双方向RNN
扱う時系列データの種類によっては、LSTM・GRUを更に応用させたモデルが用いられる。例えば、時間情報の途中が欠けていてそれが何かを予測したい場合は、過去の情報だけでなく、過去と未来両方の情報を使って予測したほうが効果的といえる。通常のLSTM・GRUでは過去から未来への一方向でしか学習をすることができなかったが、LSTM(GRU)を2つ組み合わせることで、未来から過去方向も含めて学習できるようにしたモデルのことを双方向RNN(BiRNN:Bidirectional RNN)という。
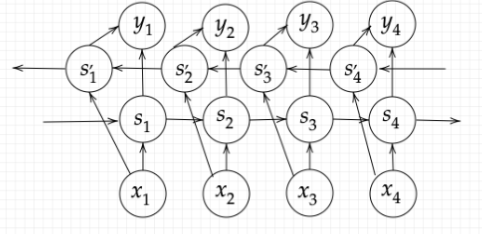
上図では、S1⇒S2⇒S3⇒S4は過去から未来の方向へ情報を反映している。
S'4⇒S'3⇒S'2⇒S'1は未来から過去の方向へ情報を反映している。
【実装例】
import numpy as np
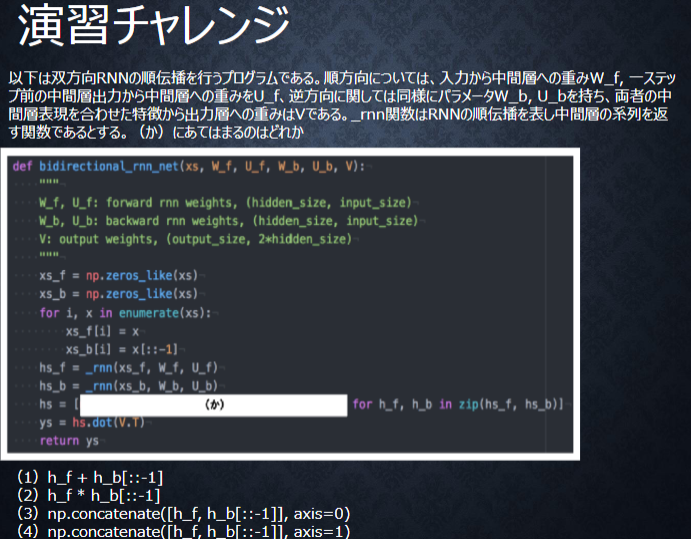
def bidirectional_rnn_net(xs, W_f, U_f, W_b, U_b, V):
"""
W_f, U_f: forward rnn weights, (hidden_size, input_sixe)
W_b, U_b: backward rnn weights, (hidden_size, input_sixe)
V: output Weights, (output_size, 2*hidden_size)
"""
xs_f = np.zeros_like(xs)
xs_b = np.zeros_like(xs)
for i, x in enumerate(xs):
xs_f[i] = x
xs_b[i] = x[::-1]
hs_f = _rnn(xs_f, W_f, U_f)
hs_b = _rnn(xs_b, W_b, U_b)
hs = [np.concatenate([h_f,h_b[::-1]], axis=1) for h_f, h_b in zip(hs_f, hs_b)]
ys = hs.dot(V.T)
return ys
【演習問題】
解答
双方向RNNでは、順方向と逆方向に伝播したときの中間層表現をあわせたものが特徴量となるので、np.concatenate([h_f, h_b[::-1]], axis=1)。
Seq2Seq(sequence to sequence)
EncoderとDecoderを備えたEncoder-Decoderモデルを使って、系列データを別の系列データに変換するモデルのこと。自動翻訳技術で用いられており、ある時系列データから翻訳元となるソース文の直近の中間層の状態を翻訳先となるターゲット文を生成するRNNの中間層の値とすることが行われている。
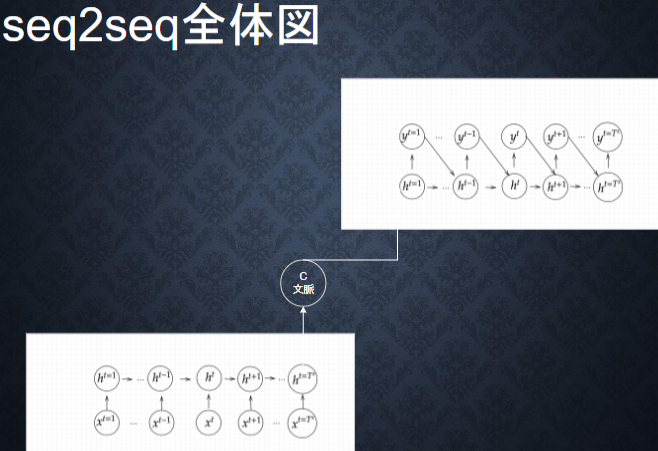
【Encoder】
文の意味をベクトル表現としてhの中に保存する
【Decoder】
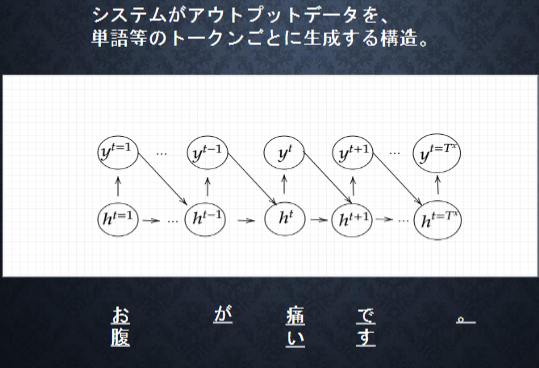
【実装例】Encoder
import numpy as np
def encode(words, E, W, U, b):
"""
words: sequence words (sentence), one-hot vector, (n_words, vocab_size)
E: word embeding matrix, (embed_size, vocab_size)
W: upward weights, (hidden_size, hidden_size)
U: lateral weights, (hidden_size, embed_size)
b: bias, (hidden_size,)
"""
hidden_size = W.shape[0]
h = np.zeros(hidden_size)
for w in words:
e = E.dot(w)
h = _activation(W.dot(e) + U.dot(h) + b)
return h
単語wはone-hotベクトルであり、それを単語埋め込みにより別の特徴量に変換する。これは埋め込み行列Eを用いて、E.dot(w)とかける
【確認テスト】

回答:(2)
【HRED(Seq2Seq + Context RNN)】
Seq2Seqの課題は、一文に対して一文を返すことしかできな。つまり一問一答。過去の文脈も使えるようにしたい。そのために、Seq2Seqの中間層を次ぎのSeq2Seqの中間層の入力値として使用し、過去のcontextを入れ込めるようにした。しかし、HREDは短い単純な返答歯科出来なく成るという課題画出た。
【VHRED】
HREDに、VAEの潜在変数の概念を追加したもの。HREDの課題を克服。
【VAE】Variational AutoEncoder Network
オートエンコーダーを活用したモデルだが、VAEは入力を固定された表現に圧縮するのではなく、統計分布に変化する。すなわち、平均と分散を表現できるように学習をする。
入力データが何かしらの分布に基づいて生成されているものだとして、その分布を表現するように学習をすればいいのではないかという考えからこうしたアプローチがとられた。
【確認テスト】

回答:
seq2seq:一問一答で、ある時系列データから別の時系列データを作り出すネットワーク
HRED:これまでのseq2seqに過去の文脈を反映できるようにした手法
VHRED:HREDが当たり障りのない回答しかできなくなった課題の克服のため、VAEの潜在変数の概念を追加したもの。

回答:確率分布
Word2vec
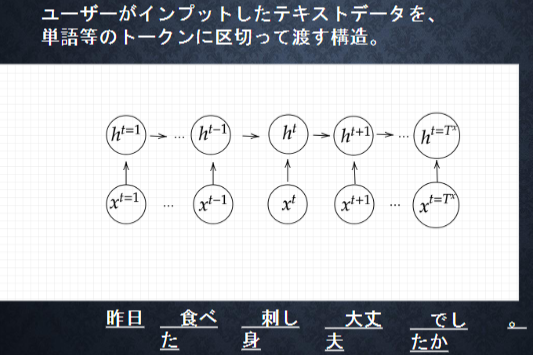
RNNでは、単語のような可変長の文字列をNNに与えることはできない。そのため固定長形式で
単語を表す必要があった。このWord2vecは文字列からembeding表現を得る方法の一つ。単語(word)は、記号の集まり(文字列)として表現ができる。この記号をベクトルとして表現することにより、ベクトル間の距離や関係として単語の意味を表現しようとするモデル。
# Word2Vecライブラリの導入
!pip install gensim
# Word2Vecライブラリのロード
from gensim.models import word2vec
# 事前準備したword_listを使ってWord2Vecの学習実施
model = word2vec.Word2Vec(word_list, size=100,min_count=5,window=5,iter=100)
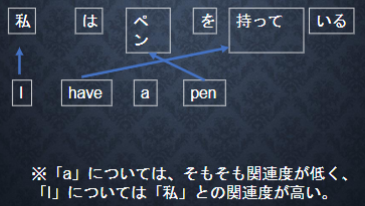
Attention
Seq2Seqは、長い文章への対応が難しいという課題があった。Seq2Seqでは、2単語でも、100単語でも、固定次元ベクトルの中に入力しなければならない。文章が長くなればなるほど、そのシーケンスの内部表現の次元も大きくなっていく仕組みが必要となった。そこで考えられたのがAttentionである。これは、「入力と出力のどの単語が関連しているのか」の関連度を学習する仕組み。
Attentionの具体例
【実装例】
class SimpleAttention(tf.keras.models.Model):
'''
Attention の説明をするための、 Multi-head ではない単純な Attention です
'''
def __init__(self, depth: int, *args, **kwargs):
'''
コンストラクタです。
:param depth: 隠れ層及び出力の次元
'''
super().__init__(*args, **kwargs)
self.depth = depth
self.q_dense_layer = tf.keras.layers.Dense(depth, use_bias=False, name='q_dense_layer')
self.k_dense_layer = tf.keras.layers.Dense(depth, use_bias=False, name='k_dense_layer')
self.v_dense_layer = tf.keras.layers.Dense(depth, use_bias=False, name='v_dense_layer')
self.output_dense_layer = tf.keras.layers.Dense(depth, use_bias=False, name='output_dense_layer')
def call(self, input: tf.Tensor, memory: tf.Tensor) -> tf.Tensor:
'''
モデルの実行を行います。
:param input: query のテンソル
:param memory: query に情報を与える memory のテンソル
'''
q = self.q_dense_layer(input) # [batch_size, q_length, depth]
k = self.k_dense_layer(memory) # [batch_size, m_length, depth]
v = self.v_dense_layer(memory)
# ここで q と k の内積を取ることで、query と key の関連度のようなものを計算します。
logit = tf.matmul(q, k, transpose_b=True) # [batch_size, q_length, k_length]
# softmax を取ることで正規化します
attention_weight = tf.nn.softmax(logit, name='attention_weight')
# 重みに従って value から情報を引いてきます
attention_output = tf.matmul(attention_weight, v) # [batch_size, q_length, depth]
return self.output_dense_layer(attention_output)
【確認テスト】

回答
RNN:時系列データを処理するのに適したネットワーク
Word2vec:単語の分散表現ベクトルを得る手法
seq2seq:ある時系列データから別の時系列データを得るネットワーク
Attention:時系列データのそれぞれの関連性について重みをつける手法