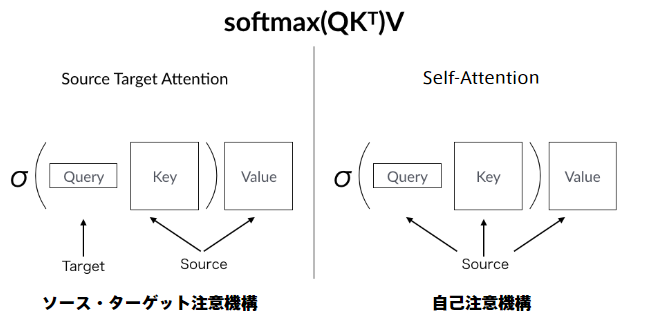
Seq2Seq
入力が時系列で出力も時系列で予測したいという場合に使用。
例)英語から日本語への機械翻訳、音声認識(波形⇒テキスト)、チャットボット(テキスト⇒テキスト)など
Encoder(入力データ処理)-Decoder(出力データ処理)モデルとも呼ばれる。
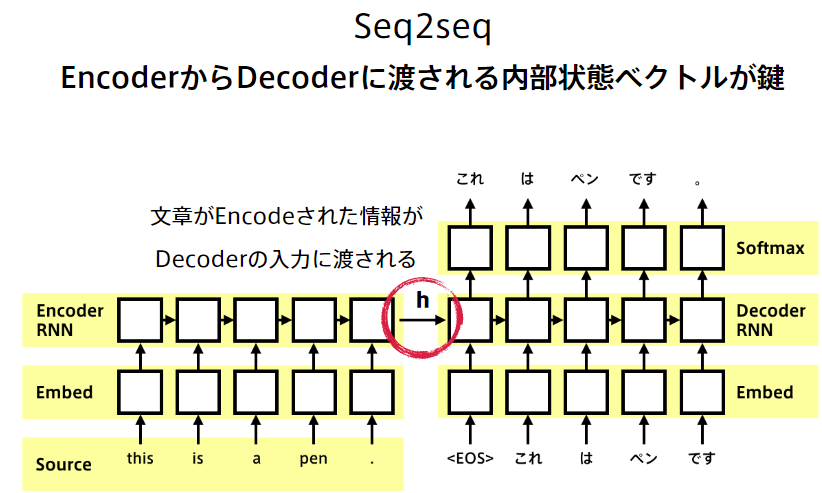
【実装例】Encoder、Decoder
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size):
"""
:param input_size: int, 入力言語の語彙数
:param hidden_size: int, 隠れ層のユニット数
"""
super(Encoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size, padding_idx=PAD)
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, seqs, input_lengths, hidden=None):
"""
:param seqs: tensor, 入力のバッチ, size=(max_length, batch_size)
:param input_lengths: 入力のバッチの各サンプルの文長
:param hidden: tensor, 隠れ状態の初期値, Noneの場合は0で初期化される
:return output: tensor, Encoderの出力, size=(max_length, batch_size, hidden_size)
:return hidden: tensor, Encoderの隠れ状態, size=(1, batch_size, hidden_size)
"""
emb = self.embedding(seqs) # seqsはパディング済み
packed = pack_padded_sequence(emb, input_lengths) # PackedSequenceオブジェクトに変換
output, hidden = self.gru(packed, hidden)
output, _ = pad_packed_sequence(output)
return output, hidden
class Decoder(nn.Module):
def __init__(self, hidden_size, output_size):
"""
:param hidden_size: int, 隠れ層のユニット数
:param output_size: int, 出力言語の語彙数
:param dropout: float, ドロップアウト率
"""
super(Decoder, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.embedding = nn.Embedding(output_size, hidden_size, padding_idx=PAD)
self.gru = nn.GRU(hidden_size, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
def forward(self, seqs, hidden):
"""
:param seqs: tensor, 入力のバッチ, size=(1, batch_size)
:param hidden: tensor, 隠れ状態の初期値, Noneの場合は0で初期化される
:return output: tensor, Decoderの出力, size=(1, batch_size, output_size)
:return hidden: tensor, Decoderの隠れ状態, size=(1, batch_size, hidden_size)
"""
emb = self.embedding(seqs)
output, hidden = self.gru(emb, hidden)
output = self.out(output)
return output, hidden
【問題】
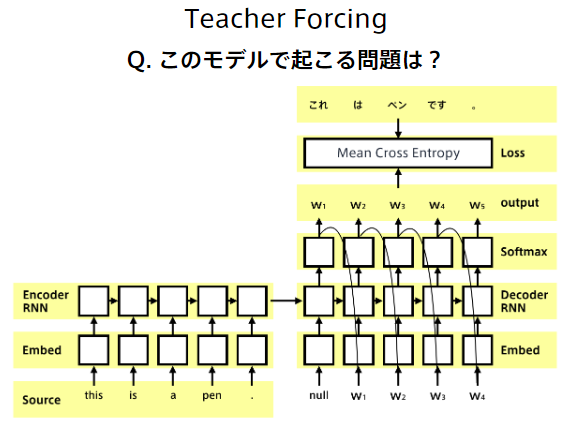
Decoderにおいて、前の方で誤りがあると、その誤差が連鎖的に大きくなってしまい、学習が不安定になってしまう。
《解決策》訓練時には、Decoder側の入力にターゲット系列(正解データ)をそのまま使う。デメリットは、評価時は前の時刻のDecoderが生成したものが使われるため、学習時と分布が異なってしまうことがある。
Transformer
RNNは過去のどの時点がどれだけ影響をもっているかまでは直接的には求めていない。あくまでも、それまでの時点の状態がまとまって過去の隠れ層として反映されている。そうした背景から、「時間の重み」をネットワークに組み込んだのがAttenstionと呼ばれる機構。また、RNNでは、翻訳元の文の内容をひとつのベクトル表現にしてしまうため、文長が長くなると表現力が足りなくなるが、Transformerで実装されているAttention機構はその問題を解決している。
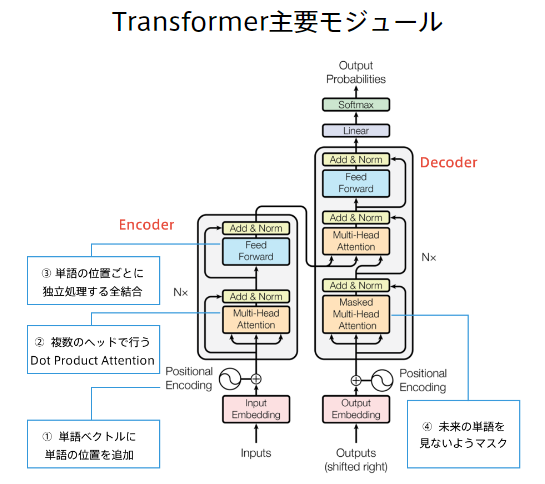
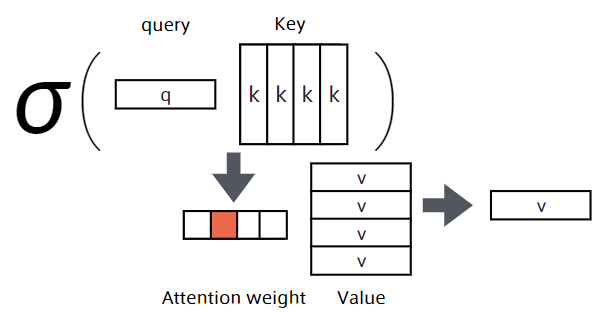
Attentionは何かをしているのか?
Attentionは辞書オブジェクト
Query(検索クエリ)に一致するkeyを牽引し、対応するValueを取り出す操作とみなすことができる。
これは辞書オブジェクトの機能と同じ。
Attention機構には2種類ある
特に「Self-Attention」が肝