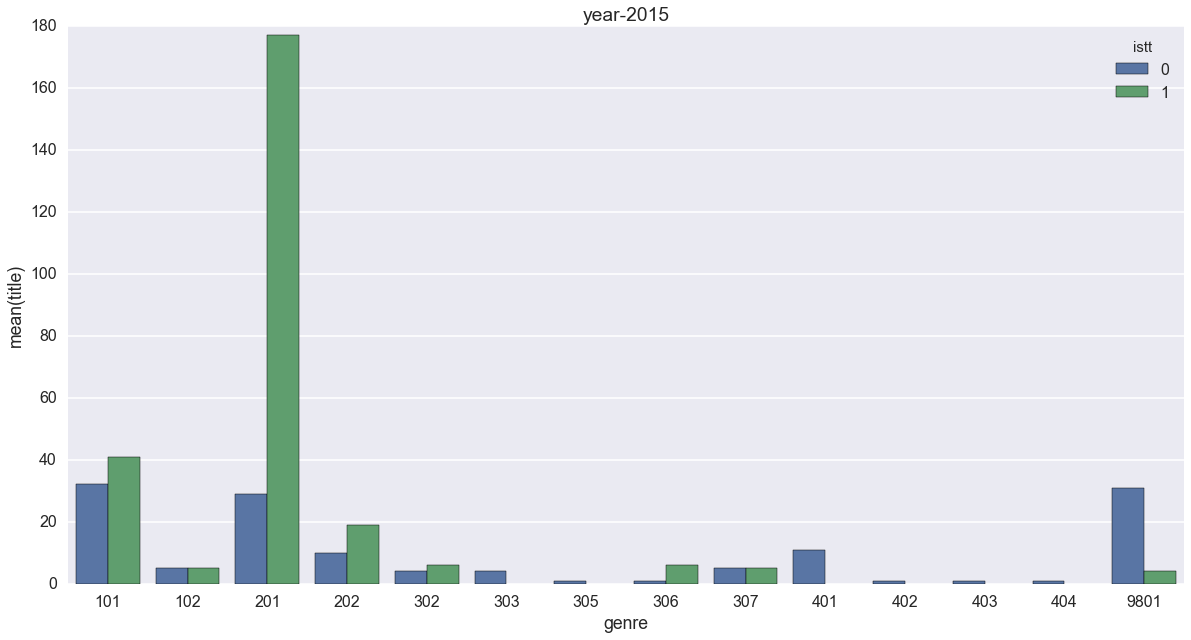
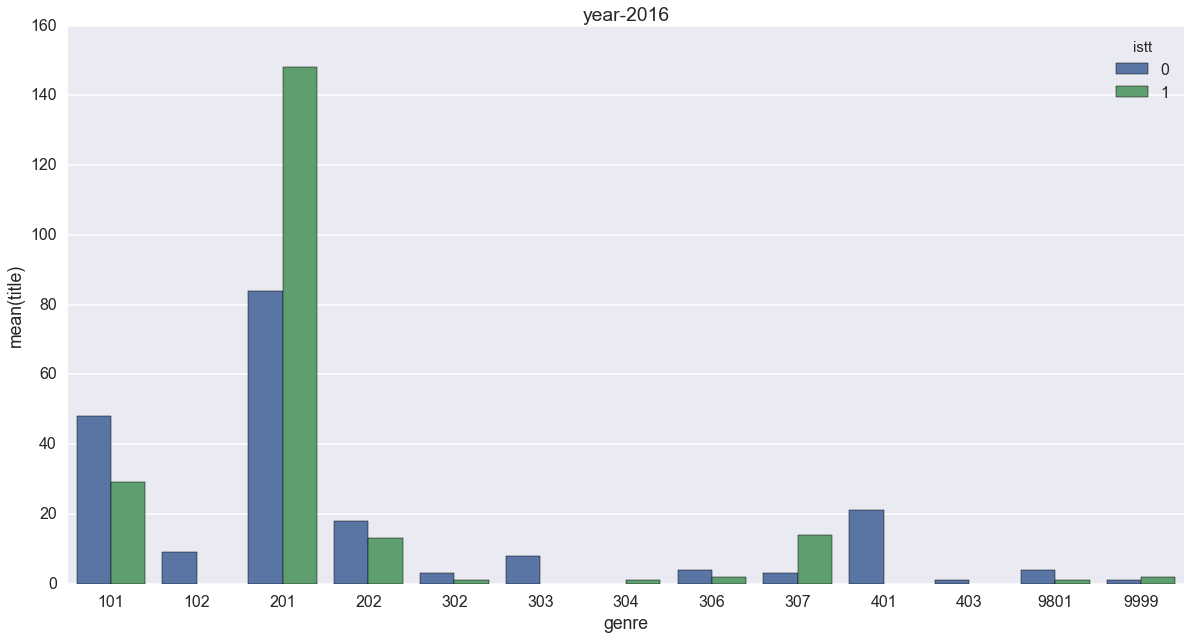
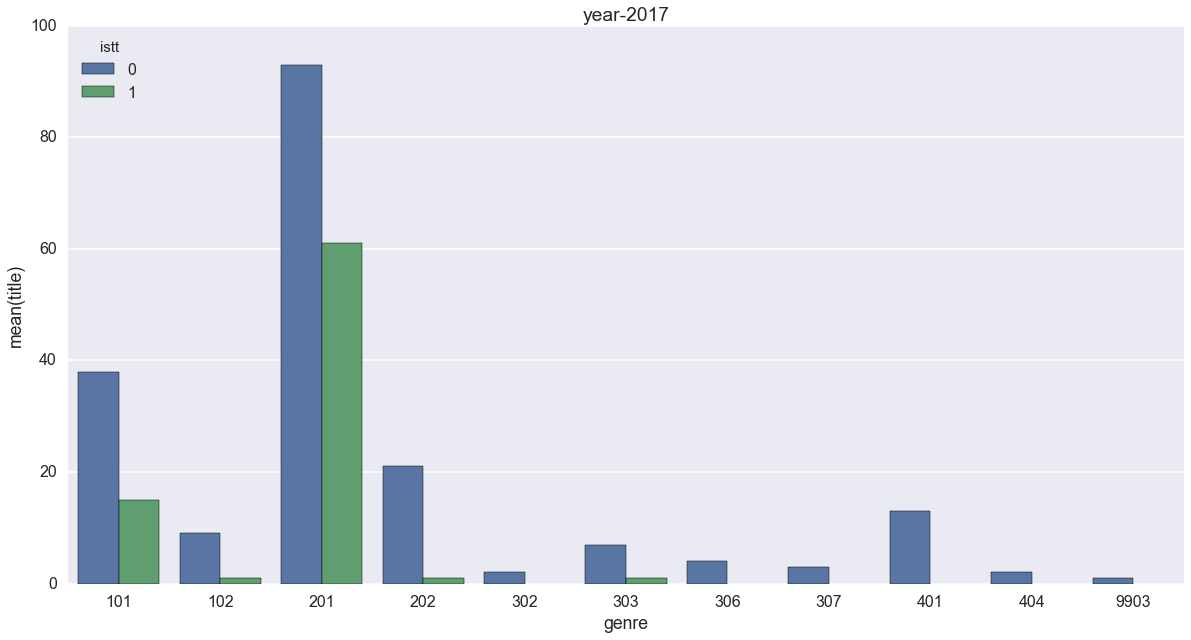
101の恋愛[異世界]、201のハイファンタジーに注目です。
もうはっきりと、異世界転生が減っているのが分かります。特にハイファンタジーでの落ち込みは顕著で、2017年には転生以外に逆転されていますね。2015年のグラフからは、想像も出来ません。
異世界転生率・年次推移
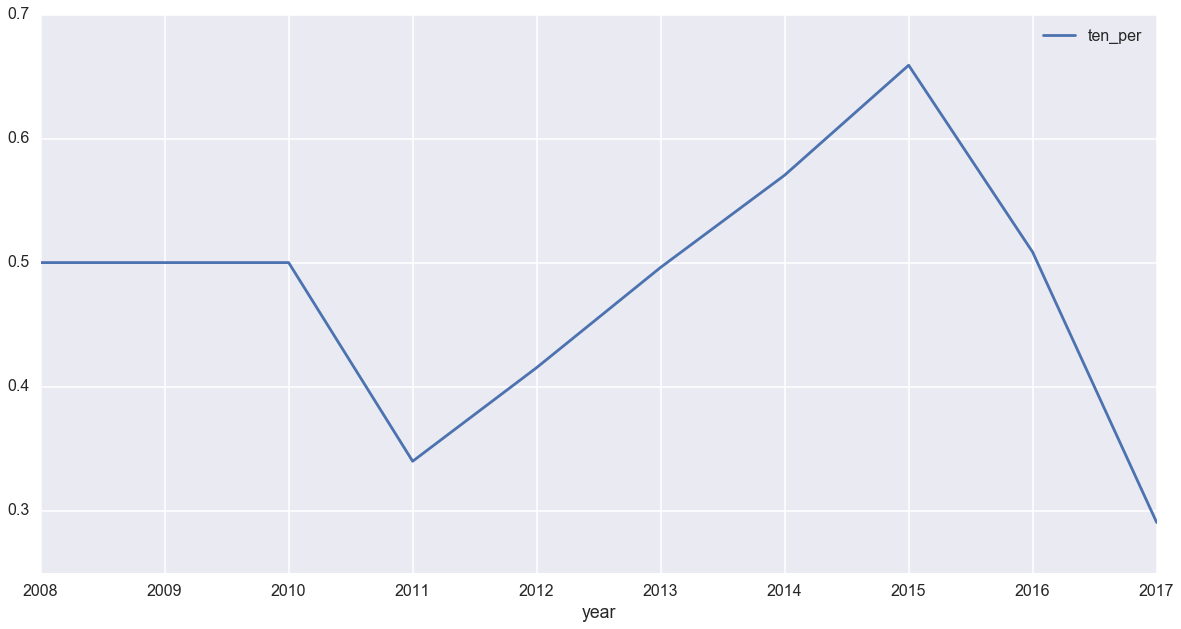
最後に、異世界転生率の年次推移を出しましょう。
今までは件数ベースで見てきましたが、今度はパーセンテージです。
必要なものは、
- 年別の小説全体数
- 年別の異世界転生/転移小説数
ですね。
まず、年別の小説全体数を出しましょう。
by_year = df.groupby('year')['title'].count().reset_index()
簡単ですね。年別の異世界転生小説数は、最初のグラフのときに作りました。
あとは、単純にこの二つをくっつけてしまいましょう。SQLにおけるINNER JOINを使います。
今回はmergeメソッドを使いますが、pandasには他にも様々な結合メソッドが用意されていますので、ケースに分けて使って下さい。
joined = pd.merge(by_year_ten,by_year,on='year',how='inner')
joined['ten_per'] = joined['title_x'] / joined['title_y']
joined[joined['istt']==1]
| year | istt | title_x | title_y | ten_per |
|---|---|---|---|---|
| 2008 | 1 | 1 | 2 | 0.500000 |
| 2009 | 1 | 5 | 10 | 0.500000 |
| 2010 | 1 | 22 | 44 | 0.500000 |
| 2011 | 1 | 35 | 103 | 0.339806 |
| 2012 | 1 | 76 | 183 | 0.415301 |
| 2013 | 1 | 129 | 260 | 0.496154 |
| 2014 | 1 | 178 | 312 | 0.570513 |
| 2015 | 1 | 263 | 399 | 0.659148 |
| 2016 | 1 | 211 | 415 | 0.508434 |
| 2017 | 1 | 79 | 272 | 0.290441 |
構文の見た目はまんまSQLっぽいですね。onで外部キーを指定します。
二つのテーブルに同名の項目があると(この場合はtitleがそう)、pandasは自動的に_x、_yを割り振ってくれます。
さて、ten_perが異世界転生率ですが、うーん、順調に落ちてますね。
結論
冒頭で「猫も杓子も異世界転生」と書きましたが、間違っておりました。
実際には、異世界転生率はかなり下がってきているようです。
アニメ化作品に転生モノが多いので、つい増えている印象を持ってしまいましたが、実態はだいぶ違いますね。
アニメ化する作品というのは、数年以上連載している作品が殆どなので、ブーム絶頂期の雰囲気がタイムマシン的にやって来ているのかも知れません。