高速化
モデルを出来るだけ早く構築する技術
【分散深層学習】
深層学習は多くのデータを使用したり、パラメータ調整のために多くの時間を使用するため、高速な計算が求められる。毎年10倍の早さでモデルが複雑になっており、計算量も10倍になっている。一方コンピューターは18ヶ月で2倍に性能UP。これではモデルの複雑化にコンピューターの性能が追いつかない!!
複数の計算資源(ワーカー)を使用し、並列的にニューラルネットワークを構築することで、効率の良い学習を行いたい。
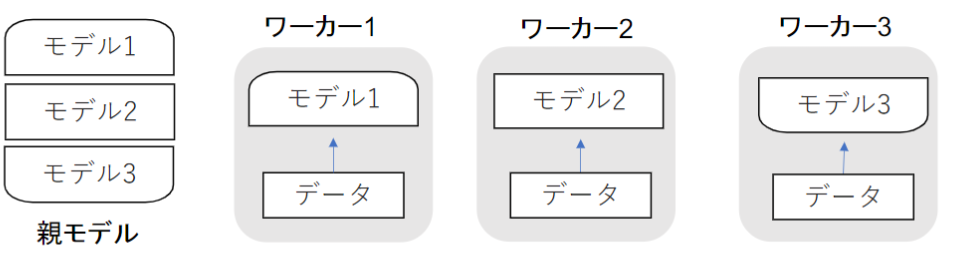
①データ並列化
・親モデルを各ワーカーに子モデルとしてコピー
・データを分割し、各ワーカーごとに計算させる
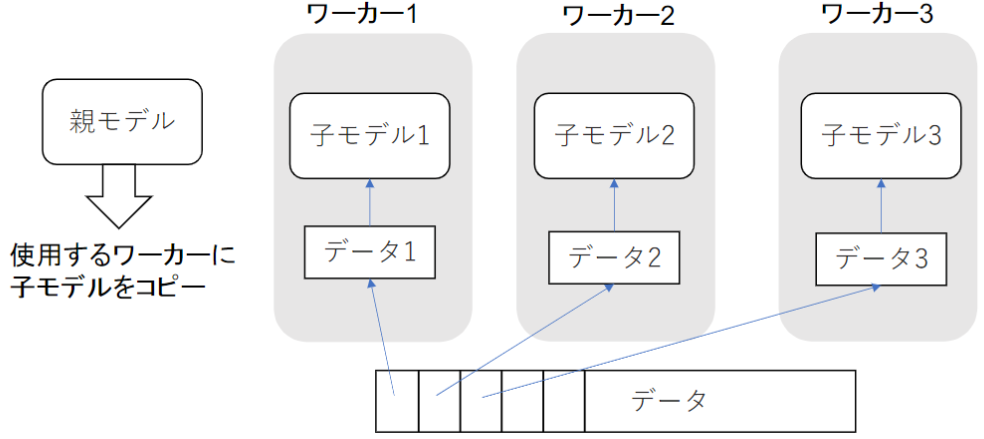
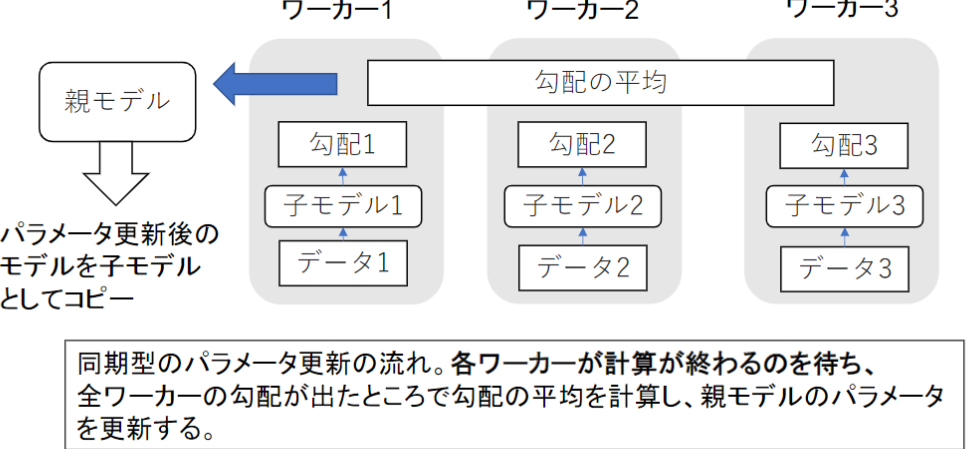
データ並列化(同期型)
各ワーカーが計算が終わるのを待つ必要があるため、自身でコントロール可能なコンピューターを複数準備できるならこちらの方がよい。安定的に学習が進む。現在は、同期型の方が精度が良いことが多いので、主流となっている。
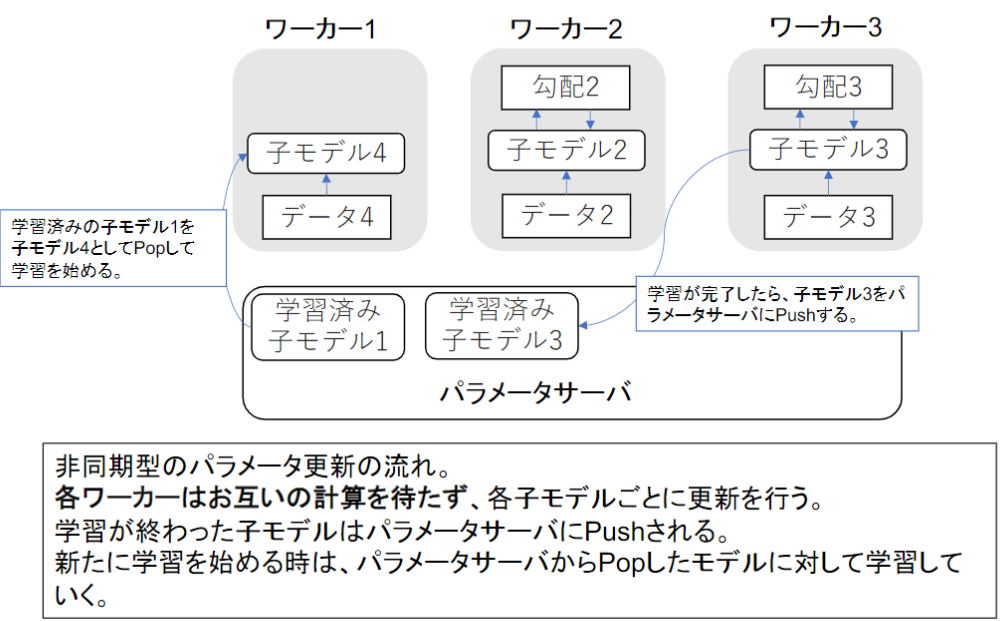
データ並列化(非同期型)
各ワーカーはお互いの計算を待たず、各子モデル毎に更新される。そのため、各自が持っているPCやスマホを使うなど、自身でコントロールが難しいコンピュータを使用する場合に適している。ただし、学習は不安定になりやすい。
②モデル並列
親モデルを各ワーカーに分割し、それぞれのモデルを学習させる。全てのデータで学習が終わった後で、一つのモデルに復元。モデルが大きい時はモデル並列化を、データが大きい時はデータ並列化をすると良い。
③GPU
CPUと比べ、「低性能なコアが多数」「簡単な並列処理が得意」。ニューラルネットワークの学習は単純な行列演算が多いので、高速化が可能。
軽量化
スマホなどの性能でもモデルを動かせるようにするために、モデルを軽量化する技術。
モデルの精度を維持しつつパラメータや演算回数を低減する手法の総称。
①量子化(Quantization)
簡単にできるため、最も良く使う方法。
ネットワークが大きくなると大量のパラメータが必要になり、学習や推論に多くのメモリと演算処理が必要。通常のパラメータの64bit浮動小数点を32bitなど下位の精度に落とすことでメモリと演算処理の削減を行う。「計算の高速化」「省メモリ化」という利点があるが、一方で「精度の低下」という欠点もある。実際の問題では倍精度(64bit)を単精度(32bit)にしてもほぼ精度はかわらない。

【実装例】量子化のライブラリ
import torch.quantization
print(torch.quantization.default_qconfig)
QConfig(activation=functools.partial(, reduce_range=True), weight=functools.partial(, dtype=torch.qint8, qscheme=torch.per_tensor_symmetric))
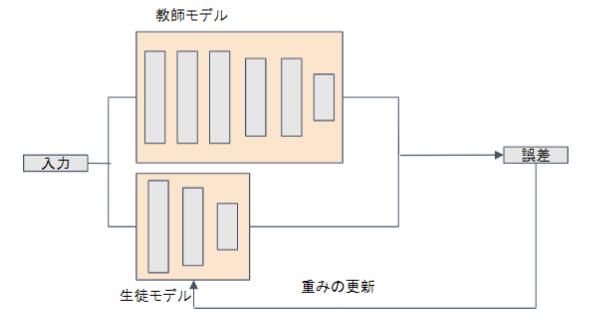
②蒸留(Distillation)
精度の高いモデルはニューロンの規模が大きなモデルになっている。そのため、推論に多くのメモリと演算処理が必要。そこで、大きなモデルの知識を使い、軽量なモデルの作成を行う。
蒸留は「教師モデル」と「生徒モデル」の2つで構成される。
教師モデル:予測精度の高い、複雑なモデルやアンサンブルされたモデル
生徒モデル:教師モデルをもとに作られる軽量なモデル
教師モデルの重みを固定し生徒モデルの重みを更新していく
誤差は教師モデルと生徒モデルのそれぞれの誤差を使い重みを更新していく
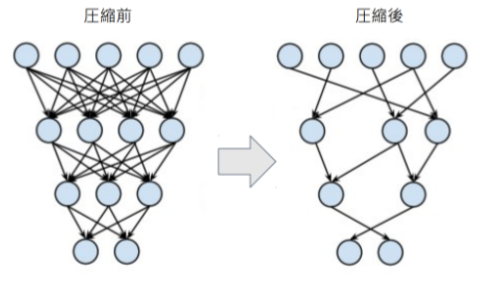
③プル-ニング(Pruning)
ネットワークが大きくなると大量のパラメータのすべてのニューロンの計算が精度に寄与しているわけではない。モデルの精度に寄与が少ないニューロンを削減することでモデルの軽量化、高速化が見込まれる。